US20040006559A1 - System, apparatus, and method for user tunable and selectable searching of a database using a weigthted quantized feature vector - Google Patents
System, apparatus, and method for user tunable and selectable searching of a database using a weigthted quantized feature vector Download PDFInfo
- Publication number
- US20040006559A1 US20040006559A1 US10/448,168 US44816803A US2004006559A1 US 20040006559 A1 US20040006559 A1 US 20040006559A1 US 44816803 A US44816803 A US 44816803A US 2004006559 A1 US2004006559 A1 US 2004006559A1
- Authority
- US
- United States
- Prior art keywords
- database
- user
- data
- similarity
- query
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Abandoned
Links
Images

















Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/20—Information retrieval; Database structures therefor; File system structures therefor of structured data, e.g. relational data
- G06F16/24—Querying
- G06F16/245—Query processing
- G06F16/2457—Query processing with adaptation to user needs
- G06F16/24578—Query processing with adaptation to user needs using ranking
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/903—Querying
-
- G—PHYSICS
- G16—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR SPECIFIC APPLICATION FIELDS
- G16C—COMPUTATIONAL CHEMISTRY; CHEMOINFORMATICS; COMPUTATIONAL MATERIALS SCIENCE
- G16C20/00—Chemoinformatics, i.e. ICT specially adapted for the handling of physicochemical or structural data of chemical particles, elements, compounds or mixtures
- G16C20/40—Searching chemical structures or physicochemical data
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/953—Organization of data
- Y10S707/955—Object-oriented
-
- Y—GENERAL TAGGING OF NEW TECHNOLOGICAL DEVELOPMENTS; GENERAL TAGGING OF CROSS-SECTIONAL TECHNOLOGIES SPANNING OVER SEVERAL SECTIONS OF THE IPC; TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10—TECHNICAL SUBJECTS COVERED BY FORMER USPC
- Y10S—TECHNICAL SUBJECTS COVERED BY FORMER USPC CROSS-REFERENCE ART COLLECTIONS [XRACs] AND DIGESTS
- Y10S707/00—Data processing: database and file management or data structures
- Y10S707/99931—Database or file accessing
Definitions
- CD-R bearing the electronic title “Gange & Framroze,” the contents of which comprise a program listing in ASCII text file format entitled LISTING.TXT, being of size 86 KB and having been created on May 29, 2003.
- the contents of said CD-R is incorporated by reference herein.
- the CD-R is hand labeled as follows:
- This invention relates to data processing and specifically enabling highly efficient searching of a database wherein the entries can be characterized using a set of one or more descriptive properties that can be expressed in numeric form.
- the question: “Which are most similar?” is not meaningful without additional input.
- a proper answer requires input of the key dimension. If “feathers” represent the key dimension, then the hawk and the hummingbird are most similar. If “the ability to fly stationary” is the key dimension, then the dragonfly and the hummingbird are most similar. Other possible key dimensions could be metabolism, life span, body temperature, etc. Therefore, the answer to the question: “Which are most similar?” is subjective depending upon the preferences of the person supplying the answer.
- a potential buyer would be looking to buy a home by expressing preferences that become the parameters for a similarity search. Such parameters might include number of bedrooms, type of house, asking price, neighborhood, quality of the local school system, property taxes, age restrictions on residents, home-owners' associations, etc.
- a real estate agent would first screen for homes having a specific most desirable characteristic (e.g., neighborhood or number of bedrooms). Then, the agent would look for the next desirable characteristic. The process would be repeated for each parameter, each search yielding a number of homes for consideration by the buyer. Where a particular home appears in the search results multiple times, it is more likely that the agent can make a sale.
- a binary feature vector may be created using these and other parameters, and a similarity search can be performed to match a potential buyer's preferences. This search would generate a list of homes approximating these preferences. A binary vector could indicate whether or not the buyer is interested in a particular feature. The homes can then be compared in their entirety by computing the mathematical distance between their feature vectors. In the rare instance where an exact match is found, the distance between the vectors would be zero. However, if the distance is not zero, the smaller the distance between the feature vectors of an ideal home and an available home, the more similar they are.
- a chemical structure similarity search may be performed by creating a chemical fragment dictionary or by using an algorithm that generates chemical structure fragments.
- a fragment consists of a grouping of atoms attached to one another by specific chemical bonds. All of the compounds in the database are parsed to determine whether or not a particular fragment is present.
- Associated with each compound is a binary vector. Each element of the vector represents the presence or absence of a specific fragment. This binary vector then serves as an index for that compound in the database.
- a search can be made to find a compound in the database that is similar to a substance that interests the user. The distance between the vector for the new substance and the vectors of compounds in the database can be calculated. The results can then be returned in order of decreasing similarity.
- a feature vector or a vector of test results can be formed where binary values would not be used.
- the distance between vectors may be measured, and distances would represent the degree of similarity between entries in the database.
- Similarity searching using quantized vectors is prior art.
- prior art searches have been performed according to a fixed searching algorithm.
- the user might wish to perform a similarity search based upon substructure comparisons, and the data processing system would provide an answer as a sorted list of compounds.
- process development chemists search for similarity in chemical compounds, some parts of the molecule are more important to them than other parts. Therefore, when performing a search, they would be interested in establishing a higher search priority to the important substructures and a lower search priority to the less important substructures. Assignment of search priorities is arbitrary and based upon user preference.
- priorities of substructure preferences can be dynamically assigned, then should the results of the search not be what the user desires, the user can reassign substructure priorities, thereby refining the search results.
- the units of assigned priority or weights can be arbitrary, and only their ratio to each other is important.
- the similarity search revealed homes having all of the features that interested a potential buyer. Yet, for some potential buyers, certain items are more important than others. For example, for a family with four children, purchase of a house with five bedrooms and the quality of the school system might be more important than asking price and property taxes. Yet these latter features could also serve as influencing factors. In such a case, being able to assign higher priorities to certain features and lower priorities to other features would result in a more meaningful search.
- the invention disclosed herein is a data processing product and method that permits computerized similarity searching of an electronic database using a quantization vector.
- the quantization vector a linear array of descriptive properties of the entries in the database, is maintained by the system. Different datatype representations of the quantization vector may be implemented.
- the system examines the structure of a query item in terms of its known descriptive properties. During examination, the quantization vector is established. This vector represents the query item's “fingerprint.” The system then searches the entire database for identity or similarity to the query item by comparing the vectors.
- the system further permits the user to set numeric priorities for the descriptive properties in a user friendly environment, said priorities to be used in the search for entries that are similar to the query item.
- An object of the invention is to provide a simplified searching system for naive and infrequent users.
- a computerized user tunable system is disclosed that selectively searches a database of chemical compounds.
- a computerized user tunable system is disclosed that selectively searches a database of biological activity screening test results.
- FIG. 1 is an overview program flowchart showing a current computerized method of performing similarity searches for a generalized database. The method shown is prior art.
- FIG. 2 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches for a generalized database.
- FIG. 3 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of organic chemical compounds.
- FIG. 4 shows the screen view of the chemical structure of the query compound, Trovafloxacin, as drawn by the user with one of the standard chemical drawing software packages and input into the search program.
- FIG. 5 shows the structure of the query compound having been parsed or fingerprinted according to chemical structure fragments in a fragment dictionary. Only twelve fragments are shown on the screen in the figure. However, a slider on the right edge of the screen may be used to display additional fragments. An adjustable slider with a numeric scale is associated with each fragment shown.
- FIG. 6 is the screen of FIG. 5 after the user adjusted some of the sliders so as to assign weights to their associated fragments.
- FIG. 7 shows the results of the similarity search for the query compound with compounds in the database. The figure shows ten out of fifty compounds returned as part of the search.
- FIG. 8 shows a program flow chart for a specific implementation of the program in FIG. 3 in which the screens shown in FIG. 4 through FIG. 7 are used.
- FIG. 9 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of biological responses to various compounds.
- FIG. 10 is a MICROSOFT EXCEL spreadsheet divided into three parts, FIGS. 10 ( a ), ( b ), and ( c ), done so because the entire spreadsheet could not conveniently fit on a single drawing sheet.
- the data represented in the spreadsheet (the LEWI Data) represents the biological response test data of rats to various tranquilizers.
- FIG. 11 represents four screen prints of the program shown in FIG. 9 operating on the data shown in FIG. 10.
- a user submits a query to the system.
- the query may be submitted using different formats, but a query item must be able to be classified according to its descriptive properties.
- the descriptive properties may have inherent numeric values (e.g., test results, characteristic values, prices, ASCII values, checksums, etc.). Alternatively, they may have binary values (‘one’ indicating the presence of a feature and ‘zero’ indicating the absence of the feature).
- the query item is parsed according to its descriptive properties.
- the descriptive properties are analyzed by comparing various elements of the query item in sequence to standardized descriptive properties previously entered electronically into the computer. The characteristics of these descriptive properties may be pre-stored in an electronic dictionary or be generated dynamically by some program algorithm. However these descriptive properties are presented for comparison with the query item, the query item is analyzed for the presence of absence of a particular property, and its numeric value is noted.
- a quantized vector is formed wherein each element in the vector represents a value for a specific descriptive property. The quantized vector can be thought of as a “fingerprint” for the query item.
- the database contains entries of similarly describable items, each such item having been similarly pre-parsed into quantized vectors.
- the quantized vector (or “fingerprint”) for each entry is stored in the database and associated with its entry. Therefore, a distance may be computed between the vector representing the query item and each vector representing each and every item in the database. The closer the query item vector is to a vector representing an entry in the database, the more similar the query item is to that database entry.
- the sorted results may be stored for future use at the user's discretion.
- the computation of vector distances in step 3 above may be calculated, inter alia, as the standard Euclidean Distance, the Tanimoto Coefficient, the Hamming Distance, the Soergel Distance, the Dice Coefficient, or the Cosine Coefficient. Other types of similarity measurement may also be used.
- D A,B the distance between vectors A and B;
- j the index to a specific vector element
- n the number of elements in the vector
- x jA the value of the jth element in the A vector
- x jB the value of the jth element in the B vector.
- the Tanimoto Coefficient is determined by taking the quotient of the sum of the cross product of two vectors divided by the sum of the squares of the elements of the first vector added to the sum of the squares of the elements of the second vector less the cross product of the two vectors.
- Another name for the Tanimoto Coefficient is the Jaccard Coefficient.
- FIG. 2 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches for a generalized database. The methodology is as follows:
- the query item is parsed according to its descriptive properties using the same method that is used to calculate the descriptive properties of the entries stored in the database.
- a quantized vector (or “fingerprint”) for the query item is formed.
- the user is permitted to assign a weight or priority to each descriptive property of the quantized vector.
- a quantized weight vector is then formed in this manner.
- the weight vector has the same dimension (or number of elements) as the quantized vector representing the “fingerprint” of the query item.
- the assignment of weights can be done by presenting to the user a computer screen showing the query item, the descriptive properties of the query item, and a means to adjust weighting to assign importance values to the descriptive properties.
- the means to adjust weighting may be adjustable sliders, dials, text boxes, or any other controls that permit the user to interactively assign weights to the descriptive properties.
- the weight values representing the elements of the quantized weight vector may be obtained from a file created by the user.
- the sorted results may be stored for future use at the user's discretion.
- the units of assigned priority or weights can be arbitrary, and only their ratio to each other is important.
- the weights are unitless integers between zero and ten.
- a logarithmic scale may also be used. In that case, “1” would be the inflection point.
- Fractional weights (between “0” and “1”) should be in tenths. Fractional weights downscale priorities while weights above “1” upscale priorities.
- D A,B the distance between vectors A and B.
- w j the weight assigned to vector element j.
- one of the preferred uses for this methodology implemented as a computerized system is as a means to selectively search a database of chemical compounds. All chemical compounds can be structurally decomposed into recognizable fragments.
- Inorganic molecules are composed of atoms, and these atoms are bound to each other in a limited number of ways. The elements making up these molecules span the entire periodic table. However, their structures are simple. On the other hand, organic molecules comprise very few elements usually on the lower end of the periodic table (e.g., carbon, hydrogen, oxygen, nitrogen, etc.), but their structures are complex. Due to structural complexity and the ability of these elements to form large molecules, the number of possible organic molecules is virtually limitless.
- a search should be done in two stages.
- the first stage is a screening search. This stage eliminates most of the compounds in the database (possibly up to 99%).
- a screening search In order to determine whether one structure is a sub-structure of another, traditionally one performs an atom-by-atom match. Atoms are graphically superimposed upon one another to make sure that all the atoms match and that all the bonds between the atoms match. If one is a subset of the other, then there is a substructure match. However, this is a slow process.
- One possible representation of a complex molecule would be to parse it into a binary fragment vector. Each bit represents the presence of absence of a particular fragment in the dictionary. The vector element order is keyed to the fragment dictionary. Molecular parsing is performed by analyzing the chemical structure atom-by-atom and bond-by-bond that is associated with each atom. A search of the fragment dictionary is performed to find a match. When a match is found, the element for molecular descriptor vector corresponding to the matched fragment is set to 1.
- the binary vector may be represented logically as a string of bits or bytes or may have any conenient representation. These binary vectors then form a fingerprint for the chemical structure of the molecule. Each bit or fragment in the fingerprint is a dimension representing one row in the vector. Equal weighting is applied to all dimensions. Data processing systems that use this type of fingerprint implement search for similarity of new compounds with known existing compounds
- FIG. 3 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of organic chemical compounds.
- search query system for a chemical compound database, the following steps must be performed:
- Fingerprint the query —Use the dictionary of chemical structure fragments or an algorithm that generates the fragments to characterize the chemical structure.
- the seaching program determines which structure fragments, from the fragment dictionary, are present in the query structure.
- results of the similarity search may be stored for future use. The results are then displayed to the user. In the preferred embodiment, they would be shown as a graphical series of compounds sorted in order of decreasing importance. However, any method of user informative display could be used.
- FIG. 4 illustrates a computer monitor screen display of the chemical structure of query compound
- FIG. 5 shows the structure of the query compound having been “fingerprinted” using the twelve fragments
- FIG. 6 shows the same screen where the user has set the sliders for the
- FIG. 7 shows the results of the similarity search.
- the first ten compounds (of fifty) found to be similar to Trovafloxacin are shown arranged in order decreasing similarity.
- the molecule of compound labeled ⁇ fraction (1/50) ⁇ is deemed by the search criteria to be most similar. It differs only by substitution of fluorine (F) for the ethyl (CH 2 ) grouping.
- FIG. 8 shows a program flow chart for a specific implementation of the program in shown in FIG. 3 in which the screens shown in FIG. 4 through FIG. 7 are used.
- a printed program listing for this system can be found in the APPENDIX attached hereto.
- the system comprises a MICROSOFT VISUAL BASIC program and an associated ORACLE database.
- the ACCORD CHEMISTRY TOOLKIT available from ACCELRYS is used for certain chemistry related functions (primarily substructure matching).
- ORACLE database requires at least two tables in this implementation of the method:
- the VISUAL BASIC program is comprised of Forms, Modules, and Class Modules.
- Search (SearchAgent.frm)—This is the main form used in the application. Query input and function execution are primarily handled from this form.
- frmTune (Tune.frm)—The form used for tuning the fragment weights used in the chemical tunable search.
- frmLogin (Login.frm)—This is a small form used to take database name, user name, and password input from the user, and then use the information to open the ORACLE database.
- AccordSDKX ACORDX50.BAS
- ActiveX controls to use on forms in conjunction with the rest of the toolkit routines.
- Utilities (Utilities.BAS)—General purpose utility functions.
- cChemUtils (cChemUtils.cls)—Class containing chemistry utilities.
- the active form is displayed to the user.
- cmdOpenDbConnection_click( ) executes
- a new login form is created and displayed
- ORACLE database is opened using the Open method of the mOraCnn(ORACLE connection) object.
- Database record sets are opened and initialized
- Tuning form is loaded.
- the TunableKeys method of the chemistry object is called cChem.TunableKeys
- the TunableProductAnalogySearch method of the chemistry object is called using the tunable key arrays as input;
- Query structures are searched for certain heterocycles—If the heterocycles are present, copies of the query are made and edited to generate related molecules whose syntheses are related to the initial query—Similarity search will be performed on the query and related synthetically equivalent structures;
- ACCORD CHEMEXPLORER recognizes a wide range of formats—ISIS/DRAW, SKETCHFILES or CHEMDRAW files, MOLFILES, RXNFILES, SD and RD files, MICROSOFT WORD documents, EXCEL spreadsheets or the like. It looks, works and feels like the WINDOWS Finder.
- the ACCORD utilities are well known. They were used only for the implementation demonstrated herein, and the data processing routines contained in the ACCORD utilities are prior art. Similarly functioning routines may be easily substituted therefor.
- ISIS/DRAW was used in this implementation as a means to input a chemical structure into the program. This program is available from MDL®. It is one of many programs of this type.
- the data processing routines contained in ISIS/DRAW are prior art, and an equivalent utility may be substituted therefor.
- the above mentioned method may also be used to search for biological data.
- the values of the elements in the vector might not be binary.
- a biological response is a continuous variable.
- the binding strength of a drug to a particular receptor would have a specific numeric value, and it would be important to express that value in the vector.
- These measurements are important for drug competition experiments where relative binding strengths are relevant. They are also important for antibody and monoclonal antibody research that involve binding to specific epitope sites.
- the priority or weight that a user would apply to a characteristic such as binding strength for a particular receptor when performing a similarity search is independent of the actual data.
- Compounds can be described based upon biological response.
- FIG. 9 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of biological responses to various compounds.
- the implementation of the method described herein is in the form of a MICROSOFT EXCEL Spreadsheet with macros performing all of the necessary functions.
- a source code listing for this implementation appears in a section entitled, “COMPUTER PROGRAM LISTING—TUNABLE BIOLOGICAL SEARCH,” at the end of this application.
- the data shown in the spreadsheet of FIG. 10 has been separated into three parts, viz., FIGS. 10 ( a ), ( b ), and ( c ).
- the source of the data (hereinafter the LEWI Data) is the paper: Janssen, Paul A.
- Weightings are input by the user to indicate the relative importance that the user places on the importance of the associated biological test.
- [0189] A collection of data related to individual compounds and their associated biological responses.
- the data are contained within the same spreadsheet as the target input scores and the target weightings.
- the LEWI Data set contains data on 40 compounds.
- a control box has been set up to allow the user to select a compound from the data set to use as a starting point data entry. Biological activity values from a selected data set compound are loaded. Then the user can modify the values to suit his or her needs.
- cboCompoundNames_change( ) A combo box, cboCompoundNames, is loaded with the names of the compounds in the data set contained within the EXCEL worksheet.
- the biological data associated with the compound is loaded into the Target area at the top of the spreadsheet. This is purely a convenience for the user, not a critical feature.
- cmdEuclidLC50_click( ) This routine calculates the Euclidean Distance between the user-supplied target biological data values, and the biological data values for the compounds in the data set using the appropriate user-supplied weights. Biological data values are sorted according to the calculated Euclidean Distances.
- cmdTanimotoLC50_click( ) This routine calculates the Tanimoto Coefficient between the user-supplied target biological data values, and the biological data values for the compounds in the data set, using the appropriate user-supplied weights. Biological data values are sorted according to the calculated Tanimoto coefficients.
- FIG. 11 represents four screen prints of the program shown in FIG. 9 operating on the data shown in FIG. 10.
- the figure is divided into four parts, viz., FIGS. 11 ( a ), ( b ), ( c ), and ( d ).
- the data for all versions of FIG. 11 are those shown in FIG. 10( a ).
- FIG. 11( a ) the cursor is positioned on the Target compound, Aceperone (R3248) butyr (Row 17 —Column A).
- the chart shows the Tanimoto fingerprint for twelve test results on rats on a logarithmic scale. Note the “Euclid LC50” and “Tanimoto LC50” radio buttons. Since the target compound is only being compared with itself, only one fingerprint is shown.
- the cursor is positioned on Promazine phen (Row 18 —Column A).
- the chart compares two fingerprints. The darker graph is the fingerprint of Aceperone (R3248) butyr while the lighter graph is the fingerprint of Promazine phen. Note how closely the fingerprints of these adjacently sorted compounds resemble each other.
- FIG. 11( d ) the cursor is positioned on Trabuton (R1516) butyr (Row 29 —Column A).
- the darker graph is the fingerprint of Aceperone (R3248) butyr and the lighter graph is the fingerprint of Trabuton (R1516) butyr.
- the two fingerprint graphs are far less similar than those of FIGS. 11 ( b ) and ( c ).
- the systems, methods, and programs disclosed herein may be implemented in hardware or software, or a combination of both.
- the techniques are implemented in computer programs executing on programmable computers that each comprise a processor, a storage medium readable by said processor (including volatile and non-volatile memory and/or storage elements), at least one input device, and at least one output device.
- Program code is applied to data entered using the input device to perform the functions described and to generate output information.
- the output information is routed to one or more output devices.
- Each such computer program is preferably stored on a storage medium or device (e.g., CD-ROM, hard disk, magnetic tape, or magnetic diskette) that is readable by a general or special purpose programmable computer. Said computer program configures and operates the computer when the storage medium or device is read by the computer to perform the procedures described in this application.
- the system may also be considered to be implemented as a computer-readable storage medium, configured with a computer program, where the storage medium so configured causes a computer to operate in a specific and predefined manner.
- the present invention may be embodied in computer-readable media, such as floppy disks, ZIP or JAZ disks, conventional hard disks, optical media, CD-ROMS, Flash ROMS, nonvolatile ROM, RAM and any other equivalent computer memory device. It will be appreciated that the system, method of operation and product may vary as to the details of its configuration and operation without departing from the basic concepts disclosed herein.
- Some or all of the functionality may be implemented on an analog computer or device or on a hybrid digital/analog computer.
- User tuning i.e., the process whereby weights are assigned to the specific descriptive properties
- the analog processing devices used may be inter alia electrical, mechanical, optical, hydraulic, or any other means for analog processing. Analog-to-digital or digital-to-analog conversion may take place at any step of the process.
Abstract
The invention disclosed herein concerns a data processing means for user tunable and selectable searching of a database wherein the data contained therein have associated descriptive properties capable of being expressed in numeric form. A quantized vector representative of the descriptive properties is created for each item in the database. This quantized vector becomes the fingerprint for each data item. The user submits a query item to be matched against the database for similarity. A fingerprint is calculated for the query item. The user may then assign weights to the individual descriptive properties based upon perceived importance. A newly weighted fingerprint for the query item is then compared with the weighted fingerprints for all the data in the database. A list of results sorted in order of decreasing similarity is presented to the user. The user may then change the previously assigned weights and then re-run the similarity search. This may be done as often as necessary to achieve the desired results. The invention describes similarity searching in a generic database. However, this invention is particularly desirable in databases containing chemical compound structure data or biological response screening result data. The process described herein may be run stand alone or as a preliminary screening search in a large database. If used for screening, it can greatly reduce the amount of data required for exactly matching a query item to the data in the database.
Description
- This is a U.S. nonprovisional utility patent application that is also described in and claims the benefit of both U.S. provisional patent application Nos. 60/383,952 filed on May 29, 2002, entitled MACHINE, METHOD AND ARTICLE OF MANUFACTURE FOR A SELECTIVELY SEARCHING A DATABASE OF CHEMICAL COMPOUNDS, and 60/384,305 filed on May 30, 2002, entitled MACHINE, METHOD AND ARTICLE OF MANUFACTURE FOR SEARCHING A DATABASE OF BIOLOGICAL ACTIVITY SCREENING RESULTS, said provisional applications being incorporated by reference in their entirety herein.
- Accompanying this patent application is a CD-R, bearing the electronic title “Gange & Framroze,” the contents of which comprise a program listing in ASCII text file format entitled LISTING.TXT, being of size 86 KB and having been created on May 29, 2003. The contents of said CD-R is incorporated by reference herein. The CD-R is hand labeled as follows:
- Non-Provisional Patent Application Dr. David M. Gange & Dr. Bomi P. Framroze Filed: May 29, 2003 Docket No.: 51900-ROW2-01-001
- Attached to this application and made an integral part hereof is an APPENDIX comprising the identical program listing as that found on said CD-R.
- 1. Field of the Invention
- This invention relates to data processing and specifically enabling highly efficient searching of a database wherein the entries can be characterized using a set of one or more descriptive properties that can be expressed in numeric form.
- 2. Description of the Prior Art
- Modern database management systems have been used since the early 1970's. Commercial database systems mostly concentrate on finding exact matches. Searches are performed either to find a specific entry, or to find multiple entries having the same characteristics. Attributes of the data often become fields. An exact search can be made to find a specific person by looking up his name or social security number. A search can be performed to find multiple individuals having the same occupation or place of birth. Alternatively, one may locate all people born before a particular date. Whether a single entry or multiple entries are found, this type of query constitutes an exact search. Exact searches try to exactly or relationally match one or more fields in different data records.
- Similarity searching of databases has been around for several years. A similarity search compares two or more entries in their entirety to determine how closely they match one another. Consider the following simple database containing entries of various animals that fly:
- a house-fly
- a bat
- a hummingbird
- a dragonfly
- a flying fish
- a hawk
- The question: “Which are most similar?” is not meaningful without additional input. A proper answer requires input of the key dimension. If “feathers” represent the key dimension, then the hawk and the hummingbird are most similar. If “the ability to fly stationary” is the key dimension, then the dragonfly and the hummingbird are most similar. Other possible key dimensions could be metabolism, life span, body temperature, etc. Therefore, the answer to the question: “Which are most similar?” is subjective depending upon the preferences of the person supplying the answer.
- For a more complicated residential real estate database, a potential buyer would be looking to buy a home by expressing preferences that become the parameters for a similarity search. Such parameters might include number of bedrooms, type of house, asking price, neighborhood, quality of the local school system, property taxes, age restrictions on residents, home-owners' associations, etc. Currently, a real estate agent would first screen for homes having a specific most desirable characteristic (e.g., neighborhood or number of bedrooms). Then, the agent would look for the next desirable characteristic. The process would be repeated for each parameter, each search yielding a number of homes for consideration by the buyer. Where a particular home appears in the search results multiple times, it is more likely that the agent can make a sale. However, a binary feature vector may be created using these and other parameters, and a similarity search can be performed to match a potential buyer's preferences. This search would generate a list of homes approximating these preferences. A binary vector could indicate whether or not the buyer is interested in a particular feature. The homes can then be compared in their entirety by computing the mathematical distance between their feature vectors. In the rare instance where an exact match is found, the distance between the vectors would be zero. However, if the distance is not zero, the smaller the distance between the feature vectors of an ideal home and an available home, the more similar they are.
- This technique has been found to be particularly useful for searching in databases containing chemical structures. Databases of organic chemical compounds can contain millions of records. An atom-by-atom and bond-by-bond search becomes more difficult as the size of the molecule increases. Even were the organic molecules to be pre-classified according to specific features, queries to find exact matches of these features might still yield questionable and non-useful results. Furthermore, in large databases, exact match searching can be extremely time consuming. Similarity searching in a large chemical structure database is a method of screening for compounds which are closely related to one another but may not exactly match. Such a screening query can also be used to shorten the list of compounds to be matched thereby resulting in greatly reducing the overall query time. In fact, several screening searches using different algorithms may be performed that would yield a manageable list of chemical compounds that would then be exactly matched in an atom-by-atom and bond-by-bond search.
- A chemical structure similarity search may be performed by creating a chemical fragment dictionary or by using an algorithm that generates chemical structure fragments. A fragment consists of a grouping of atoms attached to one another by specific chemical bonds. All of the compounds in the database are parsed to determine whether or not a particular fragment is present. Associated with each compound is a binary vector. Each element of the vector represents the presence or absence of a specific fragment. This binary vector then serves as an index for that compound in the database. Now a search can be made to find a compound in the database that is similar to a substance that interests the user. The distance between the vector for the new substance and the vectors of compounds in the database can be calculated. The results can then be returned in order of decreasing similarity.
- In another application, chemical compounds, natural products, fermentation broths, and other substances are often tested for biological activity, or pharmacological activity. The results of these tests are often stored in electronic databases. Biologists and chemists are often interested in searching a database of biological screening results for substances with an activity profile similar to a given biological activity profile. For example, in the development of an antibiotic a scientist might be interested in substances showing good activity against gram-positive bacteria and one species of gram-negative bacteria. The profile of such a substance would have strong activity values for the several gram-positive and one gram-negative bacteria under consideration and weak activity values for the rest of the gram-negative species tested. In addition, physical properties of the substances, such as LogP, molecular weight, molecular size, pKa, and other physical properties may be considered. One method that can be used to examine biological screening results and property data is similarity searching.
- In this type of database, a feature vector or a vector of test results can be formed where binary values would not be used. In this case, it would be desirable to create a vector where a specific element would refer to a particular feature or test, and the vector would contain numeric values other than one or zero. The distance between vectors may be measured, and distances would represent the degree of similarity between entries in the database.
- Similarity searching using quantized vectors is prior art. However, prior art searches have been performed according to a fixed searching algorithm. In a chemical compound database, the user might wish to perform a similarity search based upon substructure comparisons, and the data processing system would provide an answer as a sorted list of compounds. When process development chemists search for similarity in chemical compounds, some parts of the molecule are more important to them than other parts. Therefore, when performing a search, they would be interested in establishing a higher search priority to the important substructures and a lower search priority to the less important substructures. Assignment of search priorities is arbitrary and based upon user preference. If priorities of substructure preferences can be dynamically assigned, then should the results of the search not be what the user desires, the user can reassign substructure priorities, thereby refining the search results. The units of assigned priority or weights can be arbitrary, and only their ratio to each other is important.
- In the previously mentioned residential real estate database, the similarity search revealed homes having all of the features that interested a potential buyer. Yet, for some potential buyers, certain items are more important than others. For example, for a family with four children, purchase of a house with five bedrooms and the quality of the school system might be more important than asking price and property taxes. Yet these latter features could also serve as influencing factors. In such a case, being able to assign higher priorities to certain features and lower priorities to other features would result in a more meaningful search.
- The underlying mathematics for this search is very broadly applicable. It can be used inter alia in biology and medical databases, in physiology databases, in anthropology databases, in photography databases, and in taxonomy databases. It is practical where a characterization vector can be applied to the description of the data.
- It is an object of the invention described herein to create a computerized system that will perform similarity searches in an electronic database where the entries have a set of one or more descriptive properties capable of being expressed in numeric form and wherein the user can assign weights or priorities to the descriptive properties so as to influence the similarity searches.
- The invention disclosed herein is a data processing product and method that permits computerized similarity searching of an electronic database using a quantization vector. The quantization vector, a linear array of descriptive properties of the entries in the database, is maintained by the system. Different datatype representations of the quantization vector may be implemented. The system examines the structure of a query item in terms of its known descriptive properties. During examination, the quantization vector is established. This vector represents the query item's “fingerprint.” The system then searches the entire database for identity or similarity to the query item by comparing the vectors. The system further permits the user to set numeric priorities for the descriptive properties in a user friendly environment, said priorities to be used in the search for entries that are similar to the query item. An object of the invention is to provide a simplified searching system for naive and infrequent users. In one of the embodiments presented herein, a computerized user tunable system is disclosed that selectively searches a database of chemical compounds. In another embodiment presented herein, a computerized user tunable system is disclosed that selectively searches a database of biological activity screening test results.
- FIG. 1 is an overview program flowchart showing a current computerized method of performing similarity searches for a generalized database. The method shown is prior art.
- FIG. 2 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches for a generalized database.
- FIG. 3 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of organic chemical compounds.
- FIG. 4 shows the screen view of the chemical structure of the query compound, Trovafloxacin, as drawn by the user with one of the standard chemical drawing software packages and input into the search program.
- FIG. 5 shows the structure of the query compound having been parsed or fingerprinted according to chemical structure fragments in a fragment dictionary. Only twelve fragments are shown on the screen in the figure. However, a slider on the right edge of the screen may be used to display additional fragments. An adjustable slider with a numeric scale is associated with each fragment shown.
- FIG. 6 is the screen of FIG. 5 after the user adjusted some of the sliders so as to assign weights to their associated fragments.
- FIG. 7 shows the results of the similarity search for the query compound with compounds in the database. The figure shows ten out of fifty compounds returned as part of the search.
- FIG. 8 shows a program flow chart for a specific implementation of the program in FIG. 3 in which the screens shown in FIG. 4 through FIG. 7 are used.
- FIG. 9 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of biological responses to various compounds.
- FIG. 10 is a MICROSOFT EXCEL spreadsheet divided into three parts, FIGS. 10(a), (b), and (c), done so because the entire spreadsheet could not conveniently fit on a single drawing sheet. The data represented in the spreadsheet (the LEWI Data) represents the biological response test data of rats to various tranquilizers.
- FIG. 11 represents four screen prints of the program shown in FIG. 9 operating on the data shown in FIG. 10.
- It is feasible to perform similarity searches in an electronic database of items, wherein said items possess a set of one or more descriptive properties (related to the items) that can be expressed in numeric form. Similarity searching in such a generalized database according to current technology may be performed in a computer using the method shown in FIG. 1.
- 1. A user submits a query to the system. The query may be submitted using different formats, but a query item must be able to be classified according to its descriptive properties. The descriptive properties may have inherent numeric values (e.g., test results, characteristic values, prices, ASCII values, checksums, etc.). Alternatively, they may have binary values (‘one’ indicating the presence of a feature and ‘zero’ indicating the absence of the feature).
- 2. The query item is parsed according to its descriptive properties. The descriptive properties are analyzed by comparing various elements of the query item in sequence to standardized descriptive properties previously entered electronically into the computer. The characteristics of these descriptive properties may be pre-stored in an electronic dictionary or be generated dynamically by some program algorithm. However these descriptive properties are presented for comparison with the query item, the query item is analyzed for the presence of absence of a particular property, and its numeric value is noted. A quantized vector is formed wherein each element in the vector represents a value for a specific descriptive property. The quantized vector can be thought of as a “fingerprint” for the query item.
- 3. The database contains entries of similarly describable items, each such item having been similarly pre-parsed into quantized vectors. The quantized vector (or “fingerprint”) for each entry is stored in the database and associated with its entry. Therefore, a distance may be computed between the vector representing the query item and each vector representing each and every item in the database. The closer the query item vector is to a vector representing an entry in the database, the more similar the query item is to that database entry.
- 4. The results are sorted in order of similarity.
- 5. The sorted results may be stored for future use at the user's discretion.
- 6. The sorted list of database entries is then presented to the user.
- The computation of vector distances in
step 3 above may be calculated, inter alia, as the standard Euclidean Distance, the Tanimoto Coefficient, the Hamming Distance, the Soergel Distance, the Dice Coefficient, or the Cosine Coefficient. Other types of similarity measurement may also be used. - The most familiar method for computing the distance between two vectors, thereby comparing their overall similarity, is to measure the Euclidean distance between them. This is done according to the well known equation:

- where:
- D A,B=the distance between vectors A and B;
- j=the index to a specific vector element;
- n=the number of elements in the vector;
- x jA=the value of the jth element in the A vector; and,
- x jB=the value of the jth element in the B vector.
- This is the familiar process of obtaining the difference between each of the elements in the same position in each vector, squaring that difference, and then taking the square root of the sum of the squares. Using this method, the distance between two identical vectors would be zero. The smaller the distance between two vectors, the greater their degree of similarity. The Euclidean Distance can be normalized to the range of 0 to 1 if the values of all attributes are normalized to this range and the results divided by n.
- To illustrate computation of the distance, assume two
binary dimension 5 vectors: A=1 1 0 1 1 andB 0 1 1 1 0. Using Equation [1], the calculation of Euclidean distance from A to B is as follows:A − B = C C * C Sum of C Distance 1 0 1 1 3 1.73 1 1 0 0 0 1 −1 1 1 1 0 0 1 0 1 1 - Another method for comparing similarity is to compute the Tanimoto Coefficient of the two vectors. This is done using the equation:

- where:
- S A,B=the Tanimoto Coefficient.
- The Tanimoto Coefficient is determined by taking the quotient of the sum of the cross product of two vectors divided by the sum of the squares of the elements of the first vector added to the sum of the squares of the elements of the second vector less the cross product of the two vectors. Another name for the Tanimoto Coefficient is the Jaccard Coefficient.
- Other distance computations such as the Hamming Distance, the Soergel Distance, the Dice Coefficient and the Cosine Coefficient are sometimes used to perform similarity searches and are prior art. The Hamming Distance is computed as:

- The Soergel Distance is computed as:

- The Dice Coefficient (also known as the Czekanowski Coefficient and the Sørenson Coefficient) is computed as:

- The Cosine Coefficient is computed as:

- The foregoing comparison methodologies represented by Equations [1] through [6] are only a few prior art techniques for similarity measurement between two quantized vectors. Of course, the measure of similarity depends upon the method of measurement. Changing the “fingerprint” changes the similarity. The results are dictated by the algorithm of the system. For the aforementioned prior art similarity measurement methods, there is generally no feedback, no user control over the results, and no possibility of iteratively improving the answer.
- The present invention improves the quality of the results obtained from similarity searching in the type of database discussed above. The results obtained from a search using the methodology disclosed herein should be more meaningful to the user. FIG. 2 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches for a generalized database. The methodology is as follows:
- 1. The user submits a query item to the system.
- 2. The query item is parsed according to its descriptive properties using the same method that is used to calculate the descriptive properties of the entries stored in the database. A quantized vector (or “fingerprint”) for the query item is formed.
- 3. The user is permitted to assign a weight or priority to each descriptive property of the quantized vector. A quantized weight vector is then formed in this manner. The weight vector has the same dimension (or number of elements) as the quantized vector representing the “fingerprint” of the query item. The assignment of weights can be done by presenting to the user a computer screen showing the query item, the descriptive properties of the query item, and a means to adjust weighting to assign importance values to the descriptive properties. The means to adjust weighting may be adjustable sliders, dials, text boxes, or any other controls that permit the user to interactively assign weights to the descriptive properties. Alternatively, the weight values representing the elements of the quantized weight vector may be obtained from a file created by the user.
- 4. The user adjusts the descriptive property weightings to suit his or her individual preferences.
- 5. Using the query item properties and weightings, similarity values between the query item and all of the items in the database are calculated using one of the standard similarity algorithms (Euclidean Distance, Tanimoto Coefficient, etc.)
- 6. Using the calculated similarity values, the database items are sorted.
- 7. The sorted results may be stored for future use at the user's discretion.
- 8. The sorted list of database items is presented to the user.
- 9. If the user so desires, the process may be repeated until the desired outcome is achieved.
- The units of assigned priority or weights can be arbitrary, and only their ratio to each other is important. In the system represented by reduction to practice of the present invention, the weights are unitless integers between zero and ten. However a logarithmic scale may also be used. In that case, “1” would be the inflection point. Fractional weights (between “0” and “1”) should be in tenths. Fractional weights downscale priorities while weights above “1” upscale priorities.
- In this type of system, using a weight vector, w, the Euclidean distance between the two vectors would be computed as:

- where:
- D A,B=the distance between vectors A and B; and,
- w j=the weight assigned to vector element j.
- To illustrate the new computation of the Euclidean distance as influenced by the assigned weights (w j) for the two previous
binary dimension 5 vectors: A=1 1 0 1 1 and B=0 1 1 1 0. The calculation of the new Euclidean distance from A to B is as follows:A − B = C C * C Weight Sum of C Distance 1 0 1 1 3 9 3 1 1 0 0 1 0 1 −1 1 3 1 1 0 0 1 1 0 1 1 3 - The new weighted Tanimoto Coefficient derived from Equation [2] would be computed according to Equation [8]:

- Likewise, the new weighted Hamming Distance derived from Equation [3] would be computed using Equation [9]:
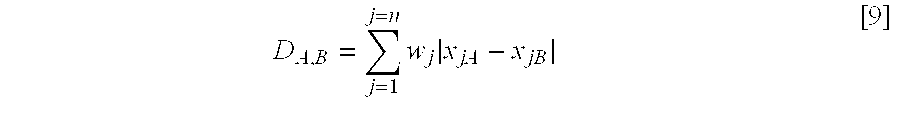
- the new weighted Soergel distance derived from Equation [4] would be computed using Equation [10]:

- the new weighted Dice coefficient derived from Equation [5] would be computed using Equation [11]:

- and the new weighted Cosine coefficient derived from Equation [6] would be computed using Equation [12]:

- As previously mentioned, one of the preferred uses for this methodology implemented as a computerized system is as a means to selectively search a database of chemical compounds. All chemical compounds can be structurally decomposed into recognizable fragments. Inorganic molecules are composed of atoms, and these atoms are bound to each other in a limited number of ways. The elements making up these molecules span the entire periodic table. However, their structures are simple. On the other hand, organic molecules comprise very few elements usually on the lower end of the periodic table (e.g., carbon, hydrogen, oxygen, nitrogen, etc.), but their structures are complex. Due to structural complexity and the ability of these elements to form large molecules, the number of possible organic molecules is virtually limitless. During product development of organic compounds, it is often important to search for other compounds having a similar molecular structure in an effort to adjust the new structure so as to predict its chemical, biological, and physical properties. Such a search is also necessary to insure that the new product does not infringe on patented products previously developed by others.
- Computerized searching of organic chemical compound databases has been around for decades. Many of these databases store molecular information according to their recognizable fragments. The data processing systems maintain a fragment dictionary, and all compounds input into the database are parsed so as to establish a relationship between fragments in the dictionary. The dictionary is instituted with a limited number of fragments well known to those skilled in the art. Many database searching tools use fragment dictionaries with a large number of entries, and others use fragment dictionaries with a smaller number of entries. A larger number of fragments makes it easier to define a complex molecule, but it increases the search time. A more rapid search engine requires fewer fragments in the dictionary.
- As the number of atoms in a complex organic molecule increase, the search time for identity and similarity in these databases grows exponentially. There is no upper bound as to the time required to secure a match. Therefore, a search should be done in two stages. The first stage is a screening search. This stage eliminates most of the compounds in the database (possibly up to 99%). In order to determine whether one structure is a sub-structure of another, traditionally one performs an atom-by-atom match. Atoms are graphically superimposed upon one another to make sure that all the atoms match and that all the bonds between the atoms match. If one is a subset of the other, then there is a substructure match. However, this is a slow process. In order to minimize the number of times that this process is performed, it is important to first apply a filter in order to perform a screening search. If a substructure match is found, all of the atoms and bonds between the atoms of the smaller structure will be contained within the larger structure. If there is a fragment dictionary, all of the fragments in the molecule to be matched must also be in the target molecule. Other fragments may also be present, but all the fragments in the substructure of both must be present in both molecules. So after performing the search using a binary vector of fragments, most of the molecules are eleminated. Then, an atom-by-atom search is performed on the remainder of the database.
- One possible representation of a complex molecule would be to parse it into a binary fragment vector. Each bit represents the presence of absence of a particular fragment in the dictionary. The vector element order is keyed to the fragment dictionary. Molecular parsing is performed by analyzing the chemical structure atom-by-atom and bond-by-bond that is associated with each atom. A search of the fragment dictionary is performed to find a match. When a match is found, the element for molecular descriptor vector corresponding to the matched fragment is set to 1. The binary vector may be represented logically as a string of bits or bytes or may have any conenient representation. These binary vectors then form a fingerprint for the chemical structure of the molecule. Each bit or fragment in the fingerprint is a dimension representing one row in the vector. Equal weighting is applied to all dimensions. Data processing systems that use this type of fingerprint implement search for similarity of new compounds with known existing compounds
- Searching using a fragment dictionary is commonly used in chemical database technology. Chemical Abstracts (CAS/STN) uses a dictionary of two-thousand fragment keys in the dictionary for a database of approximately ten-million chemical compounds. Most commercial databases use a dictionary of between five-hundred to one-thousand keys for a database of approximately one-million to two-million chemical compounds. The inventors have reduced the current system to practice. Said system uses a dictionary 230 fragment keys for a database of approximately seventy-thousand compounds. The performance of said system is excellent.
- FIG. 3 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of organic chemical compounds. In designing a search query system for a chemical compound database, the following steps must be performed:
- 1. Draw the query:—A user draws a chemical structure using a chemical structure drawing package such as ChemDraw, ISISDraw, or CASDraw. The resulting chemical structure, the qurey structure, is transferred to the program implementing the search.
- 2. Fingerprint the query:—Use the dictionary of chemical structure fragments or an algorithm that generates the fragments to characterize the chemical structure. The seaching program determines which structure fragments, from the fragment dictionary, are present in the query structure.
- 3. Allow the user to adjust the fragment weighting:—An electronic form displaying the structure fragments, from the fragment dictionary, which are present in the query structure is displayed to the user. For each structure fragment, there is also present a control that allows the user to define the importance of the fragment. The control on the form could be a slider with a numeric scale, a dial with a numeric scale, a text box allowing numeric value entry, or any graphic or text based system that would permit the user to interactively assign a weight to the importance of a particular structure fragment. Alternatively, the fragment weights may be input from a file.
- 4. Run the similarity search:—After the user has assigned the structure fragment weights, the similarity search is performed using a Euclidean distance, the Tanimoto coefficient, or other method of comparing the similarity between two vectors.
- 5. Return Results:—The results of the similarity search may be stored for future use. The results are then displayed to the user. In the preferred embodiment, they would be shown as a graphical series of compounds sorted in order of decreasing importance. However, any method of user informative display could be used.
- Using the above method of searching, the search may be biased in a direction defined by the user. The above tunable search process applied to organic chemical compounds is illustrated in FIG. 4 through FIG. 7. FIG. 4 illustrates a computer monitor screen display of the chemical structure of query compound

- Trovafloxacin (C 20H15F3N4O3) as input through one of the standard chemical drawing packages. FIG. 5 shows the structure of the query compound having been “fingerprinted” using the twelve fragments

- These are shown graphically on the lower portion of the screen. Sliders are shown next to each fragment all preset to their default values of 1. FIG. 6 shows the same screen where the user has set the sliders for the

- fragment to 6.5, the

- fragment to 7, and the

- to 7. FIG. 7 shows the results of the similarity search. In the figure the first ten compounds (of fifty) found to be similar to Trovafloxacin are shown arranged in order decreasing similarity. For example, the molecule of compound labeled {fraction (1/50)} is deemed by the search criteria to be most similar. It differs only by substitution of fluorine (F) for the ethyl (CH 2) grouping.
- FIG. 8 shows a program flow chart for a specific implementation of the program in shown in FIG. 3 in which the screens shown in FIG. 4 through FIG. 7 are used. A printed program listing for this system can be found in the APPENDIX attached hereto. The system comprises a MICROSOFT VISUAL BASIC program and an associated ORACLE database. In addition, the ACCORD CHEMISTRY TOOLKIT available from ACCELRYS is used for certain chemistry related functions (primarily substructure matching).
- The ORACLE database requires at least two tables in this implementation of the method:
- Fragment dictionary table containing
- ID numbers
- Chemical fragment structures in MOLFILE or other chemistry structure format
- Main compound table containing:
- ID numbers
- Chemical structures in MOLFILE or other chemistry structure format
- Chemical structure fingerprints (stored as binary bit string or other numeric format
- The VISUAL BASIC program is comprised of Forms, Modules, and Class Modules.
- Forms:
- 1. Search (SearchAgent.frm)—This is the main form used in the application. Query input and function execution are primarily handled from this form.
- 2. frmTune (Tune.frm)—The form used for tuning the fragment weights used in the chemical tunable search.
- 3. frmLogin (Login.frm)—This is a small form used to take database name, user name, and password input from the user, and then use the information to open the ORACLE database.
- Modules:
- 1. AccordSDK (ACCSDK50.BAS)—Module from Accelrys containing chemical structure handling routines.
- 2. AccordSDK Constraints (ACCSDK50CNST.BAS)—Definitions of constraints used by the chemical structure toolkit.
- 3. AccordSDK Fingerprints (ACCSDK50FP.BAS)—Fingerprint handling routines.
- 4. AccordSDKOld (ACCSDK50OLD.BAS)—Older versions of routines included for backward compatibility.
- 5. AccordSDKX (ACORDX50.BAS)—ActiveX controls to use on forms in conjunction with the rest of the toolkit routines.
- 6. Utilities (Utilities.BAS)—General purpose utility functions.
- Class Modules:
- 1. cChemDb (cChemDb.cls)—Class for handling chemistry related functions of the program.
- 2. cChemUtils (cChemUtils.cls)—Class containing chemistry utilities.
- 3. cError (cError.cls)—Error handling and logging class.
- The detailed program execution follows:
- 1. User starts the program.
- 2. Search.form_load( ) executes:
- Error handler is set up;
- Accelrys Accord license is checked and a new Accord session is created to allow use of the toolkit functions;
- New database connections are set up and an Accord chemistry object is created;
- The active form is displayed to the user.
- 3. User clicks “Open DB Connection”:
- cmdOpenDbConnection_click( ) executes;
- A new login form is created and displayed;
- User enters database connection information, username, and password and then clicks OK.
- 4. frmlogin.cmdOK_click( ) executes:
- User supplied information is loaded into variables and form is closed.
- 5. Search.fLogin_close(Cancel as Integer) executes:
- ORACLE database is opened using the Open method of the mOraCnn(ORACLE connection) object.
- 6. Search.mOraCnn_ConnectionComplete executes:
- Status of the ORACLE connection is returned;
- User is notified that DB is open;
- Database record sets are opened and initialized;
- User clicks OK button on status notice.
- 7. User clicks Tune button
- 8. Search.cmdTune_click( ) executes:
- Strings containing (fragment) key status information are initialized;
- Tuning form is loaded.
- 9. frmTune.Form_load( ) executes:
- Form checks (fragment) key status information and initializes sliders (user weighting controls) if needed.
- 10. User double clicks on a structure box—ISIS Draw starts.
- 11. User draws or reads a structure into ISIS Draw.
- 12. User clicks return box on ISIS Draw and returns structure to program.
- 13. frmTune.chmTune_changes( ) event fires:
- The arrays containing (fragment) key information are initialized;
- Any pictures of keys already present on the form are removed;
- If it does not already exist, a chemistry object is created;
- The TunableKeys method of the chemistry object is called cChem.TunableKeys;
- For every key found in the query the appropriate members of the key arrays are set;
- Key arrays are returned to the calling routine;
- For every key that has been set in the key arrays, a picture and a slider are loaded and displayed on the form.
- 14. The user adjusts the settings of the sliders to adjust the weightings used in the similarity calculations.
- 15. The user clicks the Search button.
- 16. frmTune.cmdTunableSearch_click( ) executes:
- The values of the sliders are loaded into the tunable key arrays;
- The structure contained in the Tune form is loaded into the query box of the Search form
- 17. Search.cmdTunableProductAnalogySearch_click( ) is called by frmTune:
- If it does not already exist, a chemistry object is created;
- When the object is created, the database connection is established and the record sets are opened;
- The TunableProductAnalogySearch method of the chemistry object is called using the tunable key arrays as input;
- cChem.TunableProductAnalogySearch initialization routines are fired;
- Query structures are searched for certain heterocycles—If the heterocycles are present, copies of the query are made and edited to generate related molecules whose syntheses are related to the initial query—Similarity search will be performed on the query and related synthetically equivalent structures;
- Calculate the similarity values between the query compound(s) and the molecules in the database, sort, and store the top 50 results;
- SearchDone event is raised;
- Search.cChem_SearchDone executes;
- Search complete message is displayed to the user;
- Answers are extracted from the database and displayed on the form.
- 18. User clicks “Done” button on Tune form:
- Tune form unloads.
- 19. User browses answers and runs another search at his or her discretion.
- The aforementioned data processing system was also implemented in the C++ and JAVA programming languages in addition to the MICROSOFT VISUAL BASIC implementation shown in the APPENDIX. As described above, several prior art software packages were used in the implementation of the system shown in the APPENDIX. The ORACLE database is well known to those with ordinary skill in the art. It was used only for the implementation discussed herein, and any comparable database management system may be substituted therefor. Similarly, ACCORD allows a user to search through documents and files for chemical structures and reactions. ACCORD CHEMEXPLORER recognizes a wide range of formats—ISIS/DRAW, SKETCHFILES or CHEMDRAW files, MOLFILES, RXNFILES, SD and RD files, MICROSOFT WORD documents, EXCEL spreadsheets or the like. It looks, works and feels like the WINDOWS Finder. The ACCORD utilities are well known. They were used only for the implementation demonstrated herein, and the data processing routines contained in the ACCORD utilities are prior art. Similarly functioning routines may be easily substituted therefor. Finally, ISIS/DRAW was used in this implementation as a means to input a chemical structure into the program. This program is available from MDL®. It is one of many programs of this type. The data processing routines contained in ISIS/DRAW are prior art, and an equivalent utility may be substituted therefor.
- The above mentioned method may also be used to search for biological data. In this case, the values of the elements in the vector might not be binary. A biological response is a continuous variable. For example, the binding strength of a drug to a particular receptor would have a specific numeric value, and it would be important to express that value in the vector. These measurements are important for drug competition experiments where relative binding strengths are relevant. They are also important for antibody and monoclonal antibody research that involve binding to specific epitope sites. However, the priority or weight that a user would apply to a characteristic such as binding strength for a particular receptor when performing a similarity search is independent of the actual data. Compounds can be described based upon biological response. Plotting the biological response over a series of tests produces a graph possessing a characteristic shape. A database biological compounds may be probed for those having characteristic shapes that are similar. Often compounds having a similar profile would have similar modes of action. In this case, a weighted search would provide a significant advantage. The inventors have reduced this technique to practice with excellent results by performing such a search with a highly descriptive biological compound model based upon biological response.
- FIG. 9 is an overview program flowchart showing the computerized method of the invention disclosed herein being used to perform similarity searches in a database of biological responses to various compounds. The implementation of the method described herein is in the form of a MICROSOFT EXCEL Spreadsheet with macros performing all of the necessary functions. A source code listing for this implementation appears in a section entitled, “COMPUTER PROGRAM LISTING—TUNABLE BIOLOGICAL SEARCH,” at the end of this application. The data shown in the spreadsheet of FIG. 10 has been separated into three parts, viz., FIGS. 10(a), (b), and (c). The source of the data (hereinafter the LEWI Data) is the paper: Janssen, Paul A. J.; Niemegeers, Carlos J. E.; and Schellekens, Karel H. L.; “Is it Possible to Predict the Clinical Effects of Neuroleptic Drugs (Major Tranquillizers) from Animal Data?—Part I: ‘Neuroleptic activity spectra’ for rats”; from the Janssen Pharmaceutic n.v., Research Laboratoria, Beerse (Belgium), Drug Research,
Vol 15,Heft 2, 1965, pp 104-117. A copy of this paper is provided with this application, and is incorporated by reference as non-essential material in its entirety herein. - The following features are needed:
- 1. A row of target biological activity scores to use as a target in the similarity search. In the LEWI Data, there are twelve measured responses.
- 2. A row of weighting values to apply to the target biological responses. Weightings are input by the user to indicate the relative importance that the user places on the importance of the associated biological test.
- 3. A collection of data related to individual compounds and their associated biological responses. For the purposes of this implementation, the data are contained within the same spreadsheet as the target input scores and the target weightings. The LEWI Data set contains data on 40 compounds.
- The program works as follows:
- 1. After the user has entered the biological response values, and the associated biological response weightings, the user initiates the calculation by pressing the button for Euclidean Distance or Tanimoto Coefficient.
- 2. Using the user-supplied biological activity target values, and user-supplied target weightings, the similarity values are calculated for each compound in the data set.
- 3. The calculated similarity values for each compound in the data set is stored.
- 4. After the similarity values for all the compounds in the data set have been calculated, the data is then sorted in order of decreasing similarity.
- For the convenience of the user, other features have been added:
- To simplify the entry of target biological activity values, a control box has been set up to allow the user to select a compound from the data set to use as a starting point data entry. Biological activity values from a selected data set compound are loaded. Then the user can modify the values to suit his or her needs.
- When scrolling through the sorted output data, a graph showing the relationship between the input target and the data set compound data currently selected can be shown.
- The routines are as follows:
- 1. cboCompoundNames_change( )—A combo box, cboCompoundNames, is loaded with the names of the compounds in the data set contained within the EXCEL worksheet. When the user selects a compound name from the combo box, the biological data associated with the compound is loaded into the Target area at the top of the spreadsheet. This is purely a convenience for the user, not a critical feature.
- 2. cmdEuclidLC50_click( )—This routine calculates the Euclidean Distance between the user-supplied target biological data values, and the biological data values for the compounds in the data set using the appropriate user-supplied weights. Biological data values are sorted according to the calculated Euclidean Distances.
- 3. cmdEuclidSpec_click( )—Not Used!
- 4. cmdTanimotoLC50_click( )—This routine calculates the Tanimoto Coefficient between the user-supplied target biological data values, and the biological data values for the compounds in the data set, using the appropriate user-supplied weights. Biological data values are sorted according to the calculated Tanimoto coefficients.
- 5. cmdTanimotoSpec_click( )—Not Used!
- 6. Worksheet_activate( )—Loads the combo box with the compound names from the data set. Reset all weightings to 1. This routine fires when the user opens the spreadsheet.
- 7. Worksheet_SelectionChange(by Val Target as Range)—This routine checks to see if the selection is within the dataset range. If it is within the range, then a chart showing the biological responses from the Target and the selected compound are shown. This routine uses the makeChart routine to create the charts.
- 8. makeChart(by Val as long)—This routine creates a chart using the Target biological responses and the biological data from a compound in the data set. This routine is called by Worksheet_SelectionChange.
- FIG. 11 represents four screen prints of the program shown in FIG. 9 operating on the data shown in FIG. 10. The figure is divided into four parts, viz., FIGS. 11(a), (b), (c), and (d). The data for all versions of FIG. 11 are those shown in FIG. 10(a).
- In FIG. 11( a), the cursor is positioned on the Target compound, Aceperone (R3248) butyr (
Row 17—Column A). The chart shows the Tanimoto fingerprint for twelve test results on rats on a logarithmic scale. Note the “Euclid LC50” and “Tanimoto LC50” radio buttons. Since the target compound is only being compared with itself, only one fingerprint is shown. - In FIG. 11( b), the cursor is positioned on Promazine phen (
Row 18—Column A). Here, the chart compares two fingerprints. The darker graph is the fingerprint of Aceperone (R3248) butyr while the lighter graph is the fingerprint of Promazine phen. Note how closely the fingerprints of these adjacently sorted compounds resemble each other. - In FIG. 11( c), the cursor is positioned on Levomepromazine phen (
Row 25—Column A). Once again there are two fingerprints being compared where the darker graph is the fingerprint of Aceperone (R3248) butyr and the lighter graph is the fingerprint of Levomepromazine phen. Note here that the two graphs are far less similar than those of FIG. 11(b). - In FIG. 11( d), the cursor is positioned on Trabuton (R1516) butyr (
Row 29—Column A). The darker graph is the fingerprint of Aceperone (R3248) butyr and the lighter graph is the fingerprint of Trabuton (R1516) butyr. Here, the two fingerprint graphs are far less similar than those of FIGS. 11(b) and (c). - The systems, methods, and programs disclosed herein may be implemented in hardware or software, or a combination of both. Preferably, the techniques are implemented in computer programs executing on programmable computers that each comprise a processor, a storage medium readable by said processor (including volatile and non-volatile memory and/or storage elements), at least one input device, and at least one output device. Program code is applied to data entered using the input device to perform the functions described and to generate output information. The output information is routed to one or more output devices.
- Each such computer program is preferably stored on a storage medium or device (e.g., CD-ROM, hard disk, magnetic tape, or magnetic diskette) that is readable by a general or special purpose programmable computer. Said computer program configures and operates the computer when the storage medium or device is read by the computer to perform the procedures described in this application. The system may also be considered to be implemented as a computer-readable storage medium, configured with a computer program, where the storage medium so configured causes a computer to operate in a specific and predefined manner. The present invention may be embodied in computer-readable media, such as floppy disks, ZIP or JAZ disks, conventional hard disks, optical media, CD-ROMS, Flash ROMS, nonvolatile ROM, RAM and any other equivalent computer memory device. It will be appreciated that the system, method of operation and product may vary as to the details of its configuration and operation without departing from the basic concepts disclosed herein.
- Some or all of the functionality may be implemented on an analog computer or device or on a hybrid digital/analog computer. User tuning (i.e., the process whereby weights are assigned to the specific descriptive properties) is an area of the computerized process most applicable to analog processing. The analog processing devices used may be inter alia electrical, mechanical, optical, hydraulic, or any other means for analog processing. Analog-to-digital or digital-to-analog conversion may take place at any step of the process.
- Based upon the disclosure of the systems, processes, methods, and computer programs herein, as well as the foregoing discussion of apparatus considerations, it is apparent that one skilled in the art would be able to implement the present invention on any of the apparatuses or devices mentioned above without undue experimentation.
1 COMPUTER PROGRAM LISTING - TUNABLE BIOLOGICAL SEARCH 2 Written to be executed within a Microsoft Excel Spreadsheet, using MS Excel Visual Basic. 3 Private Sub cboCompoundNames_Change() 4 ′Copy the data into the appropriate boxes 5 Dim i As Long, rowNumber As Long, rng As Range, name As String 6 If cboCompoundNames.ListIndex = −1 Then 7 ′Do Nothing, empty box 8 Else 9 ′Get LC50 data 10 name = cboCompoundNames.Text 11 Set rng = Range(“A17:A56”).Find(name) 12 rowNumber = rng.row 13 ′Set the title for the rows in header area 14 Me.Cells(3, 1) = CStr(Me.Cells(rowNumber, 1)) & “ LC50” 15 Me.Cells)5, 1) = “Weighting (0 - 9)” 16 For i = 2 To 13 17 ′copy LC50 values into row 3 18 Me.Cells(3, i) = Me.Cells(rowNumber, i) 19 ′copy standard weights into row 5 20 Me.Cells(5, i) = 1# 21 Next 22 End If 23 End Sub 24 Private Sub cmdEuclidLC50_Click() 25 Dim valueRow As Long, rowCount As Long, columnCoumt As Long 26 Dim SumOfSquares As Double, targetCellvalue As Double, testCellValue As Doube 27 Dim Difference As Double, EuclideanDistance As Double, weight(1 To 20) As Double 28 Dim i As Long, j As Long, weightRow As Long, rng As Range 29 valueRow = 3 30 weightRow = 5 31 columnCount = 14 32 ′Data in rows 17 to 56 33 For i = 17 To 56 34 SumOfSquares = 0 35 ′Include first column in data 36 For j = 2 To 13 37 weight(j) = Me.Cells(weightRow, j) 38 targetCellvalue = Me.Cells(valueRow, j) 39 testCellValue = Me.Cells(i, j) 40 Difference = weight(j) * (targetCellValue − testCellValue) 41 SumofSquares = SumofSquares + (Difference * Difference) 42 Next j 43 ′Take the square root 44 EuclideanDistance = Sqr(SumOfSquares) 45 Me.Cells(i, columnCount + 1) = EuclideanDistance 46 Next i 47 ′Now sort the results 48 Set rng = Range(“A16:P56”) 49 rng.Select 50 rng.sort Key1:=Ramge(“016”), Order1:=xlAscending, Header:=xlYes, _ 51 MatchCase:=False, OrderCustom:=1, Orientation:=xlRows 52 Set rng = Range(“A17”) 53 rng.Select 54 End Sub 55 56 Private Sub cmdTanimotoLC50_Click() 57 Dim valueRow As Long, rowCount As Long, columnCount As Long 58 Dim SumASquared As Double, SumBSquared As Double, SumAtimesB As Double 59 Dim i As Long, j As Long, tanimoto As Double, weight(1 To 20) As Double 60 Dim weightRow As Long, rng As Range 1 valueRow = 3 2 weightRow = 5 3 columnCount = 14 4 ′Calculate the Tanimoto Coefficient 5 ′Use all columns when operating on the untransformed data. 6 SumASquared = 0 7 For j = 2 To 13 8 weight(j) = Me.Cells(weightRow, j) 9 SumASquared = SumASquared + weight(j) * (Me.Cells(valueRow, j) * Me.Cells(valueRow, 10 j)) 11 Next j 12 For i = 17 To 56 13 SumBSquared = 0 14 SumAtimesB = 0 15 For j = 2 To 13 16 weight(j) = Me.Cells(weightRow, j) 17 SumBSquared = SumBSquared + weight(j) * (Me.Cells(i, j) * Me.Cells(i, j)) 18 SumAtimesB = SumAtimesB + weight(j) * (Me.Cells(valueRow, j) * Me.Cells(i, j)) 19 Next j 20 tanimoto = SumAtimesB / (SumASquared + SumBSquared − SumAtimesB) 21 Me.Cells(i, columnCount + 2) = tanimoto 22 Next i 23 ′Now sort the results 24 Set rng = Range(“A16:P56”) 25 rng.Select 26 rng.sort Key1:=Range(“P16”), Order1:=xlDescending, Header:=xlYes, _ 27 MatchCase:=False, OrderCustom:=1, Orientation:=xlRows 28 Set rng = Range(“A17”) 29 rng.Select 30 End Sub 31 32 Private Sub Worksheet_Activate() 33 Dim i As Long 34 cboCompoundNames.Clear 35 ′Fill the combo box with the compound names 36 If cboCompoundNames.ListCount = 0 Then 37 For i = 3 To 42 38 cboCompoundNames.AddItem Sheet1.Cells(i, 1).value 39 Next i 40 End If 41 ′Fill the weighting cells with the standard value (1.00) 42 For i = 2 To 14 43 Me.Cells(4, i) = 1# 44 Next 45 End Sub 46 47 Private Sub Worksheet_SelectionChange(ByVal Target As Range) 48 ′Look to see if we are in the LC50 rows or spectral rows and then put up a chart 49 Dim newrow As Long 50 newrow = Target.row 51 If newrow <> oldrow Then 52 ′make a chart 53 makeChart (newrow) 54 End If 55 oldrow = newrow 56 End Sub 57 Private Sub makeChart(ByVal row As Long) 58 Dim co As ChartObject, cw As Long, rh As Long 59 Dim rng As Range, oCell As Range, selection As String 1 Dim MinimumValue As Double 2 ′Get rid of old charts 3 If ActiveSheet.ChartObjects.Count > 0 Then 4 Do 5 ActiveSheet.ChartObjects.Delete 6 Loop Until ActiveSheet.ChartObjects.Count = 0 7 EndIf 8 If row < 57 And row > 16 Then 9 ′Charts for LC50 similarities 10 selection = “A3:M3, ” & “A” & row & “:M” & row 11 ′Rows(“2:2”).Select 12 ′Rows(CStr(row) & “:” & CStr(row)).Select 13 ′Create column width and row height units 14 cw = Columns(2).Width ′In points 15 rh = Rows(1).Height 16 ′Place chart with respect to upper left corner of A1 17 ′ ( Left, Top, Width, Height ) 18 Set co = ActiveSheet.ChartObjects.Add(cw * 7.5, rh * 5.5, cw * 7, rh * 18) 19 co.name = “Test Chart” 20 ′Set the chart type 21 ′co.Chart.ChartType = xlXYScatterSmooth 22 ′co.Chart.ChartType = xlLine 23 co.Chart.ChartType = xlLineMarkers 24 co.Chart.HasLegend = False 25 ′Attach the data to the chart 26 ′ Source:=ActiveSheet.Range(“B1;I1”, selection), 27 co.Chart.SeriesCollection.Add _ 28 Source:=ActiveSheet.Range (selection), 29 rowcol:=xlRows 30 co.Chart.HasTitle = False 31 ′These are the standard default values 32 With co.Chart 33 .HasAxis(xlCategory, xlPrimary) = True 34 .HasAxis(xlCategory, xlSecondary) = False 35 .HasAxis(xlValue, xlPrimary) = True 36 .HasAxis(xlValue, xlSecondary) = False 37 End With 38 ′Get the names from the first row, category names missing from scatter plot 39 co.Chart.Axes(xlCategory).CategoryNames = _ 40 ActiveSheet.Range (“bl:ml”) 41 ′co.Chart.Axes(xlvalue).CrossAt = xlAxisCrossesMinimum ′This doesn't work here 42 ′MinimumValue = co.Chart.Axes(xlValue, xlPrimary).MinimumScale 43 co.Chart.Axes(xlValue, xlPrimary).MinimumScale = −4# 44 co.Chart.Axes(xlValue, xlPrimary).MaximumScale = 2# 45 co.Chart.Axes(xlValue).CrossesAt = −4# 46 co.Chart.Axes(xlValue).HasTitle = True 47 ′co.Chart.Axes(xlValue).AxisTitle.Orientation = xlHorizontal 48 ′co.Chart.Axes(xlValue).AxisTitle.Orientation = xlVertical 49 co.Chart.Axes(xlValue).AxisTitle.Orientation = xlUpward 50 ′co.Chart.Axes(xlValue).AxisTitle.Orientation = xlDownward 51 co.Chart.Axes(xlValue).AxisTitle.Text = “Log(1/C)” 52 add a data table to the bottom 53 ′datatable.doesn't appear in scatter plots,does appear in line graphs 54 ′co.Chart.HasDataTable = True 55 ′Doesn't affect a line graph, does affect scatter plot 56 co.Chart.SeriesCollection(1).MarkerSize = 5 57 co.Chart.SeriesCollection(1).MarkerStyle = xlMarkerStyleDiamond 58 End If 59 End Sub -







































Claims (20)
1. A method for searching an electronic database of data,
wherein said data has associated with them a set of one or more calculated descriptive properties related to said data; and
wherein said descriptive properties are capable of being expressed in numeric form;
said method comprising:
a) accepting a query datum submitted electronically by a user;
b) electronically calculating a set of one or more descriptive properties of said query datum wherein the descriptive properties of said query datum are capable of being expressed in numeric form, are of the same number and arrangement, and are calculated in the same manner as said descriptive properties of the data in said database;
c) allowing the user to electronically examine the calculated descriptive properties of said query datum;
d) electronically setting a weight for every descriptive property to unity, said weight being an importance value for that particular descriptive property;
e) allowing the user to change said weights for any or all of the descriptive properties to other numeric values, said other numeric values being set at the user's discretion;
f) electronically calculating a similarity value to the query datum for all data in the database according to a method comprising:
factoring in the user assigned weights of the descriptive properties to both the query datum and each datum in the database thereby forming a weighted query datum and a weighted database datum;
computing a quantized vector distance, or equivalent indicator or coefficient, between said weighted query dataum and said weighted database datum; and,
assigning said quantized vector distance, or equivalent indicator or coefficient, to the similarity value;
g) presenting a list of data from said database to the user wherein said data is sorted in order of their similarity values;
h) repeating steps f) and g) of this method at the user's discretion as many times as the user desires.
2. The method according to claim 1 wherein a user can assign weights to said descriptive properties by manipulating objects on a computer screen.
3. The method according to claim 2 wherein said objects are sliders with numeric scales.
4. The method according to claim 2 wherein said objects are dials with numeric scales.
5. The method according to claim 2 wherein said objects are text boxes allowing numeric entry.
6. The method according to claim 1 wherein said similarity value is calculated using a weighted Euclidean Distance between said quantized vectors of the descriptive properties.
7. The method according to claim 1 wherein said similarity value is calculated using a weighted Hamming Distance between said quantized vectors of the descriptive properties.
8. The method according to claim 1 wherein said similarity value is calculated using a weighted Soergel Distance between said quantized vectors of the descriptive properties.
9. The method according to claim 1 wherein said similarity value is calculated using a weighted Tanimoto Coefficient between said quantized vectors of the descriptive properties.
10. The method according to claim 1 wherein said similarity value is calculated using a weighted Dice Coefficient between said quantized vectors of the descriptive properties.
11. The method according to claim 1 wherein said similarity value is calculated using a weighted Cosine Coefficient between said quantized vectors of the descriptive properties.
12. The method according to claim 1 wherein said data in said database is representative of structures of chemical compounds and wherein said query datum is also representative of the structure of a chemical compound.
13. The method according to claim 12 wherein said qurey datum is generated by a chemical structure drawing package.
14. The method according to claim 12 wherein said descriptive properties of said database data and query datum are characterized by assigned structure fragments.
15. The method according to claim 14 wherein the numeric values of said descriptive properties are set to either one or zero, a one representing the presence of the structure fragment associated with a particular descriptive property, and a zero representing the absence of said structure fragment.
16. The method according to claim 14 wherein the structure fragments are contained within and referenced in an electronic dictionary.
17. The method according to claim 14 wherein the structure fragments are generated by an algorithm.
18. The method according to claim 1 wherein said data in said database is representative of biological activity screening results and wherein said query datum is also representative of biological activity screening results.
19. The method according to claim 18 further comprising:
a) a user entering biological response values for known screening results;
b) a user entering the biological response values for a target query item;
c) a user entering weights for each of the biological response values;
d) a user selectively designating a method to be used to calculate similarity;
20. The method according to claim 1 further comprising storing the sorted calculated similarity results for further use.
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US10/448,168 US20040006559A1 (en) | 2002-05-29 | 2003-05-28 | System, apparatus, and method for user tunable and selectable searching of a database using a weigthted quantized feature vector |
| US10/516,061 US7251643B2 (en) | 2003-05-28 | 2004-05-25 | System, apparatus, and method for user tunable and selectable searching of a database using a weighted quantized feature vector |
| PCT/US2004/016322 WO2004107217A1 (en) | 2003-05-28 | 2004-05-25 | System, apparatus, and method for user tunable and selectable searching of a database using a weighted quantized feature vector |
| EP04753194A EP1631925A4 (en) | 2003-05-28 | 2004-05-25 | System, apparatus, and method for user tunable and selectable searching of a database using a weighted quantized feature vector |
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US38395202P | 2002-05-29 | 2002-05-29 | |
| US38430502P | 2002-05-30 | 2002-05-30 | |
| US10/448,168 US20040006559A1 (en) | 2002-05-29 | 2003-05-28 | System, apparatus, and method for user tunable and selectable searching of a database using a weigthted quantized feature vector |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US10/516,061 Continuation-In-Part US7251643B2 (en) | 2003-05-28 | 2004-05-25 | System, apparatus, and method for user tunable and selectable searching of a database using a weighted quantized feature vector |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| US20040006559A1 true US20040006559A1 (en) | 2004-01-08 |
Family
ID=33489401
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US10/448,168 Abandoned US20040006559A1 (en) | 2002-05-29 | 2003-05-28 | System, apparatus, and method for user tunable and selectable searching of a database using a weigthted quantized feature vector |
| US10/516,061 Expired - Fee Related US7251643B2 (en) | 2003-05-28 | 2004-05-25 | System, apparatus, and method for user tunable and selectable searching of a database using a weighted quantized feature vector |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US10/516,061 Expired - Fee Related US7251643B2 (en) | 2003-05-28 | 2004-05-25 | System, apparatus, and method for user tunable and selectable searching of a database using a weighted quantized feature vector |
Country Status (3)
| Country | Link |
|---|---|
| US (2) | US20040006559A1 (en) |
| EP (1) | EP1631925A4 (en) |
| WO (1) | WO2004107217A1 (en) |
Cited By (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050021490A1 (en) * | 2003-07-25 | 2005-01-27 | Chen Francine R. | Systems and methods for linked event detection |
| US20050021324A1 (en) * | 2003-07-25 | 2005-01-27 | Brants Thorsten H. | Systems and methods for new event detection |
| US20060069982A1 (en) * | 2004-09-30 | 2006-03-30 | Microsoft Corporation | Click distance determination |
| US20060074903A1 (en) * | 2004-09-30 | 2006-04-06 | Microsoft Corporation | System and method for ranking search results using click distance |
| US20060074871A1 (en) * | 2004-09-30 | 2006-04-06 | Microsoft Corporation | System and method for incorporating anchor text into ranking search results |
| US20060136411A1 (en) * | 2004-12-21 | 2006-06-22 | Microsoft Corporation | Ranking search results using feature extraction |
| US20060200460A1 (en) * | 2005-03-03 | 2006-09-07 | Microsoft Corporation | System and method for ranking search results using file types |
| US20060294100A1 (en) * | 2005-03-03 | 2006-12-28 | Microsoft Corporation | Ranking search results using language types |
| US20070016612A1 (en) * | 2005-07-11 | 2007-01-18 | Emolecules, Inc. | Molecular keyword indexing for chemical structure database storage, searching, and retrieval |
| US20070038622A1 (en) * | 2005-08-15 | 2007-02-15 | Microsoft Corporation | Method ranking search results using biased click distance |
| US20080016051A1 (en) * | 2001-12-21 | 2008-01-17 | Andrew Schiller | Method for analyzing demographic data |
| US20080208791A1 (en) * | 2007-02-27 | 2008-08-28 | Madirakshi Das | Retrieving images based on an example image |
| US20090106221A1 (en) * | 2007-10-18 | 2009-04-23 | Microsoft Corporation | Ranking and Providing Search Results Based In Part On A Number Of Click-Through Features |
| US20090106223A1 (en) * | 2007-10-18 | 2009-04-23 | Microsoft Corporation | Enterprise relevancy ranking using a neural network |
| US20090106235A1 (en) * | 2007-10-18 | 2009-04-23 | Microsoft Corporation | Document Length as a Static Relevance Feature for Ranking Search Results |
| US7587408B2 (en) | 2002-03-21 | 2009-09-08 | United States Postal Service | Method and system for storing and retrieving data using hash-accessed multiple data stores |
| US20090259651A1 (en) * | 2008-04-11 | 2009-10-15 | Microsoft Corporation | Search results ranking using editing distance and document information |
| US20100017403A1 (en) * | 2004-09-27 | 2010-01-21 | Microsoft Corporation | System and method for scoping searches using index keys |
| US20100145896A1 (en) * | 2007-08-22 | 2010-06-10 | Fujitsu Limited | Compound property prediction apparatus, property prediction method, and program for implementing the method |
| US20100169375A1 (en) * | 2008-12-29 | 2010-07-01 | Accenture Global Services Gmbh | Entity Assessment and Ranking |
| US20100217770A1 (en) * | 2007-09-10 | 2010-08-26 | Peter Ernst | Method for automatically sensing a set of items |
| US8738635B2 (en) | 2010-06-01 | 2014-05-27 | Microsoft Corporation | Detection of junk in search result ranking |
| US20140316768A1 (en) * | 2012-12-14 | 2014-10-23 | Pramod Khandekar | Systems and methods for natural language processing |
| EP2361410A4 (en) * | 2008-12-05 | 2015-11-11 | Decript Inc | Method for creating virtual compound libraries within markush structure patent claims |
| US9495462B2 (en) | 2012-01-27 | 2016-11-15 | Microsoft Technology Licensing, Llc | Re-ranking search results |
| US20170132305A1 (en) * | 2015-11-09 | 2017-05-11 | Industrial Technology Research Institute | Method for finding crowd movements |
| US20180253426A1 (en) * | 2017-03-03 | 2018-09-06 | Perkinelmer Informatics, Inc. | Systems and methods for searching and indexing documents comprising chemical information |
| US20190377720A1 (en) * | 2013-09-24 | 2019-12-12 | Qliktech International Ab | Methods and systems for data management and analysis |
| CN110569421A (en) * | 2019-08-22 | 2019-12-13 | 上海摩库数据技术有限公司 | search method based on chemical industry |
| CN110569420A (en) * | 2019-08-22 | 2019-12-13 | 上海摩库数据技术有限公司 | Search method based on chemical industry |
| US20210073732A1 (en) * | 2019-09-11 | 2021-03-11 | Ila Design Group, Llc | Automatically determining inventory items that meet selection criteria in a high-dimensionality inventory dataset |
| US11373734B2 (en) * | 2012-05-18 | 2022-06-28 | Georgetown University | Methods and systems for populating and searching a drug informatics database |
Families Citing this family (31)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8024349B1 (en) * | 2005-07-25 | 2011-09-20 | Shao Henry K | String-based systems and methods for searching for real estate properties |
| CA2549536C (en) * | 2006-06-06 | 2012-12-04 | University Of Regina | Method and apparatus for construction and use of concept knowledge base |
| US8005823B1 (en) * | 2007-03-28 | 2011-08-23 | Amazon Technologies, Inc. | Community search optimization |
| US8275681B2 (en) | 2007-06-12 | 2012-09-25 | Media Forum, Inc. | Desktop extension for readily-sharable and accessible media playlist and media |
| US8146120B2 (en) * | 2007-10-08 | 2012-03-27 | Jaman.Com, Inc. | Multi-criteria rating and searching system |
| US9058378B2 (en) | 2008-04-11 | 2015-06-16 | Ebay Inc. | System and method for identification of near duplicate user-generated content |
| US8615707B2 (en) * | 2009-01-16 | 2013-12-24 | Google Inc. | Adding new attributes to a structured presentation |
| US8412749B2 (en) | 2009-01-16 | 2013-04-02 | Google Inc. | Populating a structured presentation with new values |
| US8977645B2 (en) * | 2009-01-16 | 2015-03-10 | Google Inc. | Accessing a search interface in a structured presentation |
| US20100185651A1 (en) * | 2009-01-16 | 2010-07-22 | Google Inc. | Retrieving and displaying information from an unstructured electronic document collection |
| US8452791B2 (en) * | 2009-01-16 | 2013-05-28 | Google Inc. | Adding new instances to a structured presentation |
| US8161054B2 (en) * | 2009-04-03 | 2012-04-17 | International Business Machines Corporation | Dynamic paging model |
| US20100274615A1 (en) * | 2009-04-22 | 2010-10-28 | Eran Belinsky | Extendable Collaborative Correction Framework |
| US20110106819A1 (en) * | 2009-10-29 | 2011-05-05 | Google Inc. | Identifying a group of related instances |
| KR20120038418A (en) * | 2009-06-01 | 2012-04-23 | 구글 인코포레이티드 | Searching methods and devices |
| US20100306223A1 (en) * | 2009-06-01 | 2010-12-02 | Google Inc. | Rankings in Search Results with User Corrections |
| EP2577530A1 (en) * | 2010-06-07 | 2013-04-10 | Priaxon AG | Method for identifying compounds |
| US8639695B1 (en) | 2010-07-08 | 2014-01-28 | Patent Analytics Holding Pty Ltd | System, method and computer program for analysing and visualising data |
| AU2010202901B2 (en) | 2010-07-08 | 2016-04-14 | Patent Analytics Holding Pty Ltd | A system, method and computer program for preparing data for analysis |
| US8687892B2 (en) * | 2012-06-21 | 2014-04-01 | Thomson Licensing | Generating a binary descriptor representing an image patch |
| US9141676B2 (en) * | 2013-12-02 | 2015-09-22 | Rakuten Usa, Inc. | Systems and methods of modeling object networks |
| KR102454725B1 (en) * | 2016-09-09 | 2022-10-13 | 엘에스일렉트릭(주) | Apparatus for editing graphic object |
| JP7100422B2 (en) | 2016-10-21 | 2022-07-13 | 富士通株式会社 | Devices, programs, and methods for recognizing data properties |
| JP6805765B2 (en) | 2016-10-21 | 2020-12-23 | 富士通株式会社 | Systems, methods, and programs for running software services |
| EP3312722A1 (en) | 2016-10-21 | 2018-04-25 | Fujitsu Limited | Data processing apparatus, method, and program |
| EP3312724B1 (en) | 2016-10-21 | 2019-10-30 | Fujitsu Limited | Microservice-based data processing apparatus, method, and program |
| JP6787087B2 (en) * | 2016-10-21 | 2020-11-18 | 富士通株式会社 | Devices, methods and programs for data property recognition |
| US10776170B2 (en) | 2016-10-21 | 2020-09-15 | Fujitsu Limited | Software service execution apparatus, system, and method |
| US11269943B2 (en) * | 2018-07-26 | 2022-03-08 | JANZZ Ltd | Semantic matching system and method |
| US11334629B2 (en) * | 2019-12-27 | 2022-05-17 | Hitachi High-Tech Solutions Corporation | Search system for chemical compound having biological activity |
| CN113407809B (en) * | 2020-03-17 | 2024-01-09 | Gsi 科技公司 | Efficient similarity search |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6094648A (en) * | 1995-01-11 | 2000-07-25 | Philips Electronics North America Corporation | User interface for document retrieval |
| US20010047398A1 (en) * | 2000-02-29 | 2001-11-29 | Rubenstein Stewart D. | Managing chemical information and commerce |
| US6433771B1 (en) * | 1992-12-02 | 2002-08-13 | Cybernet Haptic Systems Corporation | Haptic device attribute control |
| US6751343B1 (en) * | 1999-09-20 | 2004-06-15 | Ut-Battelle, Llc | Method for indexing and retrieving manufacturing-specific digital imagery based on image content |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5918223A (en) * | 1996-07-22 | 1999-06-29 | Muscle Fish | Method and article of manufacture for content-based analysis, storage, retrieval, and segmentation of audio information |
| AU3001500A (en) * | 1999-02-19 | 2000-09-04 | Bioreason, Inc. | Method and system for artificial intelligence directed lead discovery through multi-domain clustering |
| JP2002007432A (en) * | 2000-06-23 | 2002-01-11 | Ntt Docomo Inc | Information retrieval system |
| US6654018B1 (en) * | 2001-03-29 | 2003-11-25 | At&T Corp. | Audio-visual selection process for the synthesis of photo-realistic talking-head animations |
-
2003
- 2003-05-28 US US10/448,168 patent/US20040006559A1/en not_active Abandoned
-
2004
- 2004-05-25 WO PCT/US2004/016322 patent/WO2004107217A1/en active Application Filing
- 2004-05-25 EP EP04753194A patent/EP1631925A4/en not_active Withdrawn
- 2004-05-25 US US10/516,061 patent/US7251643B2/en not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6433771B1 (en) * | 1992-12-02 | 2002-08-13 | Cybernet Haptic Systems Corporation | Haptic device attribute control |
| US6094648A (en) * | 1995-01-11 | 2000-07-25 | Philips Electronics North America Corporation | User interface for document retrieval |
| US6751343B1 (en) * | 1999-09-20 | 2004-06-15 | Ut-Battelle, Llc | Method for indexing and retrieving manufacturing-specific digital imagery based on image content |
| US20010047398A1 (en) * | 2000-02-29 | 2001-11-29 | Rubenstein Stewart D. | Managing chemical information and commerce |
Cited By (57)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7680859B2 (en) * | 2001-12-21 | 2010-03-16 | Location Inc. Group Corporation a Massachusetts corporation | Method for analyzing demographic data |
| US20100185620A1 (en) * | 2001-12-21 | 2010-07-22 | Location Inc. Group Corporation | Method for analyzing demographic data |
| US8849808B2 (en) * | 2001-12-21 | 2014-09-30 | Location Inc. Group Corporation | Method for analyzing demographic data |
| US20080016051A1 (en) * | 2001-12-21 | 2008-01-17 | Andrew Schiller | Method for analyzing demographic data |
| US7587408B2 (en) | 2002-03-21 | 2009-09-08 | United States Postal Service | Method and system for storing and retrieving data using hash-accessed multiple data stores |
| US20050021324A1 (en) * | 2003-07-25 | 2005-01-27 | Brants Thorsten H. | Systems and methods for new event detection |
| US8650187B2 (en) * | 2003-07-25 | 2014-02-11 | Palo Alto Research Center Incorporated | Systems and methods for linked event detection |
| US7577654B2 (en) * | 2003-07-25 | 2009-08-18 | Palo Alto Research Center Incorporated | Systems and methods for new event detection |
| US20050021490A1 (en) * | 2003-07-25 | 2005-01-27 | Chen Francine R. | Systems and methods for linked event detection |
| US20100017403A1 (en) * | 2004-09-27 | 2010-01-21 | Microsoft Corporation | System and method for scoping searches using index keys |
| US8843486B2 (en) | 2004-09-27 | 2014-09-23 | Microsoft Corporation | System and method for scoping searches using index keys |
| US20060074871A1 (en) * | 2004-09-30 | 2006-04-06 | Microsoft Corporation | System and method for incorporating anchor text into ranking search results |
| US8082246B2 (en) | 2004-09-30 | 2011-12-20 | Microsoft Corporation | System and method for ranking search results using click distance |
| US7739277B2 (en) | 2004-09-30 | 2010-06-15 | Microsoft Corporation | System and method for incorporating anchor text into ranking search results |
| US7761448B2 (en) | 2004-09-30 | 2010-07-20 | Microsoft Corporation | System and method for ranking search results using click distance |
| US7827181B2 (en) | 2004-09-30 | 2010-11-02 | Microsoft Corporation | Click distance determination |
| US20060074903A1 (en) * | 2004-09-30 | 2006-04-06 | Microsoft Corporation | System and method for ranking search results using click distance |
| US20060069982A1 (en) * | 2004-09-30 | 2006-03-30 | Microsoft Corporation | Click distance determination |
| US7716198B2 (en) | 2004-12-21 | 2010-05-11 | Microsoft Corporation | Ranking search results using feature extraction |
| US20060136411A1 (en) * | 2004-12-21 | 2006-06-22 | Microsoft Corporation | Ranking search results using feature extraction |
| US20060294100A1 (en) * | 2005-03-03 | 2006-12-28 | Microsoft Corporation | Ranking search results using language types |
| US20060200460A1 (en) * | 2005-03-03 | 2006-09-07 | Microsoft Corporation | System and method for ranking search results using file types |
| US7792833B2 (en) | 2005-03-03 | 2010-09-07 | Microsoft Corporation | Ranking search results using language types |
| US20070016612A1 (en) * | 2005-07-11 | 2007-01-18 | Emolecules, Inc. | Molecular keyword indexing for chemical structure database storage, searching, and retrieval |
| US7599917B2 (en) * | 2005-08-15 | 2009-10-06 | Microsoft Corporation | Ranking search results using biased click distance |
| US20070038622A1 (en) * | 2005-08-15 | 2007-02-15 | Microsoft Corporation | Method ranking search results using biased click distance |
| US20080208791A1 (en) * | 2007-02-27 | 2008-08-28 | Madirakshi Das | Retrieving images based on an example image |
| US20100145896A1 (en) * | 2007-08-22 | 2010-06-10 | Fujitsu Limited | Compound property prediction apparatus, property prediction method, and program for implementing the method |
| US8473448B2 (en) * | 2007-08-22 | 2013-06-25 | Fujitsu Limited | Compound property prediction apparatus, property prediction method, and program for implementing the method |
| US20100217770A1 (en) * | 2007-09-10 | 2010-08-26 | Peter Ernst | Method for automatically sensing a set of items |
| US8250057B2 (en) * | 2007-09-10 | 2012-08-21 | Parametric Technology Corporation | Method for automatically sensing a set of items |
| US20090106223A1 (en) * | 2007-10-18 | 2009-04-23 | Microsoft Corporation | Enterprise relevancy ranking using a neural network |
| US9348912B2 (en) | 2007-10-18 | 2016-05-24 | Microsoft Technology Licensing, Llc | Document length as a static relevance feature for ranking search results |
| US20090106235A1 (en) * | 2007-10-18 | 2009-04-23 | Microsoft Corporation | Document Length as a Static Relevance Feature for Ranking Search Results |
| US20090106221A1 (en) * | 2007-10-18 | 2009-04-23 | Microsoft Corporation | Ranking and Providing Search Results Based In Part On A Number Of Click-Through Features |
| US7840569B2 (en) | 2007-10-18 | 2010-11-23 | Microsoft Corporation | Enterprise relevancy ranking using a neural network |
| US20090259651A1 (en) * | 2008-04-11 | 2009-10-15 | Microsoft Corporation | Search results ranking using editing distance and document information |
| US8812493B2 (en) | 2008-04-11 | 2014-08-19 | Microsoft Corporation | Search results ranking using editing distance and document information |
| EP2361410A4 (en) * | 2008-12-05 | 2015-11-11 | Decript Inc | Method for creating virtual compound libraries within markush structure patent claims |
| US20100169375A1 (en) * | 2008-12-29 | 2010-07-01 | Accenture Global Services Gmbh | Entity Assessment and Ranking |
| US8639682B2 (en) * | 2008-12-29 | 2014-01-28 | Accenture Global Services Limited | Entity assessment and ranking |
| US8738635B2 (en) | 2010-06-01 | 2014-05-27 | Microsoft Corporation | Detection of junk in search result ranking |
| US9495462B2 (en) | 2012-01-27 | 2016-11-15 | Microsoft Technology Licensing, Llc | Re-ranking search results |
| US11373734B2 (en) * | 2012-05-18 | 2022-06-28 | Georgetown University | Methods and systems for populating and searching a drug informatics database |
| US20140316768A1 (en) * | 2012-12-14 | 2014-10-23 | Pramod Khandekar | Systems and methods for natural language processing |
| US9443005B2 (en) * | 2012-12-14 | 2016-09-13 | Instaknow.Com, Inc. | Systems and methods for natural language processing |
| US20190377720A1 (en) * | 2013-09-24 | 2019-12-12 | Qliktech International Ab | Methods and systems for data management and analysis |
| US11853281B2 (en) * | 2013-09-24 | 2023-12-26 | Qliktech International Ab | Methods and systems for data management and analysis |
| US20170132305A1 (en) * | 2015-11-09 | 2017-05-11 | Industrial Technology Research Institute | Method for finding crowd movements |
| US10417648B2 (en) * | 2015-11-09 | 2019-09-17 | Industrial Technology Research Institute | System and computer readable medium for finding crowd movements |
| US11301518B2 (en) | 2017-03-03 | 2022-04-12 | Perkinelmer Informatics, Inc. | Systems and methods for searching and indexing documents comprising chemical information |
| US20180253426A1 (en) * | 2017-03-03 | 2018-09-06 | Perkinelmer Informatics, Inc. | Systems and methods for searching and indexing documents comprising chemical information |
| US10572545B2 (en) * | 2017-03-03 | 2020-02-25 | Perkinelmer Informatics, Inc | Systems and methods for searching and indexing documents comprising chemical information |
| CN110569421A (en) * | 2019-08-22 | 2019-12-13 | 上海摩库数据技术有限公司 | search method based on chemical industry |
| CN110569420A (en) * | 2019-08-22 | 2019-12-13 | 上海摩库数据技术有限公司 | Search method based on chemical industry |
| US20210073732A1 (en) * | 2019-09-11 | 2021-03-11 | Ila Design Group, Llc | Automatically determining inventory items that meet selection criteria in a high-dimensionality inventory dataset |
| US11494734B2 (en) * | 2019-09-11 | 2022-11-08 | Ila Design Group Llc | Automatically determining inventory items that meet selection criteria in a high-dimensionality inventory dataset |
Also Published As
| Publication number | Publication date |
|---|---|
| US20060074859A1 (en) | 2006-04-06 |
| EP1631925A1 (en) | 2006-03-08 |
| EP1631925A4 (en) | 2007-01-31 |
| US7251643B2 (en) | 2007-07-31 |
| WO2004107217A1 (en) | 2004-12-09 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20040006559A1 (en) | System, apparatus, and method for user tunable and selectable searching of a database using a weigthted quantized feature vector | |
| Schouteden et al. | Performing DISCO-SCA to search for distinctive and common information in linked data | |
| Bijmolt et al. | A comparison of multidimensional scaling methods for perceptual mapping | |
| US20080016035A1 (en) | Integration of documents with OLAP using search | |
| Paek et al. | IRTPRO 2.1 for Windows (item response theory for patient-reported outcomes) | |
| Rossi et al. | Statistical tool for soil biology X. Geostatistical analysis. | |
| Andersson et al. | Estimation of latent regression item response theory models using a second-order Laplace approximation | |
| Kilpatrick | Statistical principles in health care information. | |
| Kubojima et al. | Accuracy of the shear modulus of wood obtained by Timoshenko's theory of bending. | |
| Mitchell | A sensitive dot immunoassay employing monoclonal antibodies for detection of Sirococcus strobilinus in spruce seed. | |
| Sheppard et al. | Methods for the evaluation of EIA tests for use in the detection of seed-borne diseases. | |
| Lahl et al. | EQUIWORD: A software application for the automatic creation of truly equivalent word lists | |
| Palardy | Review of HLM 7 | |
| Wilkins et al. | A hybrid model for nonignorable dropout in longitudinal binary responses | |
| Huang et al. | Analysis of longitudinal data unbalanced over time | |
| Berry et al. | Correlation and Association | |
| Lin et al. | Investigation and analysis of the internal quality control in primary clinical laboratory of pre-pregnancy eugenics. | |
| Ayatollahi et al. | A study of adult height, weight and obesity in Shiraz, Iran, 1988-1989. | |
| Sharifnabi et al. | Occurrence and geographical distribution of Tilletia species attacking winter wheat in west and north-west of Iran. | |
| Kuzyk et al. | Evaluation of a direct method for the determination of true protein content in milk by Kjeldahl analysis. | |
| Gancet et al. | Analysis of a sulfonated wood cross-section by auger electron spectroscopy. | |
| Musa | The spectrum of resistance in rye to Puccinia graminis and P. recondita. | |
| Campos et al. | Estimate of repetitiveness and reproductiveness of laboratories and its application in quality control of soil analyses. | |
| Giannessi et al. | Radioimmunoassay of human chorionic somatomammotropin: evaluation and comparison of three kit-methods. | |
| Turney et al. | Economic analysis and properties of the risk aversion coefficient in constrained mathematical options. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: ROW2 TECHNOLOGIES, INC., NEW JERSEY Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:GANGE, DAVID M.;FRAMROZE, BOMI P.;REEL/FRAME:014131/0472 Effective date: 20030527 |
|
| STCB | Information on status: application discontinuation |
Free format text: ABANDONED -- FAILURE TO RESPOND TO AN OFFICE ACTION |