US8005293B2 - Gradient based training method for a support vector machine - Google Patents
Gradient based training method for a support vector machine Download PDFInfo
- Publication number
- US8005293B2 US8005293B2 US10/257,929 US25792903A US8005293B2 US 8005293 B2 US8005293 B2 US 8005293B2 US 25792903 A US25792903 A US 25792903A US 8005293 B2 US8005293 B2 US 8005293B2
- Authority
- US
- United States
- Prior art keywords
- data
- training
- processor
- data points
- machine
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related, expires
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
- G06F18/241—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches
- G06F18/2411—Classification techniques relating to the classification model, e.g. parametric or non-parametric approaches based on the proximity to a decision surface, e.g. support vector machines
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N20/00—Machine learning
- G06N20/10—Machine learning using kernel methods, e.g. support vector machines [SVM]
Definitions
- the present invention relates to a training method for a support vector machine.
- Computer systems can be configured as learning machines that are able to analyse data and adapt in response to analysis of the data, and also be trained on the basis of a known data set.
- Support Vector Machines (“SVMs”), for instance, execute a supervised learning method for data classification and regression.
- Supervised methods refer to tasks in which a machine is presented with historical data with known labels, i.e. good customers vs bad customers, and then the machine is trained to look for patterns in the data.
- SVMs represent a recent development in “neural network” algorithms and have become increasingly popular over the past few years. Essentially these machines seek to define a decision surface which gives the largest margin or separation between the data classes whilst at the same time minimising the number of errors. This is usually accomplished by solving a specific quadratic optimisation problem.
- the first of these two forms is used in regression (more precisely, the so-called ⁇ -insensitive regression), and the other in classification tasks.
- the problem is in fact more subtle than this because training the machine ordinarily involves searching for a surface in a very high dimensional space, and possibly infinite dimensional space.
- the search in such a high dimensional space is achieved by replacing the regular dot product in the above expression with a nonlinear version.
- the nonlinear dot product is referred to as the Mercer kernel and SVMs are sometimes referred to as kernel machines. Both are described in V. Vapnik, Statistical Learning Theory, J. Wiley, 1998, (“Vapnik”); C.
- the present invention relates to a training method for a support vector machine, including executing an iterative process on a training set of data to determine parameters defining said machine, said iterative process being executed on the basis of a differentiable form of a primal optimisation problem for said parameters, said problem being defined on the basis of said parameters and said data set.
- the training method can be adapted for generation of a kernel support vector machine and a regularisation networks.
- y sgn ( w ⁇ x+/ ⁇ b ), where y is the output, x is the input data, ⁇ is 0 or 1, the vector w and bias b defining a decision surface is obtained as the argument by minimising the following differentiable objective function:
- C>0 is a free parameter
- n being the number of data points
- the said iterative process preferably operates on a derivative of the objective function ⁇ until the vectors converge to a vector w defining the machine.
- the differentiable form of the optimisation problem is given as minimisation of the functional
- the present invention also provides a support vector machine for a classification task having an output y given by
- x ⁇ R m is a data point to be classified and x i are training data points
- k is a Mercer kernel function as described in Vapnik and Burges
- the present invention also provides a support vector machine for ⁇ -regression having output y given by
- x ⁇ R m is a data point to be evaluated and x i are training data points
- k is the Mercer kernel function
- ⁇ 0 or 1
- i, j 1, . . , n, n being the number of data points and t represents an iteration.
- FIG. 1 is a block diagram of a preferred embodiment of a support vector machine
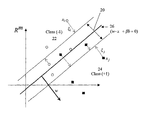
- FIG. 2 is a graph illustrating an optimal hyperplane established by the support vector machine for linear classification
- FIG. 3 is a graph of a hypersurface established by the support vector machine for a non-linear classification
- FIG. 4 is a graph of a regression function established by the support vector machine for linear regression
- FIG. 5 is a graph of a regression function established by a support vector machine for non-linear regression
- FIG. 6 is a graph of differential loss functions for classification and regression for the support vector machine.
- FIG. 7 is a graph of differential loss functions for regularisation networks established by the support vector machine.
- a Support Vector Machine (SVM) 2 is implemented by a computer system 2 which executes data analysis using a supervised learning method for the machine.
- the computer system 2 of the Support Vector Machine includes a processing unit 6 connected to at least one data input device 4 , and at least one output device 8 , such as a display screen.
- the input device 4 may include such data input devices as a keyboard, mouse, disk drive etc for inputting data on which the processing unit can operate.
- the processing unit 6 includes a processor 10 with access to data memory 12 , such as RAM and hard disk drives, that can be used to store computer programs or software 14 that control the operations executed by the processor 10 .
- the software 14 is executed by the computer system 2 .
- the processing steps of the SVM are normally executed by the dedicated computer program or software 14 stored on a standard computer system 2 , but can be executed by dedicated hardware circuits, such as ASICs.
- the computer system 2 and its software components may also be distributed over a communications network.
- the computer system 2 may be a UNIX workstation or a standard personal computer with sufficient processing capacity to execute the data processing step described herein.
- ⁇ tilde over (L) ⁇ is a convex loss function; the ⁇ i s represent errors and are often referred to as slack variables and C>0 is a free parameter.
- the first term on the right hand side of equation (3) controls the margin 20 between the data classes 22 and 24 , as shown in FIG. 2 , while the second term describes the error penalty.
- the primal problem is an example of a constrained quadratic minimisation problem.
- a common approach when dealing with constraints is to use the method of Lagrange multipliers. This technique typically simplifies the form of constraints and makes the problem more tractable.
- the modified loss L( ⁇ ) is assumed to be 0 for ⁇ 0.
- the first method executes a gradient descent technique to obtain the vector w iteratively using the following:
- ⁇ controls the steps size and t represents the “time” or iteration step.
- the value of the parameter ⁇ can be either fixed or can be made to decrease gradually.
- the iterative training process of equation (8) can, in some instances, fail to converge to a set of vectors, but when it does converge it does very rapidly.
- the training process of equation (7) is not as rapid as that of equation (8), but it will always converge provided ⁇ is sufficiently small.
- the two processes can be executed in parallel to ensure convergence to a set of vectors for an SVM.
- This approach can be extended to search for a hyperplane in a high dimensional or even infinite dimensional space of feature vectors.
- This hyperplane corresponds to a non-linear surface in the original space, such as the optimal hypersurface 30 shown in FIG. 3 .
- the optimal SVM is uniquely determined by those coefficients, because for any vector ⁇ tilde over (x) ⁇ i ⁇ R ⁇ tilde over (m) ⁇ ,
- ⁇ j t w t ⁇ x j
- ⁇ j t+1 w t+1 ⁇ x j and ⁇ >0 is a free parameter.
- ⁇ + ⁇ i and ⁇ i ⁇ 0 for i 1, . . . ,n, (17)
- C, ⁇ >0 are free parameters and L is the loss function as before.
- the iterative processes ( 19 ) and ( 20 ) can also be extended to the non-linear (kernel) case to provide a regression function 50 , as shown in FIG. 5 , defining the optimal hypersurface to give the kernel version of the gradient descent process for regression:
- the optimal SVM regressor function 50 is defined by
- the coefficients ⁇ i (Lagrange multipliers) are derived from the following equation which is analogous to equation (15)
- ⁇ i CL′ (
- regularisation networks (RNs), as discussed in G. Kimeldorf and G. Wahba, A correspondence between Bayesian estimation of stochastic processes and smoothing by spines , Anm. Math. Statist, 1970, 495-502; F. Girosi, M. Jones and T. Poggio, Regularization Theory and Neural Networks Architectures , Neural Computation. 1995, 219-269; and G. Wahba, Support Vector Machines, Reproducing Kernel Hilbert Spaces and the Randomized GACV 2000, in B. Scholkopf, C. J. Burges and A.
- ⁇ >0 is a free parameter (regularisation constant)
- the coefficients (Lagrange multipliers) ⁇ i are derived from the following equation analogous to equation (15)
- ⁇ i CL′ ( y i ⁇ i ⁇ b )
- SVM SVM
- SVM SVM
- a large amount of email messages are received and it is particularly advantageous to be able to remove those messages which are unsolicited or the organisation clearly does not Want its personnel to receive.
- fast training processes described above which are able to operate on large data sets of multiple dimensions, several to several hundred emails can be processed to establish an SVM which is able to classify emails as either being bad or good.
- the training data set includes all of the text of the email messages and each word or phrase in a preselected dictionary can be considered to constitute a dimension of the vectors.
- SVM Session метор
- image classification particle identification for high energy physics
- object detection combustion engine knock detection
- detection of remote protein homologies 3D object recognition
- text categorisation as discussed above
- time series prediction and reconstruction for chaotic systems
- hand written digit recognition breast cancer diagnosis and prognosis based on breast cancer data sets
- decision tree methods for database marketing.
Abstract
Description
y=w·x+βb (1)
or its binarised form
y=sgn(w·x+βb) (2)
where the vector w defines the decision surface, x is the input data, y is the classification, β is a constant that acts on a switch between the homogeneous (β=0) and the non-homogeneous (β=1) case, b is a free parameter usually called bias and “sgn” denotes the ordinary signum function, i.e. sgn(ξ)=1 for ξ>0, sgn(ξ)=−1 for ξ<1 and sgn(0)=0. Typically, the first of these two forms is used in regression (more precisely, the so-called ε-insensitive regression), and the other in classification tasks. The problem is in fact more subtle than this because training the machine ordinarily involves searching for a surface in a very high dimensional space, and possibly infinite dimensional space. The search in such a high dimensional space is achieved by replacing the regular dot product in the above expression with a nonlinear version. The nonlinear dot product is referred to as the Mercer kernel and SVMs are sometimes referred to as kernel machines. Both are described in V. Vapnik, Statistical Learning Theory, J. Wiley, 1998, (“Vapnik”); C. Burges, A Tutorial on Support Vector Machines for Pattern Recognition, Data Mining and Knowledge Discovery, 2, 1998, (“Burges”); V. Cherkassky and F. Mulier, Learning From Data, John Wiley and Sons, Inc., 1998; and N. Christinini and J. Shawe-Taylor, 2000, An Introduction to Support Vector Machines and other Kernel-Based Learning Methods, Cambridge University Press, Cambridge 2000.
y=sgn(w·x+/βb),
where y is the output, x is the input data, β is 0 or 1, the vector w and bias b defining a decision surface is obtained as the argument by minimising the following differentiable objective function:
where C>0 is a free parameter, xi, i=1, . . . ,n, being the data points, yi=±1, i=1, . . . , n, being the known labels, n being the number of data points and L being a differentiable loss function such that L(ε)=0 for ε≦0. The said iterative process preferably operates on a derivative of the objective function Ψ until the vectors converge to a vector w defining the machine.
Preferably, for ε-insensitive regression, the differentiable form of the optimisation problem is given as minimisation of the functional
where the ε>0 is a free parameter.
where x∈Rm is a data point to be classified and xi are training data points, k is a Mercer kernel function as described in Vapnik and Burges, and αi are coefficients determined by
αi =CL′(1−y i η i −βb)
where L′(ξ) is the derivative of the loss and the values ηi are determined by iteratively executing
where δ>0 is a free parameter (a learning rate) and/or, in the homogeneous case (β=0) by iteratively executing:
where i, j=1, . . . , n, n being the number of data points, t represents an iteration and L′ is the derivative of the loss function L.
where x∈Rm is a data point to be evaluated and xi are training data points, k is the Mercer kernel function, β=0 or 1, and βi and bias b are coefficients determined by
βi =CL′(|y i−ηi −βb|−ε)sgn(y i−ηi −βb)
where ε is a free parameter and the values ηi, and b are determined by iteratively executing
where δ>0 is a free parameter (learning rate) and/or, in the homogeneous case (β=0) by iteratively executing:
where i, j=1, . . , n, n being the number of data points and t represents an iteration.
where the (modified loss) L(χ)={tilde over (L)}(max(0, χ)) is obtained after a direct substitution for the slack variable ξi=max(0,1−yiw·wi), for i=1, 2, . . . , n. The modified loss L(χ) is assumed to be 0 for χ≦0. In this form the constraints (4) do not explicitly appear and so as long as equation (5) is differentiable, standard techniques for finding the minimum of an unconstrained function may be applied. This holds if the loss function L is differentiable, in particular for L(χ)=max(0, χ)p for p>1. For non-differentiable cases, such as the linear loss function L(χ)=max(0, χ), a simple smoothing technique can be employed, e.g. a Huber loss function could be used, as discussed in Vapnik. The objection function is also referred to as a regularised risk.
where δ controls the steps size and t represents the “time” or iteration step. The value of the parameter δ can be either fixed or can be made to decrease gradually. One robust solution for p=2 is to use δ calculated by the formula:
where ∇wΨ and □bΨ are calculated from (6) simplify
with summation taken over all indices i such that yi(1−yiw·xi−yiβb)>0.
x i ·x j=Φ({tilde over (x)} i)·Φ({tilde over (x)} j)=k({tilde over (x)} i , {tilde over (x)} j). (9)
where αi≧0 (referred to as Lagrange multipliers). The optimal SVM is uniquely determined by those coefficients, because for any vector {tilde over (x)}iεR{tilde over (m)},
leading to the “non-linear” version of gradient descent process being
where ηj t=wt·xj and ηj t+1=wt+1·xj and δ>0 is a free parameter.
but this is computationally difficult, as the problem is invariably singular. A better approach is to note from equation (7) that the coefficients are given by
αi =CL′(1−y iηi −βb) (15)
subject to
|y i −w·x i −βb|≦ε+ξ i and ξi≧0 for i=1, . . . ,n, (17)
where C, ε>0 are free parameters and L is the loss function as before. This problem is equivalent to minimisation of the following function
analogous to equation (5) for classification, where as before we define the loss L(χ)={tilde over (L)}(max(0, χ)). Further in a similar manner to equations (7) and (8), for the linear case the gradient descent process for regression takes the form
and the fixed point algorithms for regression becomes:
and the kernel version of the fixed point algorithm for regression (β=0):
where the coefficients βi (Lagrange multipliers) are derived from the following equation which is analogous to equation (15)
βi =CL′(|y i−ηi −βb|−ε)sgn(y i−ηi −βb)
where λ>0 is a free parameter (regularisation constant) and L is the convex loss function, e.g. L(ξ)=ξp for p≧1. This problem is equivalent to minimisation of the following functional
under assumption λ=C−1. The latest functional has the form of equation (16), and the techniques analogous to those described above can be employed to find its minimum. Analogous to equation (19), in the linear case, the gradient descent algorithm for RN takes the form
and the fixed point algorithms for RN becomes:
w t+1 =CΣ i=1 n L′(y i−wt ·x i −βb)xi
Those two algorithms extended to the non-linear (kernel) case yield the kernel version of gradient descent algorithm for RN:
and the kernel version of the fixed point algorithm for RN (β=0):
Having found the optimal values ηj (j=1, . . . ,n), from the above algorithms, the optimal regressor is defined as
where the coefficients (Lagrange multipliers) βi are derived from the following equation analogous to equation (15)
βi =CL′(y i−ηi −βb)
x=x(E)=(freq 1(E), . . . ,freq m(E))
where freqi (E) gives the number (frequency) of the phrase phrasei appeared in the email E. In the classification phase the likelihood of email E being Spam is estimated as
where the vector w=(w1, . . . , wm) defining the decision surface is obtained using the training process of equation (7) or (8) for the sequence of training email vectors xi=(freq1(E), . . . , freqm(Ei)), each associated with the training label yi=1 for an example of a Spam email and yi=−1 for each allowed email, i=1, . . . , n.
Claims (10)
y=sgn(w·x+βb),
a i =CL′(1−y i n i βb)
βi =CL′(|y i-nj-βb|-ε)sgn(y i-i-βb)
βl =CL′(|y i-ni-βb|-ε)
y=sgn(w.x+βb),
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| AUPQ6844 | 2000-04-11 | ||
| AUPQ6844A AUPQ684400A0 (en) | 2000-04-11 | 2000-04-11 | A gradient based training method for a support vector machine |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| US20030158830A1 US20030158830A1 (en) | 2003-08-21 |
| US8005293B2 true US8005293B2 (en) | 2011-08-23 |
Family
ID=3820938
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US10/257,929 Expired - Fee Related US8005293B2 (en) | 2000-04-11 | 2001-04-11 | Gradient based training method for a support vector machine |
Country Status (6)
| Country | Link |
|---|---|
| US (1) | US8005293B2 (en) |
| EP (1) | EP1281130A4 (en) |
| AU (1) | AUPQ684400A0 (en) |
| CA (1) | CA2405824A1 (en) |
| NZ (1) | NZ521890A (en) |
| WO (1) | WO2001077855A1 (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110185789A1 (en) * | 2008-10-01 | 2011-08-04 | Yamatake Corporation | Calorific value calculation formula generating system, calorific value calculation formula generating method, calorific value calculating system, and calorific value calculating method |
| US8888361B2 (en) | 2011-05-09 | 2014-11-18 | Azbil Corporation | Calorific value measuring system and calorific value measuring method |
| US9188557B2 (en) | 2012-03-27 | 2015-11-17 | Azbil Corporation | Calorific value measuring system and calorific value measuring method |
Families Citing this family (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| AUPR958901A0 (en) | 2001-12-18 | 2002-01-24 | Telstra New Wave Pty Ltd | Information resource taxonomy |
| US8015131B2 (en) * | 2007-10-12 | 2011-09-06 | Microsoft Corporation | Learning tradeoffs between discriminative power and invariance of classifiers |
| DE102008041840A1 (en) * | 2008-09-05 | 2009-10-08 | Robert Bosch Gmbh | Method for knock detection in internal combustion engine by linear or non-linear support vector machine, involves transmitting vibration data of internal combustion engine to linear or non-linear support vector machine |
| US8626677B2 (en) | 2010-05-28 | 2014-01-07 | Microsoft Corporation | Training SVMs with parallelized stochastic gradient descent |
| US9524730B2 (en) | 2012-03-30 | 2016-12-20 | Ohio State Innovation Foundation | Monaural speech filter |
| CN103971690A (en) * | 2013-01-28 | 2014-08-06 | 腾讯科技(深圳)有限公司 | Voiceprint recognition method and device |
| US9502038B2 (en) | 2013-01-28 | 2016-11-22 | Tencent Technology (Shenzhen) Company Limited | Method and device for voiceprint recognition |
| US10332025B2 (en) * | 2014-03-11 | 2019-06-25 | Siemens Aktiengesellschaft | Proximal gradient method for huberized support vector machine |
| TWI636276B (en) * | 2014-05-16 | 2018-09-21 | 財團法人國家實驗研究院 | Method of determining earthquake with artificial intelligence and earthquake detecting system |
| US10043288B2 (en) * | 2015-11-10 | 2018-08-07 | Honeywell International Inc. | Methods for monitoring combustion process equipment |
| CN105678340B (en) * | 2016-01-20 | 2018-12-25 | 福州大学 | A kind of automatic image marking method based on enhanced stack autocoder |
| CN105574551B (en) * | 2016-02-18 | 2019-03-08 | 天津师范大学 | A kind of ground cloud atlas automatic classification method based on group schema |
| CN106482967B (en) * | 2016-10-09 | 2019-10-29 | 湖南工业大学 | A kind of Cost Sensitive Support Vector Machines locomotive wheel detection system and method |
| CN108875821A (en) * | 2018-06-08 | 2018-11-23 | Oppo广东移动通信有限公司 | The training method and device of disaggregated model, mobile terminal, readable storage medium storing program for executing |
| CN110006795B (en) * | 2019-04-30 | 2024-02-13 | 华北电力大学(保定) | Particle detection device and method and FPGA |
| WO2020231049A1 (en) * | 2019-05-16 | 2020-11-19 | Samsung Electronics Co., Ltd. | Neural network model apparatus and compressing method of neural network model |
| CN110648010A (en) * | 2019-07-26 | 2020-01-03 | 浙江工业大学 | Bus passenger flow prediction method based on small sample data |
| CN111307453B (en) * | 2020-03-20 | 2021-11-12 | 朗斯顿科技(北京)有限公司 | Transmission system fault diagnosis method based on multi-information fusion |
| CN112504689B (en) * | 2020-12-21 | 2023-03-21 | 潍柴动力股份有限公司 | Engine knock detection method, device, equipment and storage medium |
| CN113628759A (en) * | 2021-07-22 | 2021-11-09 | 中国科学院重庆绿色智能技术研究院 | Infectious disease epidemic situation safety region prediction method based on big data |
Citations (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5640492A (en) | 1994-06-30 | 1997-06-17 | Lucent Technologies Inc. | Soft margin classifier |
| US5649068A (en) * | 1993-07-27 | 1997-07-15 | Lucent Technologies Inc. | Pattern recognition system using support vectors |
| US5950146A (en) * | 1996-10-04 | 1999-09-07 | At & T Corp. | Support vector method for function estimation |
| WO1999057622A2 (en) | 1998-05-01 | 1999-11-11 | Barnhill Technologies, Llc | Pre-processing and post-processing for enhancing knowledge discovery using support vector machines |
| US6112195A (en) * | 1997-03-27 | 2000-08-29 | Lucent Technologies Inc. | Eliminating invariances by preprocessing for kernel-based methods |
| US6134344A (en) | 1997-06-26 | 2000-10-17 | Lucent Technologies Inc. | Method and apparatus for improving the efficiency of support vector machines |
| US6192360B1 (en) | 1998-06-23 | 2001-02-20 | Microsoft Corporation | Methods and apparatus for classifying text and for building a text classifier |
| US6714925B1 (en) * | 1999-05-01 | 2004-03-30 | Barnhill Technologies, Llc | System for identifying patterns in biological data using a distributed network |
| US6760715B1 (en) * | 1998-05-01 | 2004-07-06 | Barnhill Technologies Llc | Enhancing biological knowledge discovery using multiples support vector machines |
| US6789069B1 (en) * | 1998-05-01 | 2004-09-07 | Biowulf Technologies Llc | Method for enhancing knowledge discovered from biological data using a learning machine |
| US6990217B1 (en) * | 1999-11-22 | 2006-01-24 | Mitsubishi Electric Research Labs. Inc. | Gender classification with support vector machines |
| US7117188B2 (en) * | 1998-05-01 | 2006-10-03 | Health Discovery Corporation | Methods of identifying patterns in biological systems and uses thereof |
| US7318051B2 (en) * | 2001-05-18 | 2008-01-08 | Health Discovery Corporation | Methods for feature selection in a learning machine |
| US20080097939A1 (en) * | 1998-05-01 | 2008-04-24 | Isabelle Guyon | Data mining platform for bioinformatics and other knowledge discovery |
| US20080233576A1 (en) * | 1998-05-01 | 2008-09-25 | Jason Weston | Method for feature selection in a support vector machine using feature ranking |
| US7475048B2 (en) * | 1998-05-01 | 2009-01-06 | Health Discovery Corporation | Pre-processed feature ranking for a support vector machine |
-
2000
- 2000-04-11 AU AUPQ6844A patent/AUPQ684400A0/en not_active Abandoned
-
2001
- 2001-04-11 US US10/257,929 patent/US8005293B2/en not_active Expired - Fee Related
- 2001-04-11 CA CA002405824A patent/CA2405824A1/en not_active Withdrawn
- 2001-04-11 EP EP01921035A patent/EP1281130A4/en not_active Withdrawn
- 2001-04-11 WO PCT/AU2001/000415 patent/WO2001077855A1/en active IP Right Grant
- 2001-04-11 NZ NZ521890A patent/NZ521890A/en not_active IP Right Cessation
Patent Citations (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5649068A (en) * | 1993-07-27 | 1997-07-15 | Lucent Technologies Inc. | Pattern recognition system using support vectors |
| US5640492A (en) | 1994-06-30 | 1997-06-17 | Lucent Technologies Inc. | Soft margin classifier |
| US5950146A (en) * | 1996-10-04 | 1999-09-07 | At & T Corp. | Support vector method for function estimation |
| US6112195A (en) * | 1997-03-27 | 2000-08-29 | Lucent Technologies Inc. | Eliminating invariances by preprocessing for kernel-based methods |
| US6134344A (en) | 1997-06-26 | 2000-10-17 | Lucent Technologies Inc. | Method and apparatus for improving the efficiency of support vector machines |
| US6760715B1 (en) * | 1998-05-01 | 2004-07-06 | Barnhill Technologies Llc | Enhancing biological knowledge discovery using multiples support vector machines |
| WO1999057622A2 (en) | 1998-05-01 | 1999-11-11 | Barnhill Technologies, Llc | Pre-processing and post-processing for enhancing knowledge discovery using support vector machines |
| US20100256988A1 (en) * | 1998-05-01 | 2010-10-07 | Health Discovery Corporation | System for providing data analysis services using a support vector machine for processing data received from a remote source |
| US20080233576A1 (en) * | 1998-05-01 | 2008-09-25 | Jason Weston | Method for feature selection in a support vector machine using feature ranking |
| US6789069B1 (en) * | 1998-05-01 | 2004-09-07 | Biowulf Technologies Llc | Method for enhancing knowledge discovered from biological data using a learning machine |
| US7805388B2 (en) * | 1998-05-01 | 2010-09-28 | Health Discovery Corporation | Method for feature selection in a support vector machine using feature ranking |
| US7797257B2 (en) * | 1998-05-01 | 2010-09-14 | Health Discovery Corporation | System for providing data analysis services using a support vector machine for processing data received from a remote source |
| US7542959B2 (en) * | 1998-05-01 | 2009-06-02 | Health Discovery Corporation | Feature selection method using support vector machine classifier |
| US7117188B2 (en) * | 1998-05-01 | 2006-10-03 | Health Discovery Corporation | Methods of identifying patterns in biological systems and uses thereof |
| US7475048B2 (en) * | 1998-05-01 | 2009-01-06 | Health Discovery Corporation | Pre-processed feature ranking for a support vector machine |
| US20080033899A1 (en) * | 1998-05-01 | 2008-02-07 | Stephen Barnhill | Feature selection method using support vector machine classifier |
| US20080059392A1 (en) * | 1998-05-01 | 2008-03-06 | Stephen Barnhill | System for providing data analysis services using a support vector machine for processing data received from a remote source |
| US20080097939A1 (en) * | 1998-05-01 | 2008-04-24 | Isabelle Guyon | Data mining platform for bioinformatics and other knowledge discovery |
| US6192360B1 (en) | 1998-06-23 | 2001-02-20 | Microsoft Corporation | Methods and apparatus for classifying text and for building a text classifier |
| US20050165556A1 (en) * | 1999-05-01 | 2005-07-28 | Stephen Barnhill | Colon cancer biomarkers |
| US6882990B1 (en) * | 1999-05-01 | 2005-04-19 | Biowulf Technologies, Llc | Methods of identifying biological patterns using multiple data sets |
| US6714925B1 (en) * | 1999-05-01 | 2004-03-30 | Barnhill Technologies, Llc | System for identifying patterns in biological data using a distributed network |
| US6990217B1 (en) * | 1999-11-22 | 2006-01-24 | Mitsubishi Electric Research Labs. Inc. | Gender classification with support vector machines |
| US7318051B2 (en) * | 2001-05-18 | 2008-01-08 | Health Discovery Corporation | Methods for feature selection in a learning machine |
| US7444308B2 (en) * | 2001-06-15 | 2008-10-28 | Health Discovery Corporation | Data mining platform for bioinformatics and other knowledge discovery |
Non-Patent Citations (4)
| Title |
|---|
| C. Burgess, "A Tutorial on Support Vector Machines for Pattern Recognition", Data Mining and Knowledge Discovery, 2, Kluwer Academic Publishers, 1998, pp. 121-167. |
| N. Christianini et al., "An Introduction to Support Vector Machines and other Kernel-Based Learning Methods", Cambridge University Press, Cambridge 2000. |
| V. Cherkassky et al., "Learning from Data", John Wiley and Sons, Inc., 1998. |
| V. Vapnik, "Statistical Learning Theory", John Wiley and Sons, Inc. 1998. |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20110185789A1 (en) * | 2008-10-01 | 2011-08-04 | Yamatake Corporation | Calorific value calculation formula generating system, calorific value calculation formula generating method, calorific value calculating system, and calorific value calculating method |
| US8888361B2 (en) | 2011-05-09 | 2014-11-18 | Azbil Corporation | Calorific value measuring system and calorific value measuring method |
| US9188557B2 (en) | 2012-03-27 | 2015-11-17 | Azbil Corporation | Calorific value measuring system and calorific value measuring method |
Also Published As
| Publication number | Publication date |
|---|---|
| NZ521890A (en) | 2005-01-28 |
| US20030158830A1 (en) | 2003-08-21 |
| EP1281130A1 (en) | 2003-02-05 |
| WO2001077855A1 (en) | 2001-10-18 |
| EP1281130A4 (en) | 2009-06-17 |
| AUPQ684400A0 (en) | 2000-05-11 |
| CA2405824A1 (en) | 2001-10-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8005293B2 (en) | Gradient based training method for a support vector machine | |
| Cervantes et al. | A comprehensive survey on support vector machine classification: Applications, challenges and trends | |
| Løkse et al. | Training echo state networks with regularization through dimensionality reduction | |
| García et al. | Dealing with missing values | |
| US20170147941A1 (en) | Subspace projection of multi-dimensional unsupervised machine learning models | |
| Antonucci et al. | Robust classification of multivariate time series by imprecise hidden Markov models | |
| Celeux et al. | Variable selection in model-based clustering and discriminant analysis with a regularization approach | |
| Le et al. | Budgeted semi-supervised support vector machine | |
| Benítez-Peña et al. | Cost-sensitive probabilistic predictions for support vector machines | |
| Tang et al. | A mixed integer programming approach to maximum margin 0–1 loss classification | |
| Kajdanowicz et al. | Boosting-based sequential output prediction | |
| Kashima et al. | Recent advances and trends in large-scale kernel methods | |
| Ghojogh et al. | Unified framework for spectral dimensionality reduction, maximum variance unfolding, and kernel learning by semidefinite programming: Tutorial and survey | |
| Raab et al. | Transfer learning for the probabilistic classification vector machine | |
| Yaman et al. | The Effects of Kernel Functions and Optimal Hyperparameter Selection on Support Vector Machines | |
| AU2001248153B2 (en) | A gradient based training method for a support vector machine | |
| AU2001248153A1 (en) | A gradient based training method for a support vector machine | |
| Firouzi et al. | NMF-based label space factorization for multi-label classification | |
| Yang et al. | Fuzzy clustering method with approximate orthogonal regularization | |
| Xu et al. | Graph-Regularized Tensor Regression: A Domain-Aware Framework for Interpretable Modeling of Multiway Data on Graphs | |
| Back | Classification using support vector machines | |
| Memisevic | An introduction to structured discriminative learning | |
| Sidorov | Estimating the age of birch bark manuscripts using computational paleography | |
| Bobyl et al. | On The Radon–Nikodym Machine Learning Parallelization | |
| Shao et al. | Enhancing E-Commerce Retail Product Classification Based on Big Data Analysis and Natural Language Processing |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AS | Assignment |
Owner name: TELSTRA NEW WAVE PTY LTD, AUSTRALIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:KOAWALCZYK, ADAM;ANDERSON, TREVOR BRUCE;REEL/FRAME:014085/0509;SIGNING DATES FROM 20021126 TO 20021202 Owner name: TELSTRA NEW WAVE PTY LTD, AUSTRALIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNORS:KOAWALCZYK, ADAM;ANDERSON, TREVOR BRUCE;SIGNING DATES FROM 20021126 TO 20021202;REEL/FRAME:014085/0509 |
|
| AS | Assignment |
Owner name: TELSTRA CORPORATION LIMITED,AUSTRALIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:TELSTRANEW WAVE PTY LTD;REEL/FRAME:017811/0897 Effective date: 20041118 Owner name: TELSTRA CORPORATION LIMITED, AUSTRALIA Free format text: ASSIGNMENT OF ASSIGNORS INTEREST;ASSIGNOR:TELSTRANEW WAVE PTY LTD;REEL/FRAME:017811/0897 Effective date: 20041118 |
|
| ZAAA | Notice of allowance and fees due |
Free format text: ORIGINAL CODE: NOA |
|
| ZAAB | Notice of allowance mailed |
Free format text: ORIGINAL CODE: MN/=. |
|
| STCF | Information on status: patent grant |
Free format text: PATENTED CASE |
|
| CC | Certificate of correction | ||
| FPAY | Fee payment |
Year of fee payment: 4 |
|
| MAFP | Maintenance fee payment |
Free format text: PAYMENT OF MAINTENANCE FEE, 8TH YEAR, LARGE ENTITY (ORIGINAL EVENT CODE: M1552); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY Year of fee payment: 8 |
|
| FEPP | Fee payment procedure |
Free format text: MAINTENANCE FEE REMINDER MAILED (ORIGINAL EVENT CODE: REM.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| LAPS | Lapse for failure to pay maintenance fees |
Free format text: PATENT EXPIRED FOR FAILURE TO PAY MAINTENANCE FEES (ORIGINAL EVENT CODE: EXP.); ENTITY STATUS OF PATENT OWNER: LARGE ENTITY |
|
| STCH | Information on status: patent discontinuation |
Free format text: PATENT EXPIRED DUE TO NONPAYMENT OF MAINTENANCE FEES UNDER 37 CFR 1.362 |
|
| FP | Lapsed due to failure to pay maintenance fee |
Effective date: 20230823 |