WO1998020165A2 - Biallelic markers - Google Patents
Biallelic markers Download PDFInfo
- Publication number
- WO1998020165A2 WO1998020165A2 PCT/US1997/020313 US9720313W WO9820165A2 WO 1998020165 A2 WO1998020165 A2 WO 1998020165A2 US 9720313 W US9720313 W US 9720313W WO 9820165 A2 WO9820165 A2 WO 9820165A2
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- polymorphic
- segment
- allele
- column
- nucleic acid
- Prior art date
Links
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
Definitions
- the variant form may confer an evolutionary advantage or disadvantage relative to a progenitor form or may be neutral.
- a variant form confers a lethal disadvantage and is not transmitted to subsequent generations of the organism.
- a variant form confers an evolutionary advantage to the species and is eventually incorporated into the DNA of many or most members of the species and effectively becomes the progenitor form.
- a restriction fragment length polymorphism Is a variation in DNA sequence that alters the length of a restriction fragment (Botstein et al . , Am. J. Hum . Genet . 32, 314-331 (1980)).
- the restriction fragment length polymorphism may create or delete a restriction site, thus changing the length of the restriction fragment.
- RFLPs have been widely used in human and animal genetic analyses (see WO 90/13668; W090/11369; Donis-Keller, Cell 51, 319-337 (1987); Lander et al . , Genetics 121, 85-99 (1989) ) .
- the presence of the RFLP in an individual can be used to predict the likelihood that the animal will also exhibit the trait.
- VNTR variable number tandem repeat
- STRs short tandem repeats
- VNTRs have been used in identity "and paternity analysis (US 5,075,217; Armour et al . , FEBS Lett . 307, 113-115 (1992); Horn et al . , W0 91/14003; Jeffreys, EP 370,719), and in a large number of genetic mapping studies.
- Other polymorphisms take the form of single nucleotide variations between individuals of the same species .
- polymorphisms are far more frequent than RFLPs , STRs and VNTRs .
- Some single nucleotide polymorphisms occur in protein-coding sequences, in which case, one of the polymorphic forms may give rise to the expression of a defective or other variant protein and, potentially, a genetic disease. Examples of genes, in which polymorphisms within coding sequences give rise to genetic disease include -globin (sickle cell anemia) and CFTR (cystic fibrosis) .
- Other single nucleotide polymorphisms occur in noncoding regions. Some of these polymorphisms may also result in defective protein expression (e.g., as a result of defective splicing) . Other single nucleotide polymorphisms have no phenotypic effects.
- Single nucleotide polymorphisms can be used in the same manner as RFLPs and VNTRs, but offer several advantages. Single nucleotide polymorphisms occur with greater frequency and are spaced more uniformly throughout the genome than other forms of polymorphism. The greater frequency and uniformity of single nucleotide polymorphisms means that there is a greater probability that such a polymorphism will be found in close proximity to a genetic locus of interest than would be the case for other polymorphisms. The different forms of characterized single nucleotide polymorphisms are often easier to distinguish than other types of polymorphism (e.g., by use of assays employing allele-specific hybridization probes or primers) .
- the invention provides nucleic acid sequences comprising nucleic acid segments of from about 10 to about 200 bases as shown in the Table, column 7, including a polymorphic site. Complements of these segments are also included.
- the segments can be DNA or RNA, and can be double- or single-stranded. Segments can be, for example, 10-20, 10-50 or 10-100 bases long. Preferred segments include a biallelic polymorphic site. The base occupying the polymorphic site in the segments can be the reference
- the invention further provides allele-specific- oligonucleotides that hybridize to a segment of a fragment shown in the Table, column 7, or its complement. These oligonucleotides can be probes or primers. Also provided are isolated nucleic acids comprising a sequence shown in the Table, column 7, or the complement thereto, in which the polymorphic site within the sequence is occupied by a base other than the reference base shown in the Table, column 3.
- the invention further provides a method of analyzing a nucleic acid from an individual.
- the method determines which base is present at any one of the polymorphic sites shown in the Table.
- a set of bases occupying a set of the polymorphic sites shown in the Table is determined. This type of analysis can be performed on a number of individuals, who are tested for the presence of a disease phenotype. The presence or absence of disease phenotype is then correlated with a base or set of bases present at the polymorphic sites in the individuals tested.
- An oligonucleotide can be DNA or RNA, and single- or double- stranded. Oligonucleotides can be naturally occurring or synthetic, but are typically prepared by synthetic means.
- the oligonucleotides of the present invention can comprise all of an oligonucleotide sequence presented in column 7 of the Table or a segment of such an oligonucleotide which includes a polymorphic site.
- Oligonucleotides can be all of a nucleic acid segment as represented in column 7 of the Table; a nucleic acid sequence which comprises a nucleic acid segment represented in column 7 of the Table and additional nucleic acids (present at either or both ends of a nucleic acid segment of column 7) ; or a portion (fragment) of a nucleic acid segment represented in column 7 of the Table which includes a polymorphic site.
- Preferred oligonucleotides of the invention include segments of DNA, or their complements, which include any one of the polymorphic sites shown in the Table. The segments can be between 5 and 250 bases, and, in specific embodiments, are between 5-10, 5-20, 10-20, 10- 50, 20-50 or 10-100 bases.
- the polymorphic site can occur within any position of the segment.
- the segments can be from any of the allelic forms of DNA shown in the Table.
- Hybridization probes are oligonucleotides which bind in a base-specific manner to a complementary strand of nucleic acid. Such probes include peptide nucleic acids, as described in Nielsen et al . , Science 254, 1497-1500 (1991) .
- primer refers to a single- stranded oligonucleotide which acts as a point of initiation of template-directed DNA synthesis under appropriate conditions ( e . g.
- primer site refers to the area of the target DNA to which a primer hybridizes.
- primer pair refers to a set of primers including a 5' (upstream) -primer that hybridizes with the 5' end of the DNA sequence to be amplified and a 3' (downstream) primer that hybridizes with the complement of the 3' end of the sequence to be amplified.
- linkage describes the tendency of genes, alleles, loci or genetic markers to be inherited together as a result of their location on the same chromosome. It can be measured by percent recombination •between the two genes, alleles, loci or genetic markers.
- polymorphism refers to the occurrence of two or more genetically determined alternative sequences or alleles in a population.
- a polymorphic marker or site is the locus at which divergence occurs. Preferred markers have at least two alleles, each occurring at frequency of greater than 1%, and more preferably greater than 10% or 20% of a selected population.
- a polymorphic locus may be as small as one base pair.
- Polymorphic markers include restriction fragment length polymorphisms, variable number of tandem repeats (VNTR's), hypervariable regions, minisatellites, dinucleotide repeats, trinucleotide repeats, tetranucleotide repeats, simple sequence repeats, and insertion elements such as Alu.
- allelic form is arbitrarily designated as the reference form and other allelic forms are designated as alternative or variant alleles.
- allelic form occurring most frequently in a selected population is sometimes referred to as the wildtype form. Diploid organisms may be homozygous or heterozygous for allelic forms.
- a diallelic or biallelic polymorphism has two forms.
- a triallelic polymorphism has three forms.
- a single nucleotide polymorphism occurs at a polymorphic site occupied by a single nucleotide, which is the site of variation between allelic sequences . -The site is usually preceded by and followed by highly conserved sequences of the allele (e.g., sequences that vary in less than 1/100 or 1/1000 members of the populations) .
- a single nucleotide polymorphism usually arises due to substitution of one nucleotide for another at the polymorphic site.
- a transition is the replacement of one purine by another purine or one pyrimidine by another pyrimidine.
- a transversion is the replacement of a purine by a pyrimidine or vice versa.
- Single nucleotide polymorphisms can also arise from a deletion of a nucleotide or an insertion of a nucleotide relative to a reference allele.
- the polymorphic site is occupied by a base other than the reference base. For example, where the reference allele contains the base "T" at the polymorphic site, the altered allele can contain a "C", "G” or "A" at the polymorphic site.
- Hybridizations are usually performed under stringent conditions, for example, at a salt concentration of no more than 1 M and a temperature of at least 25 °C.
- stringent conditions for example, at a salt concentration of no more than 1 M and a temperature of at least 25 °C.
- 5X SSPE 750 mM NaCl, 50 mM NaPhosphate, 5 mM EDTA, pH 7.4
- a temperature of 25-30°C, or equivalent conditions are suitable for allele-specific probe hybridizations.
- Equivalent conditions can be determined by varying one or more of the parameters given as an example, as known in the art, while maintaining a similar degree of identity or similarity between the target nucleotide sequence and the primer or probe used.
- an isolated nucleic acid of the invention may be substantially isolated with respect to the complex cellular milieu in which it naturally occurs.
- the- isolated material will form part of a composition (for example, a crude extract containing other substances) , buffer system or reagent mix.
- the material may be purified to essential homogeneity, for example as determined by PAGE or column chromatography such as HPLC.
- an isolated nucleic acid comprises at least about 50, 80 or 90 percent (on a molar basis) of all macromolecular species present.
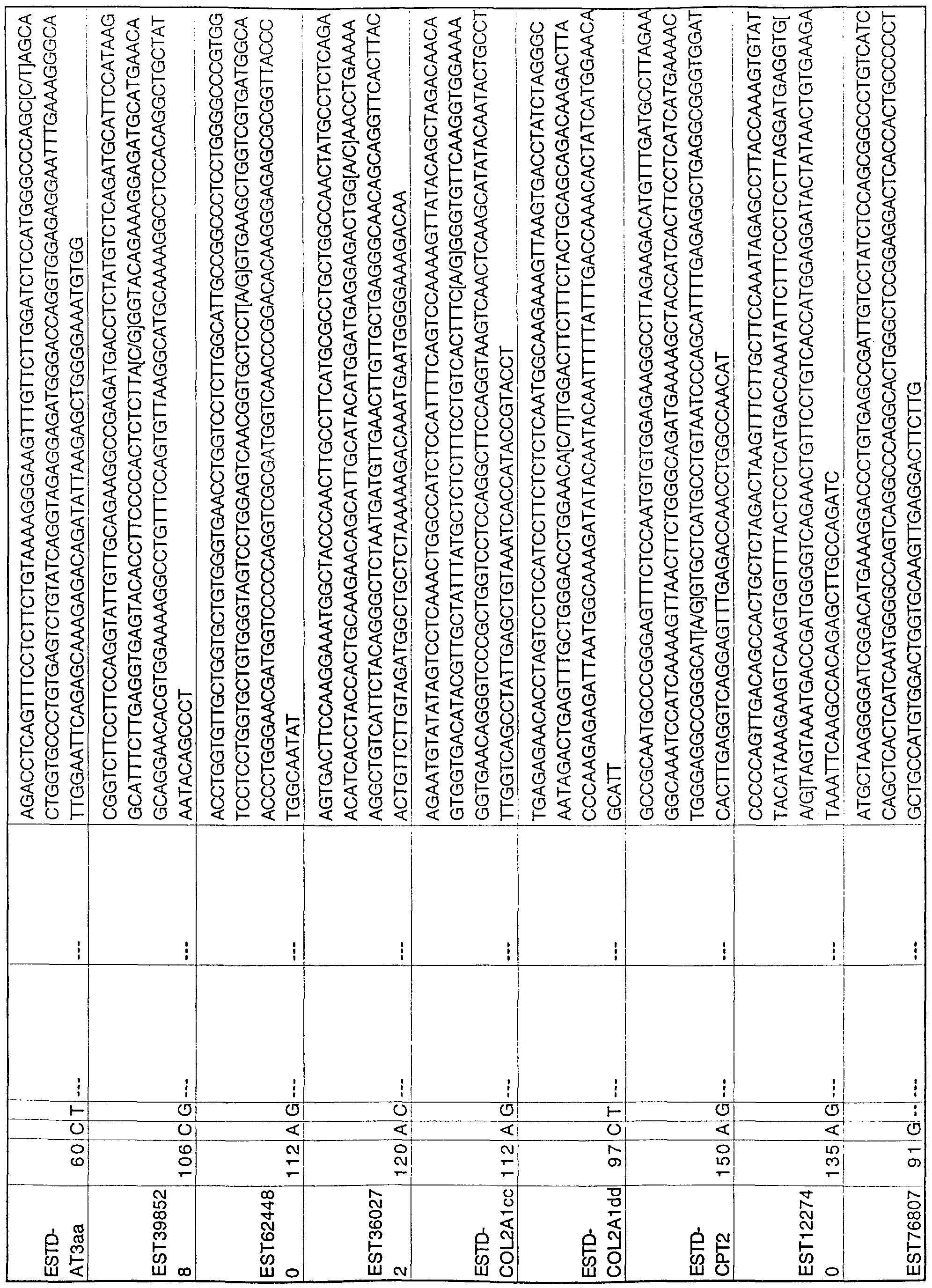
- the novel polymorphisms of the invention are listed in the Table.
- the first column of the Table lists the names assigned to the fragments in which the polymorphisms occur.
- the fragments are all human genomic fragments.
- the sequence of one allelic form of each of the fragments (arbitrarily referred to as the prototypical or reference form) has been previously published. These sequences are listed at http://www-genome.wi.mit.edu/ (all STS's (sequence tag sites)); http://shgc.stanford.edu (Stanford STS's); and http://ww.tigr.org/ (TIGR STS's).
- the Web sites also list primers for amplification of the fragments, and the genomic location of fragments. Some fragments are expressed sequence tags, and some are random genomic fragments. All information in the websites concerning the fragments listed in the Table is incorporated by reference in its entirety for all purposes.
- the second column lists the position in the fragment in which a polymorphic site has been found. Positions are numbered consecutively with the first base of the fragment sequence as listed in one of the above databases being assigned the number one.
- the third column lists the base occupying the polymorphic site in the sequence in the data base. This base is arbitrarily designated -the-- reierence or prototypical form, but it is not necessarily the most frequently occurring form.
- the fourth column in the Table lists the alternative base(s) at the polymorphic site.
- the fifth column of the Table lists a 5' (upstream or forward) primer that hybridizes with the 5' end of the DNA sequence to be amplified.
- the sixth column of the Table lists a 3' (downstream or reverse) primer that hybridizes with the complement of the 3' end of the sequence to be amplified.
- the seventh column of the Table lists a number of bases of sequence on either side of the polymorphic site in each fragment .
- the indicated sequences can be either DNA or RNA. In the latter, the T's shown in the Table are replaced by U's.
- the base occupying the polymorphic site is indicated in EUPAC-IUB ambiguity code.
- tissue samples include whole blood, semen, saliva, tears, urine, fecal material, sweat, buccal, skin and hair.
- tissue sample For assay of cDNA or mRNA, the tissue sample must be obtained from an organ in which the target nucleic acid is expressed. For example, if the target nucleic acid is a cytochrome P450, the liver is a suitable source.
- PCR DNA Amplifica tion
- PCR Protocols A Guide to Methods and Applications (eds. Innis,-- et-al . , Academic Press, San Diego, CA, 1990); Mattila et al . , Nuclei c Acids Res . 19, 4967 (1991); Eckert et al . , PCR Methods and Applications 1, 17 (1991); PCR (eds. McPherson et al . , IRL Press, Oxford); and U.S. Patent 4,683,202.
- LCR ligase chain reaction
- NASBA nucleic acid based sequence amplification
- the latter two amplification methods involve isothermal reactions based on isothermal transcription, which produce both single stranded RNA (ssRNA) and double stranded DNA (dsDNA) as the amplification products in a ratio of about 30 or 100 to 1, respectively.
- ssRNA single stranded RNA
- dsDNA double stranded DNA
- the first type of analysis is carried out to identify polymorphic sites not previously characterized (i.e., to identify new polymorphisms) .
- This analysis compares target sequences in different individuals to identify points of variation, i.e., polymorphic sites.
- groups of individuals representing the greatest ethnic diversity among humans and greatest breed and species variety in plants and animals patterns characteristic of the most common alleles/haplotypes of the locus can be identified, and the frequencies of such alleles/haplotypes in the population can be determined. Additional allelic frequencies can be determined -for subpopulations characterized by criteria such as geography, race, or gender.
- the de novo identification of polymorphisms of the invention is described in the Examples section.
- the second type of analysis determines which form(s) of a characterized (known) polymorphism are present in individuals under test. There are a variety of suitable procedures, which are discussed in turn.
- Allele-specific probes for analyzing polymorphisms is described by e.g., Saiki et al . , Nature 324, 163-166 (1986); Dattagupta, EP 235,726, Saiki, WO 89/11548. Allele-specific probes can be designed that hybridize to a segment of target DNA from one individual but do not hybridize to the corresponding segment from another individual due to the presence of different polymorphic forms in the respective segments from the two individuals. Hybridization conditions should be sufficiently stringent that there is a significant difference in hybridization intensity between alleles, and preferably an essentially binary response, whereby a probe hybridizes to only one of the alleles.
- Some probes are designed to hybridize to a segment of target DNA such that the polymorphic site aligns with a central position (e.g., in a 15-mer at the 7 position; in a 16-mer, at either the 8 or 9 position) of the probe. This design of probe achieves good discrimination in hybridization between different allelic forms.
- Allele-specific probes are often used in pairs, one member of a pair showing a perfect match to a reference form of a target sequence and the other member showing a perfect match to a variant form. Several pairs of probes can then be immobilized on the same support for simultaneous analysis of multiple polymorphisms within the same target sequence .
- the polymorphisms can also be identified by hybridization to nucleic acid arrays, some examples of which are described in WO 95/11995.
- One form of such arrays is described in the Examples section in connection with de novo identification of polymorphisms.
- the same array or a different array can be used for analysis of characterized polymorphisms.
- WO 95/11995 also describes subarrays that are optimized for detection of a variant form of a precharacterized polymorphism.
- Such a subarray contains probes designed to be complementary to a second reference sequence, which is an allelic variant of the first reference sequence.
- the second group of probes is designed by the same principles as described in the Examples, except that the probes exhibit complementarity to the second reference sequence.
- a second group can be particularly useful for analyzing short subsequences of the primary reference sequence in which multiple mutations are expected to occur within a short distance commensurate with the length of the probes (e.g., two or more mutations within 9 to 21 bases) .
- Allele-Specific Primers An allele-specific primer hybridizes to a site on target DNA overlapping a polymorphism and only primes amplification of an allelic form to which the primer exhibits perfect complementarity. See Gibbs , Nucl eic Acid Res . 17, 2427-2448 (1989) . This primer is used in conjunction with a second primer which hybridizes at a distal site. Amplification proceeds from the -two-primers , resulting in a detectable product which indicates the particular allelic form is present. A control is usually performed with a second pair of primers, one of which shows a single base mismatch at the polymorphic site and the other of which exhibits perfect complementarity to a distal site.
- the single-base mismatch prevents amplification and no detectable product is formed.
- the method works best when the mismatch is included in the 3 ' -most position of the oligonucleotide aligned with the polymorphism because this position is most destabilizing to elongation from the primer (see, e.g., WO 93/22456).
- the direct analysis of the sequence of polymorphisms of the present invention can be accomplished using either the dideoxy chain termination method or the Maxam Gilbert method (see Sambrook et al . , Molecular Cloning, A Laboratory Manual (2nd Ed., CSHP, New York 1989); Zyskind et al . i Recombinant DNA Laboratory Manual , (Acad. Press, 1988) ) . 5. Denaturing Gradient Gel Electrophoresis Amplification products generated using the polymerase chain reaction can be analyzed by the use of denaturing gradient gel electrophoresis. Different alleles can be identified based on the different sequence-dependent melting properties and electrophoretic migration of DNA in solution. Erlich, ed. , PCR Technology, Principles and Applica tions for DNA Amplification, (W.H. Freeman and Co, New York, 1992), Chapter 7.
- Alleles of target sequences can be differentia-ted using single- strand conformation polymorphism analysis, which identifies base differences by alteration in electrophoretic migration of single stranded PCR products, as described in Orita et al . , Proc . Na t . Acad . Sci . 86,
- Amplified PCR products can be generated as described above, and heated or otherwise denatured, to form single stranded amplification products.
- Single- stranded nucleic acids may refold or form secondary structures which are partially dependent on the base sequence.
- the different electrophoretic mobilities of single-stranded amplification products can be related to base-sequence differences between alleles of target sequences .
- polymorphisms of the invention are often used in conjunction with ⁇ - polymorphisms in distal genes.
- Preferred polymorphisms for use in forensics are biallelic because the population frequencies of two polymorphic forms can usually be determined with greater accuracy than those of multiple polymorphic forms at multi-allelic loci.
- the capacity to identify a distinguishing or unique set of forensic markers in an individual is useful for forensic analysis. For example, one can determine whether a blood sample from a suspect matches a blood or other tissue sample from a crime scene by determining whether the set of polymorphic forms occupying selected polymorphic sites is the same in the suspect and the sample. If the set of polymorphic markers does not match between a suspect and a sample, it can be concluded (barring experimental error) that the suspect was not the source of the sample. If the set of markers does match, one can conclude that the DNA from the suspect is consistent with that found at the crime scene.
- frequencies of the polymorphic forms at the loci tested have been determined (e.g., by analysis of a suitable population of individuals) , one can perform a statistical analysis to determine the probability that a match of suspect and crime scene sample would occur by chance .
- p(ID) is the probability that two random individuals have the same polymorphic or allelic form at a given polymorphic site. In biallelic loci, four genotypes are possible: AA, AB, BA, and BB . If alleles A and B occur in a haploid genome of the organism with frequencies x and y, the probability of each genotype in a diploid organism is
- the cumulative probability of identity (cum p(ID)) for each of multiple unlinked loci is determined by multiplying the probabilities provided by each locus.
- cum p(ID) p(IDl)p(ID2)p(ID3) ....
- the object of paternity testing is usually" to ⁇ determine whether a male is the father of a child. In most cases, the mother of the child is known and thus, the mother's contribution to the child's genotype can be traced. Paternity testing investigates whether the part of the child's genotype not attributable to the mother is consistent with that of the putative father. Paternity testing can be performed by analyzing sets of polymorphisms in the putative father and the child. If the set of polymorphisms in the child attributable to the father does not match the set of polymorphisms of the putative father, it can be concluded, barring experimental error, that the putative father is not the real father. If the set of polymorphisms in the child attributable to the father does match the set of polymorphisms of the putative father, a statistical calculation can be performed to determine the probability of coincidental match.
- polymorphisms of the invention may contribute to the phenotype of an organism in different ways . Some polymorphisms occur within a protein coding sequence and contribute to phenotype by affecting protein structure.
- the effect may be neutral, beneficial or detrimental, or both beneficial and detrimental, depending on the circumstances .
- a heterozygous sickle cell mutation confers resistance to malaria, but a homozygous sickle cell mutation is usually lethal.
- Other polymorphisms occur in noncoding regions but may exert phenotypic effects indirectly via influence on replication, transcription, and translation.
- a single polymorphism may affect more than one phenotypic trait.
- a single phenotypic trait may be affected by polymorphisms in different genes. Further, some polymorphisms predispose an individual to a distinct mutation that is causally related to a certain phenotype.
- Phenotypic traits include diseases that ha-ve teiown but hitherto unmapped genetic components (e.g., agammaglobulimenia, diabetes insipidus, Lesch-Nyhan syndrome, muscular dystrophy, Wiskott-Aldrich syndrome,
- Phenotypic traits also include symptoms of, or susceptibility to, multifactorial diseases of which a component is or may be genetic, such as autoimmune diseases, inflammation, cancer, diseases of the nervous system, and infection by pathogenic microorganisms.
- autoimmune diseases include rheumatoid arthritis, multiple sclerosis, diabetes (insulin-dependent and non-independent) , systemic lupus erythematosus and Graves disease.
- cancers include cancers of the bladder, brain, breast, colon, esophagus, kidney, leukemia, liver, lung, oral cavity, ovary, pancreas, prostate, skin, stomach and uterus.
- Phenotypic traits also include characteristics such as longevity, appearance (e.g., baldness, obesity), strength, speed, endurance, fertility, and susceptibility or receptivity to particular drugs or therapeutic treatments.
- Correlation is performed for a population of individuals who have been tested for the presence or absence of a phenotypic trait of interest and for polymorphic markers sets.
- a set of polymorphisms i.e. a polymorphic set
- the alleles of each polymorphism of the set are then reviewed--to-determine whether the presence or absence of a particular allele is associated with the trait of interest.
- Correlation can be performed by standard statistical methods such as a K - squared test and statistically significant correlations between polymorphic form(s) and phenotypic characteristics are noted.
- allele Al at polymorphism A correlates with heart disease.
- allele Bl at polymorphism B correlates with increased milk production of a farm animal.
- Such correlations can be exploited in several ways .
- detection of the polymorphic form set in a human or animal patient may justify immediate administration of treatment, or at least the institution of regular monitoring of the patient.
- Detection of a polymorphic form correlated with serious disease in a couple contemplating a family may also be valuable to the couple in their reproductive decisions.
- the female partner might elect to undergo in vitro fertilization to avoid the possibility of transmitting such a polymorphism from her husband to her offspring.
- immediate therapeutic intervention or monitoring may not be justified.
- the patient can be motivated to begin simple life-style changes (e.g., diet, exercise) that can be accomplished at little cost to the patient but confer potential benefits in reducing the risk of conditions to which the patient may have increased susceptibility by virtue of variant alleles .
- Identification -of -a polymorphic set in a patient correlated with enhanced receptiveness to one of several treatment regimes for a disease indicates that this treatment regime should be followed.
- Y ijkpn ⁇ + YSi + P j + X k + ⁇ 1 + ... jS 17 + PE n + a n +e p
- Y ijknp is the milk, fat, fat percentage, SNF, SNF percentage, energy concentration, or lactation energy record
- ⁇ is an overall mean
- YSi is the effect common to all cows calving in year-season
- X k is the effect common to cows in either the high or average selection line
- ⁇ to ⁇ xl are the binomial regressions of production record on mtDNA D-loop sequence polymorphisms
- PE n is permanent environmental effect common to all records of cow n
- a n is effect of animal n and is composed of the additive genetic contribution of sire and dam breeding values and a Mendelian sampling effect
- e p is a random residual. It was found that eleven of seventeen polymorphisms tested influenced at least one production trait. Bovines having the best
- D. Genetic Mapping of Phenotypic Traits The previous section concerns identifying correlations between phenotypic traits and polymorphisms that directly or indirectly contribute to those traits.
- the present section describes identification of a physical linkage between a genetic locus associated with a trait of interest and polymorphic markers that are not associated with the trait, but are in physical proximity with the genetic locus responsible for the trait and co-segregate with it.
- Such analysis is useful for mapping a genetic locus associated with a phenotypic trait to a chromosomal position, and thereby cloning gene(s) responsible for the trait. See Lander et al . , Proc . Na tl . Acad . Sci .
- Linkage studies are typically performed on members of a family. Available members of the family are characterized for the presence or absence of a phenotypic trait and for a set of polymorphic markers. The distribution of polymorphic markers in an informative meiosis is then analyzed to determine which polymorphic markers co- segregate with a phenotypic trait. See, e . g. , Kerem et al . , Science 245, 1073-1080 (1989); Monaco et al . , Na ture 316, 842 (1985); Yamoka et al . , Neurology 40, 222-226 (1990); Rossiter et al . , FASEB Journal 5, 21-27 (1991).
- LOD log of the odds
- the likelihood at a given value of ⁇ is: probability of data if loci linked at ⁇ to probability of data if loci unlinked.
- the computed likelihoods are usually expressed as the log 10 of this ratio (i.e., a lod score) .
- a lod score of 3 indicates 1000:1 odds against an apparent observed linkage being a coincidence.
- the use of logarithms- allows data collected from different families to be combined by simple addition. Computer programs are available for the calculation of lod scores for differing values of ⁇ (e.g., LIPED, MLINK (Lathrop, Proc . Na t . Acad . Sci . (USA) 81, 3443-3446 (1984)) .
- a recombination fraction may be determined from mathematical tables. See Smith et al . , Ma thema tical tables for research workers in human genetics (Churchill, London, 1961); Smith, Ann . Hum . Genet . 32, 127-150 (1968) . The value of ⁇ at which the lod score is the highest is considered to be the best estimate of the recombination fraction.
- Positive lod score values suggest that the two loci are linked, whereas negative values suggest that linkage is less likely (at that value of ⁇ ) than the possibility that the two loci are unlinked.
- a combined lod score of +3 or greater is considered definitive evidence that two loci are linked.
- a negative lod score of -2 or less is taken as definitive evidence against linkage of the two loci being compared.
- Negative linkage data are useful in excluding a chromosome or a segment thereof from consideration. The search focuses on the remaining non-excluded chromosomal locations .
- the invention further provides variant forms of nucleic acids and corresponding proteins.
- the nucleic acids comprise one of the sequences described in the Table, column 8, in which the polymorphic position is occupied by one of the alternative bases for that position. Some nucleic acids encode full-length variant forms of proteins.
- variant proteins have the prototypical amino acid sequences encoded by nucleic acid sequences shown in the Table, column 8, (read so as to be in- frame with the full-length coding sequence of which it is a component) except at an amino acid encoded by a codon including one of the polymorphic positions shown in the Table. That position is occupied by the amino acid coded by the corresponding codon in any of the alternative forms shown in the Table .
- Variant genes can be expressed in an expression vector in which a variant gene is operably linked to a native or other promoter.
- the promoter is a eukaryotic promoter for expression in a mammalian cell.
- the transcription regulation sequences typically include a heterologous promoter and optionally an enhancer which is recognized by the host.
- the selection of an appropriate promoter for example trp, lac, phage promoters, glycolytic enzyme promoters and tRNA promoters, depends on the host selected.
- Commercially available expression vectors can be used. Vectors can include host-recognized replication systems, amplifiable genes, selectable markers, host sequences useful for insertion into the host genome, and the like.
- the means of introducing the expression construct into a host cell varies depending upon the particular construction and the target host. Suitable means include fusion, conjugation, transfection, transduction, electroporation or injection, as described in Sambrook, supra .
- a wide variety of host cells can be employed for expression of the variant gene, both prokaryotic and eukaryotic. Suitable host cells include bacteria such as E. coli , yeast, filamentous fungi, insect cells, mammalian cells, typically immortalized, e . g. , mouse, CHO, human and monkey cell lines and derivatives thereof. Preferred host cells are able to process the variant gene product to produce an appropriate mature polypeptide.
- the protein may be isolated by conventional means of protein biochemistry and purification to obtain a substantially pure product, i . e . , 80, 95 or 99% free of cell component contaminants, as described in Jacoby, Methods in Enzymology Volume 104, Academic Press, New York (1984); Scopes, Protein Purifica tion, Principles and Practice, 2nd Edition, Springer-Verlag, New York (1987); and DeuLscher (ed) , Guide to Protein Purifica tion, Methods in Enzymology, Vol. 182 (1990). If the protein is secreted, it can be isolated from the supernatant in which the host cell is grown. If not secreted, the protein can be isolated from a lysate of the host cells.
- the invention further provides transgenic nonhuman animals capable of expressing an exogenous variant gene and/or having one or both alleles of an endogenous variant gene inactivated.
- Expression of an exogenous variant gene is usually achieved by operably linking the gene to a promoter and optionally an enhancer, and microinjecting the construct into a zygote .
- Inactivation of endogenous variant genes can be achieved by forming a transgene in which a cloned variant gene is inactivated by insertion of a positive selection marker. See Capecchi, Science 244, 1288-1292 (1989) .
- the transgene is then introduced into an embryonic stem cell, where it undergoes homologous recombination with an endogenous variant gene. Mice and other rodents are preferred animals. Such animals provide useful drug screening systems .
- the present invention includes biologically active fragments of the polypeptides, or analogs thereof, including organic molecules which simulate the interactions of the peptides.
- Biologically active fragments include any portion of the full-length polypeptide which confers a biological function on the variant gene product, including ligand binding, and antibody binding.
- Ligand binding includes binding by nucleic acids, proteins or polypeptides, small biologically active molecules, or large cellular structures.
- Antibodies that specifically bind to variant gene products but not to corresponding prototypical gene products are also provided.
- Antibodies can be made by injecting mice or other animals with the variant gene product or synthetic -peptide- fragments thereof. Monoclonal antibodies are screened as are described, for example, in Harlow & Lane, Antibodies , A Labora tory Manual , Cold Spring Harbor Press, New York (1988) ; Goding, Monoclonal antibodies, Principles and Practice (2d ed.) Academic Press, New York (1986) . Monoclonal antibodies are tested for specific immunoreactivity with a variant gene product and lack of immunoreactivity to the corresponding prototypical gene product . These antibodies are useful in diagnostic assays for detection of the variant form, or as an active ingredient in a pharmaceutical composition.
- kits comprising at least one allele-specific oligonucleotide as described above. Often, the kits contain one or more pairs of allele- specific oligonucleotides hybridizing to different forms of a polymorphism. In some kits, the allele-specific oligonucleotides are provided immobilized to a substrate.
- the same substrate can comprise allele- specific oligonucleotide probes for detecting at least 10, 100 or all of the polymorphisms shown in the Table.
- kits include, for example, restriction enzymes, reverse-transcriptase or polymerase, the substrate nucleoside triphosphates , means used to label (for example, an avidin-enzyme conjugate and enzyme substrate and chromogen if the label is biotin) , and the appropriate buffers for reverse transcription, PCR, or hybridization reactions.
- the kit also contains instructions for carrying out the methods.
- the polymorphisms shown in the Table were identified by resequencing of target sequences from three to ten unrelated individuals of diverse ethnic and geographic backgrounds by hybridization to probes immobilized to microfabricated arrays or conventional sequencing.
- the strategy and principles for design and use of such arrays are generally described in WO 95/11995.
- the strategy provides arrays of probes for analysis of target sequences showing a high degree of sequence identity to the reference sequences of the fragments shown in the Table, column 1.
- the reference sequences were sequence-tagged sites (STSs) developed in the course of the Human Genome Project (see, e . g . , Science 270, 1945-1954 (1995); Nature 380, 152-154 (1996)).
- a typical probe array used in this analysis has two groups of four sets of probes that respectively tile both strands of a reference sequence.
- a first probe set comprises a plurality of probes exhibiting perfect complementarily with one of the reference sequences.
- Each probe in the first probe set has an interrogation position that corresponds to a nucleotide in the reference sequence. That is, the interrogation position is aligned with the corresponding nucleotide in the reference sequence, when the probe and reference sequence are aligned to maximize complementarily between the two.
- For each probe in the first set there are three corresponding probes from three additional probe sets. Thus, there are four probes corresponding to each nucleotide in the reference sequence.
- probes from the three additional probe -sets aaee identical to the corresponding probe from the first probe set except at the interrogation position, which occurs in the same position in each of the four corresponding probes from the four probe sets, and is occupied by a different nucleotide in the four probe sets.
- probes were 25 nucleotides long. Arrays tiled for multiple different references sequences were included on the same substrate.
- target sequences from an individual were amplified from human genomic DNA using primers for the fragments indicated in the listed Web sites.
- the amplified target sequences were fluorescently labelled during or after PCR.
- the labelled target sequences were hybridized with a substrate bearing immobilized arrays of probes. The amount of lable bound to probes was measured. Analysis of the pattern of label revealed the nature and position of differences between the target and reference sequence. For example, comparison of the intensities of four corresponding probes reveals the identity of a corresponding nucleotide in the target sequences aligned with the interrogation position of the probes.
- the corresponding nucleotide is the complement of the nucleotide occupying the interrogation position of the probe showing the highest intensity (see WO 95/11995) .
- the existence of a polymorphism is also manifested by differences in normalized hybridization intensities of probes flanking the polymorphism when the probes hybridized to corresponding targets from different individuals. For example, relative loss of hybridization intensity in a "footprint" of probes flanking a polymorphism signals a difference between the target and reference (i.e., a polymorphism) (see EP 717,113) .
- hybridization intensities for corresponding targete-s from different individuals can be classified into groups or clusters suggested by the data, not defined a priori , such that isolates in a give cluster tend to be similar and isolates in different clusters tend to be dissimilar. Hybridizations to samples from different individuals were performed separately. The Table summarizes the data obtained for target sequences in comparison with a reference sequence for the individuals tested.
- the invention includes a number of general uses that can be expressed concisely as follows.
- the invention provides for the use of any of the nucleic acid segments described above in the diagnosis or monitoring of diseases, such as cancer, inflammation, heart disease, diseases of the CNS, and susceptibility to infection by microorganisms.
- the invention further provides for the use of any of the nucleic acid segments in the manufacture of a medicament for the treatment or prophylaxis of such diseases.
- the invention further provides for the use of any of the DNA segments as a pharmaceutical.
- Wl-7718b 248 AGGAACAAAAAATTACAAAGAACCATGCAGGAAGGAAAACTATGTATT[A/G1AT
- ATrGCACTG GTTTTTGAAATACCTTTGTAGTTACTCAAGC[A/C, ⁇ GTTACTCCCTACACTGATGC AAGGATTACAGAAACTGATGCCAAGGGGCTGAGTGAGTTCAACTACATGTTCTGGGGGCCCGGAGAT AGATGACTTTGCAGATGGAMGAGGTGAAAATGAAGAAGGAAGCTGTGTTGAAACAGAAAAATAAG
- Wl-7718a 42 TCAAAAGGAACAAAAATTACAAAGAACCATGCAGGAAGGAAAACTATGTATTA
- WI-7227C 291 TTATTATGGGAAAGGAAATGGCATTGCTGCTTTCAACCAGCGACTAATGCAAT
- Wl-7227b 93 GTGTTATTATGGGAAAGGAAATGGCATTGCTGCTTTCAACCAGCGACTAATG
- Wl-7227a 24 G GTGTTATTATGGGAAAGGAAATGGCATTGCTGCTTTCAACCAGCGACTAATG j CCACAATGCCTCTCCCACGATGTCAAGGACTCCTGTCTGTCCTGGAGGTGGGAGACAAGGAACCTCCG
- Wl-1 95b 1 30 AGTGAGCTGGGGAAGGCAGGATTT
- Wl-1126b 230 AAAATGCAAATCCAGCTGT CTTTTT[T/C
- Wl-3429b 64 TCCTGACTGTTAACAAGCACTCCAGGCAATTCTTAAGACCAAGCACGGAGC
- Wl-3429a 62 TCCTGACTGTTAACAAGCACTCCAGGCAATTCTTAAGACCAAGCACGGAGC
- Wl-6786b 1 1 1 TTTTTGGCAGGGGACACTCCTTCTGGGTGCTCTATTGCTCAGTTTCATCATT
- Wl-6786a 1 06 TTTTTGGCAGGGGACACTCCTTCTGGGTGCTCTATTGCTCAGTTTCATCATT
- AAAAGGACAG TTTCCATCTTA CCAGATATCA TTTCATTTCTG CAACATTTATCAAACATGGTAGGGAAMGTTCTCACTCTGCACTATAAAAAGGACAGCCAGATATCA
- CAGAAMTCA ATGAGACCCTGCTTTGMCGTTAMCGTTTTGGMTMTGGAAMGGAGCTAGGACMTTCTTGCTT
- AAAAATTAAC CAGGGTCTTGCTCTGTCTCCCAGGCTAGAGTGAGGTGACACMTCMGACTCACAGTAGCCTCMCCT
- WI-7079 293 TTTTACAGCTCTTGGCAT ⁇ TCCTCGCCTAGGCCTGTGAGGTMCTGGGAT
- Wl-7104b 249 GTGAGGCCTTGCACCAGGTGGGGGCCACAGCACCAGCAGCATCTTTG[CtFJF
- WI-9161 61 1 CCTGGC GGM CTGTCTAGTCTCTCCTGTMGCCAMGMATGMCATTCCA
- Wl-7023b 206 A[C/A]ACACACATTCTTGCTCTACCCAMGCTCTGGCTGGCAGCACTM
- WI-7093 54 GGGAGAGCTCTTGTTATFATTMTATTGTTGCCGCTGTTGTGTTGTTGTTA
- ACTTCTCCC TCTGACCTAGG MAGMCTACAGAGGACGATGTCCAAMCMAAMTGGCATCACCTGTCAAAMTGGAGTTCCACT
- WI-205C 1 46 ATCTTACTTTGTTTAAMMCTGCATATGCCTTTA I I I I I GTTTTAGTTCCC
- Wl-205b 1 46 ATCTTACTTTGTTTAAAAMCTGCATATGCCTTTATTTTTGTTTTAGTTCCC
- WI-1943C 1 65 TACAGGGCACCGNTGAGCATTCCAGATGACTCCAMGCCCCGGCTGGAGTAT
- Wl-1943b 1 65 TACAGGGCACCGNTGAGCATTCCAGATGACTCCAMGCCCCGGCTGGAGTAT
- Wi-6336b 234 GTACCCCAGTGCATTATGTCTTGGTAGAGCC[C/T]TGAGGACACTGACAGT
- Wl-6564b 54 GTTCCTTGGCAGGAGMCATGCATATGACTTTAAMTMAGACCMCA
- Wl-6817 1 45 MGATGTTGGACACCTTGTGTTCAMTCTTGGTTCAGGTGCGGCCTGTGCAG
- Wl-6826b 1 54 TMGCTGMTTGCAMTTATGGCMCACACACTGGACTGGGGTATACGTTG
- WI-6826 1 54 TMGCTGMTTGCAMTTATGGCMCACACACTGGACTGGGGTATACGTTG
- Wl-7056b 1 8
- WI-7136 58 NNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNGTAGCTTTCTATATATG
- WI-7146C 21 0 MCGC[A/G]GTTCATGTACMGGCCCCTCTGCMCTGGAGAGAAMTTA
- WI-7146 202 ICCMCGCAGTTCATGTACMGGCCCCTCTGCMCTGGAGAGAAMTTA
- WI-7153 1 61 AGTACCTATCTTTAMGTATAGTACATTTTACATATGTAAATGGTATGTTT
- Wl-7169b 1 61 TTTCMGTCATCTTAGCAGCTAGGATTCTCAMTGGMGTGTTATATATA
- Wl-7464b 1 68 GAMGMAGCCCTACAMTAGGCCCAGGAGMGCMCGTTCACCMCMTTAT
- Wl-7464a 1 03 GAMGMAGCCCTACAMTAGGCCCAGGAGMGCAACGTTCACCMCMTTAT
- Wl-7506b 1 1 8 GMGMMTATTTTAAMTATTGGACCACTCTTGTTCTACCATCCCTACCCACT
- Wl-7534b 1 43 AGAGTGCTGCTAAM ⁇ GGATTGGTGTGATCTTTTTGGTAGTTGTMTTT
- WI-7534 1 35 AGAGTGCTGCTAAMTTGGATTGGTGTGATCTTTTTGGTAGTTGTMTTT
- Wl-7543b 1 62 CTCTGCAGCCCTCAGATFATTTTTCCTCTGGCTCCTTGGATGTAGTCAGTTA
- Wl-7577g 1 57 ATTGTATMTGTGGCCTGTTATACATGACACTCTTCTGMTTGACTGTATTTC
- WI-7743C 1 06 GAGGGGCAGMCAGCCGCTCCTGTCTGCCAGCCAGCAGCCAGCTCTCAGCC
- Wl-7743 1 06 GAGGGGCAGMCAGCCGCTCCTGTCTGCCAGCCAGCAGCCAGCTCTCAGCC
- Wl-7765b 1 26 ACTCAMCCAMTCACTGMCTTTGCTGAGCCTGTAMATAAMGGTCGGA
- Wl-7774b 1 70 ATGATTGAAMTMTGCTGTCCTTTAGTAGCMGTAAMTGTGTCTTGCT
- Wl-7785b 1 65 TAATTIATTTTGTCCATTGATGTATTTATTTTGTAMTGTATCTTGGTGCTGC
- WI-7789C 84 GCCCTCCTGGTGACTCGGGGGCTGTCTCAGACGACTAGCCCAGGACCCATCT _
- Wl-7830d 1 50 T AGGTTGATCGTTGTGTTGTTRTGCTGCACTTTTTACI I I I I IGCGTGTGGA
- WI-7830C 54 AGGTTGATCGTTGTGTTGTTTFGCTGCACTTTTTAC I I I I I GCGTGTGGA
- Wl-7830b 1 34 AGGTTGATCGTTGTGTTGTTFTGCTGCACTTTTTAC I I I I I GCGTGTGGA
- Wl-7900d 1 28 TATGATGTATTTCTGAGCTAAMCTCMCTATAGMGACATTAAAAGAAATC
- WI-7900C 84 TATGATGTATTTCTGAGCTAAMCTCMCTATAGMGACATTAMAGAAATC
- WI-7900 84 TATGATGTATTTCTGAGCTAAAACTCAACTATAGAAGACATTAAAAGAAATC
- WI-8024C 206 TTCCC[A/G]CTCTAGMCAGCTGGCCCTGGTCGTCAGTACACMGGAMGAGC
- Wl-8024b 206 TTCCC[A/G]CTCTAGMCAGCTGGCCCTGGTCGTCAGTACACMGGMAGAGC
- WI-8321 1 78 TTTTGCTATGGTTCTAGTTFATCMCCTACTTTATTAGCTGMCTGTTGGC
- WI-8321 1 78 TTTFGCTATGGTTCTAGTTTATCMCCTACTTTATTAGCTGMCTGTTGGC
- Wl-8332b 123 AGGTGGAGGGTNTCCGGGGMGCAGTTAGATGAGTTMGTGTGATGCACA
- Wl-8378b 31 1 MCTGCCCCCATGATCCMTCACCTNTCACCAGGCCCCTCCTCCMCACGTGGGG
- WI-8378 308 MCTGCCCCCATGATCCMTCACCTNTCACCAGGCCCCTCCTCCMCACGTGGGG
- WI-8426 1 84 G AGGCTGGGAGTATGGANGGNCCCGGGGCCCTTGGCNATNGNATFCAGTGAG
- Wl-9676h 1 34 AGGCCAGGGTCTCAGCTTTAMGCCTTGGMTCCTATGCATTGTTTGTTT
- Wl-9676d 1 34 AGGCCAGGGTCTCAGCTTTAMGCCTTGGMTCCTATGCATTGTTTGTTT
- WI-9832 1 1 6 A TTTGTMGTGGACTAMGTTTGAGGACCAGACATGGMGGTTGGCTTTGGC
- AAAGCATGAC CGCTTATGTTA AATAAAATGA ATAGTMTTCC CMGTGAATATTGATACATGGCTGACMAGCATGACMTMMTGMCAC[A/G]TACGGGMTTAC
Abstract
Description
















































































































































































































































Claims
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP97946582A EP0941366A2 (en) | 1996-11-06 | 1997-11-05 | Biallelic markers |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US3045596P | 1996-11-06 | 1996-11-06 | |
| US60/030,455 | 1996-11-06 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO1998020165A2 true WO1998020165A2 (en) | 1998-05-14 |
| WO1998020165A3 WO1998020165A3 (en) | 1998-11-12 |
Family
ID=21854280
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/US1997/020313 WO1998020165A2 (en) | 1996-11-06 | 1997-11-05 | Biallelic markers |
Country Status (2)
| Country | Link |
|---|---|
| EP (1) | EP0941366A2 (en) |
| WO (1) | WO1998020165A2 (en) |
Cited By (73)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP0887407A2 (en) * | 1997-06-11 | 1998-12-30 | Smithkline Beecham Corporation | cDNA clone HAPO167 that encodes a human 7-transmembrane receptor |
| WO1999050454A2 (en) * | 1998-04-01 | 1999-10-07 | Whitehead Institute For Biomedical Research | Coding sequence polymorphisms in vascular pathology genes |
| WO1999053095A2 (en) * | 1998-04-09 | 1999-10-21 | Whitehead Institute For Biomedical Research | Biallelic markers |
| WO1999054500A2 (en) * | 1998-04-21 | 1999-10-28 | Genset | Biallelic markers for use in constructing a high density disequilibrium map of the human genome |
| WO1999061659A1 (en) * | 1998-05-26 | 1999-12-02 | Procrea Biosciences Inc. | A novel str marker system for dna fingerprinting |
| WO1999064590A1 (en) * | 1998-06-05 | 1999-12-16 | Genset | Polymorphic markers of prostate carcinoma tumor antigen-1 (pcta-1) |
| WO2000008209A2 (en) * | 1998-08-07 | 2000-02-17 | Genset | Nucleic acids encoding human tbc-1 protein and polymorphic markers thereof |
| WO2000018960A2 (en) * | 1998-09-25 | 2000-04-06 | Massachusetts Institute Of Technology | Methods and products related to genotyping and dna analysis |
| WO2000028080A2 (en) * | 1998-11-10 | 2000-05-18 | Genset | Methods, software and apparati for identifying genomic regions harboring a gene associated with a detectable trait |
| WO2000029623A2 (en) * | 1998-11-17 | 2000-05-25 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2000042165A2 (en) * | 1999-01-15 | 2000-07-20 | Human Genome Sciences, Inc. | Bone marrow-specific protein |
| WO2000055375A1 (en) * | 1999-03-17 | 2000-09-21 | Alphagene, Inc. | Secreted proteins and polynucleotides encoding them |
| WO2000056924A2 (en) * | 1999-03-24 | 2000-09-28 | Genset | Genomic sequence of the purh gene and purh-related biallelic markers |
| WO2000058519A2 (en) * | 1999-03-31 | 2000-10-05 | Whitehead Institute For Biomedical Research | Charaterization of single nucleotide polymorphisms in coding regions of human genes |
| WO2000058510A2 (en) * | 1999-03-30 | 2000-10-05 | Genset | Schizophrenia associated genes, proteins and biallelic markers |
| WO2000066728A1 (en) * | 1999-05-03 | 2000-11-09 | Compugen Ltd. | StAR HOMOLOGUES |
| WO2000071710A2 (en) * | 1999-05-25 | 2000-11-30 | Aventis Pharma S.A. | Expression products of genes involved in diseases related to cholesterol metabolism |
| FR2794131A1 (en) * | 1999-05-25 | 2000-12-01 | Aventis Pharma Sa | New nucleic acid derived from human chromosome 9, used e.g. for diagnosis and drug screening, derived from genes implicated in disorders of lipoprotein metabolism |
| WO2001000669A2 (en) * | 1999-06-25 | 2001-01-04 | Genset | A bap28 gene and protein |
| EP1088900A1 (en) * | 1999-09-10 | 2001-04-04 | Epidauros Biotechnologie AG | Polymorphisms in the human CYP3A4, CYP3A7 and hPXR genes and their use in diagnostic and therapeutic applications |
| WO2001038586A2 (en) * | 1999-11-24 | 2001-05-31 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001042511A2 (en) * | 1999-12-10 | 2001-06-14 | Whitehead Institute For Biomedical Research | Ibd-related polymorphisms |
| WO2001048245A2 (en) * | 1999-12-27 | 2001-07-05 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001047942A2 (en) * | 1999-12-27 | 2001-07-05 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001047944A2 (en) * | 1999-12-28 | 2001-07-05 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001051670A2 (en) * | 2000-01-07 | 2001-07-19 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001066800A2 (en) * | 2000-03-07 | 2001-09-13 | Whitehead Institute For Biomedical Research | Human single nucleotide polymorphisms |
| WO2001079504A1 (en) * | 2000-04-13 | 2001-10-25 | Millennium Pharmaceuticals, Inc. | 23155 NOVEL PROTEIN HUMAN 5-α REDUCTASES AND USES THEREFOR |
| WO2002002812A2 (en) * | 2000-06-30 | 2002-01-10 | University College London | Method for determining the susceptibility to stoke by analysing the ins gene |
| US6344441B1 (en) | 1997-08-06 | 2002-02-05 | Genset | Lipoprotein-regulating medicaments |
| WO2002066641A1 (en) * | 2001-02-20 | 2002-08-29 | Genset S.A. | Pg-3 and biallelic markers thereof |
| US6476208B1 (en) | 1998-10-13 | 2002-11-05 | Genset | Schizophrenia associated genes, proteins and biallelic markers |
| US6479238B1 (en) | 1999-02-10 | 2002-11-12 | Marta Blumenfeld | Polymorphic markers of the LSR gene |
| US6482923B1 (en) | 1997-09-17 | 2002-11-19 | Human Genome Sciences, Inc. | Interleukin 17-like receptor protein |
| WO2002092612A2 (en) * | 2001-05-11 | 2002-11-21 | Noxxon Pharma Ag | Nucleic acids that bind to enterotoxin b |
| WO2003000896A2 (en) * | 2001-05-03 | 2003-01-03 | Genodyssee | POLYNUCLEOTIDES AND POLYPEPTIDES OF THE IFNα-5 GENE |
| US6534293B1 (en) | 1999-01-06 | 2003-03-18 | Cornell Research Foundation, Inc. | Accelerating identification of single nucleotide polymorphisms and alignment of clones in genomic sequencing |
| US6537751B1 (en) | 1998-04-21 | 2003-03-25 | Genset S.A. | Biallelic markers for use in constructing a high density disequilibrium map of the human genome |
| US6555316B1 (en) | 1999-10-12 | 2003-04-29 | Genset S.A. | Schizophrenia associated gene, proteins and biallelic markers |
| US6566498B1 (en) | 1998-02-06 | 2003-05-20 | Human Genome Sciences, Inc. | Human serine protease and serpin polypeptides |
| US6566332B2 (en) | 2000-01-14 | 2003-05-20 | Genset S.A. | OBG3 globular head and uses thereof for decreasing body mass |
| US6582909B1 (en) | 1998-11-04 | 2003-06-24 | Genset, S.A. | APM1 biallelic markers and uses thereof |
| US6635443B1 (en) | 1997-09-17 | 2003-10-21 | Human Genome Sciences, Inc. | Polynucleotides encoding a novel interleukin receptor termed interleukin-17 receptor-like protein |
| US6703228B1 (en) | 1998-09-25 | 2004-03-09 | Massachusetts Institute Of Technology | Methods and products related to genotyping and DNA analysis |
| US6759192B1 (en) | 1998-06-05 | 2004-07-06 | Genset S.A. | Polymorphic markers of prostate carcinoma tumor antigen-1(PCTA-1) |
| US6759515B1 (en) | 1997-02-25 | 2004-07-06 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of prostate cancer |
| US6825004B1 (en) | 1998-08-07 | 2004-11-30 | Genset S.A. | Nucleic acids encoding human TBC-1 protein and polymorphic markers thereof |
| US6849719B2 (en) | 1997-09-17 | 2005-02-01 | Human Genome Sciences, Inc. | Antibody to an IL-17 receptor like protein |
| US6869762B1 (en) | 1999-12-10 | 2005-03-22 | Whitehead Institute For Biomedical Research | Crohn's disease-related polymorphisms |
| US6902892B1 (en) | 1998-10-19 | 2005-06-07 | Diadexus, Inc. | Method of diagnosing, monitoring, staging, imaging and treating prostate cancer |
| US6902890B1 (en) | 1999-11-04 | 2005-06-07 | Diadexus, Inc. | Method of diagnosing monitoring, staging, imaging and treating cancer |
| US6967091B2 (en) | 2000-01-14 | 2005-11-22 | Genset, S.A. | OBG3 globular head and uses thereof for decreasing body mass |
| US6989367B2 (en) | 2000-01-14 | 2006-01-24 | Genset S.A. | OBG3 globular head and uses thereof |
| US7067627B2 (en) | 1999-03-30 | 2006-06-27 | Serono Genetics Institute S.A. | Schizophrenia associated genes, proteins and biallelic markers |
| US7105353B2 (en) | 1997-07-18 | 2006-09-12 | Serono Genetics Institute S.A. | Methods of identifying individuals for inclusion in drug studies |
| WO2006136033A1 (en) * | 2005-06-23 | 2006-12-28 | The University Of British Columbia | Coagulation factor iii polymorphisms associated with prediction of subject outcome and response to therapy |
| US7193045B2 (en) | 1998-05-15 | 2007-03-20 | Genetech, Inc. | Polypeptides that induce cell proliferation |
| US7267966B2 (en) | 1998-10-27 | 2007-09-11 | Affymetrix, Inc. | Complexity management and analysis of genomic DNA |
| US7323307B2 (en) | 1996-09-19 | 2008-01-29 | Affymetrix, Inc. | Identification of molecular sequence signatures and methods involving the same |
| US7338787B2 (en) | 2000-01-14 | 2008-03-04 | Serono Genetics Institute S.A. | Nucleic acids encoding OBG3 globular head and uses thereof |
| US7501239B2 (en) * | 2003-04-18 | 2009-03-10 | Arkray, Inc. | Method of detecting β3 adrenaline receptor mutant gene and nucleic acid probe and kit therefor |
| WO2009143576A1 (en) * | 2008-05-27 | 2009-12-03 | Adelaide Research & Innovation Pty Ltd | Polymorphisms associated with pregnancy complications |
| US8044183B2 (en) | 1998-02-05 | 2011-10-25 | Glaxosmithkline Biologicals S.A. | Process for the production of immunogenic compositions |
| US8063191B2 (en) * | 2005-09-16 | 2011-11-22 | Mayo Foundation For Medical Education And Research | Polynucleotides encoding for fusion proteins with natriuresis activity |
| WO2011151405A1 (en) | 2010-06-04 | 2011-12-08 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Constitutively active prolactin receptor variants as prognostic markers and therapeutic targets to prevent progression of hormone-dependent cancers towards hormone-independence |
| US8133734B2 (en) | 1999-03-16 | 2012-03-13 | Human Genome Sciences, Inc. | Kit comprising an antibody to interleukin 17 receptor-like protein |
| US8367322B2 (en) | 1999-01-06 | 2013-02-05 | Cornell Research Foundation, Inc. | Accelerating identification of single nucleotide polymorphisms and alignment of clones in genomic sequencing |
| US9074244B2 (en) | 2008-03-11 | 2015-07-07 | Affymetrix, Inc. | Array-based translocation and rearrangement assays |
| US9193777B2 (en) | 2009-07-09 | 2015-11-24 | Mayo Foundation For Medical Education And Research | Method of treating cardiac arrhythmia with long acting atrial natriuretic peptide(LA-ANP) |
| US9388457B2 (en) | 2007-09-14 | 2016-07-12 | Affymetrix, Inc. | Locus specific amplification using array probes |
| US9611305B2 (en) | 2012-01-06 | 2017-04-04 | Mayo Foundation For Medical Education And Research | Treating cardiovascular or renal diseases |
| US10344068B2 (en) | 2011-08-30 | 2019-07-09 | Mayo Foundation For Medical Education And Research | Natriuretic polypeptides |
| CN111139301A (en) * | 2020-03-10 | 2020-05-12 | 无锡市第五人民医院 | Breast cancer related gene ERBB2 site g.39397319C > A mutant and application thereof |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1995012607A1 (en) * | 1993-11-03 | 1995-05-11 | Molecular Tool, Inc. | Single nucleotide polymorphisms and their use in genetic analysis |
| FR2722295A1 (en) * | 1994-07-07 | 1996-01-12 | Roussy Inst Gustave | Single strand conformation polymorphism analysis of DNA |
-
1997
- 1997-11-05 WO PCT/US1997/020313 patent/WO1998020165A2/en not_active Application Discontinuation
- 1997-11-05 EP EP97946582A patent/EP0941366A2/en not_active Withdrawn
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1995012607A1 (en) * | 1993-11-03 | 1995-05-11 | Molecular Tool, Inc. | Single nucleotide polymorphisms and their use in genetic analysis |
| FR2722295A1 (en) * | 1994-07-07 | 1996-01-12 | Roussy Inst Gustave | Single strand conformation polymorphism analysis of DNA |
Non-Patent Citations (6)
| Title |
|---|
| DATABASE EMEST10 embl Accession number: hst27766, 12 January 1995 ADAMS M D ET AL.: "Initial assessment of human gene diversity and expression patterns based upon 52 million basepairs of cDNA sequence" XP002067789 * |
| GROMPE M: "THE RAPID DETECTION OF UNKNOWN MUTATIONS IN NUCLEIC ACIDS" NATURE GENETICS, vol. 5, no. 2, October 1993, pages 111-117, XP000615290 * |
| HRUBAN R H ET AL: "K-RAS ONCOGENE ACTIVATION IN ADENOCARCINOMA OF THE HUMAN PANCREAS A STUDY OF 82 CARCINOMAS USING A COMBINATION OF MUTANT-ENRICHED POLYMERASE CHAIN RACTION ANALYSIS AND ALLELE-SPECIFIC OLIGONUCLEOTIDE HYBRIDIZATION" AMERICAN JOURNAL OF PATHOLOGY, vol. 143, no. 2, 1 August 1993, pages 545-554, XP000572114 * |
| NIKIFOROV T T ET AL: "GENETIC BIT ANALYSIS: A SOLID PHASE METHOD FOR TYPING SINGLE NUCLEOTIDE POLYMORPHISMS" NUCLEIC ACIDS RESEARCH, vol. 22, no. 20, October 1994, pages 4167-4175, XP002015765 * |
| SYVANEN A -CH ET AL: "IDENTIFICATION OF INDIVIDUALS BY ANALYSIS OF BIALLELIC DNA MARKERS,USING PCR AND SOLID-PHASE MINISEQUENCING" AMERICAN JOURNAL OF HUMAN GENETICS, vol. 52, no. 1, January 1993, pages 46-59, XP002050638 * |
| WANG D ET AL: "TOWARD A THIRD GENERATION GENETIC MAP OF THE HUMAN GENOME BASED ON BI-ALLELIC POLYMORPHISMS" AMERICAN JOURNAL OF HUMAN GENETICS, vol. 59, no. 4, October 1996, page A03 XP002050641 * |
Cited By (126)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7323307B2 (en) | 1996-09-19 | 2008-01-29 | Affymetrix, Inc. | Identification of molecular sequence signatures and methods involving the same |
| US6759515B1 (en) | 1997-02-25 | 2004-07-06 | Corixa Corporation | Compositions and methods for the therapy and diagnosis of prostate cancer |
| EP0887407A3 (en) * | 1997-06-11 | 2000-07-12 | Smithkline Beecham Corporation | cDNA clone HAPO167 that encodes a human 7-transmembrane receptor |
| EP0887407A2 (en) * | 1997-06-11 | 1998-12-30 | Smithkline Beecham Corporation | cDNA clone HAPO167 that encodes a human 7-transmembrane receptor |
| US7105353B2 (en) | 1997-07-18 | 2006-09-12 | Serono Genetics Institute S.A. | Methods of identifying individuals for inclusion in drug studies |
| US7919091B2 (en) | 1997-08-06 | 2011-04-05 | Serono Genetics Institute S.A. | Lipolysis stimulated receptor (LSR) specific antibodies |
| US7220722B2 (en) | 1997-08-06 | 2007-05-22 | Serono Genetics Institute S.A. | Lipoprotein-regulating medicants |
| US7291709B2 (en) | 1997-08-06 | 2007-11-06 | Serono Genetics Institute S.A. | LSR receptor, its activity, its cloning, and its applications to the diagnosis, prevention and/or treatment of obesity and related risks or complications |
| US6946444B2 (en) | 1997-08-06 | 2005-09-20 | Genset | Lipoprotein-regulating medicaments |
| US6344441B1 (en) | 1997-08-06 | 2002-02-05 | Genset | Lipoprotein-regulating medicaments |
| US6635431B1 (en) | 1997-08-06 | 2003-10-21 | Genset, S.A. | LSR receptor, activity, cloning, and uses for diagnosing, preventing and/or treating obesity and related risks or complications |
| US6849719B2 (en) | 1997-09-17 | 2005-02-01 | Human Genome Sciences, Inc. | Antibody to an IL-17 receptor like protein |
| US6635443B1 (en) | 1997-09-17 | 2003-10-21 | Human Genome Sciences, Inc. | Polynucleotides encoding a novel interleukin receptor termed interleukin-17 receptor-like protein |
| US7638603B2 (en) | 1997-09-17 | 2009-12-29 | Human Genome Sciences, Inc. | Antibodies against interleukin 17 receptor-like protein |
| US6482923B1 (en) | 1997-09-17 | 2002-11-19 | Human Genome Sciences, Inc. | Interleukin 17-like receptor protein |
| US8097257B2 (en) | 1998-02-05 | 2012-01-17 | Glaxosmithkline Biologicals S.A. | MAGE3 polypeptides |
| US8044183B2 (en) | 1998-02-05 | 2011-10-25 | Glaxosmithkline Biologicals S.A. | Process for the production of immunogenic compositions |
| US8597656B2 (en) | 1998-02-05 | 2013-12-03 | Glaxosmithkline Biologicals S.A. | Process for the production of immunogenic compositions |
| US6566498B1 (en) | 1998-02-06 | 2003-05-20 | Human Genome Sciences, Inc. | Human serine protease and serpin polypeptides |
| WO1999050454A2 (en) * | 1998-04-01 | 1999-10-07 | Whitehead Institute For Biomedical Research | Coding sequence polymorphisms in vascular pathology genes |
| US6692909B1 (en) | 1998-04-01 | 2004-02-17 | Whitehead Institute For Biomedical Research | Coding sequence polymorphisms in vascular pathology genes |
| WO1999050454A3 (en) * | 1998-04-01 | 2000-04-13 | Whitehead Biomedical Inst | Coding sequence polymorphisms in vascular pathology genes |
| WO1999053095A3 (en) * | 1998-04-09 | 2000-03-16 | Whitehead Biomedical Inst | Biallelic markers |
| WO1999053095A2 (en) * | 1998-04-09 | 1999-10-21 | Whitehead Institute For Biomedical Research | Biallelic markers |
| US6537751B1 (en) | 1998-04-21 | 2003-03-25 | Genset S.A. | Biallelic markers for use in constructing a high density disequilibrium map of the human genome |
| WO1999054500A3 (en) * | 1998-04-21 | 2000-03-16 | Genset Sa | Biallelic markers for use in constructing a high density disequilibrium map of the human genome |
| WO1999054500A2 (en) * | 1998-04-21 | 1999-10-28 | Genset | Biallelic markers for use in constructing a high density disequilibrium map of the human genome |
| US7193045B2 (en) | 1998-05-15 | 2007-03-20 | Genetech, Inc. | Polypeptides that induce cell proliferation |
| WO1999061659A1 (en) * | 1998-05-26 | 1999-12-02 | Procrea Biosciences Inc. | A novel str marker system for dna fingerprinting |
| WO1999064590A1 (en) * | 1998-06-05 | 1999-12-16 | Genset | Polymorphic markers of prostate carcinoma tumor antigen-1 (pcta-1) |
| US6759192B1 (en) | 1998-06-05 | 2004-07-06 | Genset S.A. | Polymorphic markers of prostate carcinoma tumor antigen-1(PCTA-1) |
| US7547771B2 (en) | 1998-06-05 | 2009-06-16 | Serono Genetics Institute S.A. | Polymorphic markers of prostate carcinoma tumor antigen -1(PCTA-1) |
| US6825004B1 (en) | 1998-08-07 | 2004-11-30 | Genset S.A. | Nucleic acids encoding human TBC-1 protein and polymorphic markers thereof |
| WO2000008209A3 (en) * | 1998-08-07 | 2000-11-09 | Genset Sa | Nucleic acids encoding human tbc-1 protein and polymorphic markers thereof |
| WO2000008209A2 (en) * | 1998-08-07 | 2000-02-17 | Genset | Nucleic acids encoding human tbc-1 protein and polymorphic markers thereof |
| WO2000018960A2 (en) * | 1998-09-25 | 2000-04-06 | Massachusetts Institute Of Technology | Methods and products related to genotyping and dna analysis |
| JP2002525127A (en) * | 1998-09-25 | 2002-08-13 | マサチューセッツ インスティテュート オブ テクノロジー | Methods and products for genotyping and DNA analysis |
| US6703228B1 (en) | 1998-09-25 | 2004-03-09 | Massachusetts Institute Of Technology | Methods and products related to genotyping and DNA analysis |
| WO2000018960A3 (en) * | 1998-09-25 | 2000-09-08 | Massachusetts Inst Technology | Methods and products related to genotyping and dna analysis |
| US7371811B2 (en) | 1998-10-13 | 2008-05-13 | Serono Genetics Institute S.A. | Schizophrenia associated genes, proteins and biallelic markers |
| US6476208B1 (en) | 1998-10-13 | 2002-11-05 | Genset | Schizophrenia associated genes, proteins and biallelic markers |
| US7432064B2 (en) | 1998-10-19 | 2008-10-07 | Diadexus, Inc. | Method of diagnosing, monitoring, staging, imaging and treating prostate cancer |
| US6902892B1 (en) | 1998-10-19 | 2005-06-07 | Diadexus, Inc. | Method of diagnosing, monitoring, staging, imaging and treating prostate cancer |
| US7267966B2 (en) | 1998-10-27 | 2007-09-11 | Affymetrix, Inc. | Complexity management and analysis of genomic DNA |
| US6582909B1 (en) | 1998-11-04 | 2003-06-24 | Genset, S.A. | APM1 biallelic markers and uses thereof |
| WO2000028080A3 (en) * | 1998-11-10 | 2000-08-17 | Genset Sa | Methods, software and apparati for identifying genomic regions harboring a gene associated with a detectable trait |
| AU771187B2 (en) * | 1998-11-10 | 2004-03-18 | Genset | Methods, software and apparati for identifying genomic regions harboring a gene associated with a detectable trait |
| WO2000028080A2 (en) * | 1998-11-10 | 2000-05-18 | Genset | Methods, software and apparati for identifying genomic regions harboring a gene associated with a detectable trait |
| US6291182B1 (en) | 1998-11-10 | 2001-09-18 | Genset | Methods, software and apparati for identifying genomic regions harboring a gene associated with a detectable trait |
| WO2000029623A3 (en) * | 1998-11-17 | 2001-04-19 | Curagen Corp | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2000029623A2 (en) * | 1998-11-17 | 2000-05-25 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| US6670464B1 (en) | 1998-11-17 | 2003-12-30 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| US6534293B1 (en) | 1999-01-06 | 2003-03-18 | Cornell Research Foundation, Inc. | Accelerating identification of single nucleotide polymorphisms and alignment of clones in genomic sequencing |
| US8367322B2 (en) | 1999-01-06 | 2013-02-05 | Cornell Research Foundation, Inc. | Accelerating identification of single nucleotide polymorphisms and alignment of clones in genomic sequencing |
| WO2000042165A2 (en) * | 1999-01-15 | 2000-07-20 | Human Genome Sciences, Inc. | Bone marrow-specific protein |
| WO2000042165A3 (en) * | 1999-01-15 | 2001-05-31 | Human Genome Sciences Inc | Bone marrow-specific protein |
| US6534485B1 (en) | 1999-01-15 | 2003-03-18 | Human Genome Sciences, Inc. | Bone marrow-specific protein |
| US6479238B1 (en) | 1999-02-10 | 2002-11-12 | Marta Blumenfeld | Polymorphic markers of the LSR gene |
| US7125667B2 (en) | 1999-02-10 | 2006-10-24 | Serono Genetics Institute S.A. | Polymorphic markers of the LSR gene |
| US8133734B2 (en) | 1999-03-16 | 2012-03-13 | Human Genome Sciences, Inc. | Kit comprising an antibody to interleukin 17 receptor-like protein |
| WO2000055375A1 (en) * | 1999-03-17 | 2000-09-21 | Alphagene, Inc. | Secreted proteins and polynucleotides encoding them |
| US6544737B1 (en) | 1999-03-24 | 2003-04-08 | Genset S.A. | Genomic sequence of the purH gene and purH-related biallelic markers |
| WO2000056924A2 (en) * | 1999-03-24 | 2000-09-28 | Genset | Genomic sequence of the purh gene and purh-related biallelic markers |
| WO2000056924A3 (en) * | 1999-03-24 | 2001-08-09 | Genset Sa | Genomic sequence of the purh gene and purh-related biallelic markers |
| US7427482B2 (en) | 1999-03-24 | 2008-09-23 | Serono Genetics Institute S.A. | Methods of assessing the risk for the development of sporadic prostate cancer |
| US7041454B2 (en) | 1999-03-24 | 2006-05-09 | Serono Genetics Institute, S.A. | Genomic sequence of the purH gene and purH-related biallelic markers |
| WO2000058510A2 (en) * | 1999-03-30 | 2000-10-05 | Genset | Schizophrenia associated genes, proteins and biallelic markers |
| US7067627B2 (en) | 1999-03-30 | 2006-06-27 | Serono Genetics Institute S.A. | Schizophrenia associated genes, proteins and biallelic markers |
| WO2000058510A3 (en) * | 1999-03-30 | 2001-08-09 | Genset Sa | Schizophrenia associated genes, proteins and biallelic markers |
| WO2000058519A2 (en) * | 1999-03-31 | 2000-10-05 | Whitehead Institute For Biomedical Research | Charaterization of single nucleotide polymorphisms in coding regions of human genes |
| WO2000058519A3 (en) * | 1999-03-31 | 2001-08-23 | Whitehead Biomedical Inst | Charaterization of single nucleotide polymorphisms in coding regions of human genes |
| WO2000066728A1 (en) * | 1999-05-03 | 2000-11-09 | Compugen Ltd. | StAR HOMOLOGUES |
| WO2000071710A3 (en) * | 1999-05-25 | 2001-05-17 | Aventis Pharma Sa | Expression products of genes involved in diseases related to cholesterol metabolism |
| WO2000071710A2 (en) * | 1999-05-25 | 2000-11-30 | Aventis Pharma S.A. | Expression products of genes involved in diseases related to cholesterol metabolism |
| FR2794131A1 (en) * | 1999-05-25 | 2000-12-01 | Aventis Pharma Sa | New nucleic acid derived from human chromosome 9, used e.g. for diagnosis and drug screening, derived from genes implicated in disorders of lipoprotein metabolism |
| WO2001000669A3 (en) * | 1999-06-25 | 2002-01-17 | Genset Sa | A bap28 gene and protein |
| WO2001000669A2 (en) * | 1999-06-25 | 2001-01-04 | Genset | A bap28 gene and protein |
| EP1088900A1 (en) * | 1999-09-10 | 2001-04-04 | Epidauros Biotechnologie AG | Polymorphisms in the human CYP3A4, CYP3A7 and hPXR genes and their use in diagnostic and therapeutic applications |
| US6555316B1 (en) | 1999-10-12 | 2003-04-29 | Genset S.A. | Schizophrenia associated gene, proteins and biallelic markers |
| US7326402B2 (en) | 1999-11-04 | 2008-02-05 | Diadexus, Inc. | Method of diagnosing, monitoring, staging, imaging and treating cancer |
| US6902890B1 (en) | 1999-11-04 | 2005-06-07 | Diadexus, Inc. | Method of diagnosing monitoring, staging, imaging and treating cancer |
| WO2001038586A3 (en) * | 1999-11-24 | 2002-04-25 | Richard A Shimkets | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001038586A2 (en) * | 1999-11-24 | 2001-05-31 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001042511A3 (en) * | 1999-12-10 | 2002-11-14 | Whitehead Biomedical Inst | Ibd-related polymorphisms |
| WO2001042511A2 (en) * | 1999-12-10 | 2001-06-14 | Whitehead Institute For Biomedical Research | Ibd-related polymorphisms |
| US6869762B1 (en) | 1999-12-10 | 2005-03-22 | Whitehead Institute For Biomedical Research | Crohn's disease-related polymorphisms |
| WO2001048245A3 (en) * | 1999-12-27 | 2002-11-28 | Curagen Corp | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001047942A3 (en) * | 1999-12-27 | 2002-12-12 | Curagen Corp | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001048245A2 (en) * | 1999-12-27 | 2001-07-05 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001047942A2 (en) * | 1999-12-27 | 2001-07-05 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001047944A2 (en) * | 1999-12-28 | 2001-07-05 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001047944A3 (en) * | 1999-12-28 | 2003-02-20 | Curagen Corp | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001051670A2 (en) * | 2000-01-07 | 2001-07-19 | Curagen Corporation | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| WO2001051670A3 (en) * | 2000-01-07 | 2002-02-28 | Curagen Corp | Nucleic acids containing single nucleotide polymorphisms and methods of use thereof |
| US6967091B2 (en) | 2000-01-14 | 2005-11-22 | Genset, S.A. | OBG3 globular head and uses thereof for decreasing body mass |
| US7671024B2 (en) | 2000-01-14 | 2010-03-02 | Serono Genetics Institute S.A. | OBG3 globular head and uses thereof |
| US6989367B2 (en) | 2000-01-14 | 2006-01-24 | Genset S.A. | OBG3 globular head and uses thereof |
| US7338787B2 (en) | 2000-01-14 | 2008-03-04 | Serono Genetics Institute S.A. | Nucleic acids encoding OBG3 globular head and uses thereof |
| US7393661B2 (en) | 2000-01-14 | 2008-07-01 | Serono Genetics Institute S.A. | Nucleic acids encoding OBG3 polypeptides |
| US6566332B2 (en) | 2000-01-14 | 2003-05-20 | Genset S.A. | OBG3 globular head and uses thereof for decreasing body mass |
| WO2001066800A2 (en) * | 2000-03-07 | 2001-09-13 | Whitehead Institute For Biomedical Research | Human single nucleotide polymorphisms |
| WO2001066800A3 (en) * | 2000-03-07 | 2003-06-05 | Whitehead Biomedical Inst | Human single nucleotide polymorphisms |
| WO2001079504A1 (en) * | 2000-04-13 | 2001-10-25 | Millennium Pharmaceuticals, Inc. | 23155 NOVEL PROTEIN HUMAN 5-α REDUCTASES AND USES THEREFOR |
| WO2002002812A3 (en) * | 2000-06-30 | 2004-02-26 | Univ London | Method for determining the susceptibility to stoke by analysing the ins gene |
| WO2002002812A2 (en) * | 2000-06-30 | 2002-01-10 | University College London | Method for determining the susceptibility to stoke by analysing the ins gene |
| WO2002066641A1 (en) * | 2001-02-20 | 2002-08-29 | Genset S.A. | Pg-3 and biallelic markers thereof |
| WO2003000896A2 (en) * | 2001-05-03 | 2003-01-03 | Genodyssee | POLYNUCLEOTIDES AND POLYPEPTIDES OF THE IFNα-5 GENE |
| WO2003000896A3 (en) * | 2001-05-03 | 2003-07-17 | Genodyssee | POLYNUCLEOTIDES AND POLYPEPTIDES OF THE IFNα-5 GENE |
| WO2002092612A3 (en) * | 2001-05-11 | 2003-07-10 | Noxxon Pharma Ag | Nucleic acids that bind to enterotoxin b |
| WO2002092612A2 (en) * | 2001-05-11 | 2002-11-21 | Noxxon Pharma Ag | Nucleic acids that bind to enterotoxin b |
| US7501239B2 (en) * | 2003-04-18 | 2009-03-10 | Arkray, Inc. | Method of detecting β3 adrenaline receptor mutant gene and nucleic acid probe and kit therefor |
| WO2006136033A1 (en) * | 2005-06-23 | 2006-12-28 | The University Of British Columbia | Coagulation factor iii polymorphisms associated with prediction of subject outcome and response to therapy |
| US8063191B2 (en) * | 2005-09-16 | 2011-11-22 | Mayo Foundation For Medical Education And Research | Polynucleotides encoding for fusion proteins with natriuresis activity |
| US9388457B2 (en) | 2007-09-14 | 2016-07-12 | Affymetrix, Inc. | Locus specific amplification using array probes |
| US10329600B2 (en) | 2007-09-14 | 2019-06-25 | Affymetrix, Inc. | Locus specific amplification using array probes |
| US11408094B2 (en) | 2007-09-14 | 2022-08-09 | Affymetrix, Inc. | Locus specific amplification using array probes |
| US9074244B2 (en) | 2008-03-11 | 2015-07-07 | Affymetrix, Inc. | Array-based translocation and rearrangement assays |
| US9932636B2 (en) | 2008-03-11 | 2018-04-03 | Affymetrix, Inc. | Array-based translocation and rearrangement assays |
| WO2009143576A1 (en) * | 2008-05-27 | 2009-12-03 | Adelaide Research & Innovation Pty Ltd | Polymorphisms associated with pregnancy complications |
| US9193777B2 (en) | 2009-07-09 | 2015-11-24 | Mayo Foundation For Medical Education And Research | Method of treating cardiac arrhythmia with long acting atrial natriuretic peptide(LA-ANP) |
| WO2011151405A1 (en) | 2010-06-04 | 2011-12-08 | Institut National De La Sante Et De La Recherche Medicale (Inserm) | Constitutively active prolactin receptor variants as prognostic markers and therapeutic targets to prevent progression of hormone-dependent cancers towards hormone-independence |
| US10344068B2 (en) | 2011-08-30 | 2019-07-09 | Mayo Foundation For Medical Education And Research | Natriuretic polypeptides |
| US9611305B2 (en) | 2012-01-06 | 2017-04-04 | Mayo Foundation For Medical Education And Research | Treating cardiovascular or renal diseases |
| US9987331B2 (en) | 2012-01-06 | 2018-06-05 | Mayo Foundation For Medical Education And Research | Treating cardiovascular or renal diseases |
| US10092628B2 (en) | 2012-01-06 | 2018-10-09 | Mayo Foundation For Medical Education And Research | Treating cardiovascular or renal diseases |
| CN111139301A (en) * | 2020-03-10 | 2020-05-12 | 无锡市第五人民医院 | Breast cancer related gene ERBB2 site g.39397319C > A mutant and application thereof |
Also Published As
| Publication number | Publication date |
|---|---|
| EP0941366A2 (en) | 1999-09-15 |
| WO1998020165A3 (en) | 1998-11-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US5856104A (en) | Polymorphisms in the glucose-6 phosphate dehydrogenase locus | |
| EP0941366A2 (en) | Biallelic markers | |
| US6525185B1 (en) | Polymorphisms associated with hypertension | |
| US20060263807A1 (en) | Methods for polymorphism identification and profiling | |
| US6869762B1 (en) | Crohn's disease-related polymorphisms | |
| WO1998038846A2 (en) | Genetic compositions and methods | |
| US20020037508A1 (en) | Human single nucleotide polymorphisms | |
| US20060188875A1 (en) | Human genomic polymorphisms | |
| WO2001066800A2 (en) | Human single nucleotide polymorphisms | |
| EP0812922A2 (en) | Polymorphisms in human mitochondrial nucleic acid | |
| EP1068353A2 (en) | Coding sequence polymorphisms in vascular pathology genes | |
| EP1240354A2 (en) | Single nucleotide polymorphisms in genes | |
| EP1068354A2 (en) | Biallelic markers | |
| WO1998058529A2 (en) | Genetic compositions and methods | |
| US20030039973A1 (en) | Human single nucleotide polymorphisms | |
| US20030054381A1 (en) | Genetic polymorphisms in the human neurokinin 1 receptor gene and their uses in diagnosis and treatment of diseases | |
| EP1024200A2 (en) | Genetic compositions and methods | |
| WO2001038576A2 (en) | Human single nucleotide polymorphisms | |
| EP1276899A2 (en) | Ibd-related polymorphisms | |
| WO1999014228A1 (en) | Genetic compositions and methods | |
| WO2000058519A2 (en) | Charaterization of single nucleotide polymorphisms in coding regions of human genes | |
| WO2001034840A2 (en) | Genetic compositions and methods | |
| WO2005072150A2 (en) | Ldlr genetic markers associated with age of onset of alzheimer's disease | |
| US20020155446A1 (en) | Very low density lipoprotein receptor polymorphisms and uses therefor | |
| US20030008301A1 (en) | Association between schizophrenia and a two-marker haplotype near PILB gene |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| AK | Designated states |
Kind code of ref document: A2 Designated state(s): JP US |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A2 Designated state(s): AT BE CH DE DK ES FI FR GB GR IE IT LU MC NL PT SE |
|
| DFPE | Request for preliminary examination filed prior to expiration of 19th month from priority date (pct application filed before 20040101) | ||
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application | ||
| AK | Designated states |
Kind code of ref document: A3 Designated state(s): JP US |
|
| AL | Designated countries for regional patents |
Kind code of ref document: A3 Designated state(s): AT BE CH DE DK ES FI FR GB GR IE IT LU MC NL PT SE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 1997946582 Country of ref document: EP |
|
| WWP | Wipo information: published in national office |
Ref document number: 1997946582 Country of ref document: EP |
|
| WWW | Wipo information: withdrawn in national office |
Ref document number: 1997946582 Country of ref document: EP |