NUCLEIC ACID AND CORRESPONDING PROTEIN ENTITLED 24P4C12 USEFUL IN TREATMENT AND DETECTION OF CANCER
STATEMENT OF RIGHTS TO INVENTIONS MADE UNDER FEDERALLY SPONSORED RESEARCH
Not applicable.
FIELD OF THE INVENTION
The invention described herein relates to a gene and its encoded protein, termed 24P4C12, expressed in certain cancers, and to diagnostic and therapeutic methods and compositions useful in the management of cancers that express 24P4C12.
BACKGROUND OF THE INVENTION
Cancer is the second leading cause of human death next to coronary disease. Worldwide, millions of people die from cancer every year. In the United States alone, as reported by ttie American Cancer Society, cancer causes the death of well over a half-million people annually, with over 1.2 million new cases diagnosed per year. While deaths from heart disease have been declining significantly, those resulting from cancer generally are on the rise. In the early part of the next century, cancer is predicted to become the leading cause of death.
Worldwide, several cancers stand out as the leading killers, tn particular, carcinomas of the lung, prostate, breast, colon, pancreas, and ovary represent the primary cause&of cancer death. These and virtually all other ca. cinomas share a common lethal feature. With very few exceptions, metastatic disease from a carcinoma is fatal. Moreover, even for those cancer patients who initially survive their primary cancers, common experience has shown that their lives are dramatically altered. Many cancer patients experience strong anxieties driven by the awareness of the potential for recurrence or treatment failure. Many cancer patients experience physical debilitations following treatment. Furthermore, many cancer patients experience a recurrence.
Worldwide, prostate cancer is the fourth most prevalent cancer in men. In North America and Northern Europe, it is by far the most common cancer in males and is the second leading cause of cancer death in men. In the United States alone, well over 30,000 men die annually of this disease - second only to lung cancer. Despite the magnitude of these figures, there is still no effective treatment for metastatic prostate cancer. Surgical prostatectomy, radiation therapy, hormone ablation therapy, surgical castration and chemotherapy continue to be the main treatment modalities. Unfortunately, these treatments are ineffective for many and are often associated with undesirable consequences.
On the diagnostic front, the lack of a prostate tumor marker that can accurately detect early-stage, localized tumors remains a significant limitation in the diagnosis and management of this disease. Although the serum prostate specific antigen (PSA) assay has been a very useful tool, however its specificity and general utility is widely regarded as lacking in several important respects.
Progress in identifying additional specific markers for prostate cancer has been improved by the generation of prostate cancer xenografts that can recapitulate different stages of the disease in mice. The LAPC (Los Angeles Prostate Cancer) xenografts are prostate cancer xenografts that have survived passage in severe combined immune deficient (SCID) mice and have exhibited the capacity to mimic the transition from androgen dependence to androgen independence (Klein et al., 1997, Nat Med. 3;402). More recently identified prostate cancer markers include PCTA-1 (Su ef al., 1996, Proc. Natl. Acad. Sci. USA 93: 7252), prostate-specific membrane (PSM) antigen (Pinto et al., Clin Cancer Res 1996 Sep 2 (9): 1445- 51), STEAP (Hubert, ef al., Proc Natl Acad Sci U SA. 1999 Dec 7; 96(25): 14523-8) and prostate stem cell antigen (PSCA) (Reiteref at, 1998, Proc. Natl. Acad. Sci. USA 95: 1735).
While previously identified markers such as PSA, PSM, PCTA and PSCA have facilitated efforts to diagnose and treat prostate cancer, there is need for the identification of additional markers and therapeutic targets for prostate and related cancers in order to further improve diagnosis and therapy.
Renal cell carcinoma (RCC) accounts for approximately 3 percent of adult malignancies. Once adenomas reach a diameter of 2 to 3 cm, malignant potential exists. In the adult, the two principal malignant renal tumors are renal cell adenocarcinoma and transitional cell carcinoma of the renal pelvis or ureter. The incidence of renal cell adenocarcinoma is estimated at more than 29,000 cases in the United States, and more than 11,600 patients died of this disease in 1998. Transitional cell carcinoma is less frequent, with an incidence of approximately 500 cases per year in the United States.
Surgery has been the primary therapy for renal cell adenocarcinoma for many decades. Until recently, metastatic disease has been refractory to any systemic therapy. With recent developments in systemic therapies, particularly immunotherapies, metastatic renal cell carcinoma may be approached aggressively in appropriate patients with a possibility of durable responses. Nevertheless, there is a remaining need for effective therapies for these patients.
Of ail new cases of cancer in the United States, bladder cancer represents approximately 5 percent in men (fifth most common neoplasm) and 3 percent in women (eighth most common neoplasm). The incidence is increasing slowly, concurrent with an increasing older population. In 1998, there was an estimated 54,500 cases, including 39,500 in men and 15,000 in women. The age-adjusted incidence in the United States is 32 per 100,000 for men and eight per 100,000 in women. The historic male/female ratio of 3:1 may be decreasing related to smoking patterns in women. There were an estimated 11 ,000 deaths from bladder cancer in 1998 (7,800 in men and 3,900 in women). Bladder cancer incidence and mortality strongly increase with age and will be an increasing problem as the population becomes more elderly.
Most bladder cancers recur in the bladder. Bladder cancer is managed with a combination of transurethral resection of the bladder (TUR) and intravesical chemotherapy or immunotherapy. The multifocal and recurrent nature of bladder cancer points out the limitations of TUR. Most muscle-invasive cancers are not cured by TUR alone. Radical cystectomy and urinary diversion is the most effective means to eliminate the cancer but carry an undeniable impact on urinary and sexual function. There continues to be a significant need for treatment modalities that are beneficial for bladder cancer patients.
An estimated 130,200 cases of colorectal cancer occurred in 2000 in the United States, including 93,800 cases of colon cancer and 36,400 of rectal cancer. Colorectal cancers are the third most common cancers in men and women. Incidence rates declined significantly during 1992-1996 (-2.1% per year). Research suggests that these declines have been due to increased screening and polyp removal, preventing progression of polyps to invasive cancers. There were an estimated 56,300 deaths (47,700 from colon cancer, 8,600 from rectal cancer) in 2000, accounting for about 11 % of all U.S. cancer deaths.
At present, surgery is the most common form of therapy for colorectal cancer, and for cancers that have not spread, it is frequently curative. Chemotherapy, or chemotherapy plus radiation, is given before or after surgery to most patients whose cancer has deeply perforated the bowel wall or has spread to the lymph nodes. A permanent colostomy (creation of an abdominal opening for elimination of body wastes) is occasionally needed for colon cancer and is infrequently required for rectal cancer. There continues to be a need for effective diagnostic and treatment modalities for colorectal cancer.
There were an estimated 164,100 new cases of lung and bronchial cancer in 2000, accounting for 14% of all U.S. cancer diagnoses. The incidence rate of lung and bronchial cancer is declining significantly in men, from a high of 86.5 per 100,000 in 1984 to 70.0 in 1996. In the 1990s, the rate of increase among women began to slow. In 1996, the incidence rate in women was 42.3 per 100,000.
Lung and bronchial cancer caused an estimated 156,900 deaths in 2000, accounting for 28% of all cancer deaths. During 1992-1996, mortality from lung cancer declined significantly among men (-1.7% per year) while rates for women were still significantly increasing (0.9% per year). Since 1987, more women have died each year of lung cancer than breast cancer, which, for over 40 years, was the major cause of cancer death in women. Decreasing lung cancer incidence and mortality rates most likely resulted from deσeased smoking rates over the previous 30 years; however, decreasing smoking patterns among women lag behind those of men. Of concern, although the declines in adult tobacco use have slowed, tobacco use in youth is increasing again.
Treatment options for lung and bronchial cancer are determined by the type and stage of the cancer and include surgery, radiation therapy, and chemotherapy. For many localized cancers, surgery is usually the treatment of choice. Because the disease has usually spread by the time it is discovered, radiation therapy and chemotherapy are often needed in combination with surgery. Chemotherapy alone or combined with radiation is the treatment of choice for small cell lung cancer; on this regimen, a large percentage of patients experience remission, which in some cases is long lasting. There is however, an ongoing need for effective treatment and diagnostic approaches for lung and bronchial cancers.
An estimated 182,800 new invasive cases of breast cancer were expected to occur among women in the United States during 2000. Additionally, about 1 ,400 new cases of breast cancer were expected to be diagnosed in men in 2000. After increasing about 4% per year in the 1980s, breast cancer incidence rates in women have leveled off in the 1990s to about 110.6 cases per 100,000.
In the U.S. alone, there were an estimated 41 ,200 deaths (40,800 women, 400 men) in 2000 due to breast cancer. Breast cancer ranks second among cancer deaths in women. According to the most recent data, mortality rates declined significantly during 1992-1996 with the largest decreases in younger women, both white and black. These decreases were probably the result of earlier detection and improved treatment.
Taking into account the medical circumstances and the patient's preferences, treatment of breast cancer may involve lumpectomy (local removal of the tumor) and removal of the lymph nodes under the arm; mastectomy (surgical removal of the breast) and removal of the lymph nodes under the arm; radiation therapy; chemotherapy; or hormone therapy. Often, two or more methods are used in combination. Numerous studies have shown that, for early stage disease, long-term survival rates after lumpectomy plus radiotherapy are similar to survival rates after modified radical mastectomy. Significant advances in reconstruction techniques provide several options for breast reconstruction after mastectomy. Recently, such reconstruction has been done at the same time as the mastectomy.
Local excision of ductal carcinoma in situ (DCIS) with adequate amounts of surrounding normal breast tissue may prevent the local recurrence of the DCIS. Radiation to the breast and/or tamoxifen may reduce the chance of DCIS occurring in the remaining breast tissue. This is important because DCIS, if left untreated, may develop into invasive breast cancer. Nevertheless, there are serious side effects or sequelae to these treatments. There is, therefore, a need for efficacious breast cancer treatments.
There were an estimated 23,100 new cases of ovarian cancer in the United States in 2000. It accounts for 4% of all cancers among women and ranks second among gynecologic cancers. During 1992-1996, ovarian cancer incidence rates were significantly declining. Consequent to ovarian cancer, there were an estimated 14,000 deaths in 2000. Ovarian cancer causes more deaths than any other cancer of the female reproductive system.
Surgery, radiation therapy, and chemotherapy are treatment options for ovarian cancer. Surgery usually includes the removal of one or both ovaries, the fallopian tubes (salpingo-oophorectomy), and the uterus (hysterectomy). In some very early tumors, only the involved ovary will be removed, especially in young women who wish to have children. In advanced disease, an attempt is made to remove all intra-abdominal disease to enhance the effect of chemotherapy. There continues to be an important need for effective treatment options for ovarian cancer.
There were an estimated 28,300 new cases of pancreatic cancer in the United States in 2000. Over the past 20 years, rates of pancreatic cancer have declined in men. Rates among women have remained approximately constant but may be beginning to decline. Pancreatic cancer caused an estimated 28,200 deaths in 2000 in the United States. Over the past 20 years, there has been a slight but significant decrease in mortality rates among men (about -0.9% per year) while rates have increased slightly among women.
Surgery, radiation therapy, and chemotherapy are treatment options for pancreatic cancer. These treatment options can extend survival and/or relieve symptoms in many patients but are not likely to produce a cure for most. There is a significant need for additional therapeutic and diagnostic options for pancreatic cancer.
SUMMARY OF THE INVENTION
The present invention relates to a gene, designated 24P4C12, that has now been found to be over-expressed in the cancer(s) listed in Table I. Northern blot expression analysis of 24P4C12 gene expression in normal tissues shows a restricted expression pattern in adult tissues. The nucleotide (Figure 2) and amino acid (Figure 2, and Figure 3) sequences of 24P4C12 are provided. The tissue-related profile of 24P4C12 in normal adult tissues, combined with the over-expression observed in the tissues listed in Table I, shows that 24P4C12 is aberrantly over-expressed in at least some cancers, and thus serves as a useful diagnostic, prophylactic, prognostic, and/or therapeutic target for cancers of the tissue(s) such as those listed in Table I.
The invention provides polynucleotides corresponding or complementary to all or part of the 24P4C12 genes, mRNAs, and/or coding sequences, preferably in isolated form, including polynucleotides encoding 24P4C12-. elated proteins and fragments of 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, or more than 25 contiguous amino acids; at least 30, 35, 40, 45, 50, 55, 60, 65, 70, 80, 85, 90, 95, 100 or more than 100 contiguous amino acids of a 24P4C12-related protein, as well as the peptides/proteins themselves; DNA, RNA, DNA/RNA hybrids, and related molecules, polynucleotides or oligonucleotides complementary or having at least a 90% homology to the 24P4C12 genes or mRNA sequences or parts thereof, and polynucleotides or oligonucleotides that hybridize to the 24P4C12 genes, mRNAs, or to 24P4C12-encoding polynucleotides. Also provided are means for isolating cDNAs and the genes encoding 24P4C12. Recombinant DNA molecules containing 24P4C12 polynucleotides, cells transformed or transduced with such molecules, and host-vector systems for the expression of 24P4C12 gene products are also provided. The invention further provides antibodies that bind to 24P4C12 proteins and polypeptide fragments thereof, including polyclonal and monoclonal antibodies, murine and other mammalian antibodies, chimeric antibodies, humanized and fully human antibodies, and antibodies labeled with a detectable marker or therapeutic agent. In certain embodiments, there is a proviso that the entire nucleic acid sequence of Figure 2 is not encoded and/or the entire amino acid sequence of Figure 2 is not prepared. In certain embodiments, the entire nucleic acid sequence of Figure 2 is encoded and/or the entire amino acid sequence of Figure 2 is prepared, either of which are in respective human unit dose forms.
The invention further provides methods for detecting the presence and status of 24P4C12 polynucleotides and proteins in various biological samples, as well as methods for identifying cells that express 24P4C12. A typical embodiment of this invention provides methods for monitoring 24P4C12 gene products in a tissue or hematology sample having or suspected of having some form of growth dysregulation such as cancer.
The invention further provides various immunogenic or therapeutic compositions and strategies for treating cancers that express 24P4C12 such as cancers of tissues listed in Table I, including therapies aimed at inhibiting the transcription, translation, processing or function of 24P4C12 as well as cancer vaccines. In one aspect, the invention provides compositions, and methods comprising them, for treating a cancer that expresses 24P4C12 in a human subject wherein the composition comprises a carrier suitable for human use and a human unit dose of one or more than one agent that inhibits
the production or function of 24P4C12. Preferably, the carrier is a uniquely human carrier. In another aspect of the invention, the agent is a moiety that is immunoreactive with 24P4C12 protein. Non-limiting examples of such moieties include, but are not limited to, antibodies (such as single chain, monoclonal, polyclonal, humanized, chimeric, or human antibodies), functional equivalents thereof (whether naturally occurring or synthetic), and combinations thereof. The antibodies can be conjugated to a diagnostic or therapeutic moiety. In another aspect, the agent is a small molecule as defined herein.
In another aspect, the agent comprises one or more than one peptide which comprises a cytotoxic T lymphocyte (CTL) epitope that binds an HLA class I molecule in a human to elicit a CTL response to 24P4C12 and/or one or more than one peptide which comprises a helper T lymphocyte (HTL) epitope which binds an HLA class II molecule in a human to elicit an HTL response. The peptides of the invention may be on the same or on one or more separate polypeptide molecules. In a further aspect of the invention, the agent comprises one or more than one nucleic acid molecule that expresses one or more than one of the CTL or HTL response stimulating peptides as described above. In yet another aspect of the invention, the one or more than one nucleic acid molecule may express a moiety that is immunologically reactive with 24P4C12 as described above. The one or more than one nucleic acid molecule may also be, or encodes, a molecule that inhibits production of 24P4C12. Non-limiting examples of such molecules include, but are not limited to, those complementary to a nucleotide sequence essential for production of 24P4C12 (e.g. antisense sequences or molecules that form a triple helix with a nucleotide double helix essential for 24P4C12 production) or a ribozyme effective to lyse 24P4C12 mRNA.
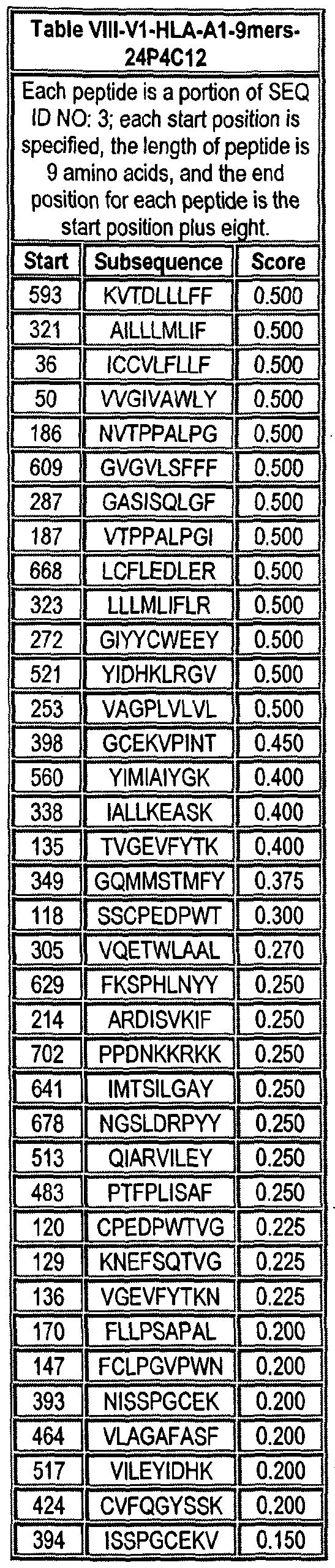
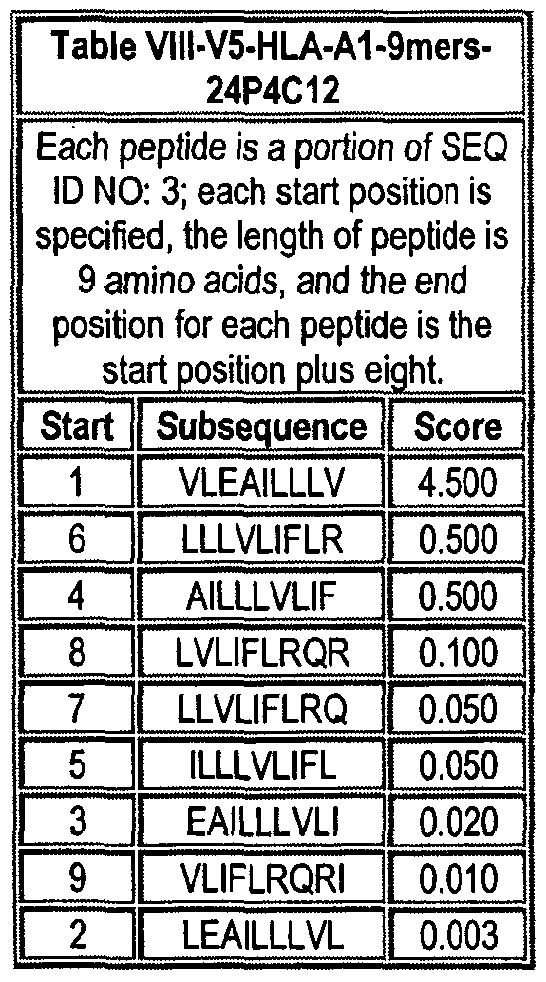
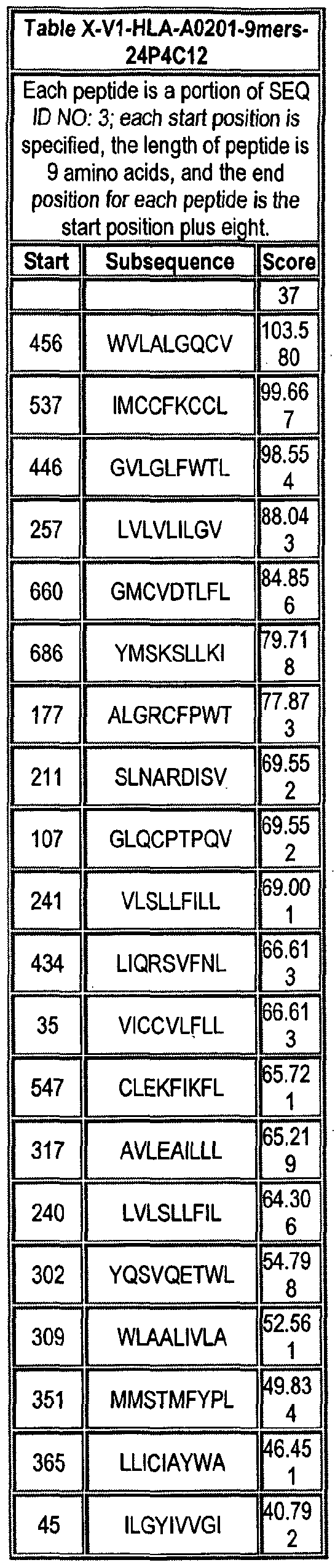
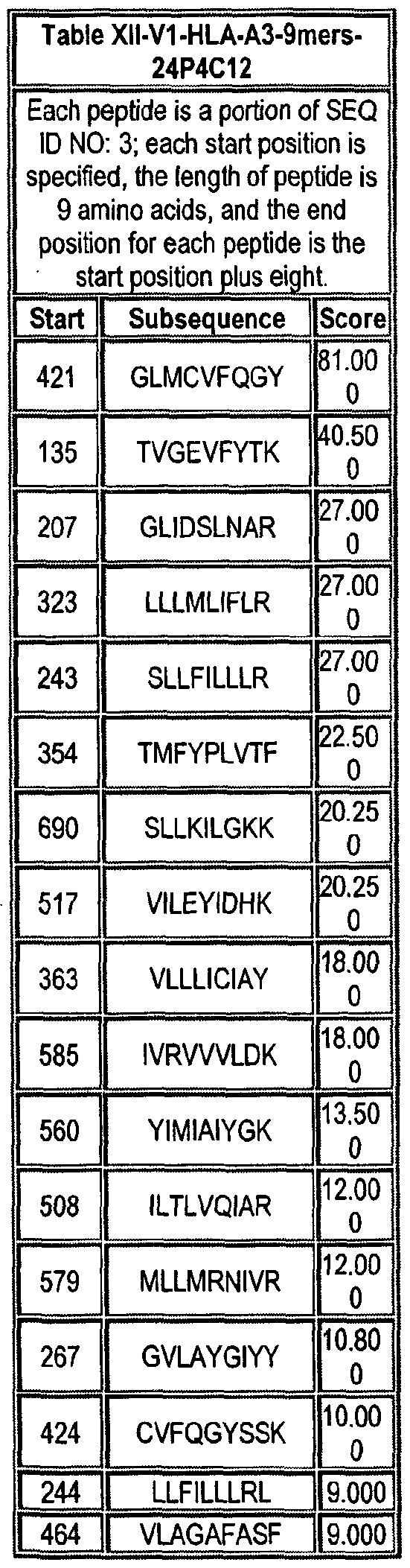
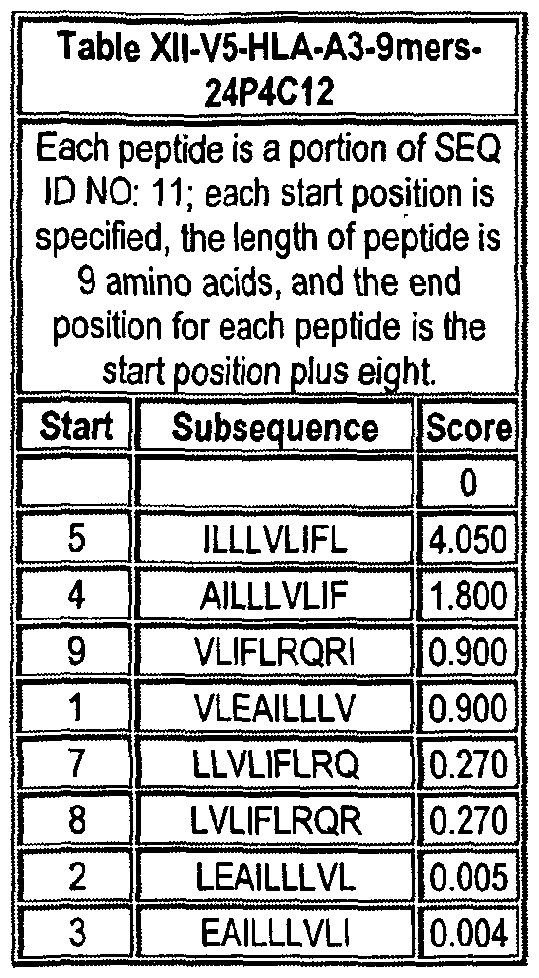
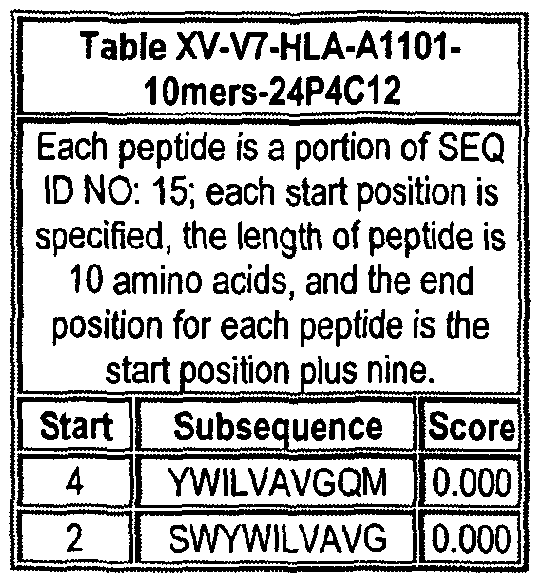
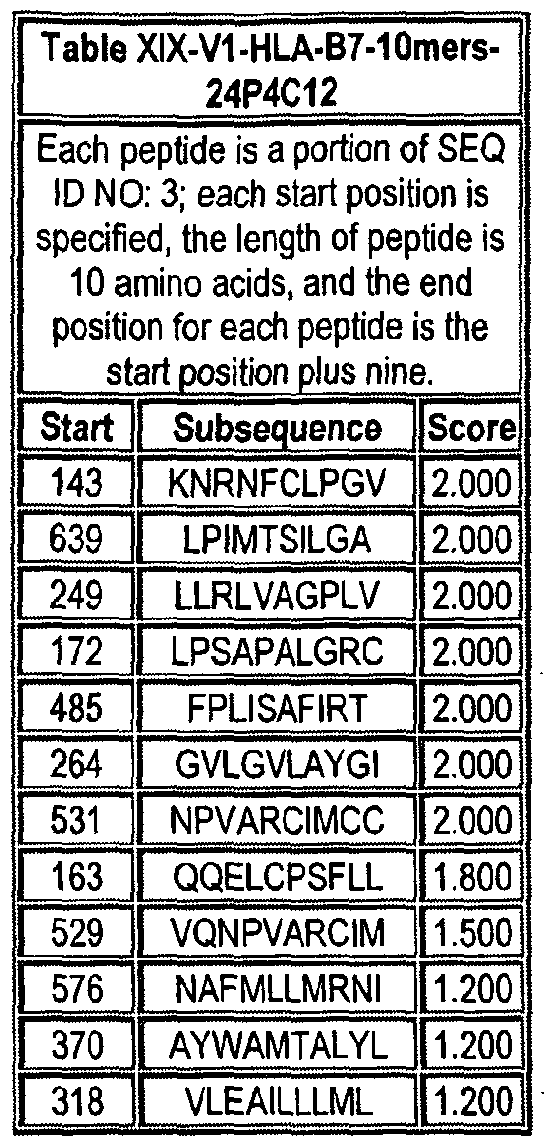
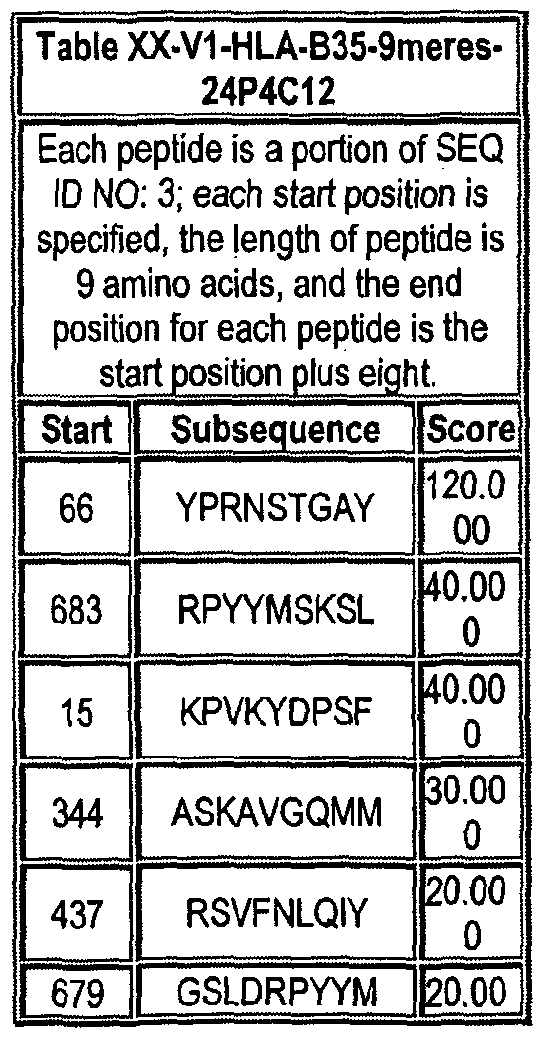
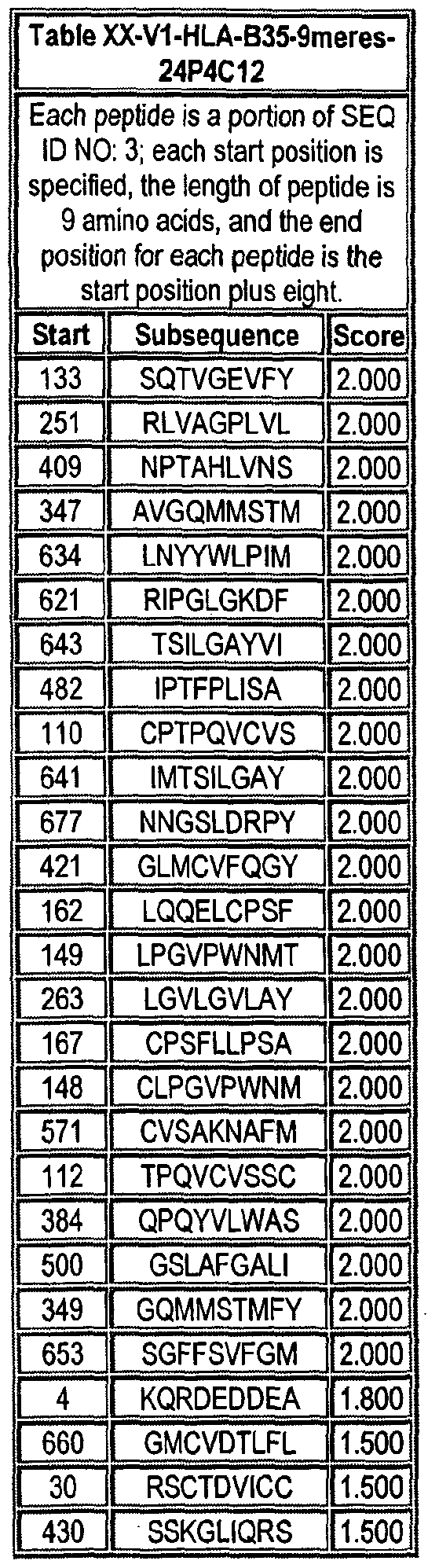
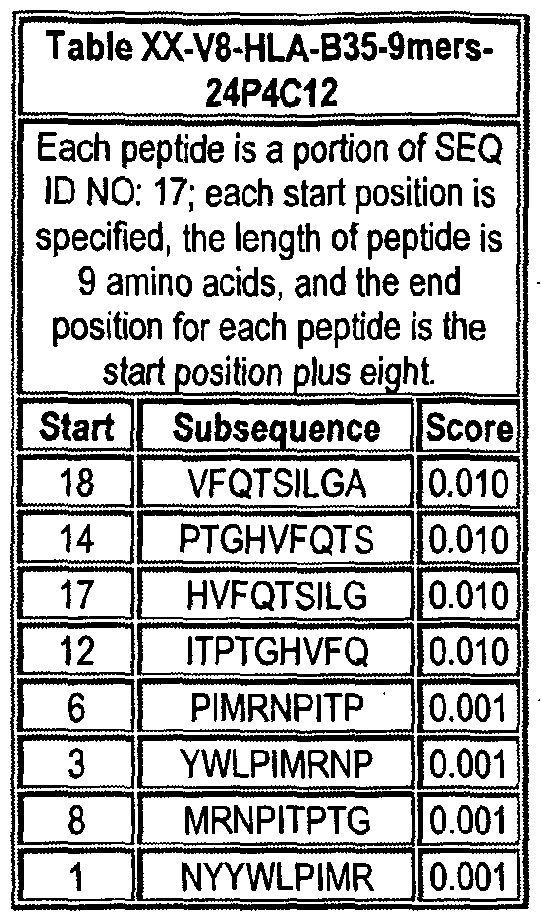
Note that to determine the starting position of any peptide set forth in Tables VIII-XXI and XXII to XLIX (collectively HLA Peptide Tables) respective to its parental protein, e.g., variant 1, variant 2, etc., reference is made to three factors: the particular variant, the length of the peptide in an HLA Peptide Table, and the Search Peptides in Table VII. Generally, a unique Search Peptide is used to obtain HLA peptides of a particular for a particular variant. The position of each Search Peptide relative to its respective parent molecule is listed in Table VII. Accordingly, if a Search Peptide begins at position "X", one must add the value "X - V to each position in Tables VIII-XXI and XXII to XLIX to obtain the actual position of the HLA peptides in their parental molecule. For example, if a particular Search Peptide begins at position 150 of its parental molecule, one must add 150 - , i.e., 149 to each HLA peptide amino acid position to calculate the position of that amino acid in the parent molecule.
One embodiment of the invention comprises an HLA peptide, that occurs at least twice in Tables VIII-XXI and XXII to XLIX collectively, or an oligonucleotide that encodes the HLA peptide. Another embodiment of the invention comprises an HLA peptide that occurs at least once in Tables VIII-XXI and at least once in tables XXII to XLIX, or an oligonucleotide that encodes the HLA peptide.
Another embodiment of the invention is antibody epitopes, which comprise a peptide regions, or an oligonucleotide encoding the peptide region, that has one two, three, four, or five of the following characteristics: i) a peptide region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino acid position having a value equal to or greater than 0.5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Hydrophilicity profile of Figure 5; ii) a peptide region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino acid position having a value equal to or less than 0.5, 0.4, 0.3, 0.2, 0.1, or having a value equal to 0.0, in the Hydropathiάty profile of Figure 6; iii) a peptide region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino acid position having a value equal to or greater than 0.5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Percent Accessible Residues profile of Figure 7;
iv) a peptide region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino acid position having a value equal to or greater than 0.5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Average Flexibility profile of Figure 8; or v) a peptide region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino acid position having a value equal to or greater than 0.5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Beta-turn profile of Figure 9.
BRIEF DESCRIPTION OF THE FIGURES
Figure 1. The 24P4C12 SSH sequence of 160 nucleotides.
Figure 2. A) The cDNA and amino acid sequence of 24P4C12 variant 1 (also called "24P4C12 v.1" or "24P4C12 variant 1") is shown in Figure 2A. The start methionine is underlined. The open reading frame extends from nucleic acid 6-
2138 including the stop codon.
B) The cDNA and amino acid sequence of 24P4C12 variant 2 (also called "24P4C12 v.2") is shown in Figure 2B. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2138 including the stop codon.
C) The cDNA and amino acid sequence of 24P4C12 variant 3 (also called "24P4C12 v.3") is shown in Figure 20 The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2138 including the stop codon,
D) The cDNA and amino acid sequence of 24P4C12 variant 4 (also called "24P4C12 v.4") is shown in Figure 2D. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2138 including the stop codon.
E) The cDNA and amino acid sequence of 24P4C12 variant 5 (also called "24P4C12 v.5") is shown in Figure 2E. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2138 including the stop codon.
F) The cDNA and amino acid sequence of 24P4C12 variant 6 (also called "24P4C12 v.6") is shown in Figure 2F. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2138 including the stop codon.
G) The cDNA and amino acid sequence of 24P4C12 variant 7 (also called "24P4C12 v.7") is shown in Figure 2G. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-1802 including the stop codon.
H) The cDNA and amino acid sequence of 24P4C12 variant 8 (also called "24P4C12 v.8") is shown in Figure 2H. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2174 including the stop codon.
I) The cDNA and amino acid sequence of 24P4C12 variant 9 (also called "24P4C12 v.9n) is shown in Figure 21. The codon for the start methionine is underlined. The open reading frame extends from nucleic acid 6-2144 including the stop codon.
Figure 3.
A) Amino acid sequence of 24P4C12 v.1 is shown in Figure 3A; it has 710 amino acids.
B) The amino acid sequence of 24P4C12 v.3 is shown in Figure 3B; it has 710 amino acids.
C) The amino acid sequence of 24P4C12 v.5 is shown in Figure 3C; it has 710 amino acids.
D) The amino acid sequence of 24P4C12 v.6 is shown in Figure 3D; it has 710 amino acids.
E) The amino acid sequence of 24P4C12 v.7 is shown in Figure 3E; it has 598 amino acids.
F) The amino acid sequence of 24P4C12 v.8 is shown in Figure 3F; it has 722 amino acids.
G) The amino acid sequence of 24P4C12 v.9 is shown in Figure 3G; it has 712 amino acids. As used herein, a reference to 24P4C12 includes all variants thereof, including those shown in Figures 2, 3, 10, and 11, unless the context clearly indicates otherwise.
Figure 4. Alignment or 24P4C12 with human choline transporter-like protein 4 (CTL4) (gi|14249468).
Figure 5. Hydrophilicity amino acid profile of 24P4C12 determined by computer algorithm sequence analysis using the method of Hopp and Woods (Hopp T.P., Woods K.R., 1981. Proc. Natl. Acad. Sci. U.S.A.78:3824-3828) accessed on the Protscale website located on the World Wide Web at (.expasy.ch/cgi-bin/protscale.pl) through the ExPasy molecular biology server.
Figure 6. Hydropathicity amino acid profile of 24P4C12 determined by computer algorithm sequence analysis using the method of Kyte and Doolittle (Kyte J., Doolittle R.F., 1982. J. Mol. Biol. 157:105-132) accessed on the ProtScale website located on the World Wide Web at (.expasy.ch/cgi-bin/protscale.pl) through the ExPasy molecular biology server.
Figure 7. Percent accessible residues amino acid profile of 24P4C12 determined by computer algorithm sequence analysis using the method of Janin (Janin J., 1979 Nature 277:491492) accessed on the ProtScale website located on the World Wide Web at (.expasy.ch/cgi-bin/protscale.pl) through the ExPasy molecular biology server.
Figure 8.. Average flexibility amino acid profile of 24P4C12 determined by computer algorithm sequence analysis using the method of Bhaskaran and Ponnuswamy (Bhaskaran R., and Ponnuswamy P.K., 1988 Int. J. Pept. Protein Res. 32:242-255) accessed on the ProtScale website located on the World Wide Web at (.expasy.ch/cgi-bin/protscale.pl) through the ExPasy molecular biology server.
Figure 9. Beta-turn amino acid profile of 24P4C12 determined by computer algorithm sequence analysis using the method of Deleage and Roux (Deleage, G., Roux B. 1987 Protein Engineering 1:289-294) accessed on the ProtScale website located on the World Wide Web at (.expasy.ch/cgi-bin/protscale.pl) through the ExPasy molecular biology server.
Figure 10. Schematic alignment of SNP variants of 24P4C12. Variants 24P4C12 v.2 through v.6 are variants with single nucleotide differences. Though these SNP variants are shown separately, they could also occur in any combinations and in any transcript variants that contains the base pairs. Numbers correspond to those of 24P4C12 v.1. Black box shows the same sequence as 24P4C12 v.1. SNPs are indicated above the box.
Figure 11. Schematic alignment of protein variants of 24P4C12. Protein variants correspond to nucleotide variants. Nucleotide variants 24P4C12 v.2, v.4 in Figure 10 code for the same protein as 24P4C12 v.1. Nucleotide variants 24P4C12 v.7, v.8 and v.9 are splice variants of v.1, as shown in Figure 12. Single amino acid differences were indicated above the boxes. Black boxes represent the same sequence as 24P4C12 v.1. Numbers underneath the box correspond to 24P4C12 V.1.
Figure 12. Exon compositions of transcript variants of 24P4C12. Vanant24P4C12 v.7, v.8 and v.9 are transcript variants of 24P4C12 v.1. Variant 24P4C12 v.7 does not have exons 10 and 11 of variant 24P4C12 v.1. Variant 24P4C12 v.8 extended 36 bp at the 3' end of exon 20 of variant 24P4C12 v.1. Variant 24P4C12 v.9 had a longer exon 12 and shorter exon 13 as compared to variant 24P4C12 v.1. Numbers in "( )" underneath the boxes correspond to those of 24P4C12 v.1. Lengths of introns and exons are not proportional.
Figure 13. Secondary structure and transmembrane domains prediction for 24P4C12 protein variant 1 (SEQ ID NO: 112). A: The secondary structure of 24P4C12 protein variant 1 was predicted using the HNN - Hierarchical Neural Network method (Guermeur, 1997, http://pbil.ibcp.fr/cgi-bin/npsa_automat.pl?page=npsa_nn.html), accessed from the ExPasy molecular biology server (http://www.expasy.ch/tools/). This method predicts the presence and location of alpha helices, extended strands, and random coils from the primary protein sequence. The percent of the protein in a given
secondary structure is also listed. B: Schematic representation of the probability of existence of transmembrane regions and orientation of 24P4C12 variant 1 based on the TMpred algorithm of Hofmann and Stoffel which utilizes TMBASE (K. Hofmann, W. Stoffel. TMBASE - A database of membrane spanning protein segments Biol. Chem. Hoppe-Seyler 374:166, 1993). C: Schematic representation of the probability of the existence of transmembrane regions and the extracellular and intracellular orientation of 24P4C12 variant 1 based on the TMHMM algorithm of Sonnhammer, von Heijne, and Krogh (Erik L.L. Sonnhammer, Guπnar von Heijne, and Anders Krogh: A hidden Markov model for predicting transmembrane helices in protein sequences. In Proc. of Sixth Int. Conf. on Intelligent Systems for Molecular Biology, p 175-182 Ed J. Glasgow, T. Littlejohn, F. Major, R. Lathrop, D. Sankoff, and C. Sensen Menlo Park, CA: AAAI Press, 1998). The TMpred and TMHMM algorithms are accessed from the ExPasy molecular biology server (http://www.expasy.ch/tools/).
Figure 14. 24P4C12 Expression by RT-PCR. First strand cDNA was generated from vital pool 1 (kidney, liver and lung), vital pool 2 (colon, pancreas and stomach), a pool of prostate cancer xenografts (LAPC-4AD, LAPC-4AI, LAPC-9AD and LAPC-9AI), prostate cancer pool, bladder cancer pool, kidney cancer pool, colon cancer pool, ovary cancer pool, breast cancer pool, and cancer metastasis pool. Normalization was performed by PCR using primers to actin. Semi-quantitative PCR, using primers to 24P4C12, was performed at 26 and 30 cycles of amplification. Results show strong expression of 24P4C12 in prostate cancer pool and ovary cancer pool. Expression was also detected in prostate cancer xenografts, bladder cancer pool, kidney cancer pool, colon cancer pool, breast cancer pool, cancer metastasis pool, vital pool 1 , and vital pool 2.
Figure 15. Expression of 24P4C12 in normal tissues. Two multiple tissue northern blots (Clontech) both with 2 ug of mRNA/lane were probed with the 24P4C12 sequence. Size standards in kilobases (kb) are indicated on the side. Results show expression of 24P4C12 in prostate, kidney and colon. Lower expression is detected in pancreas, lung and placenta amongst all 16 normal tissues tested.
Figure 16. Expression of 24P4C12 in Prostate Cancer Xenografts and Cell Lines. RNA was extracted from a panel of cell lines and prostate cancer xenografts (PrEC, LAPC-4AD, LAPC-4AI, LAPC-9AD, LAPC-9AI, LNCaP, PC-3, DU145, TsuPr, and LAPC-4CL). Northern blot with 10 ug of total RNA/lane was probed with 24P4C12 SSH sequence. Size standards in kilobases (kb) are indicated on the side. The 24P4C12 transcript was detected in LAPC-4AD, LAPC-4AI, LAPC- 9AD, LAPC-9AI, LNCaP, and LAPC-4 CL.
Figure 17. Expression of 24P4C12 in Patient Cancer Specimens and Normal Tissues. RNA was extracted from a pool of prostate cancer specimens, bladder cancer specimens, colon cancer specimens, ovary cancer specimens, breast cancer specimens and cancer metastasis specimens, as well as from normal prostate (NP), normal bladder (NB), normal kidney (NK), and normal colon (NC). Northern blot with 10 μg of total RNA/lane was probed with 24P4C12 SSH sequence. Size standards in kilobases (kb) are indicated on the side. Strong expression of 24P4C12 transcript was detected in the patient cancer pool specimens, and in normal prostate but not in the other normal tissues tested.
Figure 18. Expression of 24P4C12 in Prostate Cancer Patient Specimens. RNA was extracted from normal prostate (N), prostate cancer patient tumors (T) and their matched normal adjacent tissues (Nat). Northern blots with 10 ug of total RNA were probed with the 24P4C12 SSH fragment. Size standards in kilobases are on the side. Results show expression of 24P4C12 in normal prostate and all prostate patient tumors tested.
Figure 19. Expression of 24P4C12 in Colon Cancer Patient Specimens. RNA was extracted from colon cancer cell lines (CL: Colo 205, LoVo, and SK-CO-), normal colon (N), colon'cancer patient tumors (T) and their matched normal adjacent tissues (Nat). Northern blots with 10 ug of total RNA were probed with the 24P4C12 SSH fragment. Size standards in kilobases are on the side. Results show expression of 24P4C12 in normal colon and all colon patient tumors tested. Expression was detected in the cell lines Colo 205 and SK-CO-, but not in LoVo.
Figure 20. Expression of 24P4C12 in Lung Cancer Patient Specimens. RNA was extracted from lung cancer cell lines (CL: CALU-1 , A427, NCI-H82, NCI-H146), normal lung (N), lung cancer patient tumors (T) and their matched normal adjacent tissues (Nat). Northern blots with 10 ug of total RNA were probed with the 24P4C12 SSH fragment. Size standards in kilobases are on the side. Results show expression of 24P4C12 in lung patient tumors tested, but not in normal lung. Expression was also detected in CALU-1 , but not in the other cell lines A427, NCI-H82, and NCI-H146.
Figure 21. Expression of 24P4C12 in breast and stomach human cancer specimens. Expression of 24P4C12 was assayed in a panel of human stomach and breast cancers (T) and their respective matched normal tissues (N) on RNA dot blots. 24P4C12 expression was seen in both stomach and breast cancers. The expression detected in normal adjacent tissues (isolated from diseased tissues) but not in normal tissues (isolated from healthy donors) may indicate that these tissues are not fully normal and that 24P4C12 may be expressed in early stage tumors.
Figure 22. 24P4C12 Expression in a large panel of Patient Cancer Specimens. First strand cDNA was prepared from a panel of ovary patient cancer specimens (A), uterus patient cancer specimens (B), prostate cancer specimens (C), bladder cancer patient specimens (D), lung cancer patient specimens (E), pancreas cancer patient specimens (F), colon cancer specimens (G), and kidney cancer specimens (H). Normalization was performed by PCR using primers to actin. Semi-quantitative PCR, using primers to 24P4C12, was performed at 26 and 30 cycles of amplification. Samples were run on an agarose gel, and PCR products were quantitated using the Alphalmager software. Expression was recorded as absent, low, medium or strong. Results show expression of 24P4C12 in the majority of patient cancer specimens tested, 73.3% of ovary patient cancer specimens, 83.3% of uterus patient cancer specimens, 95.0% of prostate cancer specimens, 61.1 % of bladder cancer patient specimens, 80.6% of lung cancer patient specimens, 87.5% of pancreas cancer patient specimens, 87.5% of colon cancer specimens, 68.4% of of clear cell renal carcinoma, 100% of papillary renal cell carcinoma.
Figure 23. 24P4C12 expression in transduced cells. PC3 prostate cancer cells, NIH-3T3 mouse cells and 300.19 mouse cells were transduced with 24P4C12 .pSRa retroviral vector. Cells were selected in neomycin for the generation of stable cell lines. RNA was extracted following selection in neomycin. Northern blots with 10 ug of total RNA were probed with the 24P4C12 SSH fragment. Results show strong expression of 24P4C12 in 24P4C12.pSRa transduced PC3, 3T3 and 300.19 cells, but not in the control cells transduced with the parental pSRa construct.
Figure 24. Expression of 24P4C12 in 293T cells. 293T cell were transiently transfected with either pCDNA3.1 Myc-His tagged expression vector, the pSRO expression vector each encoding the 24P4C12 variant 1 cDNA or a control neo vector. Cells were harvested 2 days later and analyzed by Western blot with anti-24P4C12 pAb (A) or by Flow cytometry (B) on fixed and permeabilized 293T cells with either the anti-24P4C12 pAb or anti-His pAb followed by a PE-conjugated anti- rabbit IgG secondary Ab. Shown is expression of the monomeric and aggregated forms of 24P4C12 by Western blot and a fluorescent shift of 24P4C12-293T cells compared to control neo cells when stained with the anti-24P4C12 and anti-His pAbs which are directed to the intracellular NH3 and COOH termini, respectively.
Figure 25. Expression and detection of 24P4C12 in stably transduced PC3 cells. PC3 cells were infected with retrovirus encoding the 24P4C12 variant 1 cDNA and stably transduced ceils were derived by G418 selection. Cells were then analyzed by Western blot (A) or immunohistochemistry (B) with anti-24P4C12 pAb. Shown with an arrow on the Western blot is expression of a -94 kD band representing 24P4C12 expressed in PC3-24P4C12 cells but not in control neo cells. Immunohistochemical analysis shows specific staining of 24P4C12-PC3 cells and not PC3-neo cells which is competed away competitor peptide to which the pAb was derived.
Figure 26. Expression of recombinant 24P4C12 antigens in 293T cells. 293T cells were transiently transfected with Tag5 His-tagged expression vectors encoding either amino acids 59-227 or 319-453 of 24P4C12 variant 1 or a control vector. 2 days later supernatants were collected and cells harvested and lysed. Supernatants and lysates were then subjected to Western blot analysis using an anti-His pAb. Shown is expression of the recombinant Tag559-227 protein in
both the supernatant and lysate and the Tag5 319-453 protein in lhe cell lysate. These proteins are purified and used as antigens for generation of 24P4C12-specific antibodies,
Figure 27. Monoclonal antibodies detect 24P4C12 protein expression in 293T cells by flow cytometry. 293T cells were transfected with either pCDNA 3.1 His-tagged expression vector for 24P4C12 or a control neo vector and harvested 2 days later. Cells were fixed, permeabilized, and stained with a 1 :2 dilution of supernatants of the indicated hybridomas generated from mice immunized with 300.19-24P4C12 cells or with anti-His pAb. Ceils were then stained with a PE- conjugated secondary Ab and analyzed by flow cytometry. Shown is a fluorescent shift of 293T-24P4C12 cells but not control neo cells demonstrating specific recognition of 24P4C12 protein by the hybridoma supernatants.
Figure 28. Shows expression of 24P4C12 Enhances Proliferation. PC3 and 3T3 were grown overnight in low FBS. Cells were then incubated in low or 10% FBS as indicated. Proliferation was measured by Alamar Blue.
Figure 29. Detection of 24P4C12 protein by immunohistochemistry in prostate cancer patient specimens. Prostate adenocarcinoma tissue and its matched normal adjacent tissue were obtained from prostate cancer patients. The results showed strong expression of 24P4C12 in the tumor cells and normal epithelium of the prostate cancer patients' tissue (panels (A) low grade prostate adenocarcinoma, (B) high grade prostate adenocarcinoma, (C) normal tissue adjacent to tumor). The expression was detected mostly around the cell membrane indicating that 24P4C12 is membrane associated in prostate tissues.
Figure 30. Detection of 24P4C12 protein by immunohistochemistry in various cancer patient specimens. Tissue was obtained from patients with colon adenocarcinoma, breast dυcta) carcinoma, lung adenocarcinoma, bladder transitional cell carcinoma, renal clear cell carcinoma and pancreatic adenocarcinoma. The results showed expression of 24P4C12 in the tumor cells of the cancer patients' tissue (panel (A) colon adenocarcinoma, (B) lung adenocarcinoma, (C) breast ductal carcinoma, (D) bladder transitional carcinoma, (E) renal clear cell carcinoma, (F) pancreatic adenocarcinoma).
Figure 31. Shows 24P4C12 Enhances Tumor Growth in SCID Mice. 1 x 106 PC3-24P4C12 cells were mixed with Matrigel and injected on the right and left subcutaneous flanks of 4 male SCID mice per group. Each data point represents mean tumor volume (n=8).
Figure 32. Shows 24P4C12 Enhances Tumor Growth in SCID Mice. 1 x 106 3T3-24P4C12 cells were mixed with
Matrigel and injected on the right subcutaneous flanks of 7 male SCID mice per group. Each data point represents mean tumor volume (n=6).
DETAILED DESCRIPTION OF THE INVENTION Outline of Sections
I.) Definitions
II.) 24P4C12 Polynucleotides
II.A.) Uses of 24P4C12 Polynucleotides
(I.A.1.) Monitoring of Genetic Abnormalities
II.A.2.) Antisense Embodiments
II.A.3.) Primers and Primer Pairs
II.A.4.) Isolation of 24P4C12-Encoding Nucleic Acid Molecules II 5.) Recombinant Nucleic Acid Molecules and Host-Vector Systems III.) 24P4C12-related Proteins
III.A.) Motif-bearing Protein Embodiments
III.B.) Expression of 24P4C12-related Proteins
III.C.) Modifications of 24P4C12-. elated Proteins
III.D.) Uses of 24P4C12-related Proteins
IV.) 24P4C12 Antibodies
V.) 24P4C12 Cellular Immune Responses
VI.) 24P4C12 Transgenic Animals
VII.) Methods for the Detection of 24P4C12
VIII.) Methods for Monitoring the Status of 24P4C12-related Genes and Their Products
IX.) Identification of Molecules That Interact With 24P4C12
X.) Therapeutic Methods and Compositions
X.A.) Anti-Cancer Vaccines X.B.) 24P4C12 as a Target for Antibody-Based Therapy X.C.) 24P4C12 as a Target for Cellular Immune Responses
X.C.1, Minigene Vaccines
X.C.2. Combinations of CTL Peptides with Helper Peptides
X.C.3. Combinations of CTL Peptides with T Cell Priming Agents
X.C.4. Vaccine Compositions Comprising DC Pulsed with CTL and/or HTL Peptides
X.D.) Adoptive Immunotherapy X.E.) Administration of Vaccines for Therapeutic or Prophylactic Purposes XI.) Diagnostic and Prognostic Embodiments of 24P4C12. XII.) Inhibition of 24P4C12 Protein Function
XII.A.) Inhibition of 24P4C12 With Intracellular Antibodies
XII.B.) Inhibition of 24P4C12 with Recombinant Proteins
XII.C.) Inhibition of 24P4C12 Transcription or Translation
Xll.D.) General Considerations for Therapeutic Strategies XIII.) Identification, Characterization and Use of Modulators of 24P4C12 XIV.) KITS/Articles of Manufacture
L) Definitions:
Unless otherwise defined, all terms of art, notations and other scientific terms or terminology used herein are intended to have the meanings commonly understood by those of skill in the art to which this invention pertains. In some cases, terms with commonly understood meanings are defined herein for clarity and/or for ready reference, and the inclusion of such definitions herein should not necessarily be construed to represent a substantial difference over what is generally understood in the art. Many of the techniques and procedures described or referenced herein are well understood and commonly employed using conventional methodology by those skilled in the art, such as, for example, the widely utilized molecular cloning methodologies described in Sambrook et al., Molecular Cloning: A Laboratory Manual 2nd, edition (1989) Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. As appropriate, procedures involving the use of commercially available kits and reagents are generally carried out in accordance with manufacturer defined protocols and/or parameters unless otherwise noted.
The terms "advanced prostate cancer", "locally advanced prostate cancer", "advanced disease" and "locally advanced disease" mean prostate cancers that have extended through the prostate capsule, and are meant to include stage C disease under the American Urological Association (AUA) system, stage C1 - C2 disease under the Whitmore-Jewett system, and stage T3 - T4 and N+ disease under the TNM (tumor, node, metastasis) system. In general, surgery is not recommended for patients with locally advanced disease, and these patients have substantially less favorable outcomes compared to patients having clinically localized (organ-confined) prostate cancer. Locally advanced disease is clinically
identified by palpable evidence of induration beyond the lateral border of the prostate, or asymmetry or induration above the prostate base. Locally advanced prostate cancer is presently diagnosed pathologically following radical prostatectomy if the tumor invades or penetrates the prostatic capsule, extends into the surgical margin, or invades the seminal vesicles.
"Altering the native glycosylation pattern" is intended for purposes herein to mean deleting one or more carbohydrate moieties found in native sequence 24P4C12 (either by removing the underlying glycosylation site or by deleting the glycosylation by chemical and/or enzymatic means), and/or adding one or more glycosylation sites that are not present in the native sequence 24P4C12. In addition, the phrase includes qualitative changes in the glycosylation of the native proteins, involving a change in the nature and proportions of the various carbohydrate moieties present.
The term "analog" refers to a molecule which is structurally similar or shares similar or corresponding attributes with another molecule (e.g. a 24P4C12-related protein). For example, an analog of a 24P4C12 protein can be specifically bound by an antibody or T cell that specifically binds to 24P4C12.
The term "antibody" is used in the broadest sense. Therefore, an "antibody" can be naturally occurring or man-made such as monoclonal antibodies produced by conventional hybridoma technology. Anti-24P4C12 antibodies comprise monoclonal and polyclonal antibodies as well as fragments containing the antigen-binding domain and/or one or more complementarity determining regions of these antibodies.
An "antibody fragment" is defined as at least a portion of the variable region of the immunoglobulin molecule that binds to its target, i.e., the antigen-binding region. In one embodiment it specifically covers single anti-24P4C12 antibodies and clones thereof (including agonist, antagonist and neutralizing antibodies) and anti-24P4C12 antibody compositions with polyepitopic specificity.
The term "codon optimized sequences" refers to nucleotide sequences that have been optimized for a particular host species by replacing any codons having a usage frequency of less than about 20%. Nucleotide sequences that have been optimized for expression in a given host species by elimination of spurious polyadenylation sequences, elimination of exon/intr on splicing signals, elimination of transposon-like repeats and/or optimization of GC content in addition to codon optimization are referred to herein as an "expression enhanced sequences."
A "combinatorial library" is a collection of diverse chemical compounds generated by either chemical synthesis or biological synthesis by combining a number of chemical "building blocks" such as reagents. For example, a linear combinatorial chemical library, such as a polypeptide (e.g., mutein) library, is formed by combining a set of chemical building blocks called amino acids in every possible way for a given compound length (i.e., the number of amino acids in a polypeptide compound). Numerous chemical compounds are synthesized through such combinatorial mixing of chemical building blocks (Gallop et al., J. Med. Chem. 37(9): 1233-1251 (1994)).
Preparation and sσeening of combinatorial libraries is well known to those of skill in the art. Such combinatorial chemical libraries include, but are not limited to, peptide libraries (see, e.g., U.S. Patent No. 5,010,175, Furka, Pept. Prot. Res. 37:487493 (1991), Houghton et al., Nature, 354:84-88 (1991)), peptoids (PCT Publication No WO 91/19735), encoded peptides (PCT Publication WO 93/20242), random bio- oligomers (PCT Publication WO 92/00091), benzodiazepines (U.S. Pat. No. 5,288,514), diversomers such as hydantoins, benzodiazepines and dipeptides (Hobbs et al., Proc. Nat. Acad. Sci. USA 90:6909-6913 (1993)), vinylogous polypeptides (Hagihara et al., J. Amer. Chem. Soc. 114:6568 (1992)), nonpeptidal peptidomimetics with a Beta-D-Glucose scaffolding (Hirschmann et al., J. Amer. Chem. Soc. 114:9217-9218 (1992)), analogous organic syntheses of small compound libraries (Chen et al., J. Amer. Chem. Soc. 116:2661 (1994)), oligocarbarnates (Cho, et al., Science 261 :1303 (1993)), and/or peptidyl phosphonates (Campbell et al., J. Org. Chem. 59:658 (1994)). See, generally, Gordon et al., J. Med. Chem. 37:1385 (1994), nucleic acid libraries (see, e.g., Stratagene, Corp.), peptide nucleic acid libraries (see, e.g., U.S. Patent 5,539,083), antibody libraries (see, e.g., Vaughn et al., Nature Biotechnology 14(3): 309-314 (1996), and PCT/US96/10287), carbohydrate libraries (see, e.g., Liang et al., Science
274:1520-1522 (1996), and U.S. Patent No. 5,593,853), and small organic molecule libraries (see, e.g., benzodiazepines, Baum, C&EN, Jan 18, page 33 (1993); isoprenoids, U.S. Patent No. 5,569,588; thiazolidinones and metathiazanones, U.S. Patent No. 5,549,974; pynolidines, U.S. Patent Nos. 5,525,735 and 5,519,134; morpholino compounds, U.S. Patent No. 5,506, 337; benzodiazepines, U.S. Patent No, 5,288,514; and the like).
Devices for the preparation of combinatorial libraries are commercially available (see, e.g., 357 NIPS, 390 NIPS, Advanced Chem Tech, Louisville KY; Symphony, Rainin, Woburn, MA; 433A, Applied Biosystems, Foster City, CA; 9050, Plus, Millipore, Bedford, NIA). A number of well-known robotic systems have also been developed for solution phase chemistries. These systems include automated workstations such as the automated synthesis apparatus developed by Takeda Chemical Industries, LTD. (Osaka, Japan) and many robotic systems utilizing robotic arms (Zymate H, Zymark Corporation, Hopkinton, Mass.; Orca, Hewlett-Packard, Palo Alto, Calif.), which mimic the manual synthetic operations performed by a chemist. Any of the above devices are suitable for use with the present invention. The nature and implementation of modifications to these devices (if any) so that they can operate as discussed herein will be apparent to persons skilled in the relevant art. In addition, numerous combinatorial libraries are themselves commercially available (see, e.g., ComGenex, Princeton, NJ; Asinex, Moscow, RU; Tripos, Inc., St. Louis, MO; ChemStar, Ltd, Moscow, RU; 3D Pharmaceuticals, Exton, PA; Martek Biosciences, Columbia, MD; etc.).
The term "cytotoxic agent" refers to a substance that inhibits or prevents the expression activity of cells, function of cells and/or causes destruction of cells. The term is intended to include radioactive isotopes chemotherapeutic agents, and toxins such as small molecule toxins or enzymatically active toxins of bacterial, fungal, plant or animal origin, including fragments and/or variants thereof. Examples of cytotoxic agents include, but are not limited to auristatins, auromycins, maytansinoids, yttrium, bismuth, ricin, ricin A-chain, combrestatin, duocarmycins, dolostatins, doxorubicin, daunorubicin, taxol, cisplatin, cc1065, ethidium bromide, mitomycin, etoposide, tenoposide, vincristine, vinblastine, colchicine, dihydroxy anthracin dione, actinomycin, diphtheria toxin, Pseudomonas exotoxin (PE) A, PE40, abrin, abrin A chain, modeccin A chain, alpha-sarcin, gelonin, mitogellin, retstrictocin, phenomycin, enomycin, curicin, crotjn, calicheamicin, Sapaonaria officinalis inhibitor, and glucocorticoid and other chemotherapeutic agents, as well as radioisotopes such as At211, 1131, 1125, Y90, Re186, Re188, Sm153, Bi212or213, P32 and radioactive isotopes of Lu including Lu177. Antibodies may also be conjugated to an anti- cancer pro-drug activating enzyme capable of converting the pro-drug to its active form.
The "gene product" is sometimes referred to herein as a protein or mRNA. For example, a "gene product of the invention" is sometimes referred to herein as a "cancer amino acid sequence", "cancer protein", "protein of a cancer listed in Table I", a "cancer mRNA", "mRNA of a cancer listed in Table I", etc. In one embodiment, the cancer protein is encoded by a nucleic acid of Figure 2. The cancer protein can be a fragment, or alternatively, be the full-length protein to the fragment encoded by the nucleic acids of Figure 2. In one embodiment, a cancer amino acid sequence is used to determine sequence identity or similarity. In another embodiment, the sequences are naturally occurring allelic variants of a protein encoded by a nucleic acid of Figure 2. In another embodiment, the sequences are sequence variants as further described herein.
"High throughput screening" assays for the presence, absence, quantification, or other properties of particular nucleic acids or protein products are well known to those of skill in the art. Similarly, binding assays and reporter gene assays are similarly well known. Thus, e.g., U.S. Patent No. 5,559,410 discloses high throughput screening methods for proteins; U.S. Patent No. 5,585,639 discloses high throughput screening methods for nucleic acid binding (i.e., in arrays); while U.S. Patent Nos. 5,576,220 and 5,541,061 disclose high throughput methods of screening for ligand/antibody binding.
In addition, high throughput sσeening systems are commercially available (see, e.g., Amersham Biosciences, Piscataway, NJ; Zymark Corp., Hopkinton, MA; Air Technical Industries, Mentor, OH; Beckman Instruments, Inc. Fullerton, CA; Precision Systems, Inc., Natick, MA; etc.). These systems typically automate entire procedures, including all sample
and reagent pipetting, liquid dispensing, timed incubations, and final readings of the microplate in detector(s) appropriate for the assay. These configurable systems provide high throughput and rapid start up as well as a high degree of flexibility and customization. The manufacturers of such systems provide detailed protocols for various high throughput systems. Thus, e.g., Zymark Corp. provides technical bulletins describing screening systems for detecting the modulation of gene transcription, ligand binding, and the like.
The term "homolog" refers to a molecule which exhibits homology to another molecule, by for example, having sequences of chemical residues that are the same or similar at corresponding positions.
"Human Leukocyte Antigen" or "HLA" is a human class I or class II Major Histocompatibility Complex (MHC) protein (see, e.g., Stites, ef al., IMMUNOLOGY, 8TH ED., Lange Publishing, Los Altos, CA (1994).
The terms "hybridize", "hybridizing", "hybridizes" and the like, used in the context of polynucleotides, are meant to refer to conventional hybridization conditions, preferably such as hybridization in 50% formamide/6XSSC/0.1 % SDS/100 μg/ml ssDNA, in which temperatures for hybridization are above 37 degrees C and temperatures for washing in 0.1XSSC/0.1 % SDS are above 55 degrees C.
The phrases "isolated" or "biologically pure" refer to material which is substantially or essentially free from components which normally accompany the material as it is found in its native state. Thus, isolated peptides in accordance with the invention preferably do not contain materials normally associated with the peptides in their in situ environment. For example, a polynucleotide is said to be "isolated" when it is substantially separated from contaminant polynucleotides that correspond or are complementary to genes other than the 24P4C12 genes or that encode polypeptides other than 24P4C12 gene product or fragments thereof. A skilled artisan can readily employ nucleic acid isolation procedures to obtain an isolated 24P4C12 polynucleotide. A protein is said to be "isolated," for example, when physical, mechanical or chemical methods are employed to remove the 24P4C12 proteins from cellular constituents that are normally associated with the protein. A skilled artisan can readily employ standard purification methods to obtain an isolated 24P4C12 protein. Altematively, an isolated protein can be prepared by chemical means.
The term "mammal" refers to any organism classified as a mammal, including mice, rats, rabbits, dogs, cats, cows, horses and humans. In one embodiment of the invention, the mammal is a mouse. In another embodiment of the invention, the mammal is a human.
The terms "metastatic prostate cancer" and "metastatic disease" mean prostate cancers that have spread to .regional lymph nodes or to distant sites, and are meant to include stage D disease under the AUA system and stage TxNxM÷ under the TNM system. As is the case with'locally advanced prostate cancer, surgery is generally not indicated for patients with metastatic disease, and hormonal (androgen ablation) therapy is a preferred treatment modality. Patients with metastatic prostate cancer eventually develop an androgen-refractory state within 12 to 18 months of treatment initiation. Approximately half of these androgen-refractory patients die within 6 months after developing that status. The most common site for prostate cancer metastasis is bone. Prostate cancer bone metastases are often osteoblastic rather than osteolytic (i.e., resulting in net bone formation). Bone metastases are found most frequently in the spine, followed by the femur, pelvis, rib cage, skull and humerus. Other common sites for metastasis include lymph nodes, lung, liver and brain. Metastatic • prostate cancer is typically diagnosed by open or laparoscopic pelvic lymphadenectomy, whole body radionuclide scans, skeletal radiography, and/or bone lesion biopsy.
The term "modulator" or "test compound" or "drug candidate" or grammatical equivalents as used herein describe any molecule, e.g., protein, oligopeptide, small organic molecule, polysaccharide, polynucleotide, etc., to be tested for the capacity to directly or indirectly alter the cancer phenotype or the expression of a cancer sequence, e.g., a nucleic acid or protein sequences, or effects of cancer sequences (e.g., signaling, gene expression, protein interaction, etc.) In one aspect, a modulator will neutralize the effect of a cancer protein of the invention. By "neutralize" is meant that an activity of a protein
is inhibited or blocked, along with the consequent effect on the cell. In another aspect, a modulator will neutralize the effect of a gene, and its corresponding protein, of the invention by normalizing levels of said protein. In preferred embodiments, modulators alter expression profiles, or expression profile nucleic acids or proteins provided herein, or downstream effector pathways. In one embodiment, the modulator suppresses a cancer phenotype, e.g. to a normal tissue fingerprint. In another embodiment, a modulator induced a cancer phenotype. Generally, a plurality of assay mixtures is run in parallel with different agent concentrations to obtain a differential response to the various concentrations. Typically, one of these concentrations serves as a negative control, i.e., at zero concentration or below the level of detection.
Modulators, drug candidates or test compounds encompass numerous chemical classes, though typically they are organic molecules, preferably small organic compounds having a molecular weight of more than 100 and less than about 2,500 Daltons. Preferred small molecules are less than 2000, or less than 1500 or less than 1000 or less than 500 D. Candidate agents comprise functional groups necessary for structural interaction with proteins, particularly hydrogen bonding, and typically include at least an amine, carbonyl, hydroxyl or carboxyl group, preferably at least two of the functional chemical groups. The candidate agents often comprise cyclical carbon or heterocyclic structures and/or aromatic or polyaromatic structures substituted with one or more of the above functional groups. Modulators also comprise biomolecules such as peptides, saccharides, fatty acids, steroids, purines, pyrimidines, derivatives, structural analogs or combinations thereof. Particularly preferred are peptides. One class of modulators are peptides, for example of from about five to about 35 amino acids, with from about five to about 20 amino acids being preferred, and from about 7 to about 15 being particularly preferred. Preferably, the cancer modulatory protein is soluble, includes a non-transmembrane region, and/or, has an N- terminal Cys to aid in solubility. In one embodiment, the C-terminus of the fragment is kept as a free acid and the N-terminus is a free amine to aid in coupling, i.e., to cysteine. In one embodiment, a cancer protein of the invention is conjugated to an i munogenic agent as discussed herein. In one embodiment, the cancer protein is conjugated to BSA. The peptides of the invention, e.g., of preferred lengths, can be linked to each other or to other amino acids to create a longer peptide/protein. The modulatory peptides can be digests of naturally occurring proteins as is outlined above, random peptides, or "biased" random peptides. In a preferred embodiment, peptide/protein-based modulators are antibodies, and fragments thereof, as defined herein.
Modulators of cancer can also be nucleic acids. Nucleic acid modulating agents can be naturally occurring nucleic acids, random nucleic acids, or "biased" random nucleic acids. For example, digests of prokaryotic or eukaryotic genomes can be used in an approach analogous to that outlined above for proteins.
The term "monoclonal antibody" refers to an antibody obtained from a population of substantially homogeneous antibodies, i.e., the antibodies comprising the population are identical except for possible naturally occurring mutations that are present in minor amounts.
A "motif, as in biological motif of a 24P4C12-related protein, refers to any pattern of amino acids forming part of the primary sequence of a protein, that is associated with a particular function (e.g. protein-protein interaction, protein-DNA interaction, etc) or modification (e.g. that is phosphorylated, glycosylated or amidated), or localization (e.g. secretory sequence, nuclear localization sequence, etc.) or a sequence that is correlated with being immunogenic, either humorally or cellularly . A motif can be either contiguous or capable of being aligned to certain positions that are generally correlated with a certain function or property. In the context of HLA motifs, "motif" refers to the pattern of residues in a peptide of defined length, usually a peptide of from about 8 to about 13 amino acids for a class I HLA motif and from about 6 to about 25 amino acids for a class II HLA motif, which is recognized by a particular HLA molecule. Peptide motifs for HLA binding are typically different for each protein encoded by each human HLA allele and differ in the pattern of the primary and secondary anchor residues.
A "pharmaceutical excipient" comprises a material such as an adjuvant, a carrier, pH-adjusting and buffering agents, tonicity adjusting agents, wetting agents, preservative, and the like.
"Pharmaceutically acceptable" refers to a non-toxic, inert, and/or composition that is physiologically compatible with humans or other mammals.
The term "polynucleotide" means a polymeric form of nucleotides of at least 10 bases or base pairs in length, either ribonudeotides or deoxynucleotides or a modified form of either type of nucleotide, and is meant to include single and double stranded forms of DNA and/or RNA. In the art, this term if often used interchangeably with "oligonucleotide". A polynucleotide can comprise a nucleotide sequence disclosed herein wherein thymidine (T), as shown for example in Figure 2, can also be uracil (U); this definition pertains to the differences between the chemical structures of DNA and RNA, in particular the observation that one of the four major bases in RNA is uracil (U) instead of thymidine (T).
The term "polypeptide" means a polymer of at least about 4, 5, 6, 7, or 8 amino acids. Throughout the specification, standard three letter or single letter designations for amino acids are used. In the art, this term is often used interchangeably with "peptide" or "protein".
An HLA "primary anchor residue" is an amino add at a specific position along a peptide sequence which is understood to provide a contact point between the immunogenic peptide and the HLA molecule. One to three, usually two, primary anchor residues within a peptide of defined length generally defines a "motif" for an immunogenic peptide. These residues are understood to fit in close contact with peptide binding groove of an HLA molecule, with their side chains buried in specific pockets of the binding groove. In one embodiment, for example, the primary anchor residues for an HLA class I molecule are located at position 2 (from the amino terminal position) and at the carboxyl terminal position of a 8, 9, 10, 11 , or 12 residue peptide epitope in accordance with the invention. Alternatively, in another embodiment, the primary anchor residues of a peptide binds an HLA class II molecule are spaced relative to each other, rather than to the termini of a peptide, where the peptide is generally of at least 9 amino acids in length. The primary anchor positions for each motif and supermotif are set forth in Table IV. For example, analog peptides can be created by altering the presence or absence of particular residues in the primary and/or secondary anchor positions shown in Table IV. Such analogs are used to modulate the binding affinity and/or population coverage of a peptide comprising a particular HLA motif or supermotif.
"Radioisotopes" include, but are not limited to the following (non-limiting exemplary uses are also set forth):
Examples of Medical Isotopes:
Isotope
Description of use
Actinium-225
(AC-225)
See Thorium-229 (Th-229)
Actinium-227
(AC-227)
Parent of Radium-223 (Ra-223) which is an alpha emitter used to treat metastases in the skeleton resulting from cancer (i.e., breast and prostate cancers), and cancer radioimmunotherapy
Bismuth-212
(Bi-212)
See Thorium-228 (Th-228)
Bismuth-213
(Bi-213)
See Thorium-229 (Th-229)
Cadmium-109 (Cd-109) Cancer detection
Cobalt-60
(Co-60)
Radiation source for radiotherapy of cancer, for food irradiators, and for sterilization of medical supplies
Copper-64
(Cu-64)
A positron emitter used for cancer therapy and SPECT imaging
Copper-67
(Cu-67)
Beta/gamma emitter used in cancer radioimmunotherapy and diagnostic studies (i.e., breast and colon cancers, and lymphoma)
Dysprosium-166
(Dy-166)
Cancer radioimmunotherapy
Erbium-169
(Er-169)
Rheumatoid arthritis treatment, particularly for the small joints associated with fingers and toes
Europium-152
(Eu-152)
Radiation source for food irradiation and for sterilization of medical supplies
Europium-154
(Eu-154)
Radiation source for food irradiation and for sterilization of medical supplies
Gadolinium-153
(Gd-153)
Osteoporosis detection and nuclear medical quality assurance devices
Gold-198 (Au-198) Implant and intr acavity therapy of ovarian, prostate, and brain cancers
Holmium-166
(Ho-166)
Multiple myeloma treatment in targeted skeletal therapy, cancer radioimmunotherapy, bone marrow ablation, and rheumatoid arthritis treatment lodine-125
(1-125)
Osteoporosis detection, diagnostic imaging, tracer drugs, brain cancer treatment, radiolabeling, tumor imaging, mapping of receptors in the brain, interstitial radiation therapy, brachytherapy for treatment of prostate cancer, determination of glomemlar filtration rate (GFR), determination of plasma volume, detection of deep vein thrombosis of the legs lodine-131 (1-131) -
Thyroid function evaluation, thyroid disease detection, treatment of thyroid cancer as well as other non- malignant thyroid diseases (i.e., Graves disease, goiters, and hyperthyroidism), treatment of leukemia, lymphoma, and other forms of cancer (e.g., breast cancer) using radioimmunotherapy lridium-192
(lr-192)
Brachytherapy, brain and spinal cord tumor treatment, treatment of blocked arteries (i.e., arteriosderosis and re stenosis), and implants for breast and prostate tumors
Lutefium-177
(Lu-177)
Cancer radioimmunotherapy and treatment of blocked arteries (i.e., arteriosderosis and restenosis)
Molybdenum-99
(Mo-99)
Parent of Technetium-99m (Tc-99m) which is used for imaging the brain, liver, lungs, heart, and other organs.
Currently, Tc-99m is the most widely used radioisotope used for diagnostic imaging of various cancers and diseases involving the brain, heart, liver, lungs; also used in detection of deep vein thrombosis of the legs .
Osmium-194
(Os-194)
Cancer radioimmunotherapy
Palladium-103
(Pd-103)
Prostate cancer treatment
Platinum-195m
(Pt-195m)
Studies on biodistribution and metabolism of cisplatin, a chemotherapeutic drug
Phosphorus-32
(P-32)
Polycythemia rubra vera (blood cell disease) and leukemia treatment, bone cancer diagnosis/treatment; colon, pancreatic, and liver cancer treatment; radiolabeling nucleic acids for in vitro research, diagnosis of superficial tumors, treatment of blocked arteries (i.e., arteriosclerosis and restenosis), and intracavity therapy
Phosphorus-33
(P-33)
Leukemia treatment, bone disease diagnosis/treatment, radiolabeling, and treatment of blocked arteries (i.e., arteriosclerosis and restenosis)
Radium-223
(Ra-223)
See Actinium-227 (Ac-227)
Rhenium-186
(Re-186)
Bone cancer pain relief, rheumatoid arthritis treatment, and diagnosis and treatment of lymphoma and bone, breast, colon, and liver cancers using radioimmunotherapy
Rhenium-188
(Re-188)
Cancer diagnosis and treatment using radioimmunotherapy, bone cancer pain relief, treatment of rheumatoid arthritis, and treatment of prostate cancer
Rhodium-105
(Rh-105)
Cancer radioimmunotherapy
Samarium-145
(Sm-145)
Ocular cancer treatment
Samarium-153
(Sm-153)
Cancer radioimmunotherapy and bone cancer pain relief
Scandium47
(Sc47)
Cancer radioimmunotherapy and bone cancer pain relief
Selenium-75 (Se-75)
Radiotracer used in brain studies, imaging of adrenal cortex by gamma-sdntigraphy, lateral locations of steroid secreting tumors, panσeatic scanning, detection of hyperactive parathyroid glands, measure rate of bile acid loss from the endogenous pool
Strontium-85
(Sr-85)
Bone cancer detection and brain scans
Strontium-89
(Sr-89)
Bone cancer pain relief, multiple myeloma treatment, and osteoblastic therapy
Technetium-99m
(Tc-99m)
See Molybdenum-99 (Mo-99)
Thorium-228
(Th-228)
Parent of Bismuth-212 (Bi-212) which is an alpha emitter used in cancer radioimmunotherapy
Thorium-229
(Th-229)
Parent of Actinium-225 (Ac-225) and grandparent of Bismuth-213 (Bi-213) which are alpha emitters used in cancer radioimmunotherapy
Thulium-170
( Tm-170)
Gamma source for blood irradiators, energy source for implanted medical devices
Tin-117m
(Sn-117m)
Cancer immunotherapy and bone cancer pain relief
Tungsten-188
(W-188)
Parent for Rhenium-188 (Re-188) which is used for cancer diagnostics/treatment, bone cancer pain relief, rheumatoid arthritis treatment, and treatment of blocked arteries (i.e., arteriosclerosis and restenosis)
Xenon-127
(Xe-127)
Neuroimaging of brain disorders, high resolution SPECT studies, pulmonary function tests, and cerebral blood flow studies
Ytterbium-175
(Yb-175)
Cancer radioimmunotherapy
Yttrium-90
(Y-90)
Microseeds obtained from irradiating Yttrium-89 (Y-89) for liver cancer treatment
Yttrium-91
(Y-91)
A gamma-emitting label for Yttrium-90 (Y-90) which is used for cancer radioimmunotherapy (i.e., lymphoma, breast, colon, kidney, lung, ovarian, prostate, panσeatic, and inoperable liver cancers)
By "randomized" or grammatical equivalents as herein applied to nucleic acids and proteins is meant that each nucleic acid and peptide consists of essentially random nucleotides and amino acids, respectively. These random peptides (or nucleic acids, discussed herein) can incorporate any nucleotide or amino acid at any position. The synthetic process can be designed to generate randomized proteins or nucleic acids, to allow the formation of all or most of the possible combinations over the length of the sequence, thus forming a library of randomized candidate bioactive proteinaceous agents.
In one embodiment, a library is "fully randomized," with no sequence preferences or constants at any position. In another embodiment, the library is a "biased random" library. That is, some positions within the sequence either are held constant, or are selected from a limited number of possibilities. For example, the nucleotides or amino acid residues are randomized within a defined class, e.g., of hydrophobic amino acids, hydrophilic residues, sterically biased (either small or large) residues, towards the creation of nucleic acid binding domains, the creation of cysteines, for cross-linking, prolines for SH-3 domains, serines, threonines, tyrosines or histidines for phosphorylation sites, etc., or to purines, etc.
A "recombinant" DNA or RNA molecule is a DNA or RNA molecule that has been subjected to molecular manipulation in vitro.
Non-limiting examples of small molecules include compounds that bind or interact with 24P4C12, ligands including hormones, neuropeptides, chemokines, odorants, phospholipids, and functional equivalents thereof that bind and preferably inhibit 24P4C12 protein function. Such non-limiting small molecules preferably have a molecular weight of less than about 10 kDa, more preferably below about 9, about 8, about 7, about 6, about 5 or about 4 kDa. In certain embodiments, small molecules physically associate with, or bind, 24P4C12 protein; are not found in naturally occurring metabolic pathways; and/or are more soluble in aqueous than non-aqueous solutions
"Stringency" of hybridization reactions is readily determinable by one of ordinary skill in the art, and generally is an empirical calculation dependent upon probe length, washing temperature, and salt concentration. In general, longer probes require higher temperatures for proper annealing, while shorter probes need lower temperatures. Hybridization generally depends on the ability of denatured nucleic acid sequences to reanneal when complementary strands are present in an environment below their melting temperature. The higher the degree of desired homology between the probe and hybridizable sequence, the higher the relative temperature that can be used. As a result, it follows that higher relative temperatures would tend to make the reaction conditions more stringent, while lower temperatures less so. For additional details and explanation of stringency of hybridization reactions, see Ausubel et al., Current Protocols in Molecular Biology, Wiley Interscience Publishers, (1995).
"Stringent conditions" or "high stringency conditions", as defined herein, are identified by, but not limited to, those that: (1) employ low ionic strength and high temperature for washing, for example 0.015 M sodium chloride/0.0015 M sodium citrate/0.1 % sodium dodecyl sulfate at 50°C; (2) employ during hybridization a denaturing agent, such as formamide, for example, 50% (v/v) formamide with 0.1% bovine serum albumin/0.1% Ficoll/0.1% polyvinylpyrrolidone/50 mM sodium phosphate buffer at pH 6.5 with 750 mM sodium chloride, 75 mM sodium citrate at 42 °C; or (3) employ 50% formamide, 5 x SSC (0.75 M NaCl, 0.075 M sodium citrate), 50 mM sodium phosphate (pH 6.8), 0.1% sodium pyrophosphate, 5 x Denhardt's solution, sonicated salmon sperm DNA (50 μg/ml), 0.1% SDS, and 10% dextran sulfate at 42 °C, with washes at 42°C in 0.2 x SSC (sodium chloride/sodium, citrate) and 50% formamide at 55 °C, followed by a high-stringency wash consisting of 0.1 x SSC containing EDTA at 55 °C. "Moderately stringent conditions" are described by, but not limited to, those in Sambrook et al., Molecular Cloning: A Laboratory Manual, New York: Cold Spring Harbor Press, 1989, and indude the use of washing solution and hybridization conditions (e.g., temperature, ionic strength and %SDS) less stringent than those described above. An example of moderately stringent conditions is overnight incubation at 37°C in a solution comprising: 20% formamide, 5 x SSC (150 mM NaCl, 15 mM trisodium citrate), 50 mM sodium phosphate (pH 7.6), 5 x
Denhardt's solution, 10% dextran sulfate, and 20 mg/mL denatured sheared salmon sperm DNA, followed by washing the filters in 1 x SSC at about 37-50°C. The skilled artisan will recognize how to adjust the temperature, ionic strength, etc. as necessary to accommodate factors such as probe length and the like.
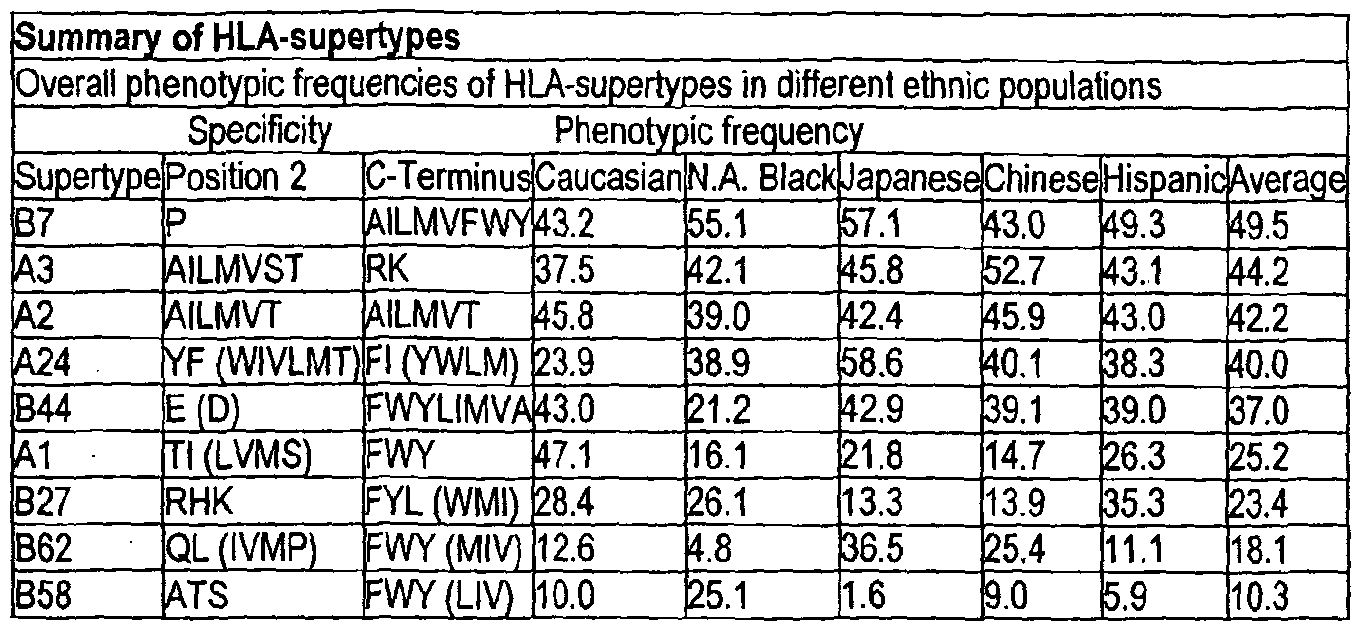
An HLA "supermotif is a peptide binding specificity shared by HLA molecules encoded by two or more HLA alleles. Overall phenotypic frequencies of HLA-supertypes in different ethnic populations are set forth in Table IV (F). The non- limiting constituents of various supetypes are as follows:
A2- A*0201, A*0202, A*0203, A*0204, A* 0205, A*0206, A*6802, A*6901, A*0207
A3: A3, A11, A31, A*3301, A*6801, A*0301, A*1101, A*3101
B7: B7, 6*3501-03, B*51, B*5301, B*5401, B*5501, B*5502, B*5601, B*6701, B*7801, B*0702, B*5101, B*5602
B44: B*3701, B*4402, B*4403, B*60 (B 001), B61 (B 006)
All A*0102, A*2604, A*3601, AM301, A*8001
A24: A*24, A*30, A*2403, A*2404, A*3002, A*3003
B27: B*1401-02, B 503, B*1509, B*1510, B*1518, B*3801-02, B*3901 , B*3902, B*3903-04, B 801-02, B*7301, B*2701-08
B58: B 516, B 517, B*5701, B*5702, B58
B62: B 601. B52. B*1501 (B62), B*1502 (B75), B*1513 (B77) Calculated population coverage afforded by different HLA-supertype combinations are set forth in Table IV (G).
As used herein "to treat" or "therapeutic" and grammatically related terms, refer to any improvement of any consequence of disease, such as prolonged survival, less morbidity, and/or a lessening of side effects which are the byproducts of an alternative therapeutic modality; full eradication of disease is not required.
A "transgenic animal" (e.g., a mouse or rat) is an animal having cells that contain a transgene, which transgene was introduced into the animal or an ancestor of the animal at a prenatal, e.g., an embryonic stage. A "transgene" is a DNA that is integrated into the genome of a cell from which a transgenic animal develops.
As used herein, an HLA or cellular immune response "vaccine" is a composition that contains or encodes one or more peptides of the invention. There are numerous embodiments of such vaccines, such as a cocktail of one or more individual peptides; one or more peptides of the invention comprised by a polyepitopic peptide; or nucleic acids that encode such individual peptides or polypeptides, e.g., a minigene that encodes a polyepitopic peptide. The "one or more peptides" can include any whole unit integer from 1-150 or more, e.g., at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130, 135, 140, 145, or 150 or more peptides of the invention. The peptides or polypeptides can optionally be modified, such as by lipidation, addition of targeting or other sequences. HLA class I peptides of the invention can be admixed with, or linked to, HLA class II peptides, to facilitate activation of both cytotoxic T lymphocytes and helper T lymphocytes. HLA vaccines can also comprise peptide-pulsed antigen presenting cells, e.g., dendritic cells.
The term "varianf refers to a molecule that exhibits a variation from a described type or norm, such as a protein that has one or more different amino add residues in the corresponding position(s) of a specifically described protein (e.g. the 24P4C12 protein shown in Figure 2 or Figure 3. An analog is an example of a variant protein. Splice isoforms and single nudeotides polymorphisms (SNPs) are further examples of variants.
The "24P4C12-related proteins" of the invention indude those specifically identified herein, as well as allelic variants, conservative substitution variants, analogs and ho ologs that can be isolated/generated and characterized without undue experimentation following the methods ouBined herein or readily available in the art Fusion proteins that combine parts of different 24P4C12 proteins or fragments thereof, as well as fusion proteins of a 24P4C12 protein and a heterologous polypeptide
are also induded. Such 24P4C12 proteins are collectively referred to as the 24P4C12-related proteins, the proteins of the invention, or 24P4C12. The term "24P4C12-related protein" refers to a polypeptide fragment or a 24P4C12 protein sequence of 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, or more than 25 amino adds; or, at least 30, 35, 40, 45, 50, 55, 60, 65, 70, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130, 135, 140, 145, 150, 155, 160, 165, 170, 175, 180, 185, 190, 195, 200, 225, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, or 664 or more amino acids.
II.) 24P4C12 Polynucleotides
One aspect of the invention provides polynucleotides corresponding or complementary to all or part of a 24P4C12 gene, mRNA, and/or coding sequence, preferably in isolated form, including polynucleotides encoding a 24P4C12-related protein and fragments thereof, DNA, RNA, DNA/RNA hybrid, and related molecules, polynucleotides or oligonucleotides complementary to a 24P4C12 gene or mRNA sequence or a part thereof, and polynucleotides or oligonucleotides that hybridize to a 24P4C12 gene, mRNA, or to a 24P4C12 encoding polynucleotide (collectively, "24P4C12 polynucleotides"). In all instances when referred to in this section, T can also be U in Figure 2.
Embodiments of a 24P4C12 polynucleotide indude: a 24P4C12 polynucleotide having the sequence shown in Figure 2, the nudeotide sequence of 24P4C12 as shown in Figure 2 wherein T is U; at least 10 contiguous nucleotides of a polynucleotide having the sequence as shown in Figure 2; or, at least 10 contiguous nucleotides of a polynucleotide having the sequence as shown in Figure 2 where T is U. For example, embodiments of 24P4C12 nucleotides comprise, without limitation:
(I) a polynucleotide comprising, consisting essentially of, or consisting of a sequence as shown in Figure 2, wherein T can also be U;
(II) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2A, from nucleotide residue number 6 through nucleotide residue number 2138, induding the stop codon, wherein T can also be U;
(III) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2B, from nucleotide residue number 6 through nucleotide residue number 2138, including the stop codon, wherein T can also be U;
(IV) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2C, from nucleotide residue number 6 through nudeotide residue number 2138, including the a stop codon, wherein T can also be U;
(V) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2D, from nucleotide residue number 6 through nucleotide residue number 2138, including the stop codon, wherein T can also be U;
(VI) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2E, from nucleotide residue number 6 through nucleotide residue number 2138, including the stop codon, wherein T can also be U;
(VII) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2F, from nucleotide residue number 6 through nucleotide residue number 2138, including the stop codon, wherein T can also be U;
(VIII) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2G, from nucleotide residue number 6 through nucleotide residue number 1802, including the stop codon, wherein T can also be U;
(IX) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 2H, from nucleotide residue number 6 through nudeotide residue number 2174, including the stop codon, wherein T can also be U;
(X) a polynucleotide comprising, consisting essentially of, or consisting of the sequence as shown in Figure 21, from nudeotide residue number 6 through nucleotide residue number 2144, including the stop codon, wherein T can also be U;
(XI) a polynucleotide that encodes a 24P4C12-related protein that is at least 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 or 100% homologous to an entire amino acid sequence shown in Figure 2A-I;
(XII) a polynucleotide that encodes a 24P4C12-related protein that is at least 90, 91 , 92, 93, 94, 95, 96, 97, 98, 99 or 100% identical to an entire amino acid sequence shown in Figure 2A-I;
(XIII) a polynudeotide that encodes at least one peptide set forth in Tables VIII-XXI and XXII-XLIX;
(XIV) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino adds of a peptide of Figure 3A-D in any whole number increment up to 710 that includes at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Hydrophilicity profile of Figure 5;
(XV) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3A-D in any whole number increment up to 710 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value less than 0.5 in the Hydropathidty profile of Figure 6;
(XVI) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino adds of a peptide of Figure 3A-D in any whole number increment up to 710 that indudes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino add positions) having a value greater than 0.5 in the Percent Accessible Residues profile of Figure 7;
(XVII) a polynudeotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 5, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino adds of a peptide of Figure 3A-D in any whole number increment up to 710 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino add position(s) having a value greater than 0.5 in the Average Flexibility profile of Figure 8;
(XVIII) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3A-D in any whole number increment up to 710 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Beta-turn profile of Figure 9;
(XIX) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3E in any whole number increment up to 598 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 3, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Hyd ophilicity profile of Figure 5;
(XX) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acids of a peptide of Figure 3E in any whole number increment up to 598 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino add position(s) having a value less than 0.5 in the Hydropathicity profile of Figure 6;
(XXI) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino adds of a peptide of Figure 3E in any whole number iπσement up to 598 that includes 1, 2, 3, , 5, 6, 7, 8, , 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Percent Accessible Residues profile of Figure 7;
(XXII) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3E in any whole number increment up to 598 that indudes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25. 26, 27. 28. 29, 30, 31 , 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Average Flexibility profile of Figure 8;
(XXIII) a polynudeotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3E in any whole number increment up to 598 that indudes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino add position(s) having a value greater than 0.5 in the Beta- turn profile of Figure 9
(XXIV) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3F in any whole number inσement up to 722 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Hydrophilicity profile of Figure 5;
(XXV) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13. 14, 15. 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino adds of a peptide of Figure 3F in any whole number increment up to 722 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value less than 0.5 in the Hydropathicity profile of Figure 6,
(XXVI) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3F in any whole number increment up to 722 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino add position(s) having a value greater than 0.5 in the Percent Accessible Residues profile of Figure 7;
(XXVII) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3F in any whole number increment up to 722 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid positi'on(s) having a value greater than 0.5 in the Average Flexibility profile of Figure 8;
(XXVI II) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acids of a peptide of Figure 3F in any whole number increment up to 722 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Beta- turn profile of Figure 9
(XXIX) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino adds of a peptide of Figure 3G in any whole number increment up to 712 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acid positioπ(s) having a value greater than 0.5 in the Hydrophilicity profile of Figure 5;
(XXX) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3G in any whole number increment up to 712 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acid position(s) having a value less than 0.5 in the Hydropathicity profile of Figure 6;
(XXXI) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a peptide of Figure 3G in any whole number increment up to 712 that indudes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Percent Accessible Residues profile of Figure 7;
(XXXII) a polynudeotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino adds of a peptide of Figure 3G in any whole
number increment up to 712 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 2, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Average Flexibility profile of Figure 8;
(XXXIII) a polynucleotide that encodes a peptide region of at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acids of a peptide of Figure 3G in any whole number increment up to 712 that includes 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Beta- turn profile of Figure 9
(XXXIV) a polynucleotide that is fully complementary to a polynucleotide of any one of (l)-(XXXIH).
(XXXV) a peptide that is encoded by any of (I) to (XXXIII); and
(XXXVI) a composition comprising a polynucleotide of any of (l)-(XXXIV) or peptide of (XXXV) together with a pharmaceutical excipient and/or in a human unit dose form.
(XXXVII) a method of using a polynucleotide of any (l)-( XXXIV) or peptide of (XXXV) or a composition of (XXXVI) in a method to modulate a cell expressing 24P4C12,
(XXXVIII) a method of using a polynucleotide of any (l)-( XXXIV) or peptide of (XXXV) or a composition of (XXXVI) in a method to diagnose, prophylax, prognose, or treat an individual who bears a cell expressing 24P4C12
(XXXIX) a method of using a polynudeotide of any (l)-( XXXIV) or peptide of (XXXV) or a composition of (XXXVI) in a method to diagnose, prophylax, prognose, or treat an individual who bears a cell expressing 24P4C12, said cell from a cancer of a tissue listed in Table I;
(XL) a method of using a polynucleotide of any (l)-(XXXIV) or peptide of (XXXV) or a composition of (XXXVI) in a method to diagnose, prophylax, prognose, or treat a a cancer;
(XLI) a method of using a polynucleotide of any (l)-(XXXIV) or peptide of (XXXV) or a composition of (XXXVI) in a method to diagnose, prophylax, prognose, or treat a a cancer of a tissue listed in Table I; and,
(XLI I) a method of using a polynucleotide of any (l)-(XXXI V) or peptide of (XXXV) or a composition of (XXXVI) in a method to identify or characterize a modulator of a cell expressing 24P4C12.
As used herein, a range is understood to disdose specifically all whole unit positions thereof.
Typical embodiments of the invention disdosed herein indude 24P4C12 polynudeotides that encode specific portions of 24P4C12 mRNA sequences (and those which are complementary to such sequences) such as those that encode the proteins and/or fragments thereof, for example: .
(a) 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130, 135, 140, 145, 150, 155, 160, 165, 170, 175, 180, 185, 190, 195, 200, 225, 250, 275, 300, 325, 350, 375.400.425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 710 or more contiguous amino acids of 24P4C12 variant 1 ; the maximal lengths relevant for other variants are: variant 3, 710 amino adds; variant 5, 710 amino acids, variant 6, 710 amino acids, variant 7, 598 amino acids, variant 8, 722 amino acids, and variant 9, 712 amino acids.
For example, representative embodiments of the invention disclosed herein include: polynucleotides and their encoded peptides themselves encoding about amino acid 1 to about amino acid 10 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 10 to about amino acid 20 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 20 to about amino acid 30 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 30 to about amino acid 40 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 40 to about amino acid 50 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 50 to about amino acid 60 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 60 to about amino acid 70 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 70 to about amino acid 80 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynucleotides encoding about amino acid 80 to about amino acid 90 of the 24P4C12 protein shown in Figure 2 or Figure 3, polynudeotides encoding about amino acid 90 to about amino acid 100 of the 24P4C12 protein shown in Figure 2 or Figure 3, in increments of about 10 amino adds, ending at the carboxyl terminal amino acid set forth in Figure 2 or Figure 3. Accordingly, polynucleotides encoding portions of the amino acid sequence (of about 10 amino acids), of amino acids, 100 through the carboxyl terminal amino acid of the 24P4C12 protein are embodiments of the invention. Wherein it is understood that each particular amino acid position discloses that position plus or minus five amino acid residues.
Polynucleotides encoding relatively long portions of a 24P4C12 protein are also within the scope of the invention. For example, polynudeotides encoding from about amino acid 1 (or 20 or 30 or 40 etc.) to about amino acid 20, (or 30, or 40 or 50 etc.) of the 24P4C12 protein "or variant" shown in Figure 2 or Figure 3 can be generated by a variety of techniques well known in the art. These polynucleotide fragments can include any portion of the 24P4C12 sequence as shown in Figure 2.
Additional illustrative embodiments of the invention disclosed herein include 24P4C12 polynucleotide fragments encoding one or more of the biological motifs contained within a 24P4C12 protein "or varianf sequence, including one or more of the motif-bearing subsequences of a 24P4C12 protein "or varianf set forth in Tables VIII-XXI and XXII-XLIX. In another embodiment, typical polynucleotide fragments of the invention encode one or more of the regions of 24P4C12 protein or variant that exhibit homology to a known molecule. In another embodiment of the invention, typical polynucleotide fragments can encode one or more of the 24P4C12 protein or variant N-glycosylation sites, cAMP and cGMP-dependent protein kinase phosphorylation sites, casein kinase II phosphorylation sites or N-myristoylation site and amidation sites.
Note that to determine the starting position of any peptide set forth in Tables VIII-XXI and Tables XXII to XLIX (collectively HLA Peptide Tables) respective to its parental protein, e.g., variant 1 , variant 2, etc., reference is made to three factors: the particular variant, the length of the peptide in an HLA Peptide Table, and the Search Peptides listed in Table LVII. Generally, a unique Search Peptide is used to obtain HLA peptides for a particular variant. The position of each Search Peptide relative to its respective parent molecule is listed in Table VII. Accordingly, if a Search Peptide begins at position "X", one must add the value "X minus 1 " to each position in Tables VIII-XXI and Tables XXII-IL to obtain the actual position of the HLA peptides in their parental molecule. For example if a particular Search Peptide begins at position 150 of its parental molecule, one must add 150 - 1 , i.e., 149 to each HLA peptide amino acid position to calculate the position of that amino acid in the parent molecule.
II.A.) Uses of 24P4C12 Polynucleotides
II.A.1.) Monitoring of Genetic Abnormalities
The polynudeotides of the preceding paragraphs have a number of different specific uses. The human 24P4C12 gene maps to the chromosomal location set forth in the Example entitled "Chromosomal Mapping of 24P4C12." For example, because the 24P4C12 gene maps to this chromosome, polynudeotides that encode different regions of the 24P4C12 proteins are used to characterize cytogenetic abnormalities of this chromosomal locale, such as abnormalities that are identified as being associated with various cancers. In certain genes, a variety of chromosomal abnormalities including
rearrangements have been identified as frequent cytogenetic abnormalities in a number of different cancers (see e.g. Krajinovic et al, Mutat. Res. 382(34): 81-83 (1998); Johansson etal., Blood 86(10): 3905-3914 (1995) and Finger et al., P.N.A.S. 85(23): 9158-9162 (1988)). Thus, polynucleotides encoding specific regions of the 24P4C12 proteins provide new tools that can be used to delineate, with greater precision than previously possible, cytogenetic abnormalities in the chromosomal region that encodes 24P4C12 that may contribute to the malignant phenotype. In this context, these polynucleotides satisfy a need in the art for expanding the sensitivity of chromosomal screening in order to identify more subtle and less common chromosomal abnormalities (see e.g. Evans etal., Am. J. Obstet. Gynecol 171(4): 1055-1057 (1994)).
Furthermore, as 24P4C12 was shown to be highly expressed in bladder and other cancers, 24P4C12 polynucleotides are used in methods assessing the status of 24P4C12 gene products in normal versus cancerous tissues. Typically, polynucleotides that encode specific regions of the 24P4C12 proteins are used to assess the presence of perturbations (such as deletions, insertions, point mutations, or alterations resulting in a loss of an antigen etc.) in specific regions of the 24P4C12 gene, such as regions containing one or more motifs. Exemplary assays include both RT-PCR assays as well as single-strand conformation polymorphism (SSCP) analysis (see, e.g., Marrogi etal., J, Cutan. Pathol. 26(8): 369-378 (1999), both of which utilize polynucleotides encoding specific regions of a protein to examine these regions within the protein.
II.A.2.) Antisense Embodiments
Other spedfically contemplated nudeic add related embodiments of the invention disdosed herein are genomic DNA cDNAs, ribozymes, and antisense molecules, as well as nudeic acid molecules based on an alternative backbone, or induding alternative bases, whether derived from natural sources or synthesized, and include molecules capable of inhibiting the RNA or protein expression of 24P4C12. For example, antisense molecules can be RNAs or other molecules, including peptide nucleic acids (PNAs) or non-nucleic acid molecules such as phosphorothioate derivatives that spedfically bind DNA or RNA in a base pair-dependent manner. A skilled artisan can readily obtain these classes of nudeic acid molecules using the 24P4C12 polynudeotides and polynudeotide sequences disclosed herein.
Antisense technology entails the administration of exogenous oligonucleotides that bind to a target polynucleotide located within the cells. The term "antisense" refers to the fact that such oligonucleotides are complementary to their intracellular targets, e.g., 24P4C12. See for example, Jack Cohen, Oligodeoxynucleotides, Antisense Inhibitors of Gene Expression, CRC Press, 1989; and Synthesis 1:1-5 (1988). The 24P4C12 antisense oligonucleotides of the present invention include derivatives such as S-oligonucleotides (phosphorothioate derivatives or S-oligos, see, Jack Cohen, supra), which exhibit enhanced cancer cell growth inhibitory action. S-oligos (nucleoside phosphorothioates) are isoelectronic analogs of an oligonucleotide (O-oligo) in which a nonbridging oxygen atom of the phosphate group is replaced by a sulfur atom. The S-oligos of the present invention can be prepared by treatment of the corresponding O-oligos with 3H-1.2- benzodithiol-3-one-1,1-dioxide, which is a sulfur transfer reagent. See, e.g., Iyer, R. P. etal., J. Org. Chem. 55:46934698 (1990); and Iyer. R. P. etal., J. Am. Chem. Soc. 112:1253-1254 (1990). Additional 24P4C12 antisense oligonucleotides of the present invention include morpholino antisense oligonucleotides known in the art (see, e.g., Partridge et al., 1996, Antisense & Nucleic Add Drug Development 6: 169-175).
The 24P4C12 antisense oligonucleotides of the present invention typically can be RNA or DNA that is complementary to and stably hybridizes with the first 1005' codons or last 1003' codons of a 24P4C 12 genomic sequence or the corresponding mRNA. Absolute complementarity is not required, although high degrees of complementarity are preferred. Use of an oligonucleotide complementary to this region allows for the selective hybridization to 24P4C12 mRNA and not to mRNA spedfying other regulatory subunits of protein kinase. In one embodiment, 24P4C12 antisense oligonucleotides of the present invention are 15 to 30-mer fragments of the antisense DNA molecule that have a sequence
that hybridizes to 24P4C12 mRNA. Optionally, 24P4C12 antisense oligonucleotide is a 30-mer oligonudeotide that is complementary to a region in the first 105' codons or last 103' codons of 24P4C12. Alternatively, the antisense molecules are modified to employ ribozymes in the inhibition of 24P4C12 expression, see, e.g., L. A. Couture & D. T. Stinchcomb; Trends Genet 12: 510-515 (1996).
II.A.3.) Primers and Primer Pairs
Further specific embodiments of these nucleotides of the invention include primers and primer pairs, which allow the specific amplification of polynucleotides of the invention or of any specific parts thereof, and probes that selectively or specifically hybridize to nucleic acid molecules of the invention or to any part thereof. Probes can be labeled with a detectable marker, such as, for example, a radioisotope, fluorescent compound, bioluminescent compound, a chemiluminescent compound, metal chelator or enzyme. Such probes and primers are used to detect the presence of a 24P4C12 polynudeotide in a sample and as a means for detecting a cell expressing a 24P4C12 protein.
Examples of such probes include polypeptides comprising all or part of the human 24P4C12 cDNA sequence shown in Figure 2. Examples of primer pairs capable of specifically amplifying 24P4C12 mRNAs are also described in the Examples. As will be understood by the skilled artisan, a great many different primers and probes can be prepared based on the sequences provided herein and used effectively to amplify and/or detect a 24P4C12 mRNA.
The 24P4C12 polynucleotides of the invention are useful for a variety of purposes, including but not limited to their use as probes and primers for the amplification and/or detection of the 24P4C12 gene(s), mRNA(s), or fragments thereof; as reagents for the diagnosis and/or prognosis of prostate cancer and other cancers; as coding sequences capable of directing the expression of 24P4C12 polypeptides; as tools for modulating or inhibiting the expression of the 24P4C12 gene(s) and/or translation of the 24P4C12 transcript(s); and as therapeutic agents.
The present invention indudes the use of any probe as described herein to identify and isolate a 24P4C12 or 24P4C12 related nudeic add sequence from a naturally occurring source, such as humans or other mammals, as well as the isolated nudeic add sequence per se, which would comprise all or most of the sequences found in the probe used. II.A.4.) Isolation of 24P4C12-Encoding Nucleic Acid Molecules
The 24P4C12 cDNA sequences described herein enable the isolation of other polynudeotides encoding 24P4C12 gene product(s), as well as the isolation of polynudeotides encoding 24P4C12 gene product homologs, alternatively spliced isoforms, allelic variants, and mutant forms of a 24P4C12 gene product as well as polynudeotides that encode analogs of 24P4C12-related proteins. Various molecular doning methods that can be employed to isolate lull length cDNAs encoding a 24P4C12 gene are well known (see, for example, Sambrook, J. ef al., Molecular Cloning: A Laboratory Manual, 2d edition, Cold Spring Harbor Press, New York, 1989; Current Protocols in Molecular Biology. Ausubel etal., Eds., Wiley and Sons, 1995). For example, lambda phage doning methodologies can be conveniently employed, using commercially available doning systems (e.g., Lambda ZAP Express, Stratagene). Phage clones containing 24P4C12 gene cDNAs can be identified by probing with a labeled 24P4C12 cDNA or a fragment thereof. For example, in one embodiment, a 24P4C12 cDNA (e.g., Figure 2) or a portion thereof can be synthesized and used as a probe to retrieve overlapping and full-length cDNAs corresponding to a 24P4C12 gene. A 24P4C12 gene itself can be isolated by sσeening genomic DNA libraries, bacterial artificial chromosome libraries (BACs), yeast artificial chromosome libraries (YACs), and the like, with 24P4C12 DNA probes or primers.
II.A.5.) Recombinant Nucleic Acid Molecules and Host-Vector Systems
The invention also provides recombinant DNA or RNA molecules containing a 24P4C12 polynudeotide, a fragment, analog or homologue thereof, induding but not limited to phages, plasmids, phagemids, cosmids, YACs, BACs, as well as various viral and non-viral vectors well known in the art, and cells transformed or transfected with such recombinant DNA or RNA molecules. Methods for generating such molecules are well known (see, for example, Sambrook ef a/. , 1989, supra).
The invention further provides a host-vector system comprising a recombinant DNA molecule containing a 24P4C12 polynudeotide, fragment analog or homologue thereof within a suitable prokaryotic or eukaryotic host cell. Examples of suitable eukaryote host cells include a yeast cell, a plant cell, or an animal cell, such as a mammalian cell or an insect cell (e.g., a baculovirus-infectible cell such as an Sf9 or HighFive cell). Examples of suitable mammalian cells include various prostate cancer cell lines such as DU145 and TsuPrl , other transfectable or transducible prostate cancer cell lines, primary cells (PrEC), as well as a number of mammalian cells routinely used for the expression of recombinant proteins (e.g , COS, CHO, 293, 293T cells). More particularly, a polynucleotide comprising the coding sequence of 24P4C12 or a fragment, analog or homolog thereof can be used to generate 24P4C12 proteins or fragments thereof using any number of host-vector systems routinely used and widely known in the art.
A wide range of host-vector systems suitable for the expression of 24P4C12 proteins or fragments thereof are available, see for example, Sambrook ef al., 1989, supra; Current Protocols in Molecular Biology, 1995, supra). Preferred vectors for mammalian expression include but are not limited to pcDNA 3.1 myc-His-tag (Invitrogen) and the retroviral vector pSRαtkneo (Muller ef al., 1991, MCB 11:1785). Using these expression vectors, 24P4C12 can be expressed in several prostate cancer and non-prostate cell lines, including for example 293, 293T, rat-1 , NIH 3T3 and TsuPrl The host-vector systems of the invention are useful for the production of a 24P4C12 protein or fragment thereof. Such host-vector systems can be employed to study the functional properties of 24P4C12 and 24P4C12 mutations or analogs.
Recombinant human 24P4C12 protein or an analog or homolog or fragment thereof can be produced by mammalian cells transfected with a construct encoding a 24P4C12-related nucleotide. For example, 293T cells can be transfected with an expression plasmid encoding 24P4C12 or fragment, analog or homolog thereof, a 24P4C12-related protein is expressed in the 293T cells, and the recombinant 24P4C12 protein is isolated using standard purification methods (e.g., affinity purification using anti-24P4C12 antibodies). In another embodiment, a 24P4C12 coding sequence is subdoned into the retroviral vector pSRαMSVtkneo and used to infect various mammalian cell lines, such as NIH 3T3, TsuPrl , 293 and rat-1 in order to establish 24P4C12 expressing cell lines. Various other expression systems well known in the art can also be employed. Expression constructs encoding a leader peptide joined in frame to a 24P4C12 coding sequence can be used for the generation of a seσeted form of recombinant 24P4C12 protein.
As discussed herein, redundancy in the genetic code permits variation in 24P4C12 gene sequences. In particular, it is known in the art that specific host species often have specific codon preferences, and thus one can adapt the disclosed sequence as preferred for a desired host. For example, preferred analog codon sequences typically have rare codons (i.e., codons having a usage frequency of less than about 20% in known sequences of the desired host) replaced with higher frequency codons. Codon preferences for a specific species are calculated, for example, by utilizing codon usage tables available on the INTERNET such as at URL dna.affrc.go.jp/~nakamura/codon.html.
Additional sequence modifications are known to enhance protein expression in a cellular host. These include elimination of sequences encoding spurious polyadenylation signals, exon/intron splice site signals, transposon-like repeats, and/or other such well-characterized sequences that are deleterious to gene expression. The GC content of the sequence is adjusted to levels average for a given cellular host, as calculated by reference to known genes expressed in the host cell. Where possible, the sequence is modified to avoid predicted hairpin secondary mRNA structures. Other useful modifications include the addition of a translational initiation consensus sequence at the start of the open reading frame, as described in Kozak, Mol. Cell Biol., 9:5073-5080 (1989). Skilled artisans understand that the general rule that eukaryotic ribosomes initiate translation exclusively at the 5' proximal AUG codon is abrogated only under rare conditions (see, e.g., Kozak PNAS 92(7): 2662-2666, (1995) and Kozak NAR 15(20): 8125-8148 (1987)).
III.) 24P4C12-related Proteins
Another aspect of the present invention provides 24P4C12-related proteins. Spedfic embodiments of 24P4C12 proteins comprise a polypeptide having all or part of the amino acid sequence of human 24P4C12 as shown in Figure 2 or Figure 3. Alternatively, embodiments of 24P4C12 proteins comprise variant, homolog or analog polypeptides that have alterations in the amino acid sequence of 24P4C12 shown in Figure 2 or Figure 3.
Embodiments of a 24P4C12 polypeptide include: a 24P4C12 polypeptide having a sequence shown in Figure 2, a peptide sequence of a 24P4C12 as shown in Figure 2 wherein T is U; at least, 10 contiguous nucleotides of a polypeptide having the sequence as shown in Figure 2; or, at least 10 contiguous peptides of a polypeptide having the sequence as shown in Figure 2 where T is U. For example, embodiments of 24P4C12 peptides comprise, without limitation:
(I) a protein comprising, consisting essentially of, or consisting of an amino add sequence as shown in Figure 2A-I or Figure 3A-G;
(II) a 24P4C12-related protein that is at least 90, 91, 92, 93, 94, 95, 96, 97, 98, 99 or 100% homologous to an entire amino acid sequence shown in Figure 2A-I;
(III) a 24P4C12-related protein that is at least 90, 91 , 92, 93, 94, 95, 96, 97, 98, 99 or 100% identical to an entire amino acid sequence shown in Figure 2A-I or 3A-G;
(IV) a protein that comprises at least one peptide set forth in Tables VIII to XLIX, optionally with a proviso that it is not an entire protein of Figure 2;
(V) a protein that comprises at least one peptide set forth in Tables VIII-XXI, collectively, which peptide is also set forth in Tables XXII to XLIX, collectively, optionally with a proviso that it is not an entire protein of Figure 2;
(VI) a protein that comprises at least two peptides selected from the peptides set forth in Tables VIII-XLIX, optionally with a proviso that it is not an entire protein of Figure 2;
(VII) a protein that comprises at least two peptides selected from the peptides set forth in Tables VIII to XLIX collectively, with a proviso that the protein is not a contiguous sequence from an amino add sequence of Figure 2;
(VIII) a protein that comprises at least one peptide selected from the peptides set forth in Tables VIII-XXI; and at least one peptide selected from the peptides set forth in Tables XXII to XLIX, with a proviso that the protein is not a contiguous sequence from an amino add sequence of Figure 2;
(IX) a polypeptide comprising at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino adds of a protein of Figure 3A, 3B, 3C, 3D, 3E, 3F, or 3G in any whole number increment up to 710, 710, 710, 710, 598, 722, or 712 respectively that indudes at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid positioπ(s) having a value greater than 0.5 in the Hydrophilicity profile of Figure 5;
(X) a polypeptide comprising at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a protein of Figure 3A, 3B, 3C, 3D, 3E, 3F, or 3G in any whole number increment up to 710, 710, 710, 710, 598, 722, or 712 respectively, that indudes at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31.32, 33, 34, 35 amino acid position(s) having a value less than 0.5 in the Hydropathicity profile of Figure 6;
(XI) a polypeptide comprising at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acids of a protein of Figure 3A, 3B, 3C, 3D, 3E, 3F, or 3G in any whole number increment up to 710, 710, 710, 710, 598, 722, or 712 respectively, that indudes at least 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Percent Accessible Residues profile of Figure 7;
(XII) a polypeptide comprising at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35 amino acids of a protein of Figure 3A, 3B, 3C, 3D, 3E, 3F, or 3G in any whole number increment up to 710, 710, 710, 710, 598, 722, or 712 respectively, that includes at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Average Flexibility profile of Figure 8;
(XIII) a polypeptide comprising at least 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acids of a protein of Figure 3A, 3B, 3C, 3D, 3E, 3F, or 3G in any whole number increment up to 710, 710, 710, 710, 598, 722, or 712 respectively, that indudes at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35 amino acid position(s) having a value greater than 0.5 in the Beta-turn profile of Figure 9;
(XIV) a peptide that occurs at least twice in Tables VIII-XXI and XXII to XLIX, collectively;
(XV) a peptide that occurs at least three times in Tables VIII-XXI and XXII to XLIX, collectively;
(XVI) a peptide that occurs at least four times in Tables VIII-XXI and XXII to XLIX, collectively;
(XVII) a peptide that occurs at least five times in Tables VIII-XXI and XXII to XLIX, collectively;
(XVIII) a peptide that occurs at least once in Tables VIII-XXI, and at least once in tables XXII to XLIX;
(XIX) a peptide that occurs at least once in Tables VIII-XXI, and at least twice in tables XXII to XLIX;
(XX) a peptide that occurs at least twice in Tables VIII-XXI, and at least once in tables XXII to XLIX;
(XXI) a peptide that occurs at least twice in Tables VIII-XXI, and at least twice in tables XXII to XLIX;
(XXII) a peptide which comprises one two, three, four, or five of the following characteristics, or an oligonucleotide encoding such peptide: i) a region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino add position having a value equal to or greater than 0.5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Hydrophilicity profile of Figure 5; ii) a region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino add position having a value equal to or less than 0.5, 0.4, 0.3, 0.2, 0.1 , or having a value equal to 0.0, in the Hydropathicity profile of Figure 6; iii) a region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that includes an amino acid position having a value equal to or greater than 0.5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Percent Accessible Residues profile of Figure 7; iv) a region of at least 5 amino acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that indudes an amino add position having a value equal to or greater than 0,5, 0.6, 0.7, 0.8, 0.9, or having a value equal to 1.0, in the Average Flexibility profile of Figure 8; or.
v) a region of at least 5 ammo acids of a particular peptide of Figure 3, in any whole number increment up to the full length of that protein in Figure 3, that indudes an am o acid position having a value equal to or greater than 05, 06, 07, 08 09, or having a value equal to 1 0, in the Beta-turn profile of Figure 9,
(XXIII) a composition comprising a peptide of (l)-(XXH) or an antibody or binding region thereof together with a pharmaceutical excipient and/or in a human unit dose form
(XXIV) a method of using a peptide of (l)-(XXII), or an antibody or binding region thereof or a composition of (XXIII) in a method to modulate a cell expressing 24P4C12,
(XXV) a method of using a peptide of (l)-(XXII) or an antibody or binding region thereof or a composition of (XXIII) in a method to diagnose, prophylax, prognose, or treat an individual who bears a cell expressing 24P4C12
(XXVI) a method of using a peptide of (l)-(XXH) or an antibody or binding region thereof or a composition (XXIII) in a method to diagnose, prophylax prognose, or treat an individual who bears a cell expressing 24P4C12 said cell from a cancer of a tissue listed in Table I,
(XXVII) a method of using a peptide of (l)-(XXII) or an antibody or binding region thereof or a composition of (XXIII) in a method to diagnose, prophylax, prognose, or treat a a cancer,
(XXVIII) a method of using a peptide of (l)-(XXII) or an antibody or binding region thereof or a composition of (XXIII) in a method to diagnose, prophylax, prognose, or treat a a cancer of a tissue listed in Table I, and
(XXIX) a method of using a a peptide of (l)-(XXII) or an antibody or binding region thereof or a composition (XXIII) in a method to identify or characteπze a modulator of a cell expressing 24P4C12
As used herein, a range is understood to specifically disclose all whole unit positions thereof
Typical embodiments of the invention disclosed herein include 24P4C12 polynucleotides that encode specific portions of 24P4C12 mRNA sequences (and those which are complementary to such sequences) such as those that encode the proteins and/or fragments thereof, for example
(a) 4, 5 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120 125, 130, 135, 140, 145, 150, 155, 160, 165, 170, 175, 180, 185, 190. 195, 200, 225, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 710 or more contiguous ammo acids of 24P4C12 vanant 1, the maximal lengths relevant for other variants are vanant 3, 710 ammo acids, variant 5, 710 ammo acids, variant 6, 710, variant 7, 598 ammo acids, variant 8, 722 ammo acids, and vanant 9, 712 ammo acids
In general, naturally occumng allelic vaπants of human 24P4C12 share a high degree of structural identity and homology (e g , 90% or more homdogy) Typically, allelic vaπants of a 24P4C12 protein contain conservative am o aαd substitutions within the 24P4C12 sequences descnbed herein or contain a substitution of an ammo actd from a corresponding position in a homologue of 24P4C12 One dass of 24P4C12 allelic vaπants are proteins that share a high degree of homology with at least a small region of a particular 24P4C12 ammo aαd sequence, but further contain a radical departure from the sequence, such as a non-conservative substitution, truncation, insertion or frame shift In compaπsons of protein sequences, the terms similaπty, identity, and homology each have a distind meaning as appreαated in the field of genetics Moreover, orthology and paralogy can be important concepts descnbmg the relationship of members of a given protein family in one organism to the members of the same family in other organisms
Ammo acid abbreviations are provided in Table II Conservative ammo acid substitutions can frequently be made in a protein without altering either the conformation or the function of the protein Proteins of the invention can compnse 1 , 2, 3, 4, 5, 6, 7, 8, 9, 10 11, 12, 13, 14, 15 conservative substitutions Such changes include substituting any of isoleucine (I), valine (V) and leucine (L) for any other of these hydrophobic ammo acids, aspartic acid (D) for glutamic acid (E) and vice versa glutamine (Q) for asparagine (N) and vice versa, and serine (S) for threonine (T) and vice versa Other substitutions can also be considered conservative, depending on the environment of the particular ammo acid and its role in the three- dimensional structure of the protein For example, glycine (G) and alanine (A) can frequently be interchangeable, as can alanine (A) and valine (V) Methionine (M), which is relatively hydrophobic, can frequently be interchanged with leucine and isoleucine, and sometimes with valine Lysine (K) and arginine (R) are frequently interchangeable in locations in which the significant feature of the am o acid residue is its charge and the differing pK's of these two ammo acid residues are not significant Still other changes can be considered "conservative" in particular environments (see e g Table III herein, pages 13 15 "Biochemistry" 2nd ED Lubert Stryered (Stanford University), Henikoff ef al , PNAS 1992 Vol 89 10915-10919, Lei ef al , J Biol Chem 1995 May 19, 270(20) 11882-6)
Embodiments of the invention disclosed herein include a wide variety of art-accepted variants or analogs of 24P4C12 proteins such as polypeptides having ammo acid insertions, deletions and substitutions 24P4C12 variants can be made using methods known in the art such as site-directed mutagenesis, alanine scanning, and PCR mutagenesis Site- directed mutagenesis (Carter ef al , Nucl Acids Res , 134331 (1986), Zoller ef al , Nucl Acids Res, 106487 (1987)), cassette mutagenesis (Wells ef al , Gene 34315 (1985)), restπction selection mutagenesis (Wells et al , Philos Trans R Soc London SerA, 317415 (1986)) or other known techniques can be performed on the cloned DNA to produce the 24P4C12 variant DNA
Scanning ammo acid analysis can also be employed to identify one or more am o acids along a contiguous sequence that is involved in a specific biological activity such as a protein-protein interaction Among the preferred scanning ammo acids are relatively small, neutral ammo acids Such ammo acids include alanine, glycine, senne, and cysteine Alanine is typically a preferred scanning amino acid among this group because it eliminates the side-chain beyond the beta- carbon and is less likely to alter the mam-chain conformation of the variant Alanine is also typically preferred because it is the most common amino acid Further, it is frequently found in both buried and exposed positions (Creighton, The Proteins, (W H Freeman & Co , N Y ), Chothia J Mol Biol , 150 1 (1976)) If alanine substitution does not yield adequate amounts of vanant, an isosteπc ammo aαd can be used
As defined herein, 24P4C12 variants, analogs or homologs, have the distinguishing attribute of having at least one epitope that is "cross reactive" with a 24P4C12 protein having an am o acid sequence of Figure 3 As used in this sentence, "σoss reactive" means that an antibody or T cell that specifically binds to a 24P4C12 vanant also specifically binds to a 24P4C12 protein having an ammo acid sequence set forth in Figure 3 A polypeptide ceases to be a vanant of a protein shown in Figure 3, when it no longer contains any epitope capable of being recognized by an antibody or T cell that specifically binds to the starting 24P4C12 protein Those skilled in the art understand that antibodies that recognize proteins bind to epitopes of varying size, and a grouping of the order of about four or five ammo acids, contiguous or not, is regarded as a typical number of am o aαds in a minimal epitope See, e g , Nair et al , J Immunol 2000165(12) 6949-6955, Hebbes ef al Mol Immunol (1989) 26(9) 865-73, Schwartz ef al , J Immunol (1985) 135(4) 2598-608
Other classes of 24P4C12-related protein vaπants share 70%, 75%, 80%, 85% or 90% or more similarity with an am o acid sequence of Figure 3, or a fragment thereof Another specific class of 24P4C12 protein vanants or analogs compnses one or more of the 24P4C12 biological motifs descnbed herein or presently known in the art Thus, encompassed by the present invention are analogs of 24P4C12 fragments (nudeic or ammo acid) that have altered functional (e g
immunogenic) properties relative to the starting fragment. It is to be appredated that motifs now or which become part of the art are to be applied to the nucleic or amino acid sequences of Figure 2 or Figure 3.
As discussed herein, embodiments of the claimed invention include polypeptides containing less than the full amino acid sequence of a 24P4C12 protein shown in Figure 2 or Figure 3. For example, representative embodiments of the invention comprise peptides/proteins having any 4, 5, 6, 7, 8, 9, 10, 11 , 12, 13, 14, 15 or more contiguous amino acids of a 24P4C12 protein shown in Figure 2 or Figure 3.
Moreover, representative embodiments of the invention disclosed herein include polypeptides consisting of about amino acid 1 to about amino acid 10 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 10 to about amino acid 20 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 20 to about amino acid 30 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 30 to about amino acid 40 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 40 to about amino acid 50 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 50 to about amino acid 60 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino add 60 to about amino acid 70 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 70 to about amino acid 80 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 80 to about amino acid 90 of a 24P4C12 protein shown in Figure 2 or Figure 3, polypeptides consisting of about amino acid 90 to about amino acid 100 of a 24P4C12 protein shown in Figure 2 or Figure 3, etc. throughout the entirety of a 24P4C12 amino acid sequence. Moreover, polypeptides consisting of about amino acid 1 (or 20 or 30 or 40 etc.) to about amino acid 20, (or 130, or 140 or 150 etc.) of a 24P4C12 protein shown in Figure 2 or Figure 3 are embodiments of the invention. It is to be appreciated that the starting and stopping positions in this paragraph refer to the specified position as well as that position plus or minus 5 residues.
24P4C12-related proteins are generated using standard peptide synthesis technology or using chemical deavage methods well known in the art. Altematively, recombinant methods can be used to generate nudeic add molecules that encode a 24P4C12-related protein. In one embodiment, nudeic add molecules provide a means to generate defined fragments of a 24P4C12 protein (or variants, homologs or analogs thereof).
III.A.l Motif-bearing Protein Embodiments
Additional illustrative embodiments of the invention disclosed herein include 24P4C12 polypeptides comprising the amino acid residues of one or more of the biological motifs contained within a 24P4C12 polypeptide sequence set forth in Figure 2 or Figure 3. Various motifs are known in the art, and a protein can be evaluated for the presence of such motifs by a number of publicly available Internet sites (see, e.g., URL addresses: pfam.wustl.edu/; searchlauncher.bcm.tmc.edu/seq- search/struc-predicthtml; psort.ims.u-tokyo.ac.jp/; cbs.dtu.dk/; ebi.ac.uk/interpro/scan.html; expasy.ch/tools/scnpsitl.html; Epimatrix™and Epimer™, Brown University, brown.edu/Research/TB-HIVJ-ab/epimatri.yepimatiixhtml; and BIMAS, bimas.dcrt.nih.gov/.).
Motif bearing subsequences of all 24P4C12 variant proteins are set forth and identified in Tables VIII-XXI and XXII- XLIX.
Table V sets forth several frequently occurring motifs based on pfam searches (see URL address pfam.wustl.edu/). The columns of Table V list (1) motif name abbreviation, (2) percent identity found amongst the different member of the motif family, (3) motif name or description and (4) most common function; location information is included if the motif is relevant for location.
Polypeptides comprising one or more of the 24P4C12 motifs discussed above are useful in elucidating the specific characteristics of a malignant phenotype in view of the observation that the 24P4C12 motifs discussed above are associated with growth dysregulation and because 24P4C12 is overexpressed in certain cancers (See, e.g., Table I). Casein kinase II,
cAMP and camp-dependent protein kinase, and Protein Kinase C, for example, are enzymes known to be associated with the development of the malignant phenotype (see e.g. Chen ef a/., Lab Invest., 78(2): 165-174 (1998); Gaiddon ef al., Endocrinology 136(10): 43314338 (1995); Hall ef al., Nucleic Acids Research 24(6): 1119-1126 (1996); Peterziel etal., Oncogene 18(46): 6322-6329 (1999) and O'Brian, Oncol. Rep. 5(2): 305-309 (1998)). Moreover, both glycosylation and myristoylation are protein modifications also associated with cancer and cancer progression (see e.g. Dennis ef al., Biochem. Biophys. Ada 1473(1):21-34 (1999); Raju etal., Exp. Cell Res. 235(1): 145-154 (1997)). Amidation is another protein modification also associated with cancer and cancer progression (see e.g. Treston et al., J. Natl. Cancer Inst. Monogr. (13): 169-175 (1992)).
In another embodiment, proteins of the invention comprise one or more of the immunoreactive epitopes identified in accordance with art-accepted methods, such as the peptides set forth in Tables VIII-XXI and XXII-XLIX. CTL epitopes can be determined using specific algorithms to identify peptides within a 24P4C12 protein that are capable of optimally binding to spedfied HLA alleles (e.g., Table IV; Epimatrix™ and Epimer™, Brown University, URL brown.edu/Research/TB- HIV_Lab/epimatrix/epimatrix.htrnl; and BIMAS, URL bimas.dcrtnih.gov/.) Moreover, processes for identifying peptides that have sufficient binding affinity for HLA molecules and which are correlated with being immunogenic epitopes, are well known in the art, and are carried out without undue experimentation. In addition, processes for identifying peptides that are immunogenic epitopes, are well known in the art, and are carried out without undue experimentation either in vitro or in vivo.
Also known in the art are principles for creating analogs of such epitopes in order to modulate immunogenicity. For example, one begins with an epitope that bears a CTL or HTL motif (see, e.g., the HLA Class I and HLA Class II motifs/ supermotifs of Table IV). The epitope is analoged by substituting out an amino acid at one of the specified positions, and replacing it with another amino acid specified for that position. For example, on the basis of residues defined in Table IV, one can substitute out a deleterious residue in favor of any other residue, such as a prefened residue; substitute a less- preferred residue with a preferred residue; or substitute an originally-occurring preferred residue with another preferred residue. Substitutions can occur at primary anchor positions or at other positions in a peptide; see, e.g., Table IV.
A variety of references reflect the art regarding the identification and generation of epitopes in a protein of interest as well as analogs thereof. See, for example, WO 97/33602 to Chesnut etal:, Sette, Immunogenetics 199950(34): 201- 212; Sette ef a/., J. Immunol. 2001 166(2): 1389-1397; Sidney ef al.. Hum. Immunol. 199758(1): 12-20; Kondo ef af., Immunogenetics 199745(4): 249-258; Sidney et al., J. Immunol. 1996 157(8): 3480-90; and Faik ef al. , Nature 351 : 290-6 (1991); Huntef al., Sdence 255:1261-3 (1992); Parker ef af, J. Immunol. 149:3580-7 (1992); Parker ef a/., J. Immunol. 152:163-75 (1994)); Kast ef af., 1994 152(8): 3904-12; Borras-Cuesta et al, Hum. Immunol. 200061(3): 266-278; Alexander et al., J. Immunol. 2000 164(3); 164(3): 1625-1633; Alexander ef al., PMID: 7895164, UI: 95202582; O'Sullivan etal., J. Immunol. 1991 147(8): 2663-2669; Alexander et al., Immunity 1994 1(9): 751-761 and Alexander et al. , Immunol. Res. 1998 18(2): 79-92.
Related embodiments of the invention indude polypeptides comprising combinations of the different motifs set forth in Table VI, and/or, one or more of the predicted CTL epitopes of Tables VIII-XXI and XXII-XLIX, and/or, one or more of the predicted HTL epitopes of Tables XLVI-XLIX, and/or, one or more of the T cell binding motifs known in the art Preferred embodiments contain no insertions, deletions or substitutions either within the motifs or within the intervening sequences of the polypeptides. In addition, embodiments which include a number of either N-terminal and/or C-terminal amino acid residues on either side of these motifs may be desirable (to, for example, include a greater portion of the polypeptide architecture in which the motif is located). Typically, the number of N-terminal and/or C-terminal amino add residues on either side of a motif is between about 1 to about 100 amino acid residues, preferably 5 to about 50 amino add residues.
24P4C12-related proteins are embodied in many forms, preferably in isolated form. A purified 24P4C12 protein molecule will be substantially free of other proteins or molecules that impair the binding of 24P4C12 to antibody, T cell or
other ligand. The nature and degree of isolation and purification will depend on the intended use. Embodiments of a 24P4C12- related proteins include purified 24P4C12-related proteins and functional, soluble 24P4C12-related proteins. In one embodiment, a functional, soluble 24P4C12 protein or fragment thereof retains the ability to be bound by antibody, T cell or other ligand.
The invention also provides 24P4C12 proteins comprising biologically active fragments of a 24P4C12 amino acid sequence shown in Figure 2 or Figure 3. Such proteins exhibit properties of the starting 24P4C12 protein, such as the ability to elicit the generation of antibodies that specifically bind an epitope assodated with the starting 24P4C12 protein; to be bound by such antibodies; to elicit the activation of HTL or CTL; and/or, to be recognized by HTL or CTL that also specifically bind to the starting protein.
24P4C12-related polypeptides that contain particularly interesting structures can be predided and/or identified using various analytical techniques well known in the art, induding, for example, the methods of Chou-Fasman, Gamier-Robson, Kyte- Doolittle, Eisenberg, Karplus-Schultz or Jameson-Wolf analysis, or based on immunogenicity. Fragments that contain such structures are particularly useful in generating subunit-spedfic anti-24P4C12 antibodies σ T cells or in identifying cellular factors that bind to 24P4C12. For example, hydrophilicity profiles can be generated, and immunogenic peptide fragments identified, using the method of Hopp, T.P. and Woods, K.R., 1981 , Proc. Natl. Acad. Sci. U.S.A. 78:3824-3828. Hydropathicity profiles can be generated, and immunogenic peptide fragments identified, using the method of Kyte, J. and Doolittle, R.F., 1982, J. Mol. Biol. 157:105-132. Percent (%) Accessible Residues profiles can be generated, and immunogenic peptide fragments identified, using the method of Janin J., 1979, Nature 277:491492. Average Flexibility profiles can be generated, and immunogenic peptide fragments identified, using the method of Bhaskaran R., Ponnuswamy P.K., 1988, Int. J. Pept. Protein Res. 32:242-255. Beta-turn profiles can be generated, and immunogenic peptide fragments identified, using the method of Deleage, G. , Roux B„ 1987, Protein Engineering 1 :289-294.
CTL epitopes can be determined using specific algorithms to identify peptides within a 24P4C12 protein that are capable of optimally binding to specified HLA alleles (e.g., by using the SYFPEITHI site at World Wide Web URL syfpeithi.bmi- heidelberg.com/; the listings in Table IV(A)-(E); Epimatrix™ and Epimer™, Brown University, URL (brown.edu/Research/TB- HIV_Lab.epima1rix/epimatrix.html); and BIMAS, URL bimas.dcrt.nih.gov/). Illustrating this, peptide epitopes from 24P4C12 that are presented in the context of human MHC Class I molecules, e.g., HLA-A1, A2, A3, A11, A24, B7 and B35 were predicted (see, e.g., Tables VIII-XXI, XXII-XLIX). Specifically, the complete amino acid sequence of the 24P4C12 protein and relevant portions of other variants, i.e., for HLA Class I predictions 9 flanking residues on either side of a point mutation or exon juction, and for HLA Class II predictions 14 flanking residues on either side of a point mutation or exon junction corresponding to that variant, were entered into the HLA Peptide Motif Search algorithm found in the Bioinformatics and Molecular Analysis Section (BIMAS) web site listed above; in addition to the site SYFPEITHI, at URL syfpeithi.bmi- heidelberg.com/.
The HLA peptide motif search algorithm was developed by Dr. Ken Parker based on binding of specific peptide sequences in the groove of HLA Class I molecules, in particular HLA-A2 (see, e.g., Falk ef al., Nature 351: 290-6 (1991); Hunt θf al., Science 255:1261-3 (1992); Parker et al., J. Immunol. 149:3580-7 (1992); Parker ef a/., J. Immunol. 152:163-75 (1994)). This algorithm allows location and ranking of 8-mer, 9-mer, and 10-mer peptides from a complete protein sequence for predicted binding to HLA-A2 as well as numerous other HLA Class I molecules. Many HLA dass I binding peptides are 8-, 9-, 10 or 11-mers. For example, for Class I HLA-A2, the epitopes preferably contain a leudne (L) or methionine (M) at position 2 and a valine (V) or leucine (L) at the C-terminus (see, e.g., Parker et al., J. Immunol. 149:3580-7 (1992)). Selected results of 24P4C12 predicted binding peptides are shown in Tables VIII-XXI and XXII-XLIX herein. In Tables VIII- XXI and XXII-XLVII, selected candidates, 9-mers and 10-mers, for each family member are shown along with their location, the amino add sequence of each spe fic peptide, and an estimated binding score. In Tables XLVI-XLIX, selected
candidates, 15-mers, for each family member are shown along with their location, the ammo acid sequence of each specific peptide and an estimated binding score The binding score corresponds to the estimated half time of dissociation of complexes containing the peptide at 37°C at pH 65 Peptides with the highest binding score are predicted to be the most tightly bound to HLA Class I on the cell surface for the greatest period of time and thus represent the best immunogenic targets for T-cell recognition
Actual binding of peptides to an HLA allele can be evaluated by stabilization of HLA expression on the antigen- processing defective cell line T2 (see e g , Xue ef a/ , Prostate 30 73-8 (1997) and Peshwa ef al , Prostate 36 129-38 (1998)) Immunogenicity of specific peptides can be evaluated in vitro by stimulation of CD8+ cytotoxic T lymphocytes (CTL) in the presence of antigen presenting cells such as dendπtic cells
It is to be appreciated that every epitope predicted by the BIMAS site, Epimer™ and Epimatπx™ sites, or specified by the HLA dass I or dass II motifs available in the art or which become part of the art such as set forth in Table IV (or determined using World Wide Web site URL syfpeithi bmi-heidelberg com/, or BIMAS, bimas dcrt nih gov/) are to be "applied" to a 24P4C12 protein in accordance with the invention As used in this context "applied" means that a 24P4C12 protein is evaluated, e g , visually or by computer-based patterns finding methods, as appreciated by those of skill in the relevant art Every subsequence of a 24P4C12 protein of 8, 9, 10, or 11 am o acid residues that bears an HLA Class I motif, or a subsequence of 9 or more ammo acid residues that bear an HLA Class II motif are within the scope of the invention
III.B.1 Expression of 24P4C12-related Proteins
In an embodiment described in the examples that follow, 24P4C12 can be conveniently expressed in cells (such as 293T cells) transfected with a commercially available expression vector such as a CMV-dπven expression vector encoding 24P4C12 with a C-terminal 6XHιs and MYC tag (pcDNA3 1/mycHIS, Invitrogen or Tag5, GenHunter Corporation, Nashville TN) The Tag5 vector provides an IgGK secretion signal that can be used to facilitate the production of a secreted 24P4C12 protein in transfected cells The secreted HIS-tagged 24P4C12 in the culture media can be purified, e g , using a nickel column using standard techniques
III C.) Modifications of 24P4C12-related Proteins
Modifications of 24P4C12-related proteins such as covalent modifications are included within the scope of this invention One type of covalent modification includes reacting targeted ammo acid residues of a 24P4C12 polypeptide with an organic deπvatizing agent that is capable of reacting with selected side chains or the N- or C- terminal residues of a 24P4C12 protein Another type of covalent modification of a 24P4C12 polypeptide included within the scope of this invention comprises alteπng the native glycosylation pattern of a protein of the invention Another type of covalent modification of 24P4C12 comprises linking a 24P4C12 polypeptide to one of a variety of nonproteinaceous polymers, e g , polyethylene glycol (PEG), polypropylene glycol, or polyoxyalkylenes, in the manner set forth in U S Patent Nos 4,640,835 4,496,689, 4,301,144, 4,670,417, 4,791,192 or 4,179337
The 24P4C12-related proteins of the present invention can also be modified to form a chimenc molecule compnsing 24P4C12 fused to another, heterologous polypeptide or am o aαd sequence Such a chimenc molecule can be synthesized chemically or r ecombinantJy A chimenc molecule can have a protein of the invention fused to another tumor- assoαated antigen or fragment thereof Alternatively, a protein in accordance with the invention can compπse a fusion of fragments of a 24P4C12 sequence (ammo or nucleic aαd) such that a molecule is σeated that is not, through its length, directly homologous to the ammo or nucleic acid sequences shown in Figure 2 or Figure 3 Such a chimenc molecule can comprise multiples of the same subsequence of 24P4C12 A chimenc molecule can comprise a fusion of a 24P4C12-related protein with a polyhistidine epitope tag, which provides an epitope to which immobilized nickel can selectively bind, with
cytokines or with growth factors. The epitope tag is generally placed at the amino- or carboxyl- terminus of a 24P4C12 protein. In an alternative embodiment, the chimeric molecule can comprise a fusion of a 24P4C12-related protein with an immunoglobulin or a particular region of an immunoglobulin. For a bivalent form of the chimeric molecule (also referred to as an "immunoadhesin"), such a fusion could be to the Fc region of an IgG molecule. The Ig fusions preferably include the substitution of a soluble (transmembrane domain deleted or inactivated) form of a 24P4C12 polypeptide in place of at least one variable region within an Ig molecule. In a preferred embodiment, the immunoglobulin fusion includes the hinge, CH2 and CH3, or the hinge, CH I, CH2 and CH3 regions of an IgGI molecule. For the production of immunoglobulin fusions see, e.g., U.S. Patent No. 5,428,130 issued June 27, 1995.
III.D.) Uses of 24P4C12-related Proteins
The proteins of the invention have a number of different specific uses. As 24P4C12 is highly expressed in prostate and other cancers, 24P4C12-related proteins are used in methods that assess the status of 24P4C12 gene products in normal versus cancerous tissues, thereby elucidating the malignant phenotype. Typically, polypeptides from specific regions of a 24P4C12 protein are used to assess the presence of perturbations (such as deletions, insertions, point mutations etc.) in those regions (such as regions containing one or more motifs). Exemplary assays utilize antibodies or T cells targeting 24P4C12-related proteins comprising the amino acid residues of one or more of the biological motifs contained within a 24P4C12 polypeptide sequence in order to evaluate the characteristics of this region in normal versus cancerous tissues or to elicit an immune response to the epitope. Alternatively, 24P4C12-related proteins that contain the amino acid residues of one or more of the biological motifs in a 24P4C12 protein are used to screen for factors that interact with that region of 24P4C12.
24P4C12 protein fragments/subsequences are particularly useful in generating and characterizing domain-specific antibodies (e.g., antibodies recognizing an exfracellular or intracellular epitope of a 24P4C12 protein), for identifying agents or cellular fadors that bind to 24P4C12 or a particular structural domain thereof, and in various therapeutic and diagnostic contexts, induding but not limited to diagnostic assays, cancer vacdnes and methods of preparing such vaccines.
Proteins encoded by the 24P4C12 genes, or by analogs, homologs or fragments thereof, have a variety of uses, including but not limited to generating antibodies and in methods for identifying ligands and other agents and cellular constituents that bind to a 24P4C12 gene product Antibodies raised against a 24P4C12 protein or fragment thereof are useful in diagnostic and prognostic assays, and imaging methodologies in the management of human cancers characterized by expression of 24P4C12 protein, such as those listed in Table I. Such antibodies can be expressed intracellularly and used in methods of treating patients with such cancers. 24P4C12-related nudeic acids or proteins are also used in generating HTL or CTL responses.
Various immunological assays useful for the detection of 24P4C12 proteins are used, induding but not limited to various types of radioimmunoassays, enzyme-linked immunosorbent assays (ELISA), enzyme-linked immunofluorescent assays (EL1FA), immunocytochemical methods, and the like. Antibodies can be labeled and used as immunological imaging reagents capable of detecting 24P4C12-expressing cells (e.g., in radiosdntigraphic imaging melhods). 24P4C12 proteins are also particularly useful in generating cancer vacdnes, as further described herein.
IV.) 24P4C12 Antibodies
Another aspect of the invention provides antibodies that bind to 24P4C12-related proteins. Preferred antibodies spedfically bind to a 24P4C12-related protein and do not bind (or bind weakly) to peptides or proteins that are not 24P4C12- related proteins. For example, antibodies that bind 24P4C12 can bind 24P4C12-related proteins such as Ihe homologs or analogs thereof.
24P4C12 antibodies of the invention are particularly useful in cancer (see, e.g., Table I) diagnostic and prognostic assays, and imaging methodologies. Similarly, such antibodies are useful in the treatment, diagnosis, and/or prognosis of other cancers, to the extent 24P4C12 is also expressed or overexpressed in these other cancers. Moreover, intracellularly expressed antibodies (e.g., single chain antibodies) are therapeutically useful in treating cancers in which the expression of 24P4C12 is involved, such as advanced or metastatic prostate cancers.
The invention also provides various immunological assays useful for the detection and quantification of 24P4C12 and mutant 24P4C12-related proteins. Such assays can comprise one or more 24P4C12 antibodies capable of recognizing and binding a 24P4C12-related protein, as appropriate. These assays are performed within various immunological assay formats well known in the art, induding but not limited to various types of radioimmunoassays, enzyme-linked immunosorbent assays (ELISA), enzyme-linked immunofiuor escent assays (ELIFA), and the like.
Immunological non-antibody assays of the invention also comprise T cell immunogenicity assays (inhibitory or stimulatory) as well as major histocompatibility complex (MHC) binding assays.
In addition, immunological imaging methods capable of detecting prostate cancer and other cancers expressing 24P4C12 are also provided by the invention, induding but not limited to radiosdntigraphic imaging methods using labeled 24P4C12 antibodies. Such assays are dinically useful in the detection, monitoring, and prognosis of 24P4C12 expressing cancers such as prostate cancer.
24P4C12 antibodies are also used in methods for purifying a 24P4C12-related protein and for isolating 24P4C12 homologues and related molecules. For example, a method of purifying a 24P4C12-related protein comprises incubating a 24P4C12 antibody, which has been coupled to a solid matrix, with a lysate or other solution containing a 24P4C12-related protein under conditions that permit the 24P4C12 antibody to bind to the 24P4C12-related protein; washing the solid matrix to eliminate impurities; and eluting the 24P4C12-related protein from the coupled antibody. Other uses of 24P4C12 antibodies in accordance with the invention include generating anti-idiotypic antibodies that mimic a 24P4C12 protein.
Various methods for the preparation of antibodies are well known in the art. For example, antibodies can be prepared by immunizing a suitable mammalian host using a 24P4C12-related protein, peptide, or fragment, in isolated or immunoconjugated form (Antibodies: A Laboratory Manual, CSH Press, Eds., Harlow, and Lane (1988); Harlow, Antibodies, Cold Spring Harbor Press, NY (1989)). In addition, fusion proteins of 24P4C12 can also be used, such as a 24P4C12 GST-fusion protein . In a particular embodiment, a GST fusion protein comprising all or most of the amino add sequence of Figure 2 or Figure 3 is produced, then used as an immunogen to generate appropriate antibodies. In another embodiment, a 24P4C12-related protein is synthesized and used as an immunogen.
In addition, naked DNA immunization techniques known in the art are used (with OT without purified 24P4C12-related protein or 24P4C12 expressing cells) to generate an immune response to the encoded immunogen (for review, see Donnelly ef al., 1997, Ann. Rev. Immunol. 15: 617-648).
The amino acid sequence of a 24P4C12 protein as shown in Figure 2 or Figure 3 can be analyzed to select specific regions of the 24P4C12 protein for generating antibodies. For example, hydrophobidty and hydrophilidty analyses of a 24P4C12 amino add sequence are used to identify hydrophilic regions in the 24P4C12 structure. Regions of a 24P4C12 protein that show immunogenic structure, as well as other regions and domains, can readily be identified using various other methods known in the art, such as Chou-Fasman, Gamier-Robson, Kyte-Doolittle, Eisenberg, Kaφlus-Schultz or Jameson-Wolf analysis. Hydrophilidty profiles can be generated using the method of Hopp, T.P. and Woods, K.R., 1981, Proc. Natl. Acad. Sci. U.S.A. 78:3824- 3828. Hydropathicity profiles can be generated using the method of Kyte, J. and Doolittle, R.F., 1982, J. Mol. Biol. 157:105- 132. Percent (%) Accessible Residues profiles can be generated using the method of Janin J., 1979, Nature 277:491 92. Average Flexibility profiles can be generated using the method of Bhaskaran R„ Ponnuswamy P.K., 1988, Int. J. Pept. Protein Res.32:242-255. Beta-turn profiles can be generated using the method of Deleage, G., Roux B., 1987, Protein
Engineering 1 :289-294. Thus, each region identified by any of these programs or methods is within the scope of the present invention. Methods for the generation of 24P4C12 antibodies are further illustrated by way of the examples provided herein. Methods for preparing a protein or polypeptide for use as an immunogen are well known in the art. Also well known in the art are methods for preparing immunogenic conjugates of a protein with a carrier, such as BSA, KLH or other carrier protein. In some circumstances, direct conjugation using, for example, carbodiimide reagents are used; in other instances linking reagents such as those supplied by Pierce Chemical Co., Rockford, IL, are effective. Administration of a 24P4C12 immunogen is often conducted by injection over a suitable time period and with use of a suitable adjuvant, as is understood in the art. During the immunization schedule, titers of antibodies can be taken to determine adequacy of antibody formation.
24P4C12 monodonal antibodies can be produced by various means well known in the art. For example, immortalized cell lines that seσete a desired monodonal antibody are prepared using the standard hybridoma technology of Kohler and Milstein or modifications that immortalize antibody-producing B cells, as is generally known. Immortalized cell lines that seσete the desired antibodies are sσeened by immunoassay in which the antigen is a 24P4C12-related protein. When the appropriate immortalized cell culture is identified, the cells can be expanded and antibodies produced either from in vitro cultures or from asdtes fluid.
The antibodies or fragments of the invention can also be produced, by recombinant means. Regions that bind spedfically to the desired regions of a 24P4C12 protein can also be produced in the context of chimeric or complementarity- determining region (CDR) grafted antibodies of multiple species origin. Humanized or human 24P4C12 antibodies can also be produced, and are preferred for use in therapeutic contexts. Methods for humanizing murine and other non-human antibodies, by substituting one or more of the non-human antibody CDRs for corresponding human antibody sequences, are well known (see for example, Jones ef al., 1986, Nature 321: 522-525; Riechmann etal., 1988, Nature 332: 323-327; Verhoeyen etal., 1988, Science 239: 1534-1536). See also, Carter ef al., 1993, Proc. Natl. Acad. Sd. USA 89: 4285 and Sims et al., 1993, J. Immunol. 151: 2296.
Methods for produdng fully human monoclonal antibodies indude phage display and transgenic methods (for review, see Vaughan etal., 1998, Nature Biotechnology 16: 535-539). Fully human 24P4C12 monodonal antibodies can be generated using doning technologies employing large human Ig gene combinatorial libraries (i.e., phage display) (Griffiths and Hoogenboom, Building an in vitro immune system: human antibodies from phage display libraries. In: Protein Engineering of Antibody Molecules for Prophylactic and Therapeutic Applications in Man, Clark, M. (Ed.), Nottingham Academic, pp 45-64 (1993); Burton and Barbas, Human Antibodies from combinatorial libraries. Jd., pp 65-82). Fully human 24P4C12 monoclonal antibodies can also be produced using transgenic mice engineered to contain human immunoglobulin gene lo as described in PCT Patent Application W098/24893, Kucherlapati and Jakobovits etal., published December 3, 1997 (see also, Jakobovits, 1998, Exp. Opin. Invest Drugs 7(4): 607-614; U.S. patents 6,162,963 issued 19 December 2000; 6,150,584 issued 12 November 2000; and, 6,114598 issued 5 September 2000). This method avoids the in vitro manipulation required with phage display technology and efficiently produces high affinity authentic human antibodies.
Reactivity of 24P4C12 antibodies with a 24P4C12-related protein can be established by a number of well known means, including Western blot, immunoprecipitation, ELISA, and FACS analyses using, as appropriate, 24P4C12-related proteins, 24P4C12-expressing cells or extracts thereof. A 24P4C12 antibody or fragment thereof can be labeled with a detectable marker or conjugated to a second molecule. Suitable detectable markers include, but are not limited to, a radioisotope, a fluorescent compound, a biolu inescent compound, chemiluminescent compound, a metal chelator or an enzyme. Further, bi-specific antibodies specific for two or more 24P4C12 epitopes are generated using methods generally known in the art. Homodimeric antibodies can also be generated by cross-linking techniques known in the art (e.g., Wolff ef al., Cancer Res. 53: 2560-2565).
V.) 24P4C12 Cellular Immune Responses
The mechanism by which T cells recognize antigens has been delineated. Efficacious peptide epitope vacdne compositions of the invention induce a therapeutic or prophylactic immune responses in very broad segments of the worldwide population. For an understanding of the value and efficacy of compositions of the invention that induce cellular immune responses, a brief review of immunology-related technology is provided.
A complex of an HLA molecule and a peptidic antigen acts as the ligand recognized by HLA-restricted T cells (Buus, S. ef al., Cell 47:1071, 1986; Babbitt, B. P. ef al., Nature 317:359, 1985; Townsend, A. and Bodmer, H„ Annu. Rev. Immunol. 7:601, 1989; Germain, R. N., Annu. Rev. Immunol. 11:403, 1993). Through the study of single amino acid substituted antigen analogs and the sequencing of endogenously bound, naturally processed peptides, critical residues that correspond to motifs required for specific binding to HLA antigen molecules have been identified and are set forth in Table IV (see also, e.g., Southwood, ef al., J. Immunol. 160:3363, 998; Rammeπsee, et al, Immunogenetics 41:178, 1995; Rammensee ef al., SYFPEITHI, access via World Wide Web at URL (134.2.96.221/scripts.hlaserver.dll/home.htm); Sette, A. and Sidney, J. Curr. Opin. Immunol. 10:478, 1998; Engelhard, V. H., Curr. Opin. Immunol.6:13, 1994; Sette, A. and Grey, H. M., Curr. Opin. Immunol. 4:79, 1992; Sinigaglia, F. and Hammer, J. Curr. Biol. 6:52, 1994; Ruppert ef al., Cell 74:929-937, 1993; Kondo etal., J. Immunol. 155:43074312, 1995; Sidney et al., J. Immunol. 157:3480-3490, 1996; Sidney ef a/., Human Immunol. 45:79-93, 1996; Sette, A. and Sidney, J. /mmunogenef/cs 1999 Nov; 50(3-4):201-12, Review).
Furthermore, x-ray crystallographic analyses of HLA-peptide complexes have revealed pockets within the peptide binding cleft/groove of HLA molecules which accommodate, in an allele-specific mode, residues borne by peptide ligands; these residues in turn determine the HLA binding capacity of the peptides in which they are present. (See, e.g., Madden, D.R. Annu. Rev. Immunol. 13:587, 1995; Smith, etal., Immunity 4:203, 1996; Fremont et al., Immunity 8:305, 1998; Stern ef al., Structure 2:245, 1994; Jones, E.Y. Curr. Opin. Immunol. 9:75, 1997; Brown, J. H. etal., Nature 364:33, 1993; Guo, H. C. ef al., Proc. Natl. Acad. Sci. USA 90:8053, 1993; Guo, H. C. ef al., Nature 360:364, 1992; Silver, M. L ef a/., Nature 360:367, 1992; Matsumura, M. ef al., Science 257:927, 1992; Madden ef al., Cell 70:1035, 1992; Fremont, D. H. etal., Science 257:919, 1992; Saper, M. A. , Bjorkman, P. J. and Wiley, D. C, J. Mol. Biol. 219:277, 1991.)
Accordingly, the definition of class I and dass II allele-specific HLA binding motifs, or class I or class II supermofjfs allows identification of regions within a protein that are correlated with binding to particular HLA antigen(s).
Thus, by a process of HLA motif identification, candidates for epitope-based vaccines have been identified; such candidates can be further evaluated by HLA-peptide binding assays to determine binding affinity and/or the time period of association of the epitope and its corresponding HLA molecule. Additional confirmatory work can be performed to select, amongst these vaccine candidates, epitopes with preferred characteristics in terms of population coverage, and/or immunogenicity.
Various strategies can be utilized to evaluate cellular immunogenicity, induding:
1) Evaluation of primary T cell cultures from normal individuals (see, e.g., Wentworth, P. A. ef a/., Mol. Immunol. 32:603, 1995; Celis, E. etal., Proc. Natl. Acad. Sci. USA 91:2105, 1994; Tsai, V. etal., J. Immunol. 158:1796, 1997; Kawashima, I. ef al., Human Immunol. 59:1, 1998). This procedure involves the stimulation of peripheral blood lymphocytes (PBL) from normal subjects with a test peptide in the presence of antigen presenting cells in vitro over a period of several weeks. T cells specific for the peptide become activated during this time and are detected using, e.g., a lymphokine- or
51Cr-release assay involving peptide sensitized target cells,
2) Immunization of HLA transgenic mice (see, e.g., Wentworth, P. A. ef a/., J. Immunol. 26:97, 1996; Wentworth, P. A. etal., Int. Immunol. 8:651, 1996; Alexander, J. ef al., J. Immunol. 159:4753, 1997). For example, in such methods peptides in incomplete Freund's adjuvant are administered subcutaneously to HLA transgenic mice. Several weeks following immunization, splenocytes are removed and cultured in vitro in the presence of test peptide for approximately one week.
Peptide-specific T cells are detected using, e.g., a ^Cr-release assay involving peptide sensitized target cells and target cells expressing endogenously generated antigen.
3) Demonstration of recall T cell responses from immune individuals who have been either effectively vaccinated and/or from chronically ill patients (see, e.g., Rehermann, B. ef al, J. Exp. Med. 181:1047, 1995; Doolan, D. L. etal., Immunity 7:97, 1997; Bertoni, R. ef al, J. Clin. Invest. 100:503, 1997; Threlkeld, S. C. et al, J. Immunol. 159:1648, 1997; Diepolder, H. M. et al., J. Virol. 71:6011, 1997). Accordingly, recall responses are detected by culturing PBL from subjects that have been exposed to the antigen due to disease and thus have generated an immune response "naturally", or from patients who were vaccinated against the antigen. PBL from subjects are cultured in vitro for 1-2 weeks in the presence of test peptide plus antigen presenting cells (APC) to allow activation of "memory" T cells, as compared to "naive" T cells. At the end of the culture period, T cell activity is detected using assays including ^Cr release involving peptide-seπsitized targets, T cell proliferation, or lymphokine release.
VI.) 24P4C12 Transgenic Animals
Nucleic acids that encode a 24P4C12-related protein can also be used to generate either transgenic animals or "knock out" animals that, in turn, are useful in the development and screening of therapeutically useful reagents. In accordance with established techniques, cDNA encoding 24P4C12 can be used to clone genomic DNA that encodes 24P4C12. The cloned genomic sequences can then be used to generate transgenic animals containing cells that express DNA that encode 24P4C12. Methods for generating transgenic animals, particularly animals such as mice or rats, have become conventional in the art and are described, for example, in U.S. Patent Nos.4,736,866 issued 12 April 1988, and 4,870,009 issued 26 September 1989. Typically, particular cells would be targeted for 24P4C12 transgene incorporation with tissue-specific enhancers.
Transgenic animals that include a copy of a transgene encoding 24P4C12 can be used to examine the effect of increased expression of DNA that encodes 24P4C12. Such animals can be used as tester animals for reagents thought to confer protection from, for example, pathological conditions associated with its overexpression. In accordance with this aspect of the invention, an animal is treated with a reagent and a reduced incidence of a pathological condition, compared to untreated animals that bear the transgene, would indicate a potential therapeutic intervention for the pathological condition.
Alternatively, non-human homologues of 24P4C12 can be used to construct a 24P4C12 "knock out" animal that has a defective or altered gene encoding 24P4C12 as a result of homologous recombination between the endogenous gene encoding 24P4C12 and altered genomic DNA encoding 24P4C12 introduced into an embryonic cell of the animal. For example, cDNA that encodes 24P4C12 can be used to clone genomic DNA encoding 24P4C12 in accordance with established techniques. A portion of the genomic DNA encoding 24P4C12 can be deleted or replaced with another gene, such as a gene encoding a selectable marker that can be used to monitor integration. Typically, several kilobases of unaltered flanking DNA (both at the 5' and 3' ends) are included in the vector (see, e.g., Thomas and Capecchi, CeH, 51:503 (1987) for a description of homologous recombination vectors). The vector is introduced into an embryonic stem cell line (e.g., by electroporation) and cells in which the introduced DNA has homologously recombined with the endogenous DNA are selected (see, e.g., Li et al, CeH, 69:915 (1992)). The selected cells are then injected into a blastocyst of an animal (e.g., a mouse or rat) to form aggregation chimeras (see, e.g., Bradley, in Teratocarcinomas and Embryonic Stem Cells: A Practical Approach, E. J. Robertson, ed. (IRL, Oxford, 1987), pp. 113-152). A chimeric embryo can then be implanted into a suitable pseudopregnant female foster animal, and the embryo brought to term to σeate a "knock out" animal. Progeny harboring the homologously recombined DNA in their germ cells can be identified by standard techniques and used to breed animals in which all cells of the animal contain the homologously recombined DNA. Knock out animals can be characterized,
for example, for their ability to defend against certain pathological conditions or for their development of pathological conditions due to absence of a 24P4C12 polypeptide.
VII.) Methods for the Detection of 24P4C12
Another asped of the present invention relates to methods for detecting 24P4C12 polynudeotides and 24P4C12- related proteins, as well as methods for identifying a cell that expresses 24P4C12. The expression profile of 24P4C12 makes it a diagnostic marker for metastasized disease. Accordingly, the status of 24P4C12 gene products provides information useful for predicting a variety of factors induding susceptibility to advanced stage disease, rate of progression, and/or tumor aggressiveness. As discussed in detail herein, the status of 24P4C12 gene products in patient samples can be analyzed by a variety protocols that are well known in the art including immunohistochemical analysis, the variety of Northern blotting techniques induding in situ hybridization, RT-PCR analysis (for example on laser capture iσo-disseded samples), Western blot analysis and tissue array analysis.
More particularly, the invention provides assays for the detection of 24P4C12 polynudeotides in a biological sample, such as serum, bone, prostate, and other tissues, urine, semen, cell preparations, and the like. Detectable 24P4C12 polynucleotides indude, for example, a 24P4C12 gene or fragment thereof, 24P4C12 mRNA, alternative splice variant 24P4C12 mRNAs, and recombinant DNA or RNA molecules that contain a 24P4C12 polynucleotide. A number of methods for amplifying and/or detecting the presence of 24P4C12 polynudeotides are well known in the art and can be employed in the practice of this aspect of the invention.
In one embodiment, a method for detecting a 24P4C12 mRNA in a biological sample comprises producing cDNA from the sample by reverse transcription using at least one primer; amplifying the cDNA so produced using a 24P4C12 polynucleotides as sense and antisense primers to amplify 24P4C12 cDNAs therein; and detecting the presence of the amplified 24P4C12 cDNA. Optionally, the sequence of the amplified 24P4C12 cDNA can be determined.
In another embodiment, a method of detecting a 24P4C12 gene in a biological sample comprises first isolating genomic DNA from the sample; amplifying the isolated genomic DNA using 24P4C12 polynudeotides as sense and antisense primers; and detecting the presence of the amplified 24P4C12 gene. Any number of appropriate sense and antisense probe combinations can be designed from a 24P4C12 nucleotide sequence (see, e.g., Figure 2) and used for this purpose.
The invention also provides assays for detecting the presence of a 24P4C12 protein in a tissue or other biological sample such as serum, semen, bone, prostate, urine, cell preparations, and the like. Methods for detecting a 24P4C12-related protein are also well known and indude, for example, immunopredpitation, immunohistochemical analysis, Western blot analysis, molecular binding assays, ELISA, ELIFA and the like. For example, a method of detecting the presence of a 24P4C12-related protein in a biological sample comprises first contacting the sample with a 24P4C12 antibody, a 24P4C12-reactive fragment thereof, or a recombinant protein containing an antigen-binding region of a 24P4C12 antibody; and then detecting the binding of 24P4C12-related protein in the sample.
Methods for identifying a cell that expresses 24P4C12 are also within the scope of the invention. In one embodiment, an assay for identifying a cell that expresses a 24P4C12 gene comprises detecting the presence of 24P4C12 mRNA in the cell. Methods for the detection of particular mRNAs in cells are well known and indude, for example, hybridization assays using complementary DNA probes (such as in situ hybridization using labeled 24P4C12 riboprobes, Northern blot and related techniques) and various nudeic add amplification assays (such as RT-PCR using complementary primers specific for 24P4C12, and other amplification type detection methods, such as, for example, branched DNA, SISBA, TMA and the like). Alternatively, an assay for identifying a cell that expresses a 24P4C12 gene comprises detecting the presence of 24P4C12-related protein in the
cell or seσeted by the cell. Various methods for the detection of proteins are well known in the art and are employed for the detection of 24P4C12-related proteins and cells that express 24P4C12-related proteins.
24P4C12 expression analysis is also useful as a tool for identifying and evaluating agents that modulate 24P4C12 gene expression. For example, 24P4C12 expression is significantly upregulated in prostate cancer, and is expressed in cancers of the tissues listed in Table I. Identification of a molecule or biological agent that inhibits 24P4C12 expression or over- expression in cancer cells is of therapeutic value. For example, such an agent can be identified by using a screen that quantifies 24P4C12 expression by RT-PCR, nucleic acid hybridization or antibody binding.
VIII.) Methods for Monitoring the Status of 24P4C12-related Genes and Their Products
Oncogenesis is known to be a multistep process where cellular growth becomes progressively dysregulated and cells progress from a normal physiological state to precancerous and then cancerous states (see, e.g., Alers ef al., Lab Invest.77(5): 437-438 (1997) and Isaacs ef al, Cancer Surv. 23: 19-32 (1995)). In this context, examining a biological sample for evidence of dysregulated cell growth (such as aberrant 24P4C12 expression in cancers) allows for early detection of such aberrant physiology, before a pathologic state such as cancer has progressed to a stage that therapeutic options are more limited and or the prognosis is worse. In such examinations, the status of 24P4C12 in a biological sample of interest can be compared, for example, to the status of 24P4C12 in a corresponding normal sample (e.g. a sample from that individual or alternatively another individual that is not affected by a pathology). An alteration in the status of 24P4C12 in the biological sample (as compared to the normal sample) provides evidence of dysregulated cellular growth. In addition to using a biological sample that is not affected by a pathology as a normal sample, one can also use a predetermined normative value such as a predetermined normal level of mRNA expression (see, e.g., Grever et al., J. Comp. Neurol. 1996 Dec 9; 376(2): 306-14 and U.S. Patent No.5,837,501) to compare 24P4C12 status in a sample.
The term "status" in this context is used according to its art accepted meaning and refers to the condition or state of a gene and its produds. Typically, skilled artisans use a number of parameters to evaluate the condition or state of a gene and its products. These indude, but are not limited to the location of expressed gene products (induding the location of 24P4C12 expressing cells) as well as the level, and biological activity of expressed gene products (such as 24P4C12 mRNA, polynucleotides and polypeptides). Typically, an alteration in the status of 24P4C12 comprises a change in the location of 24P4C12 and/or 24P4C12 expressing cells and/or an increase in 24P4C12 mRNA and/or protein expression.
24P4C12 status in a sample can be analyzed by a number of means well known in the art, induding without limitation, immunohistochemical analysis, in situ hybridization, RT-PCR analysis on laser capture miσc-dissected samples, Western blot analysis, and tissue array analysis. Typical protocols for evaluating the status of a 24P4C12 gene and gene products are found, for example in Ausubel ef al eds., 1995, Current Protocols In Molecular Biology, Units 2 (Northern Blotting), 4 (Southern Blotting), 15 (Immunoblotting) and 18 (PCR Analysis). Thus, the status of 24P4C12 in a biological sample is evaluated by various methods utilized by skilled artisans including, but not limited to genomic Southern analysis (to examine, for example perturbations in a 24P4C12 gene), Northern analysis and/or PCR analysis of 24P4C12 mRNA (to examine, for example alterations in the polynucleotide sequences or expression levels of 24P4C12 mRNAs), and, Western and/or immunohistochemical analysis (to examine, for example alterations in polypeptide sequences, alterations in polypeptide localization within a sample, alterations in expression levels of 24P4C12 proteins and/or associations of 24P4C12 proteins with polypeptide binding partners). Detedable 24P4C12 polynucleotides indude, for example, a 24P4C12 gene or fragment thereof, 24P4C12 mRNA, alternative splice variants, 24P4C12 mRNAs, and recombinant DNA or RNA molecules containing a 24P4C12 polynudeotide.
The expression profile of 24P4C12 makes it a diagnostic marker for local and/or metastasized disease, and provides information on the growth or oncogenic potential of a biological sample. In particular, the status of 24P4C12 provides
information useful for predicting susceptibility to particular disease stages, progression, and/or tumor aggressiveness. The invention provides methods and assays for determining 24P4C12 status and diagnosing cancers that express 24P4C12, such as cancers of the tissues listed in Table I. For example, because 24P4C12 mRNA is so highly expressed in prostate and other cancers relative to normal prostate tissue, assays that evaluate the levels of 24P4C12 mRNA transcripts or proteins in a biological sample can be used to diagnose a disease assodated with 24P4C12 dysregulation, and can provide prognostic information useful in defining appropriate therapeutic options.
The expression status of 24P4C12 provides information induding the presence, stage and location of dysplastic, precancerous and cancerous cells, predicting susceptibility to various stages of disease, and/or for gauging tumor aggressiveness. Moreover, the expression profile makes it useful as an imaging reagent for metastasized disease. Consequently, an aspect of the invention is directed to the various molecular prognostic and diagnostic methods for examining the status of 24P4C12 in biological samples such as those from individuals suffering from, or suspected of suffering from a pathology characterized by dysregulated cellular growth, such as cancer.
As described above, the status of 24P4C12 in a biological sample can be examined by a number of well-known procedures in the art. For example, the status of 24P4C12 in a biological sample taken from a specific location in the body can be examined by evaluating the sample for the presence or absence of 24P4C12 expressing cells (e.g. those that express 24P4C12 mRNAs or proteins). This examination can provide evidence of dysregulated cellular growth, for example, when 24P4C12-expressing cells are found in a biological sample that does not normally contain such cells (such as a lymph node), because such alterations in the status of 24P4C12 in a biological sample are often associated with dysregulated cellular growth. Specifically, one indicator of dysregulated cellular growth is the metastases of cancer cells from an organ of origin (such as the prostate) to a different area of the body (such as a lymph node). In this context, evidence of dysregulated cellular growth is important for example because occult lymph node metastases can be detected in a substantial proportion of patients with prostate cancer, and such metastases are associated with known predictors of disease progression (see, e.g., Murphy ef al, Prostate 42(4): 315-317 (2000);Su ef al, Semin. Surg. Oncol. 18(1): 17-28 (2000) and Freeman ef al., J Urol 1995 Aug 154(2 Pt 1):474-8).
In one aspect, the invention provides methods for monitoring 24P4C12 gene products by determining the status of 24P4C12 gene products expressed by cells from an individual suspected of having a disease assodated with dysregulated cell growth (such as hyperplasia or cancer) and then comparing the status so determined to the status of 24P4C12 gene products in a corresponding normal sample. The presence of aberrant 24P4C12 gene products in the test sample relative to the normal sample provides an indication of the presence of dysregulated cell growth within the cells of the individual.
In another aspect, the invention provides assays useful in determining the presence of cancer in an individual, comprising detecting a significant increase in 24P4C12 mRNA or protein expression in a test cell or tissue sample relative to expression levels in the corresponding normal cell or tissue. The presence of 24P4C12 mRNA can, for example, be evaluated in tissues including but not limited to those listed in Table I. The presence of significant 24P4C12 expression in any of these tissues is useful to indicate the emergence, presence and/or severity of a cancer, since the corresponding normal tissues do not express 24P4C12 mRNA or express it at lower levels.
In a related embodiment, 24P4C12 status is determined at the protein level rather than at the nudeic acid level. For example, such a method comprises determining the level of 24P4C12 protein expressed by cells in a test tissue sample and comparing the level so determined to the level of 24P4C12 expressed in a corresponding normal sample. In one embodiment, the presence of 24P4C12 protein is evaluated, for example, using immunohistochemical methods. 24P4C12 antibodies or binding partners capable of detecting 24P4C12 protein expression are used in a variety of assay formats well known in the art for this purpose.
In a further embodiment, one can evaluate the status of 24P4C12 nudeotide and amino add sequences in a biological sample in order to identify perturbations in the structure of these molecules. These perturbations can indude insertions, deletions, substitutions and the like. Such evaluations are useful because perturbations in the nucleotide and amino add sequences are observed in a large number of proteins associated with a growth dysregulated phenotype (see, e.g. , Marrogi ef al , 1999, J. Cutan. Pathol. 26(8):369-378). For example, a mutation in the sequence of 24P4C12 may be indicative of the presence or promotion of a tumor. Such assays therefore have diagnostic and predictive value where a mutation in 24P4C12 indicates a potential loss of function or increase in tumor growth.
A wide variety of assays for observing perturbations in nudeotide and amino acid sequences are well known in the art. For example, the size and structure of nudeic add or amino add sequences of 24P4C12 gene products are observed by the Northern, Southern, Western, PCR and DNA sequen ng protocols discussed herein. In addition, other methods for observing perturbations in nucleotide and amino acid sequences such as single strand conformation polymorphism analysis are well known in the art (see, e.g., U.S. Patent Nos.5,382,510 issued 7 September 1999, and 5,952,170 issued 17 January 1995).
Additionally, one can examine the methylation status of a 24P4C12 gene in a biological sample. Aberrant demethylation and/or hypermethylation of CpG islands in gene 5' regulatory regions frequently occurs in immortalized and transformed cells, and can result in altered expression of various genes. For example, promoter hypermethylation of the pi-class glutathione S-tr ansferase (a protein expressed in normal prostate but not expressed in >90% of prostate carcinomas) appears to permanently silence transcription of this gene and is the most frequently detected genomic alteration in prostate carcinomas (De Marzo et al, Am. J. Pathol. 155(6): 1985-1992 (1999)). In addition, this alteration is present in at least 70% of cases of high-grade prostate intraepithelial neoplasia (PIN) (Brooks etal, Cancer Epidemiol. Biomarkers Prev., 1998, 7:531-536). In another example, expression of the LAGE-I tumor specific gene (which is not expressed in normal prostate but is expressed in 25-50% of prostate cancers) is induced by deoxy-azacytidine in lymphoblastoid cells, suggesting that tumoral expression is due to demethylation (Lethe et al, Int. J. Cancer 76(6): 903-908 (1998)). A variety of assays for examining methylation status of a gene are well known in the art. For example, one can utilize, in Southern hybridization approaches, methylation-sensitive restriction enzymes that cannot deave sequences that contain methylated CpG sites to assess the methylation status of CpG islands. In addition, MSP (methylation spedfic PCR) can rapidly profile the methylation status of all the CpG sites present in a CpG island of a given gene. This procedure involves initial modification of DNA by sodium bisulfite (which will convert all unmettiylated cytosines to uracil) followed by amplification using primers specific for methylated versus unmettiylated DNA. Protocols involving methylation interference can also be found for example in Cunent Protocols In Molecular Biology, Unit 12, Frederick M. Ausubel etal. eds., 1995.
Gene amplification is an additional method for assessing the status of 24P4C12. Gene amplification is measured in a sample directly, for example, by conventional Southern blotting or Northern blotting to quantitate the transcription of mRNA (Thomas, 1980, Proc. Natl. Acad. Sci. USA, 77:5201-5205), dot blotting (DNA analysis), or in situ hybridization, using an appropriately labeled probe, based on the sequences provided herein. Alternatively, antibodies are employed that recognize specific duplexes, including DNA duplexes, RNA duplexes, and DNA-RNA hybrid duplexes or DNA-protein duplexes. The antibodies in turn are labeled and the assay carried out where the duplex is bound to a surface, so that upon the formation of duplex on the surface, the presence of antibody bound to the duplex can be detected.
Biopsied tissue or peripheral blood can be conveniently assayed for the presence of cancer cells using for example, Northern, dot blot or RT-PCR analysis to deted 24P4C12 expression. The presence of RT-PCR amplifiable 24P4C12 mRNA provides an indication of the presence of cancer. RT-PCR assays are well known in the art RT-PCR detection assays for tumor cells in peripheral blood are currently being evaluated for use in the diagnosis and management of a number of human solid tumors. In the prostate cancer field, these indude RT-PCR assays for the detection of cells expressing PSA and PSM (Verkaik ef
al, 1997, Urol. Res.25:373-384; Ghossein etal, 1995, J. Clin. Oncol. 13:1195-2000; Heston etal, 1995, Clin. Chem.41:1687- 1688).
A further aspect of the invention is an assessment of the susceptibility that an individual has for developing cancer. In one embodiment a method for predicting susceptibility to cancer comprises deteding 24P4C12 mRNA or 24P4C12 protein in a tissue sample, its presence indicating susceptibility to cancer, wherein the degree of 24P4C12 mRNA expression correlates to the degree of susceptibility. In a spedfic embodiment the presence of 24P4C12 in prostate or other tissue is examined, with the presence of 24P4C12 in the sample providing an indication of prostate cancer susceptibility (or the emergence or existence of a prostate tumor). Similarly, one can evaluate the integrity 24P4C12 nudeotide and amino add sequences in a biological sample, in order to identify perturbations in the structure of these molecules such as insertions, deletions, substitutions and the like. The presence of one or more perturbations in 24P4C12 gene products in the sample is an indication of cancer susceptibility (or the emergence or existence of a tumor).
The invention also comprises methods for gauging tumor aggressiveness. In one embodiment, a method for gauging aggressiveness of a tumor comprises determining the level of 24P4C12 mRNA or 24P4C12 protein expressed by tumor cells, comparing the level so determined to the level of 24P4C12 mRNA or 24P4C12 protein expressed in a corresponding normal tissue taken from the same individual or a normal tissue reference sample, wherein the degree of 24P4C12 mRNA or 24P4C12 protein expression in the tumor sample relative to the normal sample indicates the degree of aggressiveness. In a spedfic embodiment, aggressiveness of a tumor is evaluated by determining the extent to which 24P4C12 is expressed in the tumor cells, with higher expression levels indicating more aggressive tumors. Another embodiment is the evaluation of the integrity of 24P4C12 nucleotide and amino add sequences in a biological sample, in order to identify perturbations in the structure of these molecules such as insertions, deletions, substitutions and the like. The presence of one or more perturbations indicates more aggressive tumors.
Another embodiment of the invention is directed to methods for observing the progression of a malignancy in an individual over time. In one embodiment, methods for observing the progression of a malignancy in an individual over time comprise determining the level of 24P4C12 mRNA or 24P4C12 protein expressed by cells in a sample of the tumor, comparing the level so determined to the level of 24P4C12 mRNA or 24P4C12 protein expressed in an equivalent tissue sample taken from the same individual at a different time, wherein the degree of 24P4C12 mRNA or 24P4C12 protein expression in the tumor sample over time provides information on the progression of the cancer. In a spedfic embodiment, the progression of a cancer is evaluated by determining 24P4C12 expression in the tumor cells over time, where inσeased expression overtime indicates a progression of the cancer. Also, one can evaluate the integrity 24P4C12 nudeotide and amino add sequences in a biological sample in order to identify perturbations in the structure of these molecules such as insertions, deletions, substitutions and the like, where the presence of one or more perturbations indicates a progression of the cancer.
The above diagnostic approaches can be combined with any one of a wide variety of prognostic and diagnostic protocols known in the art. For example, another embodiment of the invention is directed to methods for observing a coinddence between the expression of 24P4C12 gene and 24P4C12 gene products (or perturbations in 24P4C12 gene and 24P4C12 gene products) and a factor that is assodated with malignancy, as a means for diagnosing and prognosticating the status of a tissue sample. A wide variety of factors assodated with malignancy can be utilized, such as the expression of genes assodated with malignancy (e.g. PSA, PSCA and PSM expression for prostate cancer etc.) as well as gross cytological observations (see, e.g., Booking etal, 1984, Anal. Quant. Cytol. 6(2):74-88; Epstein, 1995, Hum. Pathol. 26(2):223-9; Thorson etal, 1998, Mod. Pathol. 11(6):543-51; Baisden ef al., 1999, Am. J. Surg, Pathol. 23(8):918-24). Methods for observing a coinddence between the expression of 24P4C12 gene and 24P4C12 gene products (or perturbations in 24P4C12 gene and 24P4C12 gene products) and another factor that is assodated with malignancy are useful, for example, because the presence of a set of specific factors that coindde with disease provides information crudal for diagnosing and prognosticating the status of a tissue sample.
In one embodiment, methods for observing a coinddence between the expression of 24P4C12 gene and 24P4C12 gene products (or perturbations in 24P4C12 gene and 24P4C12 gene products) and another factor assodated with malignancy entails detecting the overexpression of 24P4C12 mRNA or protein in a tissue sample, detecting the overexpression of PSA mRNA or protein in a tissue sample (or PSCA or PSM expression), and observing a coinddence of 24P4C12 mRNA or protein and PSA mRNA or protein overexpression (σ PSCA or PSM expression). In a spedfic embodiment, the expression of 24P4C12 and PSA mRNA in prostate tissue is examined, where the coinddence of 24P4C12 and PSA mRNA overexpression in the sample indicates the existence of prostate cancer, prostate cancer susceptibility or the emergence or status of a prostate tumor.
Methods for detecting and quantifying the expression of 24P4C12 mRNA or protein are described herein, and standard nudeic add and protein detection and quantification technologies are well known in the art. Standard methods for the detection and quantification of 24P4C12 mRNA indude in situ hybridization using labeled 24P4C12 riboprobes, Northern blot and related techniques using 24P4C12 polynudeotide probes, RT-PCR analysis using primers spedfic for 24P4C12, and other amplification type detection methods, such as, for example, branched DNA SISBA, TMA and the like. In a specific embodiment, semi- quantitative RT-PCR is used to detect and quantify 24P4C12 mRNA expression. Any number of primers capable of amplifying 24P4C12 can be used for this purpose, including but not limited to the various primer sets spedfically described herein. In a spedfic embodiment, polydonal or monodonal antibodies spedfically reactive with the wild-type 24P4C12 protein can be used in an immunohistochemical assay of biopsied tissue. '
IX.) Identification of Molecules That Interact With 24P4C12
The 24P4C12 protein and nucleic add sequences disclosed herein allow a skilled artisan to identify proteins, small molecules and other agents that interact with 24P4C12, as well as pathways activated by 24P4C12 via any one of a variety of art accepted protocols. For example, one can utilize one of the so-called interaction trap systems (also referred to as the "two-hybrid assay"). In such systems, molecules interact and reconstitute a transcription factor which directs expression of a reporter gene, whereupon the expression of the reporter gene is assayed. Other systems identify protein-protein interactions in vivo through reconstitution of a eukaryotic transcriptional activator, see, e.g., U.S. Patent Nos.5,955,280 issued 21 September 1999, 5,925,523 issued 20 July 1999, 5,846,722 issued 8 December 1998 and 6,004,746 issued 21 December 1999. Algorithms are also available in the art for genome-based predictions of protein function (see, e.g., Marcotte, ef al, Nature 402: 4 November 1999, 83-86).
Alternatively one can screen peptide libraries to identify molecules that interact with 24P4C12 protein sequences. In such methods, peptides that bind to 24P4C12 are identified by sσeening libraries that encode a random or controlled collection of amino adds. Peptides encoded by the libraries are expressed as fusion proteins of bacteriophage coat proteins, the bacteriophage particles are then screened against the 24P4C12 protein(s).
Accordingly, peptides having a wide variety of uses, such as therapeutic, prognostic or diagnostic reagents, are thus identified without any prior information on the structure of the expected ligand or receptor molecule. Typical peptide libraries and screening methods that can be used to identify molecules that interact with 24P4C12 protein sequences are disclosed for example in U.S. Patent Nos. 5,723,286 issued 3 March 1998 and 5,733,731 issued 31 March 1998.
Alternatively, cell lines that express 24P4C12 are used to identify protein-protein interactions mediated by 24P4C12. Such interactions can be examined using immunoprecipitation techniques (see, e.g., Hamilton B.J., et al. Biochem. Biophys. Res. Commun. 1999, 261:646-51). 24P4C12 protein can be immunoprecipitated from 24P4C12- expressing cell lines using anti-24P4C12 antibodies. Alternatively, antibodies against His-tag can be used in a cell line engineered to express fusions of 24P4C12 and a His-tag (vectors mentioned above). The immunopredpitated complex can be examined for protein association by procedures such as Western blotting, ^S-methionine labeling of proteins, protein microsequencing, silver staining and two-dimensional gel electrophoresis.
Small molecules and ligands that interact with 24P4C12 can be identified through related embodiments of such screening assays. For example, small molecules can be identified that interfere with protein function, including molecules that interfere with 24P4C12's ability to mediate phosphorylation and de-phosphorylation, interaction with DNA or RNA molecules as an indication of regulation of cell cycles, second messenger signaling or tumorigenesis. Similarly, small molecules that modulate 24P4C12-related ion channel, protein pump, or cell communication functions are identified and used to treat patients that have a cancer that expresses 24P4C12 (see, e.g., Hille, B., Ionic Channels of Excitable Membranes 2nd Ed., Sinauer Assoc, Sunderiand, MA, 1992). Moreover, ligands that regulate 24P4C12 function can be identified based on their ability to bind 24P4C12 and activate a reporter construct. Typical methods are discussed for example in U.S. Patent No. 5,928,868 issued 27 July 1999, and include methods for forming hybrid ligands in which at least one ligand is a small molecule. In an illustrative embodiment, cells engineered to express a fusion protein of 24P4C12 and a DNA-binding protein are used to co-express a fusion protein of a hybrid ligand/small molecule and a cDNA library transcriptional activator protein. The cells further contain a reporter gene, the expression of which is conditioned on the proximity of the first and second fusion proteins to each other, an event that occurs only if the hybrid ligand binds to target sites on both hybrid proteins. Those cells that express the reporter gene are selected and the unknown small molecule or the unknown ligand is identified. This method provides a means of identifying modulators, which activate or inhibit 24P4C12.
An embodiment of this invention comprises a method of sσeening for a molecule that interacts with a 24P4C12 amino add sequence shown in Figure 2 or Figure 3, comprising the steps of contacting a population of molecules with a 24P4C12 amino acid sequence, allowing the population of molecules and the 24P4C12 amino acid sequence to interact under conditions that facilitate an interaction, determining the presence of a molecule that interacts with the 24P4C12 amino add sequence, and then separating molecules that do not interact with the 24P4C12 amino acid sequence from molecules that do. In a specific embodiment, the method further comprises purifying, characterizing and identifying a molecule that interacts with the 24P4C12 amino acid sequence. The identified molecule can be used to modulate a function performed by 24P4C12. In a preferred embodiment, the 24P4C12 amino acid sequence is contacted with a library of peptides.
X.) Therapeutic Methods and Compositions
The identification of 24P4C12 as a protein that is normally expressed in a restricted set of tissues, but which is also expressed in prostate and other cancers, opens a number of therapeutic approaches to the treatment of such cancers. As contemplated herein, 24P4C12 functions as a transcription factor involved in activating tumor-promoting genes or repressing genes that block tumorigenesis.
Accordingly, therapeutic approaches that inhibit the activity of a 24P4C12 protein are useful for patients suffering from a cancer that expresses 24P4C12. These therapeutic approaches generally fall into two dasses. One class comprises various methods for inhibiting the binding or association of a 24P4C12 protein with its binding partner or with other proteins. Another class comprises a variety of methods for inhibiting the transcription of a 24P4C12 gene or translation of 24P4C12 mRNA.
X.A.. Anti-Cancer Vaccines
The invention provides cancer vacdnes comprising a 24P4C12-related protein or 24P4C12-related nucleic add. In view of the expression of 24P4C12, cancer vacdnes prevent and/or treat 24P4C12-expressing cancers with minimal or no effects on non-target tissues. The use of a tumor antigen in a vacdne that generates humoral and/or cell-mediated immune responses as anti-cancer therapy is well known in the art and has been employed in prostate cancer using human PSMA and rodent PAP immunogens (Hodge ef al, 1995, Int. J. Cancer 63:231-237; Fong ef a/., 1997, J. Immunol. 159:3113-3117).
Such methods can be readily practiced by employing a 24P4C12-related protein, or a 24P4C12-encoding nucleic acid molecule and recombinant vectors capable of expressing and presenting the 24P4C12 immunogen (which typically comprises a number of antibody or T cell epitopes) Skilled artisans understand that a wide variety of vac ne systems for delivery of immunoreactive epitopes are known in the art (see, e.g., Heryln et a/., Ann Med 1999 Feb 31(1):66-78; Maruyama ef al, Cancer Immunol Immunother 2000 Jun 49(3):123-32) Briefly, such methods of generating an immune response (e.g. humoral and/or cell-mediated) in a mammal, comprise the steps of: exposing the mammal's immune system to an immunoreactive epitope (e.g. an epitope present in a 24P4C12 protein shown in Figure 3 or analog or homolog thereof) so that the mammal generates an immune response that is specific for that epitope (e.g. generates antibodies that specifically recognize that epitope). In a preferred method, a 24P4C12 immunogen contains a biological motif, see e.g., Tables VIII-XXI and XXII-XLIX, or a peptide of a size range from 24P4C12 indicated in Figure 5, Figure 6, Figure 7, Figure 8, and Figure 9.
The entire 24P4C12 protein, immunogenic regions or epitopes thereof can be combined and delivered by various means. Such vaccine compositions can include, for example, lipopeptides (e.g. , itiello, A. ef al, J. Clin. Invest. 95:341, 1995), peptide compositions encapsulated in poly(DL-lactide-co-glycolide) ("PLG") microspheres (see, e.g., Eldridge, ef al, Molec. Immunol. 28:287-294, 1991: Alonso ef a/., Vaccine 12:299-306, 1994; Jones et a/., Vaccine 13:675-681, 1995), peptide compositions contained in immune stimulating complexes (ISCOMS) (see, e.g., Takahashi ef al, Nature 344:873- 875, 1990; Hu ef al, Clin Exp Immunol. 113:235-243, 1998), multiple antigen peptide systems (MAPs) (see e.g., Tam, J. P., Proc. Natl. Acad. Sci. U.S.A. 85:5409-5413, 1988; Tam, J.P., J. Immunol. Methods 196:17-32, 1996), peptides formulated as multivalent peptides; peptides for use in ballistic delivery systems, typically crystallized peptides, viral delivery vectors (Perkus, M. E. ef al, In: Concepts in vaccine development, Kaufmann, S. H. E., ed., p. 379, 1996; Chakrabarti, S. ef al, Nature 320:535, 1986; Hu, S. L. etal, Nature 320:537, 1986; Kieny, M.-P. ef a/., AIDS Bio/Technology 4:790, 1986; Top, F. H. ef al, J. Infect. Dis. 124:148, 1971; Chanda, P. K. et al, Virology 175:535, 1990), particles of viral or synthetic origin (e.g., Kofler, N. ef al, J. Immunol Methods. 192:25, 1996; Eldridge, J. H. et al, Sem. Hematol. 30:16, 1993; Falo, L. D., Jr. etaj., Nature Med. 7:649, 1995), adjuvants (Warren, H. S„ Vogel, F. R., and Chedid, L. A. Annu. Rev. Immunol 4:369, 1986; Gupta, R. K. et al, Vaccine 11 :293, 1993), liposomes (Reddy, R. et al, J. Immunol. 148:1585, 1992; Rock, K. L, Immunol. Today 17:131, 1996), or, naked or particle absorbed cDNA (Ulmer, J. B. ef al, Science 259:1745, 1993; Robinson, H. L, Hunt, L. A., and Webster, R. G., Vaccine 11 :957, 1993; Shiver, J. W. ef al, In: Concepts in vaccine development, Kaufmann, S. H. E., ed., p. 423, 1996; Cease, K. B., and Berzofsky, J. A., Annu. Rev. Immunol. 12:923, 1994 and Eldridge, J. H. ef al, Sem. Hematol. 30:16, 1993). Toxin-targeted delivery technologies, also known as receptor mediated targeting, such as those of Avant Immunotherapeutics, Inc. (Needham, Massachusetts) may also be used.
In patients with 24P4C12-associated cancer, the vaccine compositions of the invention can also be used in conjunction with other treatments used for cancer, e.g., surgery, chemotherapy, drug therapies, radiation therapies, efc. including use in combination with immune adjuvants such as IL-2, IL-12, GM-CSF, and the like.
Cellular Vacdnes:
CTL epitopes can be determined using specific algorithms to identify peptides within 24P4C12 protein that bind corresponding HLA alleles (see e.g., Table IV; Epimer™ and Epimatrix™, Brown University (URL brown.edu/Research/TB- HIV_Lab/epimatrix/epimatrix.html); and, BIMAS, (URL bimas.dcrtnih.gov/; SYFPEITHI at URL syfj-eithi.bmi-heidelberg.com.). In a preferred embodiment, a 24P4C12 immunogen contains one or more amino acid sequences identified using techniques well known in the art, such as the sequences shown in Tables VIII-XXI and XXII-XLIX or a peptide of 8, 9, 10 or 11 amino acids specified by an HLA Class I moti f/supermotif (e.g., Table IV (A), Table IV (D), or Table IV (E)) and/or a peptide of at least 9 amino acids that comprises an HLA Class II motif/supermotif (e.g., Table IV (B) or Table IV (C)). As is appre ated in the art, the HLA Class I binding groove is essentially closed ended so that peptides of only a particular size range can fit into the groove and be bound, generally HLA Class I epitopes are 8, 9, 10, or 11 amino acids long. In contrast, the HLA Class II
binding groove is essentially open ended; therefore a peptide of about 9 or more amino acids can be bound by an HLA Class II molecule. Due to the binding groove differences between HLA Class I and II, HLA Class I motifs are length specific, i.e., position two of a Class I motif is the second amino acid in an amino to carboxyl direction of the peptide. The amino acid positions in a Class II motif are relative only to each other, not the overall peptide, i.e., additional amino adds can be attached to the amino and/or carboxyl termini of a motif-bearing sequence. HLA Class II epitopes are often 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, or 25 amino acids long, or longer than 25 amino acids.
Antibody-based Vaccines
A wide variety of methods for generating an immune response in a mammal are known in the art (for example as the first step in the generation of hybridomas). Methods of generating an immune response in a mammal comprise exposing the mammal's immune system to an immunogenic epitope on a protein (e.g. a 24P4C12 protein) so that an immune response is generated. A typical embodiment consists of a method for generating an immune response to 24P4C12 in a host, by contacting the host with a sufficient amount of at least one 24P4C12 B cell or cytotoxic T-cell epitope or analog thereof; and at least one periodic interval thereafter re-contacting the host with the 24P4C12 B cell or cytotoxic T-cell epitope or analog thereof. A specific embodiment consists of a method of generating an immune response against a 24P4C12- related protein or a man-made multiepitopic peptide comprising: administering 24P4C12 immunogen (e.g. a 24P4C12 protein or a peptide fragment thereof, a 24P4C12 fusion protein or analog etc.) in a vaccine preparation to a human or another mammal. Typically, such vaccine preparations further contain a suitable adjuvant (see, e.g., U.S. Patent No. 6,146,635) or a universal helper epitope such as a PADRE™ peptide (Epimmune Inc., San Diego, CA; see, e.g., Alexander ef al, J. Immunol. 2000 164(3); 164(3): 1625-1633; Alexander ef al, Immunity 1994 1(9): 751-761 and Alexander ef al, Immunol. Res. 1998 18(2): 79-92). An alternative method comprises generating an immune response in an individual against a 24P4C12 immunogen by: administering in vivo to muscle or skin of the individual's body a DNA molecule that comprises a DNA sequence that encodes a 24P4C12 immunogen, the DNA sequence operatively linked to regulatory sequences which control the expression of the DNA sequence; wherein the DNA molecule is taken up by cells, the DNA sequence is expressed in the cells and an immune response is generated against the immunogen (see, e.g., U.S. Patent No. 5,962,428). Optionally a genetic vaccine facilitator such as anionic lipids; saponins; lectins; estrogenic compounds; hydroxylated lower alkyls; dimethyl sulfoxide; and urea is also administered. In addition, an antiidiotypic antibody can be administered that mimics 24P4C12, in order to generate a response to the target antigen.
Nudeic Add Vacdnes:
Vaccine compositions of the invention include nucleic add-mediated modalities. DNA or RNA that encode protein(s) of the invention can be administered to a patient. Genetic immunization methods can be employed to generate prophylactic or therapeutic humoral and cellular immune responses directed against cancer cells expressing 24P4C12. Constructs comprising DNA encoding a 24P4C12-related protein/immunogen and appropriate regulatory sequences can be injected directly into muscle or skin of an individual, such that the cells of the muscle or skin take-up the construd and express the encoded 24P4C12 protein/immunogen. Alternatively, a vaccine comprises a 24P4C12-related protein. Expression of the 24P4C12-related protein immunogen results in the generation of prophylactic or therapeutic humoral and cellular immunity against cells that bear a 24P4C12 protein. Various prophylactic and therapeutic genetic immunization techniques known in the art can be used (for review, see information and references published at Internet address genweb.com). Nudeic acid-based delivery is described, for instance, in Wolff ef. al, Science 247:1465 (1990) as well as U.S. Patent Nos.5,580,859; 5,589,466; 5,804,566; 5,739,118; 5,736,524; 5,679,647; WO 98/04720. Examples of DNA- based delivery technologies indude "naked DNA", facilitated (bupivicaine, polymers, peptide-mediated) delivery, cationic lipid complexes, and particle-mediated ("gene gun") or pressure-mediated delivery (see, e.g., U.S. Patent No. 5,922,687).
For therapeutic or prophylactic immunization purposes, proteins of the invention can be expressed via viral or bacterial vectors. Various viral gene delivery systems that can be used in the practice of the invention indude, but are not limited to, vacdnia, fowlpox, canarypox, adenovirus, influenza, poliovirus, adeno-assotiated virus, lenlivirus, and sindbis vims (see, e.g., Restifo, 1996, Curr. Opin. Immunol. 8:658-663; Tsang etal. J. NaH. Cancer Inst 87:982-990 (1995)). Non-viral delivery systems can also be employed by introducing naked DNA encoding a 24P4C12-related protein into the patient (e.g., intramuscularly or intradermally) to induce an anti-tumor response.
Vaccinia virus is used, for example, as a vector to express nucleotide sequences that encode the peptides of the invention. Upon introduction into a host, the recombinant vaccinia virus expresses the protein immunogenic peptide, and thereby elicits a host immune response. Vaccinia vectors and methods useful in immunization protocols are described in, e.g., U.S. Patent No. 4,722,848. Another vector is BCG (Bacille Calmette Guerin). BCG vectors are described in Stover ef al, Nature 351:456460 (1991). A wide variety of other vectors useful for therapeutic administration or immunization of the peptides of the invention, e.g. adeno and adeno-associated virus vectors, retroviral vectors, Salmonella typhi vectors, detoxified anthrax toxin vectors, and the like, will be apparent to those skilled in the art from the description herein.
Thus, gene delivery systems are used to deliver a 24P4C12-related nudeic add molecule. In one embodiment, the full- length human 24P4C12 cDNA is employed. In anottier embodiment, 24P4C12 nudeic acid molecules encoding spedfic cytotoxic T lymphocyte (CTL) and/or antibody epitopes are employed.
Ex Vivo Vaccines
Various ex vivo strategies can also be employed to generate an immune response. One approach involves the use of antigen presenting cells (APCs) such as dendritic cells (DC) to present 24P4C12 antigen to a patient's immune system. Dendritic cells express MHC dass I and II molecules, B7 co-stimulator, and IL-12, and are thus highly spedalized antigen presenting cells. In prostate cancer, autologous dendritic cells pulsed with peptides of the prostate-specific membrane antigen (PSMA) are being used in a Phase I clinical trial to stimulate prostate cancer patients' immune systems (Tjoa ef al, 1996, Prostate 28:65- 69; Murphy ef al, 1996, Prostate 29:371-380). Thus, dendritic cells can be used to present 24P4C12 peptides to T cells in the context of MHC class I or II molecules. In one embodiment, autologous dendritic cells are pulsed with 24P4C12 peptides capable of binding to MHC class I and/or class II molecules. In another embodiment, dendritic cells are pulsed with the complete 24P4C12 protein. Yet another embodiment involves engineering the overexpression of a 24P4C12 gene in dendritic cells using various implementing vectors known in the art, such as adenovirus (Arthur etal, 1997, Cancer Gene Ther.4:17-25), retrovirus (Henderson ef al, 1996, Cancer Res. 56:3763-3770), lentivirus, adeno-associated virus, DNA transfection (Ribas ef al, 1997, Cancer Res. 57:2865-2869), or tumor-derived RNA transfection (Ashley ef a/., 1997, J. Exp. Med. 186:1177-1182). Cells that express 24P4C12 can also be engineered to express immune modulators, such as GM- CSF, and used as immunizing agents.
X.B.) 24P4C12 as a Target for Antibody-based Therapy
24P4C12 is an attractive target for antibody-based therapeutic strategies. A number of antibody strategies are known in the art for targeting both extracellular and intracellular molecules (see, e.g., complement and ADCC mediated killing as well as the use of intrabodies). Because 24P4C12 is expressed by cancer cells of various lineages relative to corresponding normal cells, systemic administration of 24P4C12-immunoreactive compositions are prepared that exhibit excellent sensitivity without toxic, non-specific and/or non-target effects caused by binding of the immunoreactive composition to non-target organs and tissues. Antibodies spedfically reactive with domains of 24P4C12 are useful to treat 24P4C12-expressing cancers systemically, either as conjugates with a toxin or therapeutic agent, or as naked antibodies capable of inhibiting cell proliferation or function.
24P4C12 antibodies can be introduced into a patient such that the antibody binds to 24P4C12 and modulates a function, such as an interaction with a binding partner, and consequently mediates destruction of the tumor cells and/or inhibits the growth of the tumor cells. Mechanisms by which such antibodies exert a therapeutic effect can include complement-mediated cytolysis, antibody-dependent cellular cytotoxicity, modulation of the physiological function of 24P4C12, inhibition of ligand binding or signal transduction pathways, modulation of tumor cell differentiation, alteration of tumor angiogenesis factor profiles, and/or apoptosis.
Those skilled in the art understand that antibodies can be used to specifically target and bind immunogenic molecules such as an immunogenic region of a 24P4C12 sequence shown in Figure 2 or Figure 3. In addition, skilled artisans understand that it is routine to conjugate antibodies to cytotoxic agents (see, e.g., Slevers ef al. Blood 93:11 3678- 3684 (June 1 , 1999)). When cytotoxic and/or therapeutic agents are delivered directly to cells, such as by conjugating them to antibodies specific for a molecule expressed by that cell (e.g.24P4C12), the cytotoxic agent will exert its known biological effect (i.e. cytotoxicity) on those cells.
A wide variety of compositions and methods for using antibody-cytotoxic agent conjugates to kill cells are known in the art. In the context of cancers, typical methods entail administering to an animal having a tumor a biologically effective amount of a conjugate comprising a selected cytotoxic and/or therapeutic agent linked to a targeting agent (e.g. an anti- 24P4C12 antibody) that binds to a marker (e.g. 24P4C12) expressed, accessible to binding or localized on the cell surfaces. A typical embodiment is a method of delivering a cytotoxic and/or therapeutic agent to a cell expressing 24P4C12, comprising conjugating the cytotoxic agent to an antibody that immunospecifically binds to a 24P4C12 epitope, and, exposing the cell to the antibody-agent conjugate. Another illustrative embodiment is a method of treating an individual suspected of suffering from metastasized cancer, comprising a step of administering parenterally to said individual a pharmaceutical composition comprising a therapeutically effective amount of an antibody conjugated to a cytotoxic and/or therapeutic agent.
Cancer immunotherapy using anti-24P4C12 antibodies can be done in accordance with various approaches that have been successfully employed in the treatment of other types of cancer, including but not limited to colon cancer (Arlen et al, 1998, Crit. Rev. Immunol. 18:133-138), multiple myeloma (Ozaki etal, 1997, Blood 90:3179-3186, Tsunenari etal, 1997, Blood 90:2437-2444), gastric cancer (Kasprzyk etal, 1992, Cancer Res. 52:2771-2776), B-cell lymphoma (Funakoshi etal, 1996, J. Immunother. Emphasis Tumor Immunol. 19:93-101), leukemia (Zhong etal, 1996, Leuk. Res. 20:581-589), colorectal cancer (Moun etal, 1994, Cancer Res. 54:6160-6166; Velders et al, 1995, Cancer Res. 55:43984403), and breast cancer (Shepard etal, 1991, J. Clin. Immunol. 11:117-127). Some therapeutic approaches involve conjugation of naked antibody to a toxin or radioisotope, such as the conjugation of Y91 or I131 to anti-CD20 antibodies (e.g., Zevalin™, IDEC Pharmaceuticals Corp. or Bexxar™, Coulter Pharmaceuticals), while others involve co-administration of antibodies and other therapeutic agents, such as Herceptin™ (trastuzumab) with paclitaxel (Genentech, Inc.). The antibodies can be conjugated to a therapeutic agent. To treat prostate cancer, for example, 24P4C12 antibodies can be administered in conjunction with radiation, chemotherapy or hormone ablation. Also, antibodies can be conjugated to a toxin such as calicheamicin (e.g., Myiotarg™, Wyeth-Ayerst, Madison, NJ, a recombinant humanized IgG. kappa antibody conjugated to aπtitumor antibiotic calicheamicin) or a maytansinoid (e.g., taxane-based Tumor-Activated Prodrug, TAP, platform, ImmunoGen, Cambridge, MA, also see e.g., US Patent 5,416,064).
Although 24P4C12 antibody therapy is useful for all stages of cancer, antibody therapy can be particularly appropriate in advanced or metastatic cancers. Treatment with the antibody therapy of the invention is indicated for patients who have received one or more rounds of chemotherapy. Alternatively, antibody therapy of the invention is combined with a chemotherapeutic or radiation regimen for patients who have not received chemotherapeutic treatment. Additionally, antibody therapy can enable the use of reduced dosages of concomitant chemotherapy, particularly for patients who do not
tolerate the toxidty of the chemotherapeutic agent very well. Fan et al. (Cancer Res. 53:46374642, 1993), Prewett et al. (International J. of Onco. 9:217-224, 1996), and Hancock et al. (Cancer Res. 51:45754580, 1991) describe the use of various antibodies together with chemotherapeutic agents.
Although 24P4C12 antibody therapy is useful for all stages of cancer, antibody therapy can be particularly appropriate in advanced or metastatic cancers. Treatment with the antibody therapy of the invention is indicated for patients who have received one or more rounds of chemotherapy. Altematively, antibody therapy of the invention is combined with a chemotherapeutic or radiation regimen for patients who have not received chemotherapeutic treatment. Additionally, antibody therapy can enable the use of reduced dosages of concomitant chemotherapy, particularly for patients who do not tolerate the toxidty of the chemotherapeutic agent very well. v
Cancer patients can be evaluated for the presence and level of 24P4C12 expression, preferably using immunohistochemical assessments of tumor tissue, quantitative 24P4C12 imaging, or other techniques that reliably indicate the presence and degree of 24P4C12 expression. Immunohistochemical analysis of tumor biopsies or surgical specimens is preferred for this purpose. Methods for immunohistochemical analysis of tumor tissues are well known in the art.
Anti-24P4C12 monoclonal antibodies that treat prostate and other cancers include those that initiate a potent immune response against the tumor or those that are directly cytotoxic. In this regard, anti-24P4C12 monoclonal antibodies (mAbs) can elicit tumor cell lysis by either complement-mediated or antibody-dependent cell cytotoxicity (ADCC) mechanisms, both of which require an intact Fc portion of the immunoglobulin molecule for interaction with effector cell Fc receptor sites on complement proteins. In addition, anti-24P4C12 mAbs that exert a direct biological effect on tumor growth are useful to treat cancers that express 24P4C12. Mechanisms by which directly cytotoxic mAbs act include: inhibition of cell growth, modulation of cellular differentiation, modulation of tumor angiogenesis factor profiles, and the induction of apoptosis. The mechanism(s) by which a particular anti-24P4C12 mAb exerts an anti-tumor effect is evaluated using any number of in vitro assays that evaluate cell death such as ADCC, ADMMC, complement-mediated cell lysis, and so forth, as is generally known in the art.
In some patients, the use of murine or other non-human monodonal antibodies, or human/mouse chimeric mAbs can induce moderate to strong immune responses against the non-human antibody. This can result in clearance of the antibody from circulation and reduced efficacy. In the most severe cases, such an immune response can lead to the extensive formation of immune complexes which, potentially, can cause renal failure. Accordingly, preferred monoclonal antibodies used in the therapeutic methods of the invention are those that are either fully human or humanized and that bind specifically to the target 24P4C12 antigen with high affinity but exhibit low or no antigenicity in the patient.
Therapeutic methods of the invention contemplate the administration of single anti-24P4C12 mAbs as well as combinations, or cocktails, of different mAbs. Such mAb cocktails can have certain advantages inasmuch as they contain mAbs that target different epitopes, exploit different effector mechanisms or combine directly cytotoxic mAbs with mAbs that rely on immune effector functionality. Such mAbs in combination can exhibit synergistic therapeutic effects. In addition, anti- 24P4C12 mAbs can be administered concomitantly with other therapeutic modalities, including but not limited to various chemotherapeutic agents, androgen-blockers, immune modulators (e.g., IL-2, GM-CSF), surgery or radiation. The anti- 24P4C12 mAbs are administered in their "naked" or unconjugated form, or can have a therapeutic agent(s) conjugated to them.
Anti-24P4C12 antibody formulations are administered via any route capable of delivering the antibodies to a tumor cell. Routes of administration include, but are not limited to, intravenous, intr aperitoneal, intramuscular, intratumor, intradermal, and the like. Treatment generally involves repeated administration of the anti-24P4C12 antibody preparation, via an acceptable route of administration such as intravenous injection (IV), typically at a dose in the range of about 0.1 , .2,
.3, .4, .5, .6, .7, .8, .9., 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, or 25 mg/kg body weight. In general, doses in the range of 10-1000 mg mAb per week are effective and well tolerated.
Based on clinical experience with the Herceptin™ mAb in the treatment of metastatic breast cancer, an initial loading dose of approximately 4 mg/kg patient body weight IV, followed by weekly doses of about 2 mg/kg IV of the anti- 24P4C12 mAb preparation represents an acceptable dosing regimen. Preferably, the initial loading dose is administered as a 90-minute or longer infusion. The periodic maintenance dose is administered as a 30 minute or longer infusion, provided the initial dose was well tolerated. As appreciated by those of skill in the art, various factors can influence the ideal dose regimen in a particular case. Such factors include, for example, the binding affinity and half life of the Ab or mAbs used, the degree of 24P4C12 expression in the patient, the extent of circulating shed 24P4C12 antigen, the desired steady-state antibody concentration level, frequency of treatment, and the influence of chemotherapeutic or other agents used in combination with the treatment method of the invention, as well as the health status of a particular patient.
Optionally, patients should be evaluated for the levels of 24P4C12 in a given sample (e.g. the levels of circulating 24P4C12 antigen and/or 24P4C 12 expressing cells) in order to assist in the determination of the most effective dosing regimen, etc. Such evaluations are also used for monitoring purposes throughout therapy, and are useful to gauge therapeutic success in combination with the evaluation of other parameters (for example, urine cytology and/or ImmunoCyt levels in bladder cancer therapy, or by analogy, serum PSA levels in prostate cancer therapy).
Anti-idiotypic anti-24P4C12 antibodies can also be used in anti-cancer therapy as a vaccine for indudng an immune response to cells expressing a 24P4C12-related protein. In particular, the generation of anti-idiotypic antibodies is well known in the art; this methodology can readily be adapted to generate anti-idiotypic anti-24P4C12 antibodies that mimic an epitope on a 24P4C12-related protein (see, for example, Wagner etal., 1997, Hybridoma 16: 3340; Foon ef a/., 1995, J. Clin. Invest.96:334-342; Herlyn ef a/., 1996, Cancer Immunol. I munother.43:65-76). Such an anti-idiotypic antibody can be used in cancer vaccine strategies.
X.C.) 24P4C12 as a Target for Cellular Immune Responses
Vaccines and methods of preparing vaccines that contain an immunogenically effective amount of one or more HLA-binding peptides as described herein are further embodiments of the invention. Furthermore, vaccines in accordance with the invention encompass compositions of one or more of the claimed peptides. A peptide can be present in a vaccine individually. Alternatively, the peptide can exist as a homopolymer comprising multiple copies of the same peptide, or as a heteropolymer of various peptides. Polymers have the advantage of increased immunological reaction and, where different peptide epitopes are used to make up the polymer, the additional ability to induce antibodies and/or CTLs that react with different antigenic determinants of the pathogenic organism or tumor-related peptide targeted for an immune response. The composition can be a naturally occurring region of an antigen or can be prepared, e.g., recombinantly or by chemical synthesis.
Carriers that can be used with vaccines of the invention are well known in the art, and include, e.g., thyroglobulin, albumins such as human serum albumin, tetanus toxoid, polyamino adds such as poly L-lysine, poly L-glutamic add, influenza, hepatitis B virus core protein, and the like. The vacdnes can contain a physiologically tolerable (i.e., acceptable) diluent such as water, or saline, preferably phosphate buffered saline. The vaccines also typically include an adjuvant. Adjuvants such as incomplete Freund's adjuvant, aluminum phosphate, aluminum hydroxide, or alum are examples of materials well known in the art. Additionally, as disdosed herein, CTL responses can be primed by conjugating peptides of the invention to lipids, such as tripalmitoyl-S-glycerylcysteinlyseryl- serine (P3CSS). Moreover, an adjuvant such as a synthetic cytosine-phosphorothiolated-guanine-containing (CpG) oligonudeotides has been found to inσease CTL responses 10- to 100-fold, (see, e.g, Davila and Celis, J. Immunol. 165:539-547 (2000))
Upon immunization with a peptide composition in accordance with the invention, via injection, aerosol, oral, transdermal, transmucosal, intrapleur al, intrathecal, or other suitable routes, the immune system of the host responds to the vaccine by producing large amounts of CTLs and/or HTLs spedfic for the desired antigen. Consequently, the host becomes at least partially immune to later development of cells that express or overexpress 24P4C12 antigen, or derives at least some therapeutic benefit when the antigen was tumor-associated.
In some embodiments, it may be desirable to combine the class I peptide components with components that induce or facilitate neutralizing antibody and or helper T cell responses directed to the target antigen. A preferred embodiment of such a composition comprises class I and class II epitopes in accordance with the invention. An alternative embodiment of such a composition comprises a class I and/or class II epitope in accordance with the invention, along with a cross reactive HTL epitope such as PADRE™ (Epimmune, San Diego, CA) molecule (described e.g., in U.S. Patent Number 5,736,142).
A vaccine of the invention can also include antigen-presenting cells (APC), such as dendritic cells (DC), as a vehicle to present peptides of the invention. Vaccine compositions can be created in vitro, following dendritic cell mobilization and harvesting, whereby loading of dendritic cells occurs in vitro. For example, dendritic cells are transfected, e.g., with a minigene in accordance with the invention, or are pulsed with peptides. The dendritic cell can then be administered to a patient to elicit immune responses in vivo. Vaccine compositions, either DNA- or peptide-based, can also be administered in vivo in combination with dendritic cell mobilization whereby loading of dendritic cells occurs in vivo.
Preferably, the following principles are utilized when selecting an array of epitopes for inclusion in a polyepitopic composition for use in a vaccine, or for selecting disσete epitopes to be included in a vaccine and/or to be encoded by nudeic acids such as a minigene. It is preferred that each of the following principles be balanced in order to make the selection. The multiple epitopes to be incorporated in a given vaccine composition may be, but need not be, contiguous in sequence in the native antigen from which the epitopes are derived.
1.) Epitopes are selected which, upon administration, mimic immune responses that have been observed to be correlated with tumor clearance. For HLA Class I this includes 34 epitopes that come from at least one tumor associated antigen (TAA), For HLA Class II a similar rationale is employed; again 3-4 epitopes are selected from at least one TAA (see, e.g., Rosenberg et al., Science 278:1447-1450). Epitopes from one TAA may be used in combination with epitopes from one or more additional TAAs to produce a vaccine that targets tumors with varying expression patterns of frequently-expressed TAAs.
2.) Epitopes are selected that have the requisite binding affinity established to be correlated with immunogenicity: for HLA Class I an ICso of 500 nM or less, often 200 nM or less; and for Class II an ICso of 1000 nM or less.
3.) Sufficient supermotif bearing-peptides, or a sufficient array of allele-spedfic motif-bearing peptides, are selected to give broad population coverage. For example, it is preferable to have at least 80% population coverage. A Monte Carlo analysis, a statistical evaluation known in the art, can be employed to assess the breadth, or redundancy of, population coverage.
4.) When selecting epitopes from cancer-related antigens it is often useful to select analogs because the patient may have developed tolerance to the native epitope.
5.) Of particular relevance are epitopes referred to as "nested epitopes." Nested epitopes occur where at least two epitopes overlap in a given peptide sequence. A nested peptide sequence can comprise B cell, HLA class I and/or HLA class II epitopes. When providing nested epitopes, a general objective is to provide the greatest number of epitopes per sequence. Thus, an aspect is to avoid providing a peptide that is any longer than the amino terminus of the amino terminal epitope and the carboxyl terminus of the carboxyl terminal epitope in the peptide. When providing a multi-epitopic sequence,
such as a sequence comprising nested epitopes, it is generally important to screen the sequence in order to insure that it does not have pathological or other deleterious biological properties.
6.) If a polyepitopic protein is created, or when creating a minigene, an objective is to generate the smallest peptide that encompasses the epitopes of interest. This principle is similar, if not the same as that employed when selecting a peptide comprising nested epitopes. However, with an artificial polyepitopic peptide, the size minimization objective is balanced against the need to integrate any spacer sequences between epitopes in the polyepitopic protein. Spacer amino add residues can, for example, be introduced to avoid junctional epitopes (an epitope recognized by the immune system, not present in the target antigen, and only created by the man-made juxtaposition of epitopes), or to facilitate cleavage between epitopes and thereby enhance epitope presentation. Junctional epitopes are generally to be avoided because the recipient may generate an immune response to that non-native epitope. Of particular concern is a junctional epitope that is a "dominant epitope." A dominant epitope may lead to such a zealous response that immune responses to other epitopes are diminished or suppressed,
7.) Where the sequences of multiple variants of the same target protein are present, potential peptide epitopes can also be selected on the basis of their conservancy. For example, a criterion for conservancy may define that the entire sequence of an HLA class I binding peptide or the entire 9-mer core of a class II binding peptide be conserved in a designated percentage of the sequences evaluated for a specific protein antigen. X.C.1. Minigene Vaccines
A number of different approaches are available which allow simultaneous delivery of multiple epitopes. Nucleic acids encoding the peptides of the invention are a particularly useful embodiment of the invention. Epitopes for inclusion in a minigene are preferably selected according to the guidelines set forth in the previous section, A preferred means of administering nucleic acids encoding the peptides of the invention uses minigene constructs encoding a peptide comprising one or multiple epitopes of the invention.
The use of multi-epitope minigenes is described below and in, Ishioka ef al, J. Immunol. 162:3915-3925, 1999; An, L. and Whitton, J. L, J. Virol 71:2292, 1997; Thomson, S. A. ef al, J. Immunol. 157:822, 1996; Whitton, J. L. etal, J. Virol. 67:348, 1993; Hanke, R. ef al, Vaccine 16:426, 1998. For example, a multi-epitope DNA plasmid encoding supermotif- and/or motif-bearing epitopes derived 24P4C12, the PADRE® universal helper T cell epitope or multiple HTL epitopes from 24P4C12 (see e.g., Tables VIII-XXI and XXII to XLIX), and an endoplasmic reticulum-translocating signal sequence can be engineered. A vaccine may also comprise epitopes that are derived from other TAAs.
The immunogenicity of a multi-epitopic minigene can be confirmed in transgenic mice to evaluate the magnitude of CTL induction responses against the epitopes tested. Further, the immunogenicity of DNA-encoded epitopes in vivo can be correlated with the in vitro responses of specific CTL lines against target cells transfected with the DNA plasmid. Thus, these experiments can show that the minigene serves to both: 1.) generate a CTL response and 2.) that the induced CTLs recognized cells expressing the encoded epitopes.
For example, to create a DNA sequence encoding the selected epitopes (minigene) for expression in human cells, the amino acid sequences of the epitopes may be reverse translated. A human codon usage table can be used to guide the codon choice for each amino acid. These epitope-encoding DNA sequences may be directly adjoined, so that when translated, a continuous polypeptide sequence is σeated. To optimize expression and/or immunogenicity, additional elements can be incorporated into the minigene design. Examples of amino acid sequences that can be reverse translated and included in the minigene sequence indude: HLA class I epitopes, HLA class II epitopes, antibody epitopes, a ubiquitination signal sequence, and/or an endoplasmic reticulum targeting signal. In addition, HLA presentation of CTL and HTL epitopes may be improved by induding synthetic (e.g. poly-alanine) or naturally-occurring flanking sequences adjacent to the CTL or HTL epitopes; these larger peptides comprising the epitope(s) are within the scope of the invention.
The minigene sequence may be converted to DNA by assembling oligonucleotides that encode the plus and minus strands of the minigene. Overlapping oligonucleotides (30-100 bases long) may be synthesized, phosphorylated, purified and annealed under appropriate conditions using well known techniques. The ends of the oligonucleotides can be joined, for example, using T4 DNA ligase. This synthetic minigene, encoding the epitope polypeptide, can then be cloned into a desired expression vector.
Standard regulatory sequences well known to those of skill in the art are preferably included in the vector to ensure expression in the target cells. Several vector elements are desirable: a promoter with a down-stream cloning site for minigene insertion; a polyadenylation signal for efficient transcription termination; an £ coli origin of replication; and an £ coli selectable marker (e.g. ampicillin or kanamycin resistance). Numerous promoters can be used for this purpose, e.g., the human cytomegalovirus (hCMV) promoter. See, e.g., U.S. Patent Nos. 5,580,859 and 5,589,466 for other suitable promoter sequences.
Additional vector modifications may be desired to optimize minigene expression and immunogenicity. In some cases, introns are required for efficient gene expression, and one or more synthetic or naturally-occurring introns could be incorporated into the transcribed region of the minigene. The inclusion of mRNA stabilization sequences and sequences for replication in mammalian cells may also be considered for increasing minigene expression.
Once an expression vedor is selected, the minigene is cloned into the polylinker region downstream of the promoter. This plasmid is transformed into an appropriate £ coli strain, and DNA is prepared using standard techniques. The orientation and DNA sequence of the minigene, as well as all other elements induded in the vector, are confirmed using restriction mapping and DNA sequence analysis. Bacterial cells harboring the correct plasmid can be stored as a master cell bank and a working cell bank.
In addition, immunostimulatory sequences (ISSs or CpGs) appear to play a role in the immunogenicity of DNA vaccines. These sequences may be included in the vector, outside the minigene coding sequence, if desired to enhance immunogenicity.
In some embodiments, a bi-cistronic expression vector which allows production of both the minigene-encoded epitopes and a second protein (included to enhance or decrease immunogenicity) can be used. Examples of proteins or polypeptides that could beneficially enhance the immune response if co-expressed indude cytokines (e.g., IL-2, IL-12, GM- CSF), cytokine-inducing molecules (e.g., LelF), costimulatory molecules, or for HTL responses, pan-DR binding proteins (PADRE™, Epimmune, San Diego, CA). Helper (HTL) epitopes can be joined to intracellular targeting signals and expressed separately from expressed CTL epitopes; this allows direction of the HTL epitopes to a cell compartment different than that of the CTL epitopes. If required, this could facilitate more efficient entry of HTL epitopes into the HLA class II pathway, thereby improving HTL induction. In contrast to HTL or CTL induction, specifically decreasing the immune response by co-expression of immunosuppressive molecules (e.g. TGF-β) may be beneficial in certain diseases.
Therapeutic quantities of plasmid DNA can be produced for example, by fermentation in £ coli, followed by purification. Aliquots from the working cell bank are used to inoculate growth medium, and grown to saturation in shaker flasks or a bioreactor according to well-known techniques. Plasmid DNA can be purified using standard biosepar ation technologies such as solid phase anion-exchange resins supplied by QIAGEN, Inc. (Valencia, California). If required, supercoiled DNA can be isolated from the open circular and linear forms using gel electrophoresis or other methods.
Purified plasmid DNA can be prepared for injection using a variety of formulations. The simplest of these is reconstitution of lyophilized DNA in sterile phosphate-buffer saline (PBS). This approach, known as "naked DNA," is currently being used for intramuscular (IM) administration in clinical trials. To maximize the immunotherapeutic effects of minigene DNA vaccines, an alternative method for formulating purified plasmid DNA may be desirable. A variety of methods have been described, and new techniques may become available. Cationic lipids, glycolipids, and fusogenic liposomes can
also be used in the formulation (see, e.g., as described by WO 93/24640; Mannino & Gould-Fogerite, BioTechniques 6(7): 682 (1988); U.S. Pat No. 5,279,833; WO 91/06309; and Feigner, ef al, Proc. Nat'l Acad. Sci. USA 84:7413 (1987). In addition, peptides and compounds referred to collectively as protective, interactive, non-condensing compounds (PINC) could also be complexed to purified plasmid DNA to influence variables such as stability, intramuscular dispersion, or trafficking to specific organs or cell types.
Target cell sensitization can be used as a functional assay for expression and HLA class I presentation of minigene-encoded CTL epitopes. For example, the plasmid DNA is introduced into a mammalian cell line that is suitable as a target for standard CTL chromium release assays. The transfection method used will be dependent on the final formulation. Electroporation can be used for "naked" DNA, whereas cationic lipids allow direct in vitro transfection. A plasmid expressing green fluorescent protein (GFP) can be co-transfected to allow enrichment of transfected cells using fluorescence activated cell sorting (FACS). These cells are then chromιum-51 (51Cr) labeled and used as target cells for epitope-spedfic CTL lines; cytolysis, detected by 51Cr release, indicates both production of, and HLA presentation of, minigene-encoded CTL epitopes. Expression of HTL epitopes may be evaluated in an analogous manner using assays to assess HTL activity.
In vivo immunogenicity is a second approach for functional testing of minigene DNA formulations. Transgenic mice expressing appropriate human HLA proteins are immunized with the DNA product. The dose and route of administration are formulation dependent (e.g., IM for DNA in PBS, intraperitoneal (i.p.) for lipid-complexed DNA). Twenty-one days after immunization, splenocytes are harvested and restimulated for one week in the presence of peptides encoding each epitope being tested. Thereafter, for CTL effector cells, assays are conducted for cytolysis of peptide-loaded, 51Cr-labeled target cells using standard techniques. Lysis of target cells that were sensitized by HLA loaded with peptide epitopes, corresponding to minigene-encoded epitopes, demonstrates DNA vaccine function for in vivo induction of CTLs. Immunogenicity of HTL epitopes is confirmed in transgenic mice in an analogous manner.
Alternatively, the nucleic acids can be administered using ballistic delivery as described, for instance, in U.S. Patent No. 5,204,253. Using this technique, particles comprised solely of DNA are administered. In a further alternative embodiment, DNA can be adhered to particles, such as gold particles.
Minigenes can also be delivered using other bacterial or viral delivery systems well known in the art, e.g., an expression construct encoding epitopes of the invention can be incorporated into a viral vector such as vaccinia. X.C.2. Combinations of CTL Peptides with Helper Peptides
Vaccine compositions comprising CTL peptides of the invention can be modified, e.g., analoged, to provide desired attributes, such as improved serum half life, broadened population coverage or enhanced immunogenicity.
For instance, the ability of a peptide to induce CTL activity can be enhanced by linking the peptide to a sequence which contains at least one epitope that is capable of inducing a T helper cell response. Although a CTL peptide can be directly linked to a T helper peptide, often CTL epitope/HTL epitope conjugates are linked by a spacer molecule. The spacer is typically comprised of relatively small, neutral molecules, such as amino acids or amino acid imetics, which are substantially uncharged under physiological conditions. The spacers are typically selected from, e.g., Ala, Gly, or other neutral spacers of nonpolar amino acids or neutral polar amino acids. It will be understood that the optionally present spacer need not be comprised of the same residues and thus may be a hetero- or homo-oligomer. When present, the spacer will usually be at least one or two residues, more usually three to six residues and sometimes 10 or more residues. The CTL peptide epitope can be linked to the T helper peptide epitope either directly or via a spacer either at the amino or carboxy terminus of the CTL peptide. The amino terminus of either the immunogenic peptide or the T helper peptide may be acylated.
In certain embodiments, the T helper peptide is one that is recognized by T helper cells present in a majority of a genetically diverse population This can be accomplished by selecting peptides that bind to many, most, or all of the HLA class II molecules. Examples of such amino acid bind many HLA Class II molecules include sequences from antigens such as fefanus toxoid at positions 830-843 (QYIKANSKFIGITE; SEQ ID NO: 29), Plasmodium falciparum circumsporozoite (CS) protein at positions 378-398 (DIEKKIAKMEKASSVFNWNS; SEQ ID NO: 30), and Streptococcus 18kD protein at positions 116-131 (GAVDSILGGVATYGAA; SEQ ID NO: 31). Other examples include peptides bearing a DR 14-7 supermotif, or either of the DR3 motifs.
Alternatively, it is possible to prepare synthetic peptides capable of stimulating T helper lymphocytes, in a loosely HLA-restricted fashion, using amino acid sequences not found in nature (see, e.g., PCT publication WO 95/07707). These synthetic compounds called Pan-DR-binding epitopes (e.g., PADRE™, Epimmune, Inc., San Diego, CA) are designed, most preferably, to bind most HLA-DR (human HLA class II) molecules. For instance, a pan-DR-binding epitope peptide having the formula: AKXVAAWTLKAAA (SEQ ID NO: 32), where "X" is either cyclohexylalanine, phenylalanine, or tyrosine, and a is either o-alanine or L-alanine, has been found to bind to most HLA-DR alleles, and to stimulate the response of T helper lymphocytes from most individuals, regardless of their HLA type. An alternative of a pan-DR binding epitope comprises all "L" natural amino acids and can be provided in the form of nucleic acids that encode the epitope.
HTL peptide epitopes can also be modified to alter their biological properties. For example, they can be modified to include r>amino acids to increase their resistance to proteases and thus extend their serum half life, or they can be conjugated to other molecules such as lipids, proteins, carbohydrates, and the like to increase their biological activity. For example, a T helper peptide can be conjugated to one or more palmitic acid chains at either the amino or carboxyl termini. X.C.3. Combinations of CTL Peptides with T Cell Priming Agents
In some embodiments it may be desirable to include in the pharmaceutical compositions of the invention at least one component which primes B lymphocytes or T lymphocytes. Lipids have been identified as agents capable of priming CTL in vivo. For example, palmitic acid residues can be attached to the ε-and α- amino groups of a lysine residue and then linked, e.g., via one or more linking residues such as Gly, Gly-Gly-, Ser, Ser-Ser, or the like, to an immunogenic peptide. The lipidated peptide can then be administered either directly in a micelle or particle, incorporated into a liposcme, or emulsified in an adjuvant, e.g., incomplete Freund's adjuvant. In a preferred embodiment, a particularly effective immunogenic composition comprises palmitic acid attached to ε- and α- amino groups of Lys, which is attached via linkage, e.g., Ser-Ser, to the amino terminus of the immunogenic peptide.
As another example of lipid priming of CTL responses, £ coli lipoproteins, such as tripalmitoyl-S- glycerylcysteinlyseryl- serine (P3CSS) can be used to prime virus specific CTL when covalently attached to an appropriate peptide (see, e.g., Deres, etal, Nature 342:561, 1989). Peptides of the invention can be coupled to P3CSS, for example, and the lipopeptide administered to an individual to prime specifically an immune response to the target antigen. Moreover, because the induction of neutralizing antibodies can also be primed with P3CSS-conjugated epitopes, two such compositions can be combined to more effectively elicit both humoral and cell-mediated responses.
XC.4. Vaccine Compositions Comprising DC Pulsed with CTL and/or HTL Peptides
An embodiment of a vaccine composition in accordance with the invention comprises ex vivo administration of a cocktail of epitope-bearing peptides to PBMC, or isolated DC therefrom, from the patient's blood. A pharmaceutical to facilitate harvesting of DC can be used, such as Progenipoietin™ (Pharmacia-Monsanto, St. Louis, MO) or GM-CSF/IL4. After pulsing the DC with peptides and prior to reinfusion into patients, the DC are washed to remove unbound peptides. In this embodiment, a vacα'ne comprises peptide-pulsed DCs which present the pulsed peptide epitopes complexed with HLA molecules on their surfaces.
The DC can be pulsed ex vivo with a cocktail of peptides, some of which stimulate CTL responses to 24P4C12. Optionally, a helper T cell (HTL) peptide, such as a natural or artificial loosely restricted HLA Class II peptide, can be included to facilitate the CTL response. Thus, a vaccine in accordance with the invention is used to treat a cancer which expresses or overexpresses 24P4C12.
X.D. Adoptive Immunotherapy
Antigenic 24P4C12-related peptides are used to elicit a CTL and/or HTL response ex vivo, as well. The resulting CTL or HTL cells, can be used to treat tumors in patients that do not respond to other conventional forms of therapy, or will not respond to a therapeutic vaccine peptide or nucleic acid in accordance with the invention. Ex vivo CTL or HTL responses to a particular antigen are induced by incubating in tissue culture the patient's, or genetically compatible, CTL or HTL precursor cells together with a source of antigen-presenting cells (APC), such as dendritic cells, and the appropriate immunogenic peptide. After an appropriate incubation time (typically about 7-28 days), in which the precursor cells are activated and expanded into effector cells, the cells are infused back into the patient, where they will destroy (CTL) or facilitate destruction (HTL) of their spedfic target cell (e.g., a tumor cell). Transfected dendritic cells may also be used as antigen presenting cells.
X.E. Administration of Vaccines for Therapeutic or Prophylactic Purposes
Pharmaceutical and vaccine compositions of the invention are typically used to treat and/or prevent a cancer that expresses or overexpresses 24P4C12. In therapeutic applications, peptide and/or nucleic acid compositions are administered to a patient in an amount sufficient to elidt an effective B cell, CTL and/or HTL response to the antigen and to cure or at least partially arrest or slow symptoms and/or complications. An amount adequate to accomplish this is defined as "therapeutically effective dose." Amounts effective for this use will depend on, e.g., the particular composition administered, the manner of administration, the stage and severity of the disease being treated, the weight and general state of health of the patient, and the judgment of the prescribing physician.
For pharmaceutical compositions, the immunogenic peptides of the invention, or DNA encoding them, are generally administered to an individual already bearing a tumor that expresses 24P4C12. The peptides or DNA encoding them can be administered individually or as fusions of one or more peptide sequences. Patients can be treated with the immunogenic peptides separately or in conjunction with other treatments, such as surgery, as appropriate.
For therapeutic use, administration should generally begin at the first diagnosis of 24P4C12-associated cancer. This is followed by boosting doses until at least symptoms are substantially abated and for a period thereafter. The embodiment of the vaccine composition (i.e., including, but not limited to embodiments such as peptide cocktails, polyepitopic polypeptides, minigenes, or TAA-specific CTLs or pulsed dendritic cells) delivered to the patient may vary according to the stage of the disease or the patient's health status. For example, in a patient with a tumor that expresses 24P4C12, a vacdne comprising 24P4C12-specific CTL may be more efficacious in killing tumor cells in patient with advanced disease than alternative embodiments.
It is generally important to provide an amount of the peptide epitope delivered by a mode of administration sufficient to stimulate effectively a cytotoxic T cell response; compositions which stimulate helper T cell responses can also be given in accordance with this embodiment of the invention.
The dosage for an initial therapeutic immunization generally occurs in a unit dosage range where the lower value is about 1 , 5, 50, 500, or 1 ,000 μg and the higher value is about 10,000; 20,000; 30,000; or 50,000 μg. Dosage values for a human typically range from about 500 μg to about 50,000 μg per 70 kilogram patient. Boosting dosages of between about 1.0 μg to about 50,000 μg of peptide pursuant to a boosting regimen over weeks to months may be administered depending
upon the patient's response and condition as determined by measuring the specific activity of CTL and HTL obtained from the patient's blood. Administration should continue until at least clinical symptoms or laboratory tests indicate that the neoplasia, has been eliminated or reduced and for a period thereafter. The dosages, routes of administration, and dose schedules are adjusted in accordance with methodologies known in the art.
In certain embodiments, the peptides and compositions of the present invention are employed in serious disease states, that is, life-threatening or potentially life threatening situations. In such cases, as a result of the minimal amounts of extraneous substances and the relative nontoxic nature of the peptides in preferred compositions of the invention, it is possible and may be felt desirable by the treating physician to administer substantial excesses of these peptide compositions relative to these stated dosage amounts.
The vaccine compositions of the invention can also be used purely as prophylactic agents. Generally the dosage for an initial prophylactic immunization generally occurs in a unit dosage range where the lower value is about 1 , 5, 50, 500, or 1000 μg and the higher value is about 10,000; 20,000; 30,000; or 50,000 μg. Dosage values for a human typically range from about 500 μg to about 50,000 μg per 70 kilogram patient. This is followed by boosting dosages of between about 1.0 μg to about 50,000 μg of peptide administered at defined intervals from about four weeks to six months after the initial administration of vaccine. The immunogenicity of the vaccine can be assessed by measuring the specific activity of CTL and HTL obtained from a sample of the patient's blood.
The pharmaceutical compositions for therapeutic treatment are intended for parenteral, topical, oral, nasal, intrathecal, or local (e.g. as a cream or topical ointment) administration. Preferably, the pharmaceutical compositions are administered parentally, e.g., intravenously, subcutaneously, intradermally, or intramuscularly. Thus, the invention provides compositions for parenteral administration which comprise a solution of the immunogenic peptides dissolved or suspended in an acceptable carrier, preferably an aqueous carrier.
A variety of aqueous carriers may be used, e.g., water, buffered water, 0.8% saline, 0.3% glycine, hyaluronic add and the like. These compositions may be sterilized by conventional, well-known sterilization techniques, or may be sterile filtered. The resulting aqueous solutions may be packaged for use as is, or lyophilized, the lyophilized preparation being combined with a sterile solution prior to administration.
The compositions may contain pharmaceutically acceptable auxiliary substances as required to approximate physiological conditions, such as pH-adjusting and buffering agents, tonicity adjusting agents, wetting agents, preservatives, and the like, for example, sodium acetate, sodium lactate, sodium chloride, potassium chloride, caldum chloride, sorbitan monolaurate, triethanolamine oleate, efc.
The concentration of peptides of the invention in the pharmaceutical formulations can vary widely, i.e., from less than about 0.1%, usually at or at least about 2% to as much as 20% to 50% or more by weight, and will be selected primarily by fluid volumes, viscosities, efc, in accordance with the particular mode of administration selected.
A human unit dose form of a composition is typically included in a pharmaceutical composition that comprises a human unit dose of an acceptable carrier, in one embodiment an aqueous carrier, and is administered in a volume/quantity that is known by those of skill in the art to be used for administration of such compositions to humans (see, e.g., Remington's Pharmaceutical Sciences, 17* Edition, A. Gennaro, Editor, Mack Publishing Co., Easton, Pennsylvania, 1985). For example a peptide dose for initial immunization can be from about 1 to about 50,000 μg, generally 100-5,000 μg, for a 70 kg patient. For example, for nucleic adds an initial immunization may be performed using an expression vector in the form of naked nucleic acid administered IM (or SC or ID) in the amounts of 0.5-5 mg at multiple sites. The nudeic acid (0.1 to 1000 μg) can also be administered using a gene gun. Following an incubation period of 34 weeks, a booster dose is then administered. The booster can be recombinant fowlpox virus administered at a dose of 5-107 to 5x109 pfu.
For antibodies, a treatment generally involves repeated administration of the anti-24P4C12 antibody preparation, via an acceptable route of administration such as intravenous injection (IV), typically at a dose in the range of about 0.1 to about 10 mg/kg body weight. In general, doses in the range of 10-500 mg mAb per week are effective and well tolerated. Moreover, an initial loading dose of approximately 4 mg/kg patient body weight IV, followed by weekly doses of about 2 mg/kg IV of the anti- 24P4C12 mAb preparation represents an acceptable dosing regimen. As appreciated by those of skill in the art, various factors can influence the ideal dose in a particular case. Such factors include, for example, half life of a composition, the binding affinity of an Ab, the immunogenicity of a substance, the degree of 24P4C12 expression in the patient, the extent of circulating shed 24P4C12 antigen, the desired steady-state concentration level, frequency of treatment, and the influence of chemotherapeutic or other agents used in combination with the treatment method of the invention, as well as the health status of a particular patient. Non-limiting preferred human unit doses are, for example, 500μg - 1mg, 1mg - 50mg, 50mg - 100mg, 100mg - 200mg, 200mg - 300mg, 400mg - 500mg, 500mg - 600mg, 600mg - 700mg, 700mg - 800mg, 800mg - 900mg, 900mg - 1g, or 1mg - 700mg. In certain embodiments, the dose is in a range of 2-5 mg/kg body weight, e.g., with follow on weekly doses of 1-3 mg/kg; 0.5mg, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10mg/kg body weight followed, e.g., in two, three or four weeks by weekly doses; 0.5 - 1 Omg/kg body weight, e.g., followed in two, three or four weeks by weekly doses; 225, 250, 275, 300, 325, 350, 375, 400mg m2 of body area weekly; 1-600mg m2 of body area weekly; 225400mg m2 of body area weekly; these does can be followed by weekly doses for 2, 3, 4, 5, 6, 7, 8, 9, 19, 11 , 12 or more weeks.
In one embodiment, human unit dose forms of polynucleotides comprise a suitable dosage range or effective amount that provides any therapeutic effect. As appreciated by one of ordinary skill in the art a therapeutic effect depends on a number of factors, including the sequence of the polynucleotide, molecular weight of the polynucleotide and route of administration. Dosages are generally selected by the physidan or other health care professional in accordance with a variety of parameters known in the art, such as severity of symptoms, history of the patient and the like. Generally, for a polynucleotide of about 20 bases, a dosage range may be selected from, for example, an independently selected lower limit such as about 0.1 , 0,25, 0.5, 1 , 2, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 200, 300, 400 or 500 mg/kg up to an independently selected upper limit, greater than the lower limit of about 60, 80, 100, 200, 300, 400, 500, 750, 1000, 1500, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000 or 10,000 mg/kg. For example, a dose may be about any of the following: 0.1 to 100 mg/kg, 0.1 to 50 mg kg, 0.1 to 25 mg/kg, 0.1 to 10 mg/kg, 1 to 500 mg kg, 100 to 400 mg/kg, 200 to 300 mg/kg, 1 to 100 mg/kg, 100 to 200 mg/kg, 300 to 400 mg/kg, 400 to 500 mg/kg, 500 to 1000 mg/kg, 500 to 5000 mg/kg, or 500 to 10,000 mg/kg. Generally, parenteral routes of administration may require higher doses of polynudeotide compared to more direct application to the nucleotide to diseased tissue, as do polynucleotides of increasing length.
In one embodiment, human unit dose forms of T-cells comprise a suitable dosage range or effective amount that( provides any therapeutic effect. As appreciated by one of ordinary skill in the art, a therapeutic effect depends on a number of factors. Dosages are generally selected by the physician or other health care professional in accordance with a variety of parameters known in the art, such as severity of symptoms, history of the patient and the like. A dose may be about 104 cells to about 106 cells, about 10δ cells to about 108 cells, about 108 to about 1011 cells, or about 108 to about 5 x 1010 cells. A dose may also about 106 cells/m2 to about 1010 cells/m2, or about 106 cells/m2 to about 108 cells/m2 .
Proteins(s) of the invention, and/or nucleic acids encoding the protein(s), can also be administered via liposomes, which may also serve to: 1) target the proteins(s) to a particular tissue, such as lymphoid tissue; 2) to target selectively to diseases cells; or, 3) to increase the half-life of the peptide composition. Liposomes indude emulsions, foams, micelles, insoluble monolayers, liquid crystals, phospholipid dispersions, lamellar layers and the like. In these preparations, the peptide to be delivered is incorporated as part of a liposome, alone or in conjunction with a molecule which binds to a receptor prevalent among lymphoid ceils, such as monodonal antibodies which bind to the CD45 antigen, or with other therapeutic or immunogenic compositions. Thus, liposomes either filled or decorated with a desired peptide of the invention
can be directed to the site of lymphoid cells, where the liposomes then deliver the peptide compositions. Liposomes for use in accordance with the invention are formed from standard vesicle-forming lipids, which generally include neutral and negatively charged phospholipids and a sterol, such as cholesterol. The selection of lipids is generally guided by consideration of, e.g., liposome size, acid lability and stability of the liposomes in the blood stream. A variety of methods are available for preparing liposomes, as described in, e.g., Szoka, ef al, Ann. Rev. Biophys. Bioeng. 9:467 (1980), and U.S. Patent Nos. 4,235,871, 4,501,728, 4,837,028, and 5,019,369.
For targeting cells of the immune system, a ligand to be incorporated into the liposome can include, e.g., antibodies or fragments thereof specific for cell surface determinants of the desired immune system cells. A liposome suspension containing a peptide may be administered intravenously, locally, topically, efc. in a dose which varies according to, inter alia, the manner of administration, the peptide being delivered, and the stage of the disease being treated.
For solid compositions, conventional nontoxic solid carriers may be used which include, for example, pharmaceutical grades of mannitol, lactose, starch, magnesium stearate, sodium saccharin, talcum, cellulose, glucose, sucrose, magnesium carbonate, and the like. For oral administration, a pharmaceutically acceptable nontoxic composition is formed by incorporating any of the normally employed excipients, such as those carriers previously listed, and generally 10- 95% of active ingredient, that is, one or more peptides of the invention, and more preferably at a concentration of 25%-75%.
For aerosol administration, immunogenic peptides are preferably supplied in finely divided form along with a surfactant and propellant. Typical percentages of peptides are about 0.01 %-20% by weight, preferably about 1 %-10%. The surfadant must, of course, be nontoxic, and preferably soluble in the propellant. Representative of such agents are the esters or partial esters of fatty acids containing from about 6 to 22 carbon atoms, such as caproic, octanoic, lauric, palmitic, stearic, linoleic, linolenic, olesteric and oleic acids with an aliphatic polyhydric alcohol or its cyclic anhydride. Mixed esters, such as mixed or natural glycerides may be employed. The surfactant may constitute about 0.1 %-20% by weight of the composition, preferably about 0.25-5%. The balance of the composition is ordinarily propellant. A carrier can also be induded, as desired, as with, e.g., lecithin for intranasal delivery.
XI.) Diagnostic and Prognostic Embodiments of 24P4C12.
As disclosed herein, 24P4C12 polynucleotides, polypeptides, reactive cytotoxic T cells (CTL), reactive helper T cells (HTL) and anti-polypeptide antibodies are used in well known diagnostic, prognostic and therapeutic assays that examine conditions associated with dysregulated cell growth such as cancer, in particular the cancers listed in Table I (see, e.g., both its specific pattern of tissue expression as well as its overexpression in certain cancers as described for example in the Example entitled "Expression analysis of 24P4C12 in normal tissues, and patient specimens").
24P4C12 can be analogized to a prostate associated antigen PSA, the archetypal marker that has been used by medical practitioners for years to identify and monitor the presence of prostate cancer (see, e.g., Merrill ef al, J. Urol. 163(2): 503-5120 (2000); Polascik ef al, J, Urol. Aug; 162(2):293-306 (1999) and Fortieref al, J. Nat. Cancer Inst.91(19): 1635- 1640(1999)). A variety of other diagnostic markers are also used in similar contexts including p53 and K-ras (see, e.g., Tulchinsky ef al, Int J Mol Med 1999 Jul 4(1):99-102 and Minimoto ef al, Cancer Detect Prev 2000;24(1):1-12). Therefore, this disclosure of 24P4C12 polynucleotides and polypeptides (as well as 24P4C12 polynucleotide probes and anti-24P4C12 antibodies used to identify the presence of these molecules) and their properties allows skilled artisans to utilize these molecules in methods that are analogous to those used, for example, in a variety of diagnostic assays directed to examining conditions associated with cancer.
Typical embodiments of diagnostic methods which utilize the 24P4C12 polynudeotides, polypeptides, reactive T cells and antibodies are analogous to those methods from well-established diagnostic assays, which employ, e.g., PSA polynudeotides, polypeptides, reactive T cells and antibodies. For example, just as PSA polynudeotides are used as probes
(for example in Northern analysis, see, e.g., Sharief et al, Biochem. Mol. Biol. Int. 33(3):567-74(1994)) and primers (for example in PCR analysis, see, e.g., Okegawa et al. . Urol. 163(4): 1189-1190 (2000)) to observe the presence and/or the level of PSA mRNAs in methods of monitoring PSA overexpression or the metastasis of prostate cancers, the 24P4C12 polynucleotides described herein can be utilized in the same way to detect 24P4C12 overexpression or the metastasis of prostate and other cancers expressing this gene. Alternatively, just as PSA polypeptides are used to generate antibodies spedfic for PSA which can then be used to observe the presence and/or the level of PSA proteins in methods to monitor PSA protein overexpression (see, e.g., Stephan ef a/., Urology 55(4):560-3 (2000)) or the metastasis of prostate cells (see, e.g., Alanen etal, Pathol. Res. Pract 192(3):233-7 (1996)), the 24P4C12 polypeptides described herein can be utilized to generate antibodies for use in detecting 24P4C12 overexpression or the metastasis of prostate cells and cells of other cancers expressing this gene.
Specifically, because metastases involves the movement of cancer cells from an organ of origin (such as the lung or prostate gland etc.) to a different area of the body (such as a lymph node), assays which examine a biological sample for the presence of cells expressing 24P4C12 polynucleotides and/or polypeptides can be used to provide evidence of metastasis. For example, when a biological sample from tissue that does not normally contain 24P4C12-expressing cells (lymph node) is found to contain 24P4C12-expressing cells such as the 24P4C12 expression seen in LAPC4 and LAPC9, xenografts isolated from lymph node and bone metastasis, respectively, this finding is indicative of metastasis.
Alternatively 24P4C12 polynucleotides and/or polypeptides can be used to provide evidence of cancer, for example, when cells in a biological sample that do not normally express 24P4C12 or express 24P4C12 at a different level are found to express 24P4C12 or have an increased expression of 24P4C12 (see, e.g., the 24P4C12 expression in the cancers listed in Table I and in patient samples etc. shown in the accompanying Figures). In such assays, artisans may further wish to generate supplementary evidence of metastasis by testing the biological sample for the presence of a second tissue restricted marker (in addition to 24P4C12) such as PSA, PSCA etc. (see, e.g., Alanen etal, Pathol. Res. Pract. 192(3): 233- 237 (1996)).
Just as PSA polynucleotide fragments and polynucleotide variants are employed by skilled artisans for use in methods of monitoring PSA, 24P4C12 polynucleotide fragments and polynucleotide variants are used in an analogous manner. In particular, typical PSA polynucleotides used in methods of monitoring PSA are probes or primers which consist of fragments of the PSA cDNA sequence. Illustrating this, primers used to PCR amplify a PSA polynucleotide must include less than the whole PSA sequence to function in the polymerase chain reaction. In the context of such PCR reactions, skilled artisans generally create a variety of different polynucleotide fragments that can be used as primers in order to amplify different portions of a polynucleotide of interest or to optimize amplification reactions (see, e.g., Caetano-Anolles, G. Biotechniques 25(3): 472-476, 478480 (1998); Robertson etal, Methods Mol, Biol.98:121-154 (1998)). An additional illustration of the use of such fragments is provided in the Example entitled "Expression analysis of 24P4C12 in normal tissues, and patient specimens," where a 24P4C12 polynudeotide fragment is used as a probe to show the expression of 24P4C12 RNAs in cancer cells. In addition, variant polynucleotide sequences are typically used as primers and probes for the corresponding mRNAs in PCR and Northern analyses (see, e.g., Sawai ef al, Fetal Diagn. Ther. 1996 Nov-Dec 11(6):407-13 and Current Protocols In Molecular Biology, Volume 2, Unit 2, Frederick M. Ausubel ef al. eds., 1995)). Polynucleotide fragments and variants are useful in this context where they are capable of binding to a target polynucleotide sequence (e.g., a 24P4C12 polynucleotide shown in Figure 2 or variant thereof) under conditions of high stringency.
Furthermore, PSA polypeptides which contain an epitope that can be recognized by an antibody or T cell that specifically binds to that epitope are used in methods of monitoring PSA. 24P4C12 polypeptide fragments and polypeptide analogs or variants can also be used in an analogous manner. This practice of using polypeptide fragments or polypeptide variants to generate antibodies (such as anti-PSA antibodies or T cells) is typical in the art with a wide variety of systems
such as fusion proteins being used by practitioners (see, e.g., Current Protocols In Molecular Biology, Volume 2, Unit 16, Frederick M. Ausubel ef a/, eds., 1995). In this context, each epitope(s) functions to provide the architecture with which an antibody or T cell is reactive. Typically, skilled artisans create a variety of different polypeptide fragments that can be used in order to generate immune responses specific for different portions of a polypeptide of interest (see, e.g., U.S. Patent No. 5,840,501 and U.S. Patent No. 5,939,533). For example it may be preferable to utilize a polypeptide comprising one of the 24P4C12 biological motifs discussed herein or a motif-bearing subsequence which is readily identified by one of skill in the art based on motifs available in the art. Polypeptide fragments, variants or analogs are typically useful in this context as long as they comprise an epitope capable of generating an antibody or T cell specific for a target polypeptide sequence (e.g. a 24P4C12 polypeptide shown in Figure 3).
As shown herein, the 24P4C12 polynucleotides and polypeptides (as well as the 24P4C12 polynucleotide probes and anti-24P4C12 antibodies or T cells used to identify the presence of these molecules) exhibit spedfic properties that make them useful in diagnosing cancers such as those listed in Table I. Diagnostic assays that measure the presence of 24P4C12 gene products, in order to evaluate the presence or onset of a disease condition described herein, such as prostate cancer, are used to identify patients for preventive measures or further monitoring, as has been done so successfully with PSA. Moreover, these materials satisfy a need in the art for molecules having similar or complementary characteristics to PSA in situations where, for example, a definite diagnosis of metastasis of prostatic origin cannot be made on the basis of a test for PSA alone (see, e.g., Alanen et al, Pathol. Res. Pract. 192(3): 233-237 (1996)), and consequently, materials such as 24P4C12 polynucleotides and polypeptides (as well as the 24P4C12 polynucleotide probes and anti- 24P4C12 antibodies used to identify the presence of these molecules) need to be employed to confirm a metastases of prostatic origin.
Finally, in addition to their use in diagnostic assays, the 24P4C12 polynucleotides disclosed herein have a number of other utilities such as their use in the identification of oncogenetic associated chromosomal abnormalities in the chromosomal region to which the 24P4C12 gene maps (see the Example entitled "Chromosomal Mapping of 24P4C12" below). Moreover, in addition to their use in diagnostic assays, the 24P4C12-related proteins and polynucleotides disclosed herein have other utilities such as their use in the forensic analysis of tissues of unknown origin (see, e.g., Takahama K Forensic Sci Iπt 1996 Jun 28;80(1-2): 63-9).
Additionally, 24P4C12-related proteins or polynucleotides of the invention can be used to treat a pathologic condition characterized by the over-expression of 24P4C12. For example, the amino acid or nucleic acid sequence of Figure 2 or Figure 3, or fragments of either, can be used to generate an immune response to a 24P4C12 antigen. Antibodies or other molecules that react with 24P4C12 can be used to modulate the function of this molecule, and thereby provide a therapeutic benefit.
XII.) Inhibition of 24P4C12 Protein Function
The invention includes various methods and compositions for inhibiting the binding of 24P4C12 to its binding partner or its association with other protein(s) as well as methods for inhibiting 24P4C12 function.
XII.A.) Inhibition of 24P4C12 With Intracellular Antibodies
In one approach, a recombinant vector that encodes single chain antibodies that spedfically bind to 24P4C12 are introduced into 24P4C12 expressing cells via gene transfer technologies. Accordingly, the encoded single chain anti- 24P4C12 antibody is expressed intracellularly, binds to 24P4C12 protein, and thereby inhibits its function. Methods for engineering such intracellular single chain antibodies are well known. Such intracellular antibodies, also known as "intrabodies", are specifically targeted to a particular compartment within the cell, providing control over where the inhibitory
activity of the treatment is focused This technology has been successfully applied in the art (for review, see Richardson and Marasco, 1995, TIBTECH vol 13) Infrabodies have been shown to virtually eliminate the expression of otherwise abundant cell surface receptors (see, e g Richardson et al, 1995, Proc Natl Acad Sci USA 92 3137-3141, Beerli ef al, 1994, J Biol Chem 289 23931-23936, Deshane ef al , 1994, Gene Ther 1 332-337)
Single chain antibodies comprise the vanable domains of the heavy and light chain joined by a flexible linker polypeptide, and are expressed as a single polypeptide Optionally, single chain antibodies are expressed as a single chain variable region fragment joined to the light chain constant region Weil-known intracellular trafficking signals are engineered into recombinant polynucleotide vectors encoding such single chain antibodies in order to target precisely the intrabody to the desired intracellular compartment For example, infrabodies targeted to the endoplasmic reticulum (ER) are engineered to incorporate a leader peptide and, optionally, a C-terminal ER retention signal, such as the KDEL am o acid motif Infrabodies intended to exert activity in the nudeus are engineered to indude a nuclear localization signal Lipid moieties are joined to infrabodies in order to tether the intrabody to the cytosolic side of the plasma membrane Infrabodies can also be targeted to exert function in the cytosol For example, cytosolic infrabodies are used to sequester factors within the cytosol, thereby preventing them from being transported to their natural cellular destination
In one embodiment, infrabodies are used to capture 24P4C12 in the nucleus, thereby preventing its activity within the nudeus Nuclear targeting signals are engineered into such 24P4C12 infrabodies in order to achieve the desired targeting Such 24P4C12 infrabodies are designed to bind specifically to a particular 24P4C12 domain In another embodiment, cytosolic infrabodies that specifically bind to a 24P4C12 protein are used to prevent 24P4C12 from gaining access to the nucleus, thereby preventing it from exerting any biological activity within the nucleus (e g , preventing 24P4C12 from forming transcription complexes with other factors)
In order to speαfically direct the expression of such infrabodies to particular cells, the transcription of the intrabody is placed under the regulatory control of an appropnate tumor-specific promoter and/or enhancer In order to target intrabody expression speαfically to prostate, for example the PSA promoter and/or promoter/enhancer can be utilized (See, for example, U S Patent No 5,919,652 issued 6 July 1999)
XII.B.) Inhibition of 24P4C12 with Recombinant Proteins
In another approach, recombinant molecules bind to 24P4C12 and thereby inhibit 24P4C12 function For example, these recombinant molecules prevent or inhibit 24P4C12 from accessing/binding to its binding partner(s) or associating with other proteιn(s) Such recombinant mdecules can, for example, contain the reactive part(s) of a 24P4C12 specific antibody molecule In a particular embodiment, the 24P4C12 binding domain of a 24P4C12 binding partner is engineered into a dimeπc fusion protein, whereby the fusion protein compnses two 24P4C12 ligand binding domains linked to the Fc portion of a human IgG, such as human lgG1 Such IgG portion can contain, for example, the CH2 and CH3 domains and the hinge region, but not the CH1 domain Such dimenc fusion proteins are administered in soluble form to patients suffering from a cancer associated with the expression of 24P4C12 whereby the dimenc fusion protein specifically binds to 24P4C12 and blocks 24P4C12 interaction with a binding partner Such dimenc fusion proteins are further combined into multimeπc proteins using known antibody linking technologies
XII C.) Inhibition of 24P4C12 Transcription or Translation
The present invention also compnses vaπous methods and compositions for inhibiting the transcription of the 24P4C12 gene Similarly, the invention also provides methods and compositions for inhibiting the translation of 24P4C12 mRNA into protein
In one approach, a method of inhibiting the transcription of the 24P4C12 gene comprises contacting the 24P4C12 gene with a 24P4C12 antisense polynudeotide. In another approach, a method of inhibiting 24P4C12 mRNA translation comprises contacting a 24P4C12 mRNA with an antisense polynucleotide. In another approach, a 24P4C12 specific ribozyme is used to cleave a 24P4C12 message, thereby inhibiting translation. Such antisense and ribozyme based methods can also be directed to the regulatory regions of the 24P4C12 gene, such as 24P4C12 promoter and/or enhancer elements. Similarly, proteins capable of inhibiting a 24P4C12 gene transσiption factor are used to inhibit 24P4C12 mRNA transcription. The various polynucleotides and compositions useful in the aforementioned methods have been described above. The use of antisense and ribozyme molecules to inhibit transcription and translation is well known in the art.
Other factors that inhibit the transcription of 24P4C12 by interfering with 24P4C12 transcriptional activation are also useful to freat cancers expressing 24P4C12. Similarly, fadors that interfere with 24P4C12 processing are useful to treat cancers that express 24P4C12. Cancer treatment methods utilizing such factors are also within the scope of the invention.
XII.D.) General Considerations for Therapeutic Strategies
Gene fransfer and gene therapy technologies can be used to deliver therapeutic polynudeotide molecules to tumor cells synthesizing 24P4C12 (i.e., antisense, ribozyme, polynudeotides encoding infrabodies and other 24P4C12 inhibitory molecules). A number of gene therapy approaches are known in the art. Recombinant vectors encoding 24P4C12 antisense polynudeotides, ribozymes, factors capable of interfering with 24P4C12 transcription, and so forth, can be delivered to target tumor cells using such gene therapy approaches.
The above therapeutic approaches can be combined with any one of a wide variety of surgical, chemotherapy or radiation therapy regimens. The therapeutic approaches of the invention can enable the use of reduced dosages of chemotherapy (or other therapies) and/or less frequent administration, an advantage for all patients and particularly for those that do not tolerate the toxidty of the chemotherapeutic agent well.
The anti-tumor activity of a particular composition (e.g., antisense, ribozyme, intrabody), or a combination of such compositions, can be evaluated using various in vitro and in vivo assay systems. In vitro assays that evaluate therapeutic activity indude cell growth assays, soft agar assays and other assays indicative of tumor promoting activity, binding assays capable of determining the extent to which a therapeutic composition will inhibit the binding of 24P4C12 to a binding partner, etc.
In vivo, the effect of a 24P4C12 therapeutic composition can be evaluated in a suitable animal model. For example, xenogenic prostate cancer models can be used, wherein human prostate cancer explants or passaged xenograft tissues are introduced into immune compromised animals, such as nude or SCID mice (Klein et a/., 1997, Nature Medicine 3: 402408). For example, PCT Patent Application W098/16628 and U.S. Patent 6,107,540 describe various xenograft models of human prostate cancer capable of recapitulating the development of primary tumors, micrometastasis, and the formation of osteoblastic metastases characteristic of late stage disease. Efficacy can be predicted using assays that measure inhibition of tumor formation, tumor regression or metastasis, and the like.
In vivo assays that evaluate the promotion of apoptosis are useful in evaluating therapeutic compositions. In one embodiment, xenografts from tumor bearing mice treated with the therapeutic composition can be examined for the presence of apoptotic foci and compared to untreated control xenograft-bearing mice. The extent to which apoptotic foci are found in the tumors of the treated mice provides an indication of the therapeutic efficacy of the composition.
The therapeutic compositions used in the practice of the foregoing methods can be formulated into pharmaceutical compositions comprising a carrier suitable for the desired delivery method. Suitable carriers include any material that when combined with the therapeutic composition retains the anti-tumor function of the therapeutic composition and is generally non-reactive with the patient's immune system. Examples indude, but are not limited to, any of a number of standard
pharmaceutical carriers such as sterile phosphate buffered saline solutions, bacteriostatic water, and the like (see, generally, Remington's Pharmaceutical Sciences 16th Edition, A. Osal., Ed., 1980).
Therapeutic formulations can be solubilized and administered via any route capable of delivering the therapeutic composition to the tumor site. Potentially effective routes of administration include, but are not limited to, intravenous, parenteral, intraperitoneal, intramuscular, intr atumor, intrader al, intraorgan, orthotopic, and the like. A preferred formulation for intravenous injection comprises the therapeutic composition in a solution of preserved bacteriostatic water, sterile unpreserved water, and/or diluted in polyvinylchloride or polyethylene bags containing 0.9% sterile Sodium Chloride for Injection, USP. Therapeutic protein preparations can be lyophilized and stored as sterile powders, preferably under vacuum, and then reconstituted in bacteriostatic water (containing for example, benzyl alcohol preservative) or in sterile water prior to injection.
Dosages and administration protocols for the treatment of cancers using the foregoing mettiods will vary with the method and the target cancer, and will generally depend on a number of other factors appredated in the art.
XIII.) Identification. Characterization and Use of Modulators of 24P4C12
Methods to Identify and Use Modulators
In one embodiment, screening is performed to identify modulators that induce or suppress a particular expression profile, suppress or induce spedfic pathways, preferably generating the associated phenotype thereby. In another embodiment, having identified differentially expressed genes important in a particular state; screens are performed to identify modulators that alter expression of individual genes, either increase or decrease. In another embodiment, screening is performed to identify modulators that alter a biological function of the expression product of a differentially expressed gene. Again, having identified the importance of a gene in a particular state, sσeens are performed to identify agents that bind and/or modulate the biological activity of the gene product.
In addition, screens are done for genes that are induced in response to a candidate agent. After identifying a modulator (one that suppresses a cancer expression pattern leading to a normal expression pattern, or a modulator of a cancer gene that leads to expression of the gene as in normal tissue) a sσeen is performed to identify genes that are specifically modulated in response to the agent. Comparing expression profiles between normal tissue and agent-treated cancer tissue reveals genes that are not expressed in normal tissue or cancer tissue, but are expressed in agent treated tissue, and vice versa. These agent-specific sequences are identified and used by methods described herein for cancer genes or proteins. In particular these sequences and the proteins they encode are used in marking or identifying agent- treated cells. In addition, antibodies are raised against the agent-induced proteins and used to target novel therapeutics to the treated cancer tissue sample.
Modulator-related Identification and Screening Assays:
Gene Expression-related Assays
Proteins, nudeic acids, and antibodies of the invention are used in screening assays. The cancer-associated proteins, antibodies, nudeic acids, modified proteins and cells containing these sequences are used in screening assays, such as evaluating ttie effect of drug candidates on a "gene expression profile," expression profile of polypeptides or alteration of biological function. In one embodiment, the expression profiles are used, preferably in conjunction with high throughput sσeening techniques to allow monitoring for expression profile genes after treatment with a candidate agent (e.g., Davis, GF, etal, J Biol Screen 7:69 (2002); Zlokarnik, etal., Science 279:84-8 (1998); Heid, Genome Res 6:986- 94,1996).
The cancer proteins, antibodies, nucleic adds, modified proteins and cells containing the native or modified cancer proteins or genes are used in screening assays. That is, the present invention comprises methods for screening for compositions which modulate the cancer phenotype or a physiological function of a cancer protein of the invention. This is done on a gene itself or by evaluating the effect of drug candidates on a "gene expression profile" or biological function. In one embodiment, expression profiles are used, preferably in conjunction with high throughput screening techniques to allow monitoring after treatment with a candidate agent, see Zlokamik, supra.
A variety of assays are executed directed to the genes and proteins of the invention. Assays are run on an individual nucleic acid or protein level. That is, having identified a particular gene as up regulated in cancer, test compounds are screened for the ability to modulate gene expression or for binding to the cancer protein of the invention. "Modulation" in this context includes an increase or a decrease in gene expression. The preferred amount of modulation will depend on the original change of the gene expression in normal versus tissue undergoing cancer, with changes of at least 10%, preferably 50%, more preferably 100-300%, and in some embodiments 300-1000% or greater. Thus, if a gene exhibits a 4-fold increase in cancer tissue compared to normal tissue, a decrease of about four-fold is often desired; similarly, a 10-fold deσease in cancer tissue compared to normal tissue a target value of a 10-fold increase in expression by the test compound is often desired. Modulators that exacerbate the type of gene expression seen in cancer are also useful, e.g., as an upregulated target in further analyses.
The amount of gene expression is monitored using nucleic acid probes and the quantification of gene expression levels, or, alternatively, a gene product itself is monitored, e.g., through the use of antibodies to the cancer protein and standard immunoassays. Proteomics and separation techniques also allow for quantification of expression.
Expression Monitoring to Identify Compounds that Modify Gene Expression
In one embodiment, gene expression monitoring, i.e., an expression profile, is monitored simultaneously for a number of entities. Such profiles will typically involve one or more of the genes of Figure 2. In this embodiment, e.g., cancer nucleic acid probes are attached to biochips to detect and quantify cancer sequences in a particular cell. Alternatively, PCR can be used. Thus, a series, e.g., wells of a miσotiter plate, can be used with dispensed primers in desired wells. A PCR reaction can then be performed and analyzed for each well.
Expression monitoring is performed to identify compounds that modify the expression of one or more cancer- asso ated sequences, e.g., a polynucleotide sequence set out in Figure 2. Generally, a test modulator is added to the cells prior to analysis. Moreover, screens are also provided to identify agents that modulate cancer, modulate cancer proteins of the invention, bind to a cancer protein of the invention, or interfere with the binding of a cancer protein of the invention and an antibody or other binding partner.
In one embodiment, high throughput screening methods involve providing a library containing a large number of potential therapeutic compounds (candidate compounds). Such "combinatorial chemical libraries" are then screened in one or more assays to identify those library members (particular chemical species or subclasses) that display a desired characteristic activity. The compounds thus identified can serve as conventional "lead compounds," as compounds for screening, or as therapeutics.
In certain embodiments, combinatorial libraries of potential modulators are screened for an ability to bind to a cancer polypeptide or to modulate activity. Conventionally, new chemical entities with useful properties are generated by identifying a chemical compound (called a "lead compound") with some desirable property or activity, e.g., inhibiting activity, creating variants of the lead compound, and evaluating the property and activity of those variant compounds. Often, high throughput screening (HTS) methods are employed for such an analysis.
As noted above, gene expression monitoring is conveniently used to test candidate modulators (e g , protein, nudeic acid or small molecule) After the candidate agent has been added and the cells allowed to incubate for a period, the sample containing a target sequence to be analyzed is, e g , added to a biochip
If required, the target sequence is prepared using known techniques For example, a sample is treated to lyse the cells, using known lysis buffers, electroporation, etc , with purification and/or amplification such as PCR performed as appropnate For example, an in vitro transcription with labels covalently attached to the nucleotides is performed Generally, the nucleic acids are labeled with biot -FITC or PE, or with cy3 or cy5
The target sequence can be labeled with, e g , a fluorescent, a chemiluminescent, a chemical, or a radioactive signal, to provide a means of detecting the target sequence's specific binding to a probe The label also can be an enzyme, such as alkaline phosphatase or horseradish peroxidase, which when provided with an appropriate substrate produces a product that is detected Alternatively, the label is a labeled compound or small molecule, such as an enzyme inhibitor, that binds but is not catalyzed or altered by the enzyme The label also can be a moiety or compound, such as, an epitope tag or biotin which specifically binds to sfreptavidin For the example of biotin, the sfreptavidin is labeled as described above, thereby, providing a detectable signal for the bound target sequence Unbound labeled sfreptavidin is typically removed prior to analysis
As will be appreciated by those in the art, these assays can be direct hybridization assays or can comprise "sandwich assays", which include the use of multiple probes, as is generally outlined in U S Patent Nos 5, 681,702, 5,597,909, 5,545,730, 5594,117, 5,591,584 5,571,670, 5,580,731, 5,571,670, 5,591,584, 5,624,802, 5,635,352, 5,594,118, 5,359,100, 5,124, 246, and 5,681,697 In this embodiment, in general, the target nucleic acid is prepared as outlined above, and then added to the biochip compπsing a plurality of nucleic aαd probes, under conditions that allow the formation of a hybridization complex
A vaπety of hybridization conditions are used in the present invention, including high, moderate and low stnngency conditions as outlined above The assays are generally run under stnngency conditions which allow formation of the label probe hybridization complex only in the presence of target Stringency can be controlled by altering a step parameter that is a thermodynamic vanable, including, but not limited to, temperature, formamide concentration, salt concentration, chaofropic salt concentration pH, organic solvent concentration, etc These parameters may also be used to control non-specific binding, as is generally outlined in U S Patent No 5,681,697 Thus, it can be desirable to perform certain steps at higher stnngency conditions to reduce non-specific binding
The reactions outlined herein can be accomplished in a vaπety of ways Components of the reaction can be added simultaneously, or sequentially in different orders, with preferred embodiments outlined below In addition, the reaction may include a vanety of other reagents These include salts, buffers, neutral proteins, e g albumin, detergents, etc which can be used to facilitate optimal hybridization and detection, and/or reduce nonspeαfic or background interactions Reagents that otherwise improve the efficiency of the assay, such as protease inhibitors, nuclease inhibitors, anti-microbial agents, etc , may also be used as appropnate, depending on the sample preparation methods and purity of the target The assay data are analyzed to determine the expression levels of individual genes, and changes in expression levels as between states, forming a gene expression profile
Biological Activity-related Assays
The invention provides methods identify or sσeen for a compound that modulates the activity of a cancer-related gene or protein of the invention The methods compnse adding a test compound, as defined above, to a cell compπsing a cancer protein of the invention The cells contain a recombinant nudeic aαd that encodes a cancer protein of the invention In another embodiment, a library of candidate agents is tested on a plurality of cells
In one aspect, the assays are evaluated in the presence or absence or previous or subsequent exposure of physiological signals, e.g. hormones, antibodies, peptides, antigens, cytokines, growth factors, action potentials, pharmacological agents including chemotherapeutics, radiation, carcinogenics, or other cells (i.e., cell-cell contacts). In another example, the determinations are made at different stages of the cell cycle process. In this way, compounds that modulate genes or proteins of the invention are identified. Compounds with pharmacological activity are able to enhance or interfere with the activity of the cancer protein of the invention. Once identified, similar structures are evaluated to identify critical structural features of the compound.
In one embodiment, a method of modulating ( e.g., inhibiting) cancer cell division is provided; the method comprises administration of a cancer modulator. In another embodiment, a method of modulating ( e.g., inhibiting) cancer is provided; the method comprises administration of a cancer modulator. In a further embodiment, methods of treating cells or individuals with cancer are provided; the method comprises administration of a cancer modulator.
In one embodiment, a method for modulating the status of a cell that expresses a gene of the invention is provided. As used herein status comprises such art-accepted parameters such as growth, proliferation, survival, function, apoptosis, senescence, location, enzymatic activity, signal transduction, etc. of a cell. In one embodiment, a cancer inhibitor is an antibody as discussed above. In another embodiment, the cancer inhibitor is an antisense molecule. A variety of cell growth, proliferation, and metastasis assays are known to those of skill in the art, as described herein.
High Throughput Screening to Identify Modulators
The assays to identify suitable modulators are amenable to high throughput screening. Preferred assays thus detect enhancement or inhibition of cancer gene transcription, inhibition or enhancement of polypeptide expression, and inhibition or enhancement of polypeptide activity.
In one embodiment, modulators evaluated in high throughput screening methods are proteins, often naturally occurring proteins or fragments of naturally occurring proteins. Thus, e.g., cellular extracts containing proteins, or random or directed digests of proteinaceous cellular extracts, are used. In this way, libraries of proteins are made for screening in the methods of the invention. Particularly preferred in this embodiment are libraries of bacterial, fungal, viral, and mammalian proteins, with the latter being preferred, and human proteins being especially preferred. Particularly useful test compound will be directed to the dass of proteins to which the target belongs, e.g., substrates for enzymes, or ligands and receptors.
Use of Soft Aαar Growth and Colony Formation to Identify and Characterize Modulators
Normal cells require a solid substrate to attach and grow. When cells are transformed, they lose this phenotype and grow detached from the substrate. For example, transformed cells can grow in stirred suspension culture or suspended in semi-solid media, such as semi-solid or soft agar. The transformed cells, when transfected with tumor suppressor genes, can regenerate normal phenotype and once again require a solid subsfrate to attach to and grow. Soft agar growth or colony formation in assays are used to identify modulators of cancer sequences, which when expressed in host cells, inhibit abnormal cellular proliferation and transformation. A modulator reduces or eliminates the host cells' ability to grow suspended in solid or semisolid media, such as agar.
Techniques for soft agar growth or colony formation in suspension assays are described in Freshney, Culture of Animal Cells a Manual of Basic Technique (3rd ed., 1994). See also, the methods section of Garkavtsev et al. (1996), supra.
Evaluation of Contact Inhibition and Growth Density Limitation to Identify and Characterize Modulators
Normal cells typically grow in a flat and organized pattern in cell culture until they touch other cells. When the cells touch one another, they are contact inhibited and stop growing. Transformed cells, however, are not contact inhibited and continue to grow to high densities in disorganized foci. Thus, transformed cells grow to a higher saturation density than corresponding normal cells. This is detected morphologically by the formation of a disoriented monolayer of cells or cells in
foci. Alternatively, labeling index with (3H)-thymidine at saturation density is used to measure density limitation of growth, similarly an MTT or Alamar blue assay will reveal proliferation capacity of cells and the the ability of modulators to affect same. See Freshney (1994), supra. Transformed cells, when transfected with tumor suppressor genes, can regenerate a normal phenotype and become contact inhibited and would grow to a lower density.
In this assay, labeling index with 3H)-thymidine at saturation density is a preferred method of measuring density limitation of growth. Transformed host cells are transfected with a cancer-associated sequence and are grown for 24 hours at saturation density in non-limiting medium conditions. The percentage of cells labeling with (3H)-thymidine is determined by incorporated cpm.
Contact independent growth is used to identify modulators of cancer sequences, which had led to abnormal cellular proliferation and transformation. A modulator reduces or eliminates contact independent growth, and returns the cells to a normal phenotype.
Evaluation of Growth Factor or Serum Dependence to Identify and Characterize Modulators
Transformed cells have lower serum dependence than their normal counterparts (see, e.g., Temin, J. Natl. Cancer Inst, 37:167-175 (1966); Eagle et al., J. Exp. Med 131:836-879 (1970)); Freshney, supra. This is in part due to release of - various growth factors by the transformed cells. The degree of growth factor or serum dependence of fransformed host cells can be compared with that of control. For example, growth factor or serum dependence of a cell is monitored in methods to identify and characterize compounds that modulate cancer-associated sequences of the invention.
Use of Tumor-specific Marker Levels to Identify and Characterize Modulators Tumor cells release an increased amount of certain factors (hereinafter "tumor specific markers") than their normal counterparts. For example, plas inogen activator (PA) is released from human glioma at a higher level than from normal brain cells (see, e.g., Gullino, Angiogenesis, Tumor Vascularization, and Potential Interference with Tumor Growth, in Biological Responses in Cancer, pp. 178-184 (Mihich (ed.) 1985)). Similarly, Tumor Angiogenesis Factor (TAF) is released at a higher level in tumor cells than their normal counterparts. See, e.g., Folkman, Angiogenesis and Cancer, Sem Cancer Biol. (1992)), while bFGF is released from endothelial tumors (Ensoli, B etal).
Various techniques which measure the release of these factors are described in Freshney (1994), supra. Also, see, Unkless etal., J. Biol. Chem. 249:42954305 (1974); Strickland & Beers, J. Biol. Chem. 251:5694-5702 (1976); Whuret al., Br. J. Cancer 42:305 312 (1980); Gullino, Angiogenesis, Tumor Vascularization, and Potential Interference with Tumor Growth, in Biological Responses in Cancer, pp. 178-184 (Mihich (ed.) 1985); Freshney, Anticancer Res. 5:111-130 (1985). For example, tumor specific marker levels are monitored in methods to identify and characterize compounds that modulate cancer-associated sequences of the invention.
Invasiveness into Matrigel to Identify and Characterize Modulators
The degree of invasiveness into Matrigel or an extracellular matrix constituent can be used as an assay to identify and characterize compounds that modulate cancer associated sequences. Tumor cells exhibit a positive correlation between malignancy and invasiveness of cells into Matrigel or some other extracellular matrix constituent. In this assay, tumorigenic cells are typically used as host cells. Expression of a tumor suppressor gene in these host cells would decrease invasiveness of the host cells. Techniques described in Cancer Res. 1999; 59:6010; Freshney (1994), supra, can be used. Briefly, the level of invasion of host cells is measured by using filters coated with Matrigel or some other extracellular matrix constituent. Penetration into the gel, or through to the distal side of the filter, is rated as invasiveness, and rated histologically by number of cells and distance moved, or by prelabeling the cells with 1251 and counting the radioactivity on the distal side of the filter or bottom of the dish. See, e.g., Freshney (1984), supra.
Evaluation of Tumor Growth In Vivo to Identify and Characterize Modulators
Effects of cancer-associated sequences on cell growth are tested in transgenic or immune-suppressed organisms. Transgenic organisms are prepared in a variety of art-accepted ways. For example, knock-out transgenic organisms, e.g., mammals such as mice, are made, in which a cancer gene is disrupted or in which a cancer gene is inserted. Knock-out transgenic mice are made by insertion of a marker gene or other heterologous gene into the endogenous cancer gene site in the mouse genome via homologous recombination. Such mice can also be made by substituting the endogenous cancer gene with a mutated version of the cancer gene, or by mutating the endogenous cancer gene, e.g., by exposure to carcinogens.
To prepare transgenic chimeric animals, e.g., mice, a DNA construct is introduced into the nuclei of embryonic stem cells. Cells containing the newly engineered genetic lesion are injected into a host mouse embryo, which is re- implanted into a recipient female. Some of these embryos develop into chimeric mice that possess germ cells some of which are derived from the mutant cell line. Therefore, by breeding the chimeric mice it is possible to obtain a new line of mice containing the infroduced genetic lesion (see, e.g., Capecchi etal., Science 244:1288 (1989)). Chimeric mice can be derived according to US Patent 6,365,797, issued 2 April 2002; US Patent 6,107,540 issued 22 August 2000; Hogan et al., Manipulating the Mouse Embryo: A laboratory Manual, Cold Spring Harbor Laboratory (1988) and Teratocarcinomas and Embryonic Stem Cells: A Practical Approach, Robertson, ed., IRL Press, Washington, D.C., (1987).
Altematively, various immune-suppressed or immune-deficient host animals can be used. For example, a genetically athymic "nude" mouse (see, e.g., Giovanella et al., J. Natl. Cancer Inst. 52:921 (1974)), a SCID mouse, a thymectornized mouse, or an irradiated mouse (see, e.g., Bradley et al., Br. J. Cancer 38:263 (1978); Selby et al., Br. J. Cancer 41:52 (1980)) can be used as a host. Transplantable tumor cells (typically about 10s cells) injected into isogenic hosts produce invasive tumors in a high proportion of cases, while normal cells of similar origin will not. In hosts which developed invasive tumors, cells expressing cancer-associated sequences are injected subcutaneously or orthotopically. Mice are then separated into groups, including confrol groups and treated experimental groups) e.g. treated with a modulator). After a suitable length of time, preferably 4-8 weeks, tumor growth is measured (e.g., by volume or by its two largest dimensions, or weight) and compared to the control. Tumors that have statistically significant reduction (using, e.g., Student's T test) are said to have inhibited growth.
In Vitro Assays to Identify and Characterize Modulators
Assays to identify compounds with modulating activity can be performed in vitro. For example, a cancer polypeptide is first contacted with a potential modulator and incubated for a suitable amount of time, e.g., from 0.5 to 48 hours. In one embodiment, the cancer polypeptide levels are determined in vitro by measuring the level of protein or mRNA. The level of protein is measured using immunoassays such as Western blotting, ELISA and the like with an antibody that selectively binds to the cancer polypeptide or a fragment thereof. For measurement of mRNA, amplification, e.g., using PCR, LCR, or hybridization assays, e. g., Northern hybridization, RNAse protection, dot blotting, are preferred. The level of protein or mRNA is detected using directly or indirectly labeled detection agents, e.g., fluorescentJy or radioactively labeled nucleic acids, radioactively or enzymatically labeled antibodies, and the like, as described herein.
Alternatively, a reporter gene system can be devised using a cancer protein promoter operably linked to a reporter gene such as luciferase, green fluorescent protein, CAT, or P-gal. The reporter construct is typically transfected into a cell. After treatment with a potential modulator, the amount of reporter gene transσiption, translation, or activity is measured according to standard techniques known to those of skill in the art (Davis GF, supra; Gonzalez, J. & Negulescu, P. Curr. Opin. Biotechnol. 1998: 9:624).
As outlined above, in vitro screens are done on individual genes and gene products. That is, having identified a particular differentially expressed gene as important in a particular state, screening of modulators of the expression of the gene or the gene product itself is performed.
In one embodiment, screening for modulators of expression of specific gene(s) is performed. Typically, the expression of only one or a few genes is evaluated. In another embodiment, screens are designed to first find compounds that bind to differentially expressed proteins. These compounds are then evaluated for the ability to modulate differentially expressed activity. Moreover, once initial candidate compounds are identified, variants can be further screened to better evaluate structure activity relationships.
Binding Assays to Identify and Characterize Modulators
In binding assays in accordance with the invention, a purified or isolated gene product of the invention is generally used. For example, antibodies are generated to a protein of the invention, and immunoassays are run to determine the amount and/or location of protein. Alternatively, cells comprising the cancer proteins are used in the assays.
Thus, the methods comprise combining a cancer protein of the invention and a candidate compound such as a ligand, and determining the binding of the compound to the cancer protein of the invention. Preferred embodiments utilize the human cancer protein; animal models of human disease of can also be developed and used. Also, other analogous mammalian proteins also can be used as appreciated by those of skill in the art. Moreover, in some embodiments variant or derivative cancer proteins are used.
Generally, the cancer protein of the invention, or the ligand, is non-diffusibly bound to an insoluble support. The support can, e.g., be one having isolated sample receiving areas (a miσotiter plate, an array, etc.). The insoluble supports can be made of any composition to which the compositions can be bound, is readily separated from soluble material, and is otherwise compatible with the overall method of screening. The surface of such supports can be solid or porous and of any convenient shape.
Examples of suitable insoluble supports include microtiter plates, arrays, membranes and beads. These are typically made of glass, plastic (e.g., polystyrene), polysaccharide, nylon, nitrocellulose, or Teflon™, etc. Microtiter plates and arrays are especially convenient because a large number of assays can be carried out simultaneously, using small amounts of reagents and samples. The particular manner of binding of the composition to the support is not crucial so long as it is compatible with the reagents and overall methods of the invention, maintains the activity of the composition and is nondiffusable. Preferred methods of binding include the use of antibodies which do not sterically block either the ligand binding site or activation sequence when attaching the protein to the support, direct binding to "sticky" or ionic supports, chemical crosslinking, the synthesis of the protein or agent on the surface, etc. Following binding of the protein or ligand/binding agent to the support, excess unbound material is removed by washing. The sample receiving areas may then be blocked through incubation with bovine serum albumin (BSA), casein or other innocuous protein or other moiety.
Once a cancer protein of the invention is bound to the support, and a test compound is added to the assay. Alternatively, the candidate binding agent is bound to the support and the cancer protein of the invention is then added. Binding agents include specific antibodies, non-natural binding agents identified in screens of chemical libraries, peptide analogs, etc.
Of particular interest are assays to identify agents that have a low toxidty for human cells. A wide variety of assays can be used for this purpose, including proliferation assays, cAMP assays, labeled in vitro protein-protein binding assays, elect, ophoretic mobility shift assays, immunoassays for protein binding, functional assays (phosphorylation assays, etc.) and the like.
A determination of binding of the test compound (ligand, binding agent, modulator, etc.) to a cancer protein of the invention can be done in a number of ways. The test compound can be labeled, and binding determined directly, e.g., by attaching all or a portion of the cancer protein of the invention to a solid support, adding a labeled candidate compound (e.g., a fluorescent label), washing off excess reagent, and determining whether the label is present on the solid support. Various blocking and washing steps can be utilized as appropriate.
In certain embodiments, only one of the components is labeled, e.g., a protein of the invention or ligands labeled. Alternatively, more than one component is labeled with different labels, e.g., I125, for the proteins and a fiuorophor for the compound. Proximity reagents, e.g., quenching or energy transfer reagents are also useful.
Competitive Binding to Identify and Characterize Modulators
In one embodiment, the binding of the "test compound" is determined by competitive binding assay with a "competitor." The competitor is a binding moiety that binds to the target molecule (e.g., a cancer protein of the invention). Competitors include compounds such as antibodies, peptides, binding partners, ligands, etc. Under certain circumstances, the competitive binding between the test compound and the competitor displaces the test compound. In one embodiment, the test compound is labeled. Either the test compound, the competitor, or both, is added to the protein for a time sufficient to allow binding. Incubations are performed at a temperature that fadlitates optimal activity, typically between four and 40°C. Incubation periods are typically optimized, e.g., to fadlitate rapid high throughput screening; typically between zero and one hour will be sufficient. Excess reagent is generally removed or washed away. The second component is then added, and the presence or absence of the labeled component is followed, to indicate binding.
In one embodiment, the competitor is added first, followed by the test compound. Displacement of the competitor is an indication that the test compound is binding to the cancer protein and thus is capable of binding to, and potentially modulating, the activity of the cancer protein. In this embodiment, either component can be labeled. Thus, e.g., if the competitor is labeled, the presence of label in the post-test compound wash solution indicates displacement by the test compound. Alternatively, if the test compound is labeled, the presence of the label on the support indicates displacement.
In an alternative embodiment, the test compound is added first, with incubation and washing, followed by the competitor. The absence of binding by the competitor indicates that the test compound binds to the cancer protein with higher affinity than the competitor. Thus, if the test compound is labeled, the presence of the label on the support, coupled with a lack of competitor binding, indicates that the test compound binds to and thus potentially modulates the cancer protein of the invention.
Accordingly, the competitive binding methods comprise differential screening to identity agents that are capable of modulating the activity of the cancer proteins of the invention. In this embodiment, the methods comprise combining a cancer protein and a competitor in a first sample. A second sample comprises a test compound, the cancer protein, and a competitor. The binding of the competitor is determined for both samples, and a change, or difference in binding between the two samples indicates the presence of an agent capable of binding to the cancer protein and potentially modulating its activity. That is, if the binding of the competitor is different in the second sample relative to the first sample, the agent is capable of binding to the cancer protein.
Altematively, differential screening is used to identify drug candidates that bind to the native cancer protein, but cannot bind to modified cancer proteins. For example the structure of the cancer protein is modeled and used in rational drug design to synthesize agents that interact with that site, agents which generally do not bind to site-modified proteins. Moreover, such drug candidates that affect the activity of a native cancer protein are also identified by screening drugs for the ability to either enhance or reduce the activity of such proteins.
Positive controls and negative controls can be used in the assays Preferably confrol and test samples are performed in at least triplicate to obtain statistically significant results Incubation of all samples occurs for a time sufficient to allow for the binding of the agent to the protein Following incubation, samples are washed free of non-speαfically bound material and the amount of bound, generally labeled agent determined For example, where a radiolabel is employed, the samples can be counted in a scintillation counter to determine the amount of bound compound
A vaπety of other reagents can be included m the screening assays These include reagents like salts, neutral proteins, e g albumin, detergents, etc which are used to facilitate optimal protein-protein binding and/or reduce non-specific or background interactions Also reagents that otherwise improve the efficiency of the assay such as protease inhibitors nuclease inhibitors, anti-microbial agents, etc can be used The mixture of components is added in an order that provides for the requisite binding
Use of Polynucleotides to Down regulate or Inhibit a Protein of the Invention
Polynudeotide modulators of cancer can be introduced into a cell containing the target nucleotide sequence by formation of a conjugate with a ligand-bindmg molecule, as described in WO 91/04753 Suitable gand-binding molecules include, but are not limited to, cell surface receptors, growth factors, other cytokines, or other ligands that bind to cell surface receptors Preferably, conjugation of the ligand binding molecule does not substantially interfere with the ability of the ligand binding molecule to bind to its corresponding molecule or receptor, or block entry of the sense or antisense oligonucleotide or its conjugated version into the cell Alternatively, a polynucleotide modulator of cancer can be introduced into a cell containing the target nucleic acid sequence e g , by formation of a polyn u cleotide-lipid complex, as described in WO 90/10448 It is understood that the use of antisense molecules or knock out and knock in models may also be used in screening assays as discussed above, in addition to methods of treatment
Inhibitory and Antisense Nucleotides
In certain embodiments, the activity of a cancer-associated protein is down-regulated, or entirely inhibited, by the use of antisense polynucleotide or inhibitory small nudear RNA (snRNA), i e , a nucleic acid complementary to, and which can preferably hybridize specifically to, a coding mRNA nucleic acid sequence, e g , a cancer protein of the invention, mRNA, or a subsequence thereof Binding of the antisense polynucleotide to the mRNA reduces the translation and/or stability of the mRNA
In the context of this invention antisense polynudeotides can comprise naturally occumng nudeotides, or synthetic species formed from naturally occurring subunits or their close homologs Antisense polynucleotides may also have altered sugar moieties or inter-sugar linkages Exemplary among these are the phosphorothioate and other sulfur containing species which are known for use in the art Analogs are comprised by this invention so long as they function effectively to hybndize with nucleotides of the invention See, e g , Isis Pharmaceuticals, Carlsbad, CA, Sequitor, Inc , Natick, MA
Such antisense polynucleotides can readily be synthesized using recombinant means, or can be synthesized in vitro Equipment for such synthesis is sold by several vendors, including Applied Biosystems The preparation of other oligonucleotides such as phosphor othioates and alkylated derivatives is also well known to those of skill in the art
Antisense molecules as used herein include antisense or sense ohgonudeotides Sense oligonucleotides can, e g , be employed to block transaction by binding to the anti-sense strand The antisense and sense oligonucleotide comprise a single stranded nucleic acid sequence (either RNA or DNA) capable of binding to target mRNA (sense) or DNA (antisense) sequences for cancer molecules Antisense or sense oligonucleotides, according to the present invention, compπse a fragment generally at least about 12 nucleotides, preferably from about 12 to 30 nucleotides The ability to denve
an antisense or a sense oligonucleotide, based upon a cDNA sequence encoding a given protein is described in, e.g., Stein &Cohen (Cancer Res. 48:2659 (1988 and van der Krol et al. (BioTechniques 6:958 (1988)).
Ribozymes
In addition to antisense polynucleotides, ribozymes can be used to target and inhibit transcription of cancer- associated nucleotide sequences. A ribozyme is an RNA molecule that catalytically cleaves other RNA molecules. Different kinds of ribozymes have been described, including group I ribozymes, hammerhead ribozymes, hairpin ribozymes, RNase P, and axhead ribozymes (see, e.g., Castanotto et al., Adv. in Pharmacology 25: 289-317 (1994) for a general review of the properties of different ribozymes).
The general features of hairpin ribozymes are described, e.g., in Hampel et al., Nucl. Acids Res. 18:299-304 (1990); European Patent Publication No. 0360257; U.S. Patent No. 5,254,678. Methods of preparing are well known to those of skill in the art (see, e.g., WO 94/26877; Ojwang et al., Proc. Natl. Acad. Sci. USA 90:6340-6344 (1993); Yamada et al., Human Gene Therapy 1 :3945 (1994); Leavitt et al., Proc. Natl. Acad Sci. USA 92:699- 703 (1995); Leavitt et al., Human Gene Therapy 5: 1151-120 (1994); and Yamada et al., Virology 205: 121-126 (1994)).
Use of Modulators in Phenotypic Screening
In one embodiment, a test compound is administered to a population of cancer cells, which have an associated cancer expression profile. By "administration" or "contacting" herein is meant that the modulator is added to the cells in such a manner as to allow the modulator to act upon the cell, whether by uptake and intracellular action, or by action at the cell surface. In some embodiments, a nucleic acid encoding a proteinaceous agent (i.e., a peptide) is put into a viral construct such as an adenoviral or retroviral construct, and added to the cell, such that expression of the peptide agent is accomplished, e.g., PCT US97/01019. Regulatable gene therapy systems can also be used. Once the modulator has been administered to the cells, the cells are washed if desired and are allowed to incubate under preferably physiological conditions for some period. The cells are then harvested and a new gene expression profile is generated. Thus, e.g., cancer tissue is screened for agents that modulate, e.g., induce or suppress, the cancer phenotype. A change in at least one gene, preferably many, of the expression profile indicates that the agent has an effect on cancer activity. Similarly, altering a biological function or a signaling pathway is indicative of modulator activity. By defining such a signature for the cancer phenotype, sσeens for new drugs that alter the phenotype are devised. With this approach, the drug target need not be known and need not be represented in the original gene/protein expression screening platform, nor does the level of transcript for the target protein need to change. The modulator inhibiting function will serve as a surrogate marker
As outlined above, screens are done to assess genes or gene products. That is, having identified a particular differentially expressed gene as important in a particular state, sσeening of modulators of either the expression of the gene or the gene product itself is performed.
Use of Modulators to Affect Peptides of the Invention
Measurements of cancer polypeptide activity, or of the cancer phenotype are performed using a variety of assays. For example, the effeds of modulators upon the function of a cancer polypeptide(s) are measured by examining parameters described above. A physiological change that affects activity is used to assess the influence of a test compound on the polypeptides of this invention. When the functional outcomes are determined using intact cells or animals, a variety of effects can be assesses such as, in the case of a cancer associated with solid tumors, tumor growth, tumor metastasis, πeovascularization, hormone release, transcriptional changes to both known and uncharacterized genetic markers (e.g., by Northern blots), changes in cell metabolism such as cell growth or pH changes, and changes in intracellular second messengers such as cGNIP.
Methods of Identifying Characterizing Cancer-assodated Seouences
Expression of various gene sequences is correlated with cancer. Accordingly, disorders based on mutant or variant cancer genes are determined. In one embodiment, the invention provides methods for identifying cells containing variant cancer genes, e.g., determining the presence of, all or part, the sequence of at least one endogenous cancer gene in a cell. This is accomplished using any number of sequencing techniques. The invention comprises methods of identifying the cancer genotype of an individual, e.g., determining all or part of the sequence of at least one gene of the invention in the individual. This is generally done in at least one tissue of the individual, e.g., a tissue set forth in Table I, and may include the evaluation of a number of tissues or different samples of the same tissue. The method may indude comparing the sequence of the sequenced gene to a known cancer gene, i.e., a wild-type gene to determine the presence of family members, homologies, mutations or variants. The sequence of all or part of the gene can then be compared to the sequence of a known cancer gene to determine if any differences exist, This is done using any number of known homology programs, such as BLAST, Bestfit, etc. The presence of a difference in the sequence between the cancer gene of the patient and the known cancer gene correlates with a disease state or a propensity for a disease state, as outlined herein.
In a preferred embodiment, the cancer genes are used as probes to determine the number of copies of the cancer gene in the genome. The cancer genes are used as probes to determine the chromosomal localization of the cancer genes. Information such as chromosomal localization finds use in providing a diagnosis or prognosis in particular when chromosomal abnormalities such as translocations, and the like are identified in the cancer gene locus.
XIV.) Kits/Articles of Manufacture
For use in the diagnostic and therapeutic applications described herein, kits are also within the scope of the invention. Such kits can comprise a carrier, package or container that is compartmentalized to receive one or more containers such as vials, tubes, and the like, each of the container(s) comprising one of the separate elements to be used in the method. For example, the container (s) can comprise a probe that is or can be detectably labeled. Such probe can be an antibody or polynucleotide specific for a Figure 2-related protein or a Figure 2 gene or message, respectively. Where the method utilizes nudeic acid hybridization to detect the target nucleic acid, the kit can also have containers containing nucleotide(s) for amplification of the target nucleic acid sequence and/or a container comprising a reporter-means, such as a biotin-binding protein, such as avidin or sfreptavidin, bound to a reporter molecule, such as an enzymatic, florescent, or radioisotope label. The kit can include all or part of the amino acid sequences in Figure 2 or Figure 3 or analogs thereof, or a nucleic acid molecules that encodes such amino acid sequences.
The kit of the invention will typically comprise the container described above and one or more other containers comprising materials desirable from a commercial and user standpoint, induding buffers, diluents, filters, needles, syringes; carrier, package, container, vial and/or tube labels listing contents and/or instructions for use, and package inserts with instructions for use.
A label can be present on the container to indicate that the composition is used for a specific therapy or non-therapeutic application, such as a diagnostic or laboratory application, and can also indicate directions for either in vivo or in vitro use, such as those described herein. Directions and or other information can also be induded on an insert(s) or label(s) which is induded with or on the kit.
The terms "kit" and "article of manufacture" can be used as synonyms.
In another embodiment of the invention, an article(s) of manufacture containing compositions, such as amino add sequence(s), small molecule(s), nucleic add sequence(s), and/or antibody(s), e.g., materials useful for the diagnosis, prognosis, prophylaxis and/or treatment of neoplasias of tissues such as those set forth in Table I is provided. The article of
manufacture typically comprises at least one container and at least one label. Suitable containers include, for example, bottles, vials, syringes, and test tubes. The containers can be formed from a variety of materials such as glass or plastic. The container can hold amino acid sequence(s), small molecule(s), nucleic acid sequence(s), and/or antibody(s), in one embodiment the container holds a polynucleotide for use in examining the mRNA expression profile of a cell,, together with reagents used for this purpose.
The container can alternatively hold a composition which is effective for freating, diagnosis, prognosing or prophylaxing a condition and can have a sterile access port (for example the container can be an intravenous solution bag or a vial having a stopper pierceable by a hypodermic injection needle). The active agents in the composition can be an antibody capable of specifically binding 24P4C12 and modulating the function of 24P4C12.
The label can be on or associated with the container. A label a can be on a container when letters, numbers or other characters forming the label are molded or etched into the container itself; a label can be associated with a container when it is present within a receptacle or carrier that also holds the container, e.g., as a package insert. The label can indicate that the composition is used for diagnosing, treating, prophylaxing or prognosing a condition, such as a neoplasia of a tissue set forth in Table I. The article of manufacture can further comprise a second container comprising a pharmaceutically-acceptable buffer, such as phosphate-buffered saline, Ringer's solution and/ordextrose solution. It can further include other materials desirable from a commercial and user standpoint, including other buffers, diluents, filters, stirrers, needles, syringes, and/or package inserts with indications and/or instructions for use.
EXAMPLES:
Various aspects of the invention are further described and illustrated by way of the several examples that follow, none of which are intended to limit the scope of the invention.
Example 1 : SSH-Generated Isolation of cDNA Fragment of the 24P4C12 Gene
Suppression Subtractive Hybridization (SSH) was used to identify cDNAs corresponding to genes that may be differentially expressed in prostate cancer. The SSH reaction utilized cDNA from the LAPC-9 AD prostate cancer xenograft. The gene 24P4C12 was derived from an LAPC-9 AD minus benign prostatic hyperplasia experiment.
The 24P4C12 SSH cDNA of 160 bp is listed in Figure 1. The full length 24P4C12 cDNAs and ORFs are described in Figure 2 with the protein sequences listed in Figure 3.
Materials and Methods
Human Tissues:
The patient cancer and normal tissues were purchased from different sources such as the NDRI (Philadelphia, PA). mRNA for some normal tissues were purchased from Clontech, Palo Alto, CA.
RNA Isolation:
Tissues were homogenized in Trizol reagent (Life Technologies, Gibco BRL) using 10 ml/ g tissue isolate total RNA. Poly A RNA was purified from total RNA using Qiagen's Oligotex mRNA Mini and Midi kits. Total and mRNA were quantified by spectr ophotometric analysis (O.D. 260/280 nm) and analyzed by gel electrophoresis.
Oligonucleotides:
The following HPLC purified oligonucleotides were used.
DPNCDN (cDNA synthesis primer): 5'TTTTGATCAAGCTT3o3' (SEQ ID NO: 33)
Adaptor 1:
5'CTAATACGACTCACTATAGGGCTCGAGCGGCCGCCCGGGCAG3' (SEQ ID NO: 34)
3 GGCCCGTCCTAG5' (SEQ ID NO: 35)
Adaptor 2:
5'GTAATACGACTCACTATAGGGCAGCGTGGTCGCGGCCGAG3' (SEQ ID NO: 36)
3'CGGCTCCTAG5' (SEQ ID NO: 37)
PCR primer 1:
5'CTAATACGACTCACTATAGGGC3' (SEQ ID NO: 38)
Nested primer (NP)1 :
5TCGAGCGGCCGCCCGGGCAGGA3' (SEQ ID NO: 39)
Nested primer (NP)2: 5ΑGCGTGGTCGCGGCCGAGGA3' (SEQ ID NO: 40)
Suppression Subtractive Hybridization:
Suppression Subtractive Hybridization (SSH) was used to identify cDNAs conesponding to genes that may be differentially expressed in prostate cancer. The SSH reaction utilized cDNA from prostate cancer and normal tissues.
The gene 24P4C12 sequence was derived from LAPC4AD prostate cancer xenograft minus begnin prostatic hyperplasia cDNA subtraction. The SSH DNA sequence (Figure 1) was identified.
The cDNA derived from a pool of normal tissues and benign prostatic hyperplasia was used as the source of the "driver" cDNA, while the cDNA from LAPC4AD xenograft was used as the source of the "tester" cDNA. Double stranded cDNAs corresponding to tester and driver cDNAs were synthesized from 2 μg of poly(A)+ RNA isolated from the relevant xenograft tissue, as described above, using CLONTECH's PCR-Select cDNA Subtraction Kit and 1 ng of oligonucleotide DPNCDN as primer. First- and second-strand synthesis were carried out as described in the Kit's user manual protocol (CLONTECH Protocol No. PT1117-1, Catalog No. K1804-1). The resulting cDNA was digested with Dpn II for 3 hrs at 37°C Digested cDNA was extracted with phenol/chloroform (1:1) and ethanol precipitated.
Driver cDNA was generated by combining in a 1:1 ratio Dpn II digested cDNA from the relevant tissue source (see above) with a mix of digested cDNAs derived from the nine normal tissues: stomach, skeletal muscle, lung, brain, liver, kidney, pancreas, small intestine, and heart.
Tester cDNA was generated by diluting 1 μl of Dpn II digested cDNA from the relevant tissue source (see above) (400 ng) in 5 μJ of water. The diluted cDNA (2 μl, 160 ng) was then ligated to 2 μl of Adaptor 1 and Adaptor 2 (10 μM), in separate ligation reactions, in a total volume of 10 μl at 16°C overnight, using 400 u of T4 DNA ligase (CLONTECH). Ligation was terminated with 1 μl of 0.2 M EDTA and heating at 72°C for 5 min.
The first hybridization was performed by adding 1.5 μl (600 ng) of driver cDNA to each of two tubes containing 1.5 μl (20 ng) Adaptor 1- and Adaptor 2- ligated tester cDNA. In a final volume of 4 μl, the samples were overiaid with mineral oil, denatured in an M J Research thermal cyder at 98°C for 1.5 minutes, and then were allowed to hybridize for 8 hrs at 68°C. The two hybridizations were then mixed together with an additional 1 μl of fresh denatured driver cDNA and were allowed to hybridize
overnight at 68°C. The second hybridization was then diluted in 200 μl of 20 mM Hepes, pH 8.3, 50 mM NaCl, 0.2 mM EDTA, heated at 70°C for 7 min. and stored at -20°C.
PCR Amplification, Cloning and Seguencing of Gene Fragments Generated from SSH:
To amplify gene fragments resulting from SSH reactions, two PCR amplifications were performed. In the primary PCR reaction 1 μl of the diluted final hybridization mix was added to 1 μl of PCR primer 1 (10 μM), 0.5 μl dNTP mix (10 μM), 2.5 μl 10 x reaction buffer (CLONTECH) and 0.5 μl 50 x Advantage cDNA polymerase Mix (CLONTECH) in a final volume of 25 μl. PCR 1 was conducted using the following conditions: 75°C for 5 min., 94°C for 25 sec, then 27 cycles of 94°C for 10 sec, 66°C for 30 sec, 72°C for 1.5 min. Five separate primary PCR reactions were performed for each experiment. The products were pooled and diluted 1:10 with water. For the secondary PCR reaction, 1 μl from the pooled and diluted primary PCR reaction was added to the same reaction mix as used for PCR 1 , except that primers NP1 and NP2 (10 μM) were used instead of PCR primer 1. PCR 2 was performed using 10-12 cycles of 94°C for 10 sec, 68°C for 30 sec, and 72°C for 1.5 minutes. The PCR products were analyzed using 2% agarose gel electrophoresis.
The PCR products were inserted into pCR2.1 using the T/A vector cloning kit (Invitrogen). Transformed E coli were subjected to blue/white and ampicillin selection. White colonies were picked and arrayed into 96 well plates and were grown in liquid culture overnight. To identify inserts, PCR amplification was performed on 1 ul of bacterial culture using the conditions of PCR1 and NP1 and NP2 as primers. PCR products were analyzed using 2% agarose gel electrophoresis.
Bacterial clones were stored in 20% glycerol in a 96 well format. Plasmid DNA was prepared, sequenced, and subjected to nudeic acid homology searches of the GenBank, dBest, and NCI-CGAP databases.
RT-PCR Expression Analysis:
First strand cDNAs can be generated from 1 μg of mRNA with oligo (dT)12-18 priming using the Gibco-BRL Superscript Prea plification system. The manufacturer's protocol was used which included an incubation for 50 min at 42°C with reverse transcriptase followed by RNAse H treatment at 37°C for 20 min. After completing the reaction, the volume can be increased to 200 ui with water prior to normalization. First strand cDNAs from 16 different normal human tissues can be obtained from Clontech.
Normalization of the first strand cDNAs from multiple tissues was performed by using the primers 5'atatcgccgcgctcgtcgtcgacaa3' (SEQ ID NO. 41) and 5'agccacacgcagctcattgtagaagg 3' (SEQ ID NO: 42) to amplify β-actin. First strand cDNA (5 μl) were amplified in a total volume of 50 μl containing 0.4 μM primers, 0.2 μM each dNTPs, 1XPCR buffer (Clontech, 10 mM Tris-HCL, 1.5 mM MgCfc, 50 mM KCl, pH8.3) and 1X Klentaq DNA polymerase (Clontech). Five μl of the PCR reaction can be removed at 18, 20, and 22 cycles and used for agarose gel electrophoresis. PCR was performed using an MJ Research thermal cyder under the following conditions: Initial denaturation can be at 94»C for 15 sec, followed by a 18, 20, and 22 cycles of 94°C for 15, 65°C for 2 min, 72°C for 5 sec. A final extension at 72°C was carried out for 2 min. After agarose gel electrophoresis, the band intensities of the 283 b.p. β-actin bands from multiple tissues were compared by visual inspection. Dilution factors for the first strand cDNAs were calculated to result in equal β-actin band intensities in all tissues after 22 cydes of PCR. Three rounds of normalization can be required to achieve equal band intensities in all tissues after 22 cydes of PCR.
To determine expression levels of the 24P4C12 gene, 5 μl of normalized first strand cDNA were analyzed by PCR using 26, and 30 cycles of amplification. Semi-quantitative expression analysis can be achieved by comparing the PCR products at cycle numbers that give light band intensities. The primers used for RT-PCR were designed using the 24P4C12 SSH sequence and are listed below:
24P4C12.1
5'- AGATGAGGAGGAGGACAAAGGTG - 3' (SEQ ID NO: 43)
24P4C12.2
5'- ACTGCTGGGAGGAGTACCGAGTG - 3' (SEQ ID NO: 44)
Example 2: Isolation of Full Length 24P4C12 Encoding cDNA
The 24P4C12 SSH cDNA sequence was derived from a substraction consisting of LAPC4AD xenograft minus benign prostatic hyperplasia. The SSH cDNA sequence (Figure 1) was designated 24P4C12.
The isolated gene fragment of 160 bp encodes a putative open reading frame (ORF) of 53 amino acids and exhibits significant homology to an EST derived from a colon tumor library. Two larger cDNA clones were obtained by gene trapper experiments, GTE9 and GTF8. The ORF revealed a significant homology to the mouse gene NG22 and the C.elegans gene CEESB82F. NG22 was recently identified as one of many ORFs within a genomic BAC clone that encompasses the MHC class III in the mouse genome. Both NG22 and CEESB82F appear to be genes that contain 12 transmembrane domains. This suggests that the gene encoding 24P4C12 contains 12 transmembrane domains and is the human homologue of mouse NG22 and C. elegans CEESB82F. Functional studies in Ce. elegans may reveal the biological role of these homologs. If 24P4C12 is a cell surface marker, then it may have an application as a potential imaging reagent and/or therapeutic target in prostate cancer.
The 24P4C12 v.1 of 2587 bp codes for a protein of 710 amino acids (Figure 2 and Figure 3). Other variants of 24P4C12 were also identified and these are listed in Figures 2 and 3.24P4C12 v.1, v.3, v,5 and v.6 proteins are 710 amino acids in length and differ from each other by one amino acid as shown in Figure 11. 24P4C12 v.2 and v.4 code for the same protein as 24P4C12 v.1. 24P4C12 v.7, v.8 and v.9 are alternative splice variants and code for proteins of 598, 722 and 712 amino adds in length, respectively.
Example 3: Chromosomal Mapping of 24P4C12
Chromosomal localization can implicate genes in disease pathogenesis. Several chromosome mapping approaches are available induding fluorescent in situ hybridization (FISH), human/hamster radiation hybrid (RH) panels (Walter et al., 1994; Nature Genetics 7:22; Research Genetics, Huntsville Al), human-rodent somatic cell hybrid panels such as is available from the Coriell Institute (Camden, New Jersey), and genomic viewers utilizing BLAST homologies to sequenced and mapped genomic clones (NCBI, Bethesda, Maryland). 24P4C12 maps to chromosome 6p21.3 using 24P4C12 sequence and the NCBI BLAST tool located on the World Wide Web at (.ncbi.nlm.nih.gov/genome/seq/page.cgi?F=HsBlasthtml&&ORG=Hs).
Example 4: Expression Analysis of 24P4C12
Expression analysis by RT-PCR demonstrated that 24P4C12 is strongly expressed in prostate and ovary cancer patient specimens (Figure 14). First strand cDNA was generated from vital pool 1 (kidney, liver and lung), vital pool 2 (colon, pancreas and stomach), a pool of prostate cancer xenografts (LAPC4AD, LAPC4AI, LAPC-9AD and LAPC-9AI), prostate cancer pool, bladder cancer pool, kidney cancer pool, colon cancer pool, ovary cancer pool, breast cancer pool, and cancer metastasis pool. Normalization was performed by PCR using primers to actin. Semi-quantitative PCR, using primers to 24P4C12, was performed at 26 and 30 cydes of amplification. Results show strong expression of 24P4C12 in prostate cancer pool and ovary cancer pool. Expression was also detected in prostate cancer xenografts, bladder cancer pool, kidney cancer pool, colon cancer pool, breast cancer pool, cancer metastasis pool, vital pool 1 , and vital pool 2.
Extensive northern blot analysis of 24P4C12 in multiple human normal tissues is shown in Figure 15. Two multiple tissue northern blots (Clontech) both with 2 μg of mRNA lane were probed with the 24P4C12 SSH sequence. Expression of 24P4C12 was detected in prostate, kidney and colon. Lower expression is detected in pancreas, lung and placenta amongst ail 16 normal tissues tested.
Expression of 24P4C12 was tested in prostate cancer xenografts and cell lines. RNA was extracted from a panel of cell lines and prostate cancer xenografts (PrEC. LAPC4AD, LAPC4AI, LAPC-9AD, LAPC-9AI, LNCaP, PC-3, DU145, TsuPr, and LAPC- 4CL). Northern blot with 10 μg of total RNA/lane was probed with 24P4C12 SSH sequence. Size standards in kilobases (kb) are indicated on the side. The 24P4C12 transcript was detected in LAPC4AD, LAPC4AI, LAPC-9AD, LAPC-9AI, LNCaP, and LAPC-4 CL
Expression of 24P4C12 in patient cancer specimens and human normal tissues is shown in Figure 16. RNA was extracted from a pool of prostate cancer specimens, bladder cancer specimens, colon cancer specimens, ovary cancer specimens, breast cancer spedmens and cancer metastasis specimens, as well as from normal prostate (NP), normal bladder (NB), normal kidney (NK), and nomial colon (NC). Northern blot with 10 μg of total RNA/lane was probed with 24P4C12 SSH sequence. Size standards in kilobases (kb) are indicated on the side. Strong expression of 24P4C12 transcript was detected in the patient cancer pool specimens, and in normal prostate but not in the other normal tissues tested.
Expression of 24P4C12 was also detected in individual prostate cancer patient specimens (Figure 17). RNA was extracted from normal prostate (N), prostate cancer patient tumors (T) and their matched normal adjacent tissues (Nat). Northern blots with 10 μg of total RNA were probed with the 24P4C12 SSH fragment. Size standards in kilobases are on the side. Results show expression of 24P4C12 in normal prostate and all prostate patient tumors tested.
Expression of 24P4C12 in colon cancer patient specimens is shown in figure 18. RNA was extracted from colon cancer cell lines (CL: Colo 205, LoVo, and SK-CO-), normal colon (N), colon cancer patient tumors (T) and their matched normal adjacent tissues (Nat). Northern blots with 10 μg of total RNA were probed with the 24P4C12 SSH fragment. Size standards in kilobases are on the side. Results show expression of 24P4C12 in normal colon and all colon patient tumors tested. Expression was detected in the cell lines Colo 205 and SK-CO-, but not in LoVo.
Figure 20 displays expression results of 24P4C12 in lung cancer patient specimens. Ma was extracted from lung cancer cell lines (CL: CALU-1, A427, NCI-H82, NCI-H146), normal lung (N), lung cancer patient tumors (T) and their matched normal adjacent tissues (Nat). Northern blots with 10 μg of total RNA were probed with the 24P4C12 SSH fragment Size standards in kilobases are on the side. Results show expression of 24P4C12 in lung patient tumors tested, but not in normal lung. Expression was also detected in CALU-1 , but not in the other cell lines A427, NCI-H82, and NCI- HI 46.
24P4C12 was assayed in a panel of human stomach and breast cancers (T) and their respective matched normal tissues (N) on RNA dot blots. 24P4C12 expression was seen in both stomach and breast cancers. The expression detected in normal adjacent tissues (isolated from diseased tissues) but not in normal tissues (isolated from healthy donors) may indicate that these tissues are not fully normal and that 24P4C12 may be expressed in early stage tumors.
The level of expression of 24P4C12 was analyzed and quantitated in a panel of patient cancer tissues. First strand cDNA was prepared from a panel of ovary patient cancer specimens (A), uterus patient cancer specimens (B), prostate cancer specimens (C), bladder cancer patient specimens (D), lung cancer patient specimens (E), pancreas cancer patient spedmens (F), colon cancer specimens (G), and kidney cancer specimens (H). Normalization was performed by PCR using primers to actin. Semi-quantitative PCR, using primers to 24P4C12, was performed at 26 and 30 cycles of amplification. Samples were run on an agarose gel, and PCR products were quantitated using the Alphalmager software. Expression was recorded as absent, low, medium or strong. Results show expression of 24P4C12 in the majority of patient cancer specimens tested, 73.3% of ovary patient cancer spedmens, 83.3% of uterus patient cancer specimens, 95.0% of prostate cancer specimens, 61.1 % of bladder cancer patient specimens, 80.6% of lung cancer patient specimens, 87.5% of pancreas cancer patient spedmens, 87.5% of colon cancer spedmens, 68.4% of clear cell renal carcinoma, 100% of papillary renal cell carcinoma.
The restricted expression of 24P4C12 in normal tissues and the expression detected in prostate cancer, ovary cancer, bladder cancer, colon cancer, lung cancer pancreas cancer, uterus cancer, kidney cancer, stomach cancer and breast cancer suggest that 24P4C12 is a potential therapeutic target and a diagnostic marker for human cancers.
Example 5: Transcript Variants of 24P4C12
Transcript variants are variants of mature mRNA from the same gene which arise by alternative transcription or alternative splicing. Alternative transcripts are transcripts from the same gene but start transcription at different points. Splice variants are mRNA variants spliced differently from the same transcript In eukaryotes, when a multi-exon gene is transcribed from genomic DNA, the initial RNA is spliced to produce functional mRNA, which has only exons and is used for translation into an amino acid sequence. Accordingly, a given gene can have zero to many alternative transcripts and each transcript can have zero to many splice variants. Each transcript variant has a unique exon makeup, and can have different coding and/or non-coding (5' or 3' end) portions, from the original transσipt Transcript variants can code for similar or different proteins with the same or a similar function or can encode proteins with different functions, and can be expressed in the same tissue at the same time, or in different tissues at the same time, or in the same tissue at different times, or in different tissues at different times. Proteins encoded by transcript variants can have similar or different cellular or extracellular localizations, e.g., secreted versus intracellular.
Transσipt variants are identified by a variety of art-accepted methods. For example, alternative transcripts and splice variants are identified by full-length cloning experiment, or by use of full-length transcript and EST sequences. First, all human ESTs were grouped into clusters which show direct or indirect identity with each other. Second, ESTs in the same cluster were further grouped into sub-clusters and assembled into a consensus sequence. The original gene sequence is compared to the consensus sequence(s) or other full-length sequences. Each consensus sequence is a potential splice variant for that gene. Even when a variant is identified that is not a full-length clone, that portion of the variant is very useful for antigen generation and for further cloning of the full-length splice variant, using techniques known in the art.
Moreover, computer programs are available in the art that identify transcript variants based on genomic sequences. Genomic-based transcript variant identification programs indude FgenesH (A. Salamov and V. Solovyev, "Ab initio gene finding in Drosophila genomic DNA," Genome Research. 2000 April; 10(4):516-22); Grail (URL at compbio.oml.gov/Grail-bin/EmptyGrailForm) and GenScan (URL at genes.mit.edu/GENSCAN.html). For a general discussion of splice variant identification protocols see., e.g., Southan, C, A genomic perspective on human proteases, FEBS Lett. 2001 Jun 8; 498(2-3):214-8; de Souza, S.J., ef a/., Identification of human chromosome 22 transcribed sequences with ORF expressed sequence tags, Proc. Natl Acad Sci U S A, 2000 Nov 7; 97(23): 12690-3.
To further confirm the parameters of a transcript variant a variety of techniques are available in the art, such as full-length cloning, proteomic validation, PCR-based validation, and 5' RACE validation, etc. (see e.g., Proteomic Validation: Brennan, S.O., ef al, Albumin banks peninsula: a new termination variant characterized by electrospray mass spectrometry, Biochem Biophys Acta. 1999 Aug 17;1433(1-2):321-6; Ferranti P, ef al, Differential splicing of pre-messenger RNA produces multiple forms of mature caprine alpha(s1)-casein, Eur J Biochem. 1997 Oct 1;249(1):1-7. For PCR-based Validation: Wellmann S, ef al, Specific reverse transcription-PCR quantification of vascular endothelial growth factor (VEGF) splice variants by LightCycler technology, Clin Chem. 2001 Apr;47(4):654-60; Jia, H.P., ef a/., Discovery of new human beta- defensins using a genomics-based approach, Gene. 2001 Jan 24; 263(1 -2):211-8. For PCR-based and 5' RACE Validation: Brigle, K.E., ef al, Organization of the murine reduced folate carrier gene and identification of variant splice forms, Biochem Biophys Acta. 1997 Aug 7; 1353(2): 191-8).
It is known in the art that genomic regions are modulated in cancers. When the genomic region to which a gene maps is modulated in a particular cancer, the alternative transcripts or splice variants of the gene are modulated as well.
Disclosed herein is that 24P4C12 has a particular expression profile related to cancer Alternative fransσipts and splice variants of 24P4C12 may also be involved in cancers in the same or different tissues, thus serving as tumor-assoαated markers/antigens
The exon composition of the oπginal transcript, designated as 24P4C12 v 1, is shown in Table LI Using the full- length gene and EST sequences, three transcript variants were identified, designated as 24P4C12 v 7, v 8 and v 9 Compared with 24P4C12 v 1 , transcnpt variant 24P4C12 v 7 has spliced out exons 10 and 11 from vanant 24P4C12 v 1 , as shown in Figure 12 Variant 24P4C12 v 8 inserted 36 bp in between 1931 and 1932 of vanant 24P4C12 v 1 and variant 24P4C12 v 9 replaced with 36 bp the segment 1136-1163 of variant 24P4C12 v 1 Theoretically, each different combination of exons in spatial order, e g exons 2 and 3 is a potential splice vanant Figure 12 shows the schematic alignment of exons of the four transcript vaπants
Tables Lll through LXIII are set forth on a vanant by variant basis Tables LH, LVI, and LX show nucleotide sequences of the transcnpt variant Tables Lltl, LVII, and LXI show the alignment of the transcnpt variant with the nucleic acid sequence of 24P4C12 v 1 Tables LIV, LVIII, and LXII lay out the ammo acid translation of the transcript variant for the identified reading frame orientation Tables LV, LIX, and LXIII display alignments of the am o acid sequence encoded by the splice variant with that of 24P4C12 v 1
Example 6' Single Nucleotide Polymorphisms of 24P4C12
A Single Nucleotide Polymorphism (SNP) is a single base pair vaπation in a nucleotide sequence at a specific location At any given point of the genome, there are four possible nucleotide base pairs A/T, C/G, G/C and T/A Genotype refers to the specific base pair sequence of one or more locations in the genome of an individual Haplotype refers to the base pair sequence of more than one location on the same DNA molecule (or the same chromosome in higher organisms), often in the context of one gene or in the context of several tightly linked genes SNPs that occur on a cDNA are called cSNPs These cSNPs may change ammo acids of the protein encoded by the gene and thus change the functions of the protein Some SNPs cause inherited diseases, others contribute to quantitative variations in phenotype and reactions to environmental factors including diet and drugs among individuals Therefore, SNPs and/or combinations of alleles (called haplotypes) have many applications, including diagnosis of inherited diseases, determination of drug reactions and dosage, identification of genes responsible for diseases, and analysis of the genetic relationship between individuals (P Nowotny, J M Kwon and A M. Goate, " SNP analysis to dissect human traits," Curr Opin Neurobiol 2001 Oct, 11(5) 637-641, M Pir ohamed and B K Park, "Genetic susceptibility to adverse drug reactions," Trends Pharmacol Sα 2001 Jun, 22(6) 298- 305, J H Riley, C J Allan, E Lai and A Roses, " The use of single nudeotide polymorphisms in the isolation of common disease genes," Pharmacogenomics 2000 Feb, 1(1) 3947, R Judson, J C Stephens and A Windemuth "The predictive power of haplotypes in clinical response," Pharmacogenomics 2000 feb, 1(1).15-26)
SNPs are identified by a vaπety of art-accepted methods (P Bean, "The promising voyage of SNP target discovery," Am Clin Lab 2001 Oct-Nov, 20(9) 18-20, K M Weiss, "In search of human variation," Genome Res 1998 Jul, 8(7) 691-697, M M She, "Enabling large-scale pharmacogenetic studies by high-throughput mutation detection and genotyping technologies," Clin Chem 2001 Feb, 47(2) 164-172) For example, SNPs are identified by sequencing DNA fragments that show polymorphism by gel-based methods such as restriction fragment length polymorphism (RFLP) and denatuπng gradient gel electrophoresis (DGGE) They can also be discovered by direct sequenαng of DNA samples pooled from different individuals or by comparing sequences from different DNA samples With the rapid accumulation of sequence data in public and pπvate databases, one can discover SNPs by compaπng sequences using computer programs (Z Gu, L Hillier and P Y Kwok, "Single nucleotide polymorphism hunting in cyberspace," Hum Mutat 1998, 12(4) 221-225) SNPs can be venfied and genotype or haplotype of an individual can be determined by a vaπety of methods including direct
sequencing and high throughput microarrays (P. Y. Kwok, "Methods for genotyping single nucleotide polymorphisms," Annu. Rev. Genomics Hum. Genet.2001; 2:235-258; M. Kokoris, K. Dix, K. Moynihan, J. Mathis, B. Erwin, P. Grass, B. Hines and A. Duesterhoeft, "High-throughput SNP genotyping with the Masscode system," Mol. Diagn. 2000 Dec; 5(4):329-340). Using the methods described above, five SNPs were identified in the original transcript, 24P4C12 v.1, at positions 542 (G/A), 564 (G/A), 818 (C/T), 981(A/G) and 1312 (NC). The transσipts or proteins with alternative alleles were designated as variants 24P4C12 v.2, v.3, v.4, v.5 and v.6, respectively. Figure 10 shows the schematic alignment of the SNP variants. Figure 11 shows the schematic alignment of protein variants, corresponding to nucleotide variants. Nucleotide variants that code for the same amino acid sequence as variant 1 are not shown in Figure 11. These alleles of the SNPs, though shown separately here, can occur in different combinations (haplotypes) and in any one of the transcript variants (such as 24P4C12 v.7) that contains the sequence context of the SNPs.
Example 7: Production of Recombinant 24P4C12 in Prokaryotic Systems
To express recombinant 24P4C12 and 24P4C12 variants in prokaryotic cells, the full or partial length 24P4C12 and 24P4C12 variant cDNA sequences are cloned into any one of a variety of expression vectors known in the art. The full length cDNA, or any 8, 9, 10, 11 , 12, 13, 14, 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30 or more contiguous amino acids from 24P4C12, variants, or analogs thereof are used.
A. In vitro transcription and translation constructs: pCRII: To generate 24P4C12 sense and anti-sense RNA probes for RNA in situ investigations, pCRII constructs (Invitrogen, Carlsbad CA) are generated encoding either all or fragments of the 24P4C12 cDNA. The pCRII vector has Sp6 and T7 promoters flanking the insert to drive the transcription of 24P4C12 RNA for use as probes in RNA in situ hybridization experiments. These probes are used to analyze the cell and tissue expression of 24P4C12 at the RNA level. Transcribed 24P4C12 RNA representing the cDNA amino acid coding region of the 24P4C12 gene is used in in vitro translation systems such as the TnT™ Coupled Reticulolysate System (Promega, Corp., Madison, WI) to synthesize 24P4C12 protein.
B. Bacterial Constructs: pGEX Constructs: To generate recombinant 24P4C12 proteins in bacteria that are fused to the Glutathione S- transferase (GST) protein, all or parts of the 24P4C12 cDNA or variants are cloned into the GST- fusion vector of the pGEX family (Amersham Pharmacia Biotech, Piscataway, NJ). These constructs allow controlled expression of recombinant 24P4C12 protein sequences with GST fused at the amino-terminus and a six histidine epitope (6X His) at the carboxyl- terminus. The GST and 6X His tags permit purification of the recombinant fusion protein from induced bacteria with the appropriate affinity matrix and allow recognition of the fusion protein with anti-GST and anti-His antibodies. The 6X His tag is generated by adding 6 histidine codons to the cloning primer at the 3' end, e.g., of the open reading frame (ORF). A proteolyfic cleavage site, such as the PreScission™ recognition site in pGEX-6P-1, may be employed such that it permits deavage of the GST tag from 24P4C12-related protein. The ampicillin resistance gene and pBR322 origin permits selection and maintenance of the pGEX plasmids in £ coli. pMAL Constructs: To generate, in bacteria, recombinant 24P4C12 proteins that are fused to maltose-binding protein (MBP), all or parts of the 24P4C12 cDNA protein coding sequence are fused to the MBP gene by cloning into the pMAL-c2X and pMAL-p2X vectors (New England Biolabs, Beverly, MA). These constructs allow controlled expression of recombinant 24P4C12 protein sequences with MBP fused at the amino-terminus and a 6X His epitope tag at the carboxylτ terminus. The MBP and 6X His tags permit purification of the recombinant protein from induced bacteria with the appropriate affinity matrix and allow recognition of the fusion protein with anti-MBP and anti-His antibodies. The 6X His epitope tag is generated by adding 6 histidine codons to the 3' cloning primer. A Factor Xa recognition site permits cleavage of the pMAL
tag from 24P4C12. The pMAL-c2X and pMAL-p2X vectors are optimized to express the recombinant protein in the cytoplasm or periplasm respectively. Periplasm expression enhances folding of proteins with disulfide bonds. pET Constructs: To express 24P4C12 in bacterial cells, all or parts of the 24P4C12 cDNA protein coding sequence are cloned into the pET family of vectors (Novagen, Madison, WI). These vectors allow tightly controlled expression of recombinant 24P4C12 protein in bacteria with and without fusion to proteins that enhance solubility, such as NusA and thioredoxin (Trx), and epitope tags, such as 6X His and S-Tag™ that aid purification and detection of the recombinant protein. For example, constructs are made utilizing pET NusA fusion system 43.1 such that regions of the 24P4C12 protein are expressed as amino-terminal fusions to NusA.
0 Yeast Constructs: pESC Constructs: To express 24P4C12 in the yeast species Saccharamyces cerevisiae for generation of recombinant protein and functional studies, all or parts of the 24P4C12 cDNA protein coding sequence are cloned into the pESC family of vectors each of which contain 1 of 4 selectable markers, HIS3, TRP1 , LEU2, and URA3 (Stratagene, La Jolla, CA). These vectors allow controlled expression from the same plasmid of up to 2 different genes or doned sequences containing either Flag™ or Myc epitope tags in the same yeast cell. This system is useful to confirm protein-protein interactions of 24P4C12. In addition, expression in yeast yields similar post-translational modifications, such as glycosylatjons and phosphorylations, that are found when expressed in eukaryotic cells. pESP Constructs: To express 24P4C12 in the yeast species Saccharomyces pombe, all or parts of the 24P4C12 cDNA protein coding sequence are cloned into the pESP family of vectors. These vectors allow controlled high level of expression of a 24P4C12 protein sequence that is fused at either the amino terminus or at the carboxyl terminus to GST which aids purification of the recombinant protein. A Flag™ epitope tag allows detection of the recombinant protein with anti- Flag™ antibody.
Example 8: Production of Recombinant 24P4C12 in Higher Eukaryotic Systems A. Mammalian Constructs:
To express recombinant 24P4C12 in eukaryotic cells, the full or partial length 24P4C12 cDNA sequences can be cloned into any one of a variety of expression vectors known in the art. One or more of the following regions of 24P4C12 are expressed in these constructs, amino acids 1 to 710, or any 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 or more contiguous amino acids from 24P4C12 v.1 through v.6; amino acids 1 to 598, or any 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 or more contiguous amino acids from 24P4C12 v.7; amino acids 1 to 722, or any 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 or more contiguous amino acids from 24P4C12 v.8, amino acids 1 to 712, or any 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30 or more contiguous amino adds from 24P4C12 v.9, variants, or analogs thereof.
The constructs can be transfected into any one of a wide variety of mammalian cells such as 293T cells. Transfected 293T cell lysates can be probed with the anti-24P4C12 polydonal serum, described herein. pcDNA3.1/MvcHis Constructs: To express 24P4C12 in mammalian cells, a 24P4C12 ORF, or portions thereof, of 24P4C12 with a consensus Kozak translation initiation site was doned into pcDNA3.1/MycHis Version A (Invitrogen, Carlsbad, CA). Protein expression is driven from the cytomegalovirus (CMV) promoter. The recombinant proteins have the myc epitope and 6X His epitope fused to the carboxyl-terminus. The pcDNA3.1/MycHis vector also contains the bovine growth hormone (BGH) polyadenylation signal and transcription termination sequence to enhance mRNA stability, along with the SV40 origin for episomal replication and simple vector rescue in cell lines expressing the large T antigen. The Neomydn resistance gene can be used, as it allows for selection of mammalian cells expressing the protein and the ampicillin
resistance gene and ColE1 origin permits selection and maintenance of the plasmid in £ coli. Figure 24 demonstrates expression of 24P4C12 from the pcDNA3.1/MycHis construct in transiently transfected 293T cells. pcDNA4/HisMax Constructs: To express 24P4C12 in mammalian cells, a 24P4C12 ORF, or portions thereof, of 24P4C12 are cloned into pcDNA4/HisMax Version A (Invitrogen, Carlsbad, CA). Protein expression is driven from the cytomegalovirus (CMV) promoter and the SP16 translational enhancer. The recombinant protein has Xpress™ and six histidine (6X His) epitopes fused to the amino-terminus. The pcDNA4/HisMax vector also contains the bovine growth hormone (BGH) polyadenylation signal and transcription termination sequence to enhance mRNA stability along with the SV40 origin for episomal replication and simple vector rescue in cell lines expressing the large T antigen. The Zeocin resistance gene allows for selection of mammalian cells expressing the protein and the ampicillin resistance gene and ColE1 origin permits selection and maintenance of the plasmid in £ coli.
PCDNA3.1/CT-GFP-TOP0 Construct: To express 24P4C12 in mammalian cells and to allow detection of the recombinant proteins using fluorescence, a 24P4C12 ORF, or portions thereof, with a consensus Kozak translation initiation site are cloned into pcDNA3.1/CT-GFP-TOPO (Invitrogen, CA). Protein expression is driven from the cytomegalovirus (CMV) promoter. The recombinant proteins have the Green Fluorescent Protein (GFP) fused to the carboxyl-terminus facilitating non-invasive, in vivo detection and cell biology studies. The pcDNA3.1CT-GFP-TOPO vector also contains the bovine growth hormone (BGH) polyadenylation signal and transcription termination sequence to enhance mRNA stability along with the SV40 origin for episomal replication and simple vector rescue in cell lines expressing the large T antigen. The Neomycin resistance gene allows for selection of mammalian cells that express the protein and the ampicillin resistance gene and ColE1 origin permits selection and maintenance of the plasmid in £ coli. Additional constructs with an amino- terminal GFP fusion are made in pcDNA3,1/NT-GFP-TOPO spanning the entire length of a 24P4C12 protein. pTagδ: A 24P4C12 ORF, or portions thereof, were cloned into pTag-5. This vector is similar to pAPtag but without the alkaline phosphatase fusion. This construct generates 24P4C12 protein with an amino-terminal lgGκ signal sequence and myc and 6X His epitope tags at the carboxyl-terminus that facilitate detection and affinity purification. The resulting recombinant 24P4C12 protein were optimized for secretion into the media of transfected mammalian cells, and is used as immunogen or ligand to identify proteins such as ligands or receptors that interact with the 24P4C12 proteins. Protein expression is driven from the CMV promoter. The Zeocin resistance gene present in the vector allows for selection of mammalian cells expressing the protein, and the ampicillin resistance gene permits selection of the plasmid in £ coli. Figure 26 shows expression of 24P4C12 from two different pTagδ constructs.
PAPtag: A 24P4C12 ORF, or portions thereof, is cloned into pAPtag-5 (GenHunter Corp. Nashville, TN). This construct generates an alkaline phosphatase fusion at the carboxyl-terminus of a 24P4C12 protein while fusing the lgGκ signal sequence to the amino-terminus. Constructs are also generated in which alkaline phosphatase with an amino- terminal lgGκ signal sequence is fused to the amino-terminus of a 24P4C12 protein. The resulting recombinant 24P4C12 proteins are optimized for secretion into the media of transfected mammalian cells and can be used to identify proteins such as ligands or receptors that interact with 24P4C12 proteins. Protein expression is driven from the CMV promoter and the recombinant proteins also contain myc and 6X His epitopes fused at the carboxyl-terminus that facilitates detection and purification. The Zeocin resistance gene present in the vector allows for selection of mammalian cells expressing the recombinant protein and the ampicillin resistance gene permits selection of the plasmid in E coli.
PsecFc: A 24P4C12 ORF, or portions thereof, is also cloned into psecFc. The psecFc vector was assembled by doning the human immunoglobulin G1 (IgG) Fc (hinge, CH2, CH3 regions) into pSecTag2 (Invitrogen, California). This construct generates an lgG1 Fc fusion at the carboxyl-terminus of the 24P4C12 proteins, while fusing the IgGK signal sequence to N-terminus. 24P4C12 fusions utilizing the murine lgG1 Fc region are also used. The resulting recombinant 24P4C12 proteins are optimized for secretion into the media of transfected mammalian cells, and can be used as
immunogens or to identify proteins such as ligands or receptors that interact with 24P4C12 protein. Protein expression is driven from the CMV promoter. The hygromycin resistance gene present in the vector allows for selection of mammalian cells that express the recombinant protein, and the ampicillin resistance gene permits selection of the plasmid in E coli. pSRα Constructs: To generate mammalian cell lines that express 24P4C12 constitutively, 24P4C12 ORF, or portions thereof, of 24P4C12 were cloned into pSRα constructs. Amphotropic and ecofropic retroviruses were generated by transfection of pSRα constructs into the 293T-10A1 packaging line or co-transfection of pSRα and a helper plasmid (containing deleted packaging sequences) into the 293 cells, respectively. Theretrovirus is used to infect a variety of mammalian cell lines, resulting in the integration of the cloned gene, 24P4C12, into the host cell-lines. Protein expression is driven from a long terminal repeat (LTR). The Neomycin resistance gene present in the vector allows for selection of mammalian cells that express the protein, and the ampicillin resistance gene and ColE1 origin permit selection and maintenance of the plasmid in £ coli. The retroviral vectors can thereafter be used for infection and generation of various cell lines using, for example, PC3, NIH 3T3, TsuPrl, 293 or rat-1 cells. Figure 23 shows RNA expression of 24P4C12 driven from the 24P4C12.pSRa construct in stably transduced PC3, 3T3 and 300.19 cells. Figure 25 shows 24P4C12 protein expression in PC3 cells stably transduced with 24P4C12.pSRa construct.
Additional pSRα constructs are made that fuse an epitope tag such as the FLAG™ tag to the carboxyl-terminus of 24P4C12 sequences to allow detection using anti-Flag antibodies. For example, the FLAG™ sequence 5' gat tac aag gat gac gac gat aag 3' (SEQ ID NO: 45) is added to cloning primer at the 3' end of the ORF. Additional pSRα constructs are made to produce both amino-terminal and carboxyl-terminal GFP and myc/6X His fusion proteins of the full-length 24P4C12 proteins.
Additional Viral Vectors: Additional constructs are made for viral-mediated delivery and expression of 24P4C12. High virus titer leading to high level expression of 24P4C12 is achieved in viral delivery systems such as adenoviral vectors and herpes amplicon vectors. A 24P4C12 coding sequences or fragments thereof are amplified by PCR and subdoned into the AdEasy shuttle vector (Stratagene). Recombination and virus packaging are performed according to the manufacturer's instructions to generate adenoviral vectors. Alternatively, 24P4C12 coding sequences or fragments thereof are cloned into the HSV-1 vector (Imgenex) to generate heφes viral vectors. The viral vectors are thereafter used for infection of various cell lines such as PC3, NIH 3T3, 293 or rat-1 cells.
Regulated Expression Systems: To control expression of 24P4C12 in mammalian cells, coding sequences of 24P4C12, or portions thereof, are cloned into regulated mammalian expression systems such as the T-Rex System (Invitrogen), the GeneSwitch System (Invitrogen) and the tightly-regulated Ecdysone System (Sratagene). These systems allow the study of the temporal and concentration dependent effects of recombinant 24P4C12. These vectors are thereafter used to control expression of 24P4C12 in various cell lines such as PC3, NIH 3T3, 293 or rat-1 cells.
B. Baculovirus Expression Systems
To generate recombinant 24P4C12 proteins in a baculovirus expression system, 24P4C12 ORF, or portions thereof, are cloned into the baculovirus transfer vector pBlueBac 4.5 (Invitrogen), which provides a His-tag at the N-terminus. Specifically, pBlueBac-24P4C12 is co-transfected with helper plasmid pBac-N-Blue (Invitrogen) into SF9 (Spodoptera frugiperda) insect cells to generate recombinant baculovirus (see Invitrogen instruction manual for details). Baculovirus is then collected from cell supernatant and purified by plaque assay.
Recombinant 24P4C12 protein is then generated by infection of HighFive insect cells (Invitrogen) with purified baculovirus. Recombinant 24P4C12 protein can be detected using anti-24P4C12 or anti-His-tag antibody. 24P4C12 protein can be purified and used in various cell-based assays or as immunogen to generate polyclonal and monoclonal antibodies specific for 24P4C12.
Example 9: Antigenicity Profiles and Secondary Structure
Figures 5-9 depict graphically five amino acid profiles of the 24P4C12 variant 1, assessment available by accessing the ProtScale website located on the World Wide Web at (.expasy.ch/cgi-bin/protscale.pl) on the ExPasy molecular biology server.
These profiles: Figure 5, Hydrophilidty, (Hopp T.P., Woods K.R., 1981. Proc. Natl. Acad. Sci. U.S.A. 78:3824- 3828); Figure 6, Hydropathicity, (Kyte J., Doolittle R.F., 1982. J. Mol. Biol. 157:105-132); Figure 7, Percentage Accessible Residues (Janin J., 1979 Nature 277:491492); Figure 8, Average Flexibility, (Bhaskaran R., and Ponnuswamy P.K., 1988. Int. J. Pept. Protein Res. 32:242-255); Figure 9, Beta-turn (Deleage, G., Roux B. 1987 Protein Engineering 1:289-294); and optionally others available in the art, such as on the ProtScale website, were used to identify antigenic regions of the 24P4C12 protein. Each of the above amino acid profiles of 24P4C12 were generated using the following ProtScale parameters for analysis: 1 ) A window size of 9; 2) 100% weight of the window edges compared to the window center; and, 3) amino acid profile values normalized to lie between 0 and 1.
Hydrophilidty (Figure 5), Hydropathicity (Figure 6) and Percentage Accessible Residues (Figure 7) profiles were used to determine stretches of hydrophilic amino acids (i.e., values greater than 0.5 on the Hydrophilidty and Percentage Accessible Residues profile, and values less than 0.5 on the Hydropathicity profile). Such regions are likely to be exposed to the aqueous environment, be present on the surface of the protein, and thus available for immune recognition, such as by antibodies.
Average Flexibility (Figure 8) and Beta-turn (Figure 9) profiles determine stretches of amino adds (i.e., values greater than 0.5 on the Beta-turn profile and the Average Flexibility profile) that are not constrained in secondary structures such as beta sheets and alpha helices. Such regions are also more likely to be exposed on the protein and thus accessible to immune recognition, such as by antibodies.
Antigenic sequences of the 24P4C12 protein and of the variant proteins indicated, e.g., by the profiles set forth in Figure 5, Figure 6, Figure 7, Figure 8, and/or Figure 9 are used to prepare immunogens, either peptides or nucleic acids that encode them, to generate therapeutic and diagnostic anti-24P4C12 antibodies. The immunogen can be any 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50 or more than 50 contiguous amino acids, or the corresponding nucleic acids that encode them, from the 24P4C12 protein variants listed in Figures 2 and 3. In particular, peptide immunogens of the invention can comprise, a peptide region of at least 5 amino acids of Figures 2 and 3 in any whole number increment that includes an amino acid position having a value greater than 0.5 in the Hydrophilidty profile of Figure 5; a peptide region of at least 5 amino acids of Figures 2 and 3 in any whole number increment that includes an amino acid position having a value less than 0.5 in the Hydropathicity profile of Figure 6 ; a peptide region of at least 5 amino acids of Figures 2 and 3 in any whole number increment that includes an amino add position having a value greater than 0.5 in the Percent Accessible Residues profile of Figure 7 ; a peptide region of at least 5 amino acids of Figures 2 and 3 in any whole number increment that includes an amino acid position having a value greater than 0.5 in the Average Flexibility profile on Figure 8 ; and, a peptide region of at least 5 amino acids of Figures 2 and 3 in any whole number increment that includes an amino acid position having a value greater than 0.5 in the Beta-turn profile of Figure 9 . Peptide immunogens of the invention can also comprise nucleic acids that encode any of the forgoing.
All immunogens of the invention, peptide or nudeic acid, can be embodied in human unit dose form, or comprised by a composition that includes a pharmaceutical excipient compatible with human physiology.
The secondary structure of 24P4C12 variant 1 , namely the predicted presence and location of alpha helices, extended strands, and random coils, are predicted from the respective primary amino acid sequences using the HNN - Hierarchical Neural Network method (Guermeur, 1997, http://pbil.ibcp.fr/cgi-bin/npsa_automat.pl?page=npsa_nn.html),
accessed from the ExPasy molecular biology server (http://www.expasy.ch/tools/). The analysis indicates that 24P4C12 variant 1 is composed of 53.94% alpha helix, 9.44% extended strand, and 36.62% random coil (Figure 13a). Analysis for the potential presence of transmembrane domains in 24P4C12 variants were carried out using a variety of transmembrane prediction algorithms accessed from the ExPasy molecular biology server (http://www.expasy.ch/tools/). Shown graphically are the results of analysis of variant 1 depicting the presence and location of 10 transmembrane domains using the TMpred program (Figure 13b) and TMHMM program (Figure 13c). The results of each program, namely the amino acids encoding the transmembrane domains are summarized in Table L. Example 10: Generation of 24P4C12 Polyclonal Antibodies
Polyclonal antibodies can be raised in a mammal, for example, by one or more injections of an immunizing agent and, if desired, an adjuvant. Typically, the immunizing agent and/or adjuvant will be injected in the mammal by multiple subcutaneous or intraperitoneal injections. In addition to immunizing with the full length 24P4C12 protein, computer algorithms are employed in design of immunogens that, based on amino acid sequence analysis contain characteristics of being antigenic and available for recognition by the immune system of the immunized host (see the Example entitled "Antigenicity Profiles"). Such regions would be predicted to be hydrophilic, flexible, in beta-turn conformations, and be exposed on the surface of the protein (see, e.g., Figure 5, Figure 6, Figure 7, Figure 8, or Figure 9 for amino acid profiles that indicate such regions of 24P4C12 and variants).
For example, 24P4C12 recombinant bactenal fusion proteins or peptides containing hydrophilic, flexible, beta-turn regions of 24P4C12 variant proteins are used as antigens to generate polyclonal antibodies in New Zealand White rabbits. For example, such regions include, but are not limited to, amino acids 1 -34, amino acids 118-135, amino acids 194-224, amino acids 280-290, and amino acids 690-710, of 24P4C12 variants 1. It is useful to conjugate the immunizing agent to a protein known to be immunogenic in the mammal being immunized. Examples of such immunogenic proteins include, but are not limited to, keyhole limpet hemocyanin (KLH), serum albumin, bovine thyroglobulin, and soybean trypsin inhibitor. In one embodiment, a peptide encoding amino acids 1-14 of 24P4C12 variant 1 was conjugated to KLH and used to immunize a rabbit. This antiserum exhibited a high liter to the peptide (>10,000) and recognized 24P4C12 in transfected 293T cells by Western blot and flow cytometry (Figure 24) and in stable recombinant PC3 cells by Western blot and immunohistochemistry (Figure 25). Alternatively the immunizing agent may include all or portions of the 24P4C12 variant proteins, analogs or fusion proteins thereof. For example, the 24P4C12 variant 1 amino acid sequence can be fused using recombinant DNA techniques to any one of a variety of fusion protein partners that are well known in the art, such as glutathione-S-transferase (GST) and HIS tagged fusion proteins. Such fusion proteins are purified from induced bacteria using the appropriate affinity matrix.
In one embodiment, a GST-fusion protein encoding amino acids 379453, encompassing the third predicted extracellular loop of variant 1 , is produced, purified, and used as immunogen. Other recombinant bacterial fusion proteins that may be employed include maltose binding protein, LacZ, thioredoxin, NusA, or an immunoglobulin constant region (see the section entitled "Production of 24P4C12 in Prokaryotic Systems" and Current Protocols In Molecular Biology, Volume 2, Unit 16, Frederick M. Ausubul et al. eds., 1995; Linsley, P.S., Brady, W., Urnes, M., Grosmaire, L, Damle, N., and Ledbetter, L(1991) J.Exp. Med. 174, 561-566).
In addition to bacterial derived fusion proteins, mammalian expressed protein antigens are also used. These antigens are expressed from mammalian expression vectors such as the Tag5 and Fc-fusion vectors (see the Example entitled "Production of Recombinant 24P4C12 in Eukaryotic Systems"), and retains post-translational modifications such as glycosylations found in native protein. In two embodiments, the predicted 1 st and third extracellular loops of variant 1 , amino acids 59-227 and 379453 respectively, were each doned into the Tag5 mammalian seσetion vector and expressed in 293T cells (Figure 26). Each recombinant protein is then purified by metal chelate chromatography from tissue culture
supernatants and/or lysates of 293T cells stably expressing the recombinant vector. The purified Tag524P4C12 protein is then used as immunogen.
During the immunization protocol, it is useful to mix or emulsify the antigen in adjuvants that enhance the immune response of the host animal. Examples of adjuvants include, but are not limited to, complete Freund's adjuvant (CFA) and MPL-TDM adjuvant (monophosphoryl Lipid A, synthetic trehalose dicorynomycolate).
In a typical protocol, rabbits are initially immunized subcutaneously with up to 200 μg, typically 100-200 μg, of fusion protein or peptide conjugated to KLH mixed in complete Freund's adjuvant (CFA). Rabbits are then injected subcutaneously every two weeks with up to 200 μg, typically 100-200 μg, of the immunogen in incomplete Freund's adjuvant (IFA). Test bleeds are taken approximately 7-10 days following each immunization and used to monitor the tiler of the aπtiserum by ELISA.
To test reactivity and specificity of immune serum, such as the rabbit serum derived from immunization with a KLH- conjugated peptide encoding amino acids 1-14 of variant 1, the full-length 24P4C12 variant 1 cDNA is cloned into pCDNA 3.1 myc-his or retroviral expression vectors (Invitrogen, see the Example entitled "Production of Recombinant 24P4C12 in Eukaryotic Systems"). After transfection of the constructs into 293T cells or transduction of PC3 with 24P4C12 retrovirus, cell lysates are probed with the antι-24P4C12 serum and with anti-His antibody (Santa Cruz Biotechnologies, Santa Cruz, CA) to determine specific reactivity to denatured 24P4C12 protein using the Western blot technique. As shown in Figures 24 and 25 the antiseru specifically recognizes 24P4C12 protein in 293T and PC3 cells. In addition, the immune serum is tested by fluorescence microscopy, flow cytometry, and immunohistochemistry (Figure 25) and immunoprecipitation against 293T and other recombinant 24P4C12-expressing cells to determine specific recognition of native protein. Western blot, immunoprecipitation, fluorescent microscopy, immunohistochemistry and flow cytometric techniques using cells that endogenously express 24P4C12 are also carried out to test reactivity and specificity.
Anti-serum from rabbits immunized with 24P4C12 variant fusion proteins, such as GST and MBP fusion proteins, are purified by depletion of antibodies reactive to the fusion partner sequence by passage over an affinity column containing the fusion partner either alone or in the context of an irrelevant fusion protein. For example, antiserum derived from a GST- 24P4C12 fusion protein encoding amino acids 379453 of variant 1 is first purified by passage over a column of GST protein covalently coupled to AffiGel matrix (BioRad, Hercules, Calif.). The antiserum is then affinity purified by passage over a column composed of a MBP-fusion protein also encoding amino acids 379-453 covalently coupled to Affigel matrix. The serum is then further purified by protein G affinity chromatography to isolate the IgG fraction. Sera from other His-tagged antigens and peptide immunized rabbits as well as fusion partner depleted sera are affinity purified by passage over a column matrix composed of the original protein immunogen or free peptide.
Example 11 : Generation of 24P4C12 Monoclonal Antibodies (mAbs)
In one embodiment, therapeutic mAbs to 24P4C12 variants comprise those that react with epitopes specific for each variant protein or specific to sequences in common between the variants that would disrupt or modulate the biological function of the 24P4C12 variants, for example those that would disrupt the interaction with ligands and substrates or disrupt its biological activity. Immunogens for generation of such mAbs include those designed to encode or contain the entire 24P4C12 protein variant sequence, regions of the 24P4C 12 protein variants predicted to be antigenic from computer analysis of the amino acid sequence (see, e.g., Figure 5, Figure 6, Figure 7, Figure 8, or Figure 9, and the Example entitled "Antigenicity Profiles"). Immunogens include peptides, recombinant bacterial proteins, and mammalian expressed Tag 5 proteins and human and murine IgG FC fusion proteins. In addition, cells engineered to express high levels of a respective 24P4C 12 variant, such as 293T-24P4C12 variant 1 or 300.19-24P4C12 variant 1 murine Pre-B cells, are used to immunize mice.
To generate mAbs to a 24P4C12 variant mice are first immunized intraperitoneally (IP) with, typically, 10-50 μg of protein immunogen or 10724P4C12-expressing cells mixed in complete Freund's adjuvant. Mice are then subsequently immunized IP every 24 weeks with, typically, 10-50 μg of protein immunogen or 107 cells mixed in incomplete Freund's adjuvant Alternatively, MPL-TDM adjuvant is used in immunizations. In one embodiment, mice were immunized as above with 300.19-24P4C12 cells in complete and then incomplete Freund's adjuvant, and subsequently sacrificed and the spleens harvested and used for fusion and hybridoma generation. As is can be seen in Figure 27, 2 hybridomas were generated whose antibodies specifically recognize 24P4C12 protein expressed in 293T cells by flow cytometry. In addition to the above protein and cell-based immunization strategies, a DNA-based immunization protocol is employed in which a mammalian expression vector encoding a 24P4C12 variant sequence is used to immunize mice by direct injection of the plasmid DNA. In one embodiment, a Tag5 mammalian secretion vector encoding amino acids 59-227 of the variant 1 sequence (Figure 26) was used to immunize mice. Subsequent booster immunizations are then carried out with the purified protein. In another example, the same amino acids are cloned into an Fc-fusion secretion vector in which the 24P4C12 variant 1 sequence is fused at the amino-terminus to an IgK leader sequence and at the carboxyl-terminus to the coding sequence of the human or murine IgG Fc region. This recombinant vector is then used as immunogen. The plasmid immunization protocols are used in combination with purified proteins as above and with cells expressing the respective 24P4C12 variant.
During the immunization protocol, test bleeds are taken 7-10 days following an injection to monitor titer and spedfidty of the immune response. Once appropriate reactivity and specificity is obtained as determined by ELISA, Western blotting, immunoprecipitation, fluorescence microscopy, immunohistochemistry, and flow cytometric analyses, fusion and hybridoma generation is then carried out with established procedures well known in the art (see, e.g., Harlow and Lane, 1988).
In one embodiment for generating 24P4C12 variant 8 specific monoclonal antibodies, a peptide encoding amino acids 643-654 (RNPITPTGHVFQ) (SEQ ID NO: 46) of 24P4C12 variants is synthesized, coupled to KLH and used as immunogen. Balb C mice are initially immunized intraperitoneally with 25 μg of the KLH-24P4C12 variant 8 peptide mixed in complete Freund's adjuvant. Mice are subsequently immunized every two weeks with 25 μg of the antigen mixed in incomplete Freund's adjuvant for a total of three immunizations. ELISA using the free peptide determines the reactivity of serum from immunized mice. Reactivity and specificity of serum to full length 24P4C12 variant 8 protein is monitored by Western blotting, immunoprecipitation and flow cytometry using 293T cells transfected with an expression vector encoding the 24P4C12 variant 8 cDNA compared to cells transfected with the other 24P4C12 variants (see e.g., the Example entitled "Production of Recombinant 24P4C12 in Eukaryotic Systems"). Other recombinant 24P4C12 variant 8-expressing cells or cells endogenously expressing 24P4C12 variant 8 are also used. Mice showing the strongest specific reactivity to 24P4C12 variant 8 are rested and given a final injection of antigen in PBS and then sacrificed four days later. The spleens of the sacrificed mice are harvested and fused to SPO/2 myeloma cells using standard procedures (Harlow and Lane, 1988). Supernatants from HAT selected growth wells are sσeened by ELISA, Western blot, immunoprecipitation, fluorescent microscopy, and flow cytometry to identify 24P4C12 variant 8-specifϊc antibody-producing clones. A similar strategy is also used to derive 24P4C12 variant 9-specific antibodies using a peptide encompassing amino acids 379-388 (PLPTQPATLG) (SEQ ID NO: 47).
The binding affinity of a 24P4C12 monoclonal antibody is determined using standard technologies. Affinity measurements quantify the strength of antibody to epitope binding and are used to help define which 24P4C12 monoclonal antibodies, preferred for diagnostic or therapeutic use, as appreciated by one of skill in the art. The BIAcore system (Uppsala, Sweden) is a preferred method for determining binding affinity. The BIAcore system uses surface plasmon resonance (SPR, Welford K. 1991, Opt. Quant. Elect. 23:1; Morton and Myszka, 1998, Methods in Enzymology 295: 268) to
monitor bimolecular interactions in real time. BIAcore analysis conveniently generates association rate constants, dissodation rate constants, equilibrium dissociation constants, and affinity constants.
Example 12: HLA Class I and Class II Binding Assays
HLA class I and class II binding assays using purified HLA molecules are performed in accordance with disclosed protocols (e.g., PCT publications WO 94/20127 and WO 94/03205; Sidney ef al, Current Protocols in Immunology 18.3.1 (1998); Sidney, ef al, J. Immunol 154:247 (1995); Sette, ef al., Mol Immunol. 31:813 (1994)). Briefly, purified MHC molecules (5 to 500 nM) are incubated with various unlabeled peptide inhibitors and 1-10 nM 125l-radiolabeled probe peptides as described. Following incubation, MHC-peptide complexes are separated from free peptide by gel filtration and the fraction of peptide bound is determined. Typically, in preliminary experiments^each MHC preparation is titered in the presence of fixed amounts of radiolabeled peptides to determine the concentration of HLA molecules necessary to bind 10- 20% of the total radioactivity. All subsequent inhibition and direct binding assays are performed using these HLA concentrations.
Since under these conditions [label]<[HLA] and ICso≥lHLA], the measured ICso values are reasonable approximations of the true Ko values. Peptide inhibitors are typically tested at concentrations ranging from 20 μg/ml to 1.2 ng/ml, and are tested in two to four completely independent experiments. To allow comparison of the data obtained in different experiments, a relative binding figure is calculated for each peptide by dividing the IC50 of a positive control for inhibition by the IC50 for each tested peptide (typically unlabeled versions of the radiolabeled probe peptide). For database purposes, and inter-experiment comparisons, relative binding values are compiled. These values can subsequently be converted back into IC50 nM values by dividing the IC50 nM of the positive controls for inhibition by the relative binding of the peptide of interest. This method of data compilation is accurate and consistent for comparing peptides that have been tested on different days, or with different lots of purified MHC.
Binding assays as outlined above may be used to analyze HLA supermotif and/or HLA motif-bearing peptides (see Table IV).
Example 13: Identification of HLA Supermotif- and Motif-Bearing CTL Candidate Epitopes
HLA vaccine compositions of the invention can include multiple epitopes. The multiple epitopes can comprise ■multiple HLA supermotifs or motifs to achieve broad population coverage. This example illustrates the identification and confirmation of supermotif- and motif-bearing epitopes for the inclusion in such a vaccine composition. Calculation of population coverage is performed using the strategy described below.
Computer searches and algorithms for identification of supermotif and/or motif-bearing epitopes
The searches performed to identify the motif-bearing peptide sequences in the Example entitled "Antigenicity Profiles" and Tables VIII-XXI and XXII-XLIX employ the protein sequence data from the gene product of 24P4C12 set forth in Figures 2 and 3, the specific search peptides used to generate the tables are listed in Table VII.
Computer searches for epitopes bearing HLA Class I or Class II supermotifs or motifs are performed as follows. All translated 24P4C12 protein sequences are analyzed using a text string search software program to identify potential peptide sequences containing appropriate HLA binding motifs; such programs are readily produced in accordance with information in the art in view of known motif/ supermotif disclosures. Furthermore, such calculations can be made mentally.
Identified A2-, A3-, and DR-supermotif sequences are scored using polynomial algorithms to predict their capacity to bind to spedfic HLA-Class I or Class II molecules. These polynomial algorithms account for the impact of different amino acids at different positions, and are essentially based on the premise that the overall affinity (or ΔG) of peptide-HLA molecule interactions can be approximated as a linear polynomial function of the type:
where a/ is a coefficient which represents the effect of the presence of a given amino add (/) at a given position (/) along the sequence of a peptide of n amino acids. The crucial assumption of this method is that the effects at each position are essentially independent of each other (i.e., independent binding of individual side-chains). When residue j occurs at position / in the peptide, it is assumed to contribute a constant amount p to the free energy of binding of the peptide irrespective of the sequence of the rest of the peptide.
The method of derivation of specific algorithm coefficients has been described in Gulukota et al, J. Mol. Biol. 267:1258-126, 1997; (see also Sidney ef at, Human Immunol. 45:79-93, 1996; and Southwood etal, J. Immunol. 160:3363- 3373, 1998). Briefly, for all / positions, anchor and non-anchor alike, the geometric mean of the average relative binding (ARB) of all peptides carrying; is calculated relative to the remainder of the group, and used as the estimate of . For Class II peptides, if multiple alignments are possible, only the highest scoring alignment is utilized, following an iterative procedure. To calculate an algorithm score of a given peptide in a test set, the ARB values corresponding to the sequence of the peptide are multiplied. If this product exceeds a chosen threshold, the peptide is predicted to bind. Appropriate thresholds are chosen as a function of the degree of stringency of prediction desired.
Selection of HLA-A2 supertype cross-reactive peptides
Protein sequences from 24P4C12 are scanned utilizing motif identification software, to identify 8-, 9- 10- and 11- mer sequences containing the HLA-A2-supermotif main anchor specificity. Typically, these sequences are then scored using the protocol described above and the peptides corresponding to the positive-scoring sequences are synthesized and tested for their capacity to bind purified HLA-A*0201 molecules in vitro (HLA-A*0201 is considered a prototype A2 supertype molecule).
These peptides are then tested for the capacity to bind to additional A2-supertype molecules (A*0202, A*0203, A*0206, and A*6802). Peptides that bind to at least three of the five A2-supertype alleles tested are typically deemed A2- supertype cross-reactive binders. Preferred peptides bind at an affinity equal to or less than 500 nM to three or more HLA- A2 supertype molecules.
Selection of HLA-A3 supermotif-bearino epitopes
The 24P4C12 protein sequence(s) scanned above is also examined for the presence of peptides with the HLA-A3- supermotif primary anchors. Peptides corresponding to the HLA A3 super otif-bearing sequences are then synthesized and tested for binding to HLA-A*0301 and HLA-A*1101 molecules, the molecules encoded by the two most prevalent A3- supertype alleles. The peptides that bind at least one of the two alleles with binding affinities of <500 nM, often < 200 nM, are then tested for binding cross-reactivity to the other common A3-supertype alleles (e.g., A*3101, A*3301, and A*6801) to identify those that can bind at least three of the five HLA-A3-supertype molecules tested.
Selection of HLA-B7 supermotif bearing epitopes
The 24P4C12 protein(s) scanned above is also analyzed for the presence of 8-, 9- 10-, or 11-mer peptides with the HLA-B7-supermotif. Corresponding peptides are synthesized and tested for binding to HLA-B*0702, the molecule encoded by the most common B7-supertype allele (i.e., the prototype B7 supertype allele). Peptides binding B*0702 with ICso of <50Q nM are identified using standard methods. These peptides are then tested for binding to other common B7-supertype molecules (e.g., B*3501, B*5101, B*5301, and B*5401). Peptides capable of binding to three or more of the five B7- supertype alleles tested are thereby identified.
Selection of A1 and A24 motif-bearing epitopes
To further increase population coverage, HLA-A1 and -A24 epitopes can also be incorporated into vaccine compositions. An analysis of the 24P4C12 protein can also be performed to identify HLA-A1- and A24-motif-containing sequences.
High affinity and/or cross-reactive binding epitopes that bear other motif and/or supermotifs are identified using analogous methodology.
Example 14: Confirmation of Immunogenicity
Cross-reactive candidate CTL A2-supermotif-bearing peptides that are identified as described herein are selected to confirm In vitro immunogenicity. Confirmation is performed using the following methodology:
Target Cell Lines for Cellular Screening:
The .221A2.1 cell line, produced by transferring the HLA-A2.1 gene into the HLA-A, -B, -C null mutant human B- lymphoblastoid cell line 721.221, is used as the peptide-loaded target to measure activity of HLA-A2.1 -restricted CTL. This cell line is grown in RPMI-1640 medium supplemented with antibiotics, sodium pyruvate, nonessential amino adds and 10% (v/v) heat inactivated FCS. Cells that express an antigen of interest, or traπsfectants comprising the gene encoding the antigen of interest, can be used as target cells to confirm the ability of peptide-specific CTLs to recognize endogenous antigen.
Primary CTL Induction Cultures-
Generation of Dendπtic Cells (DC): PBMCs are thawed in RPMI with 30 μg/ml DNAse, washed twice and resuspended in complete medium (RPMI-1640 plus 5% AB human serum, non-essential amino acids, sodium pyruvate, L- glutamine and penicillin/streptomycin). The monocytes are purified by plating 10 x 106 PBMC/well in a 6-well plate. After 2 hours at 37°C, the non-adherent cells are removed by gently shaking the plates and aspirating the supernatants. The wells are washed a total of three times with 3 ml RPMI to remove most of the non-adherent and loosely adherent cells. Three ml of complete medium containing 50 ng/ml of GM-CSF and 1,000 U/ml of IL4 are then added to each well. TNFα is added to the DCs on day 6 at 75 ng/ml and the cells are used for CTL induction cultures on day 7.
Induction of CTL with DC and Peptide: CD8+ T-cells are isolated by positive selection with Dynal immunomagnetic beads (Dynabeads® M450) and the detacha-bead® reagent. Typically about 200-250x106 PBMC are processed to obtain 24x106 CD8+ T-cells (enough for a 48-well plate culture). Briefly, the PBMCs are thawed in RPMI with 30μg/ml DNAse, washed once with PBS containing 1% human AB serum and resuspended in PBS/1% AB serum at a concentration of 20x106cells/ml. The magnetic beads are washed 3 times with PBS/AB serum, added to the cells (140μl beads/20x106 cells) and incubated for 1 hour at 4°C with continuous mixing. The beads and cells are washed 4x with PBS/AB serum to remove the nonadherent cells and resuspended at 100x106 cells/ml (based on the original cell number) in PBS/AB serum containing 100μl/ml detacha-bead® reagent and 30 μg/ml DNAse. The mixture is incubated for 1 hour at room temperature with continuous mixing. The beads are washed again with PBS/AB/DNAse to collect the CD8+ T-cells. The DC are collected and centrifuged at 1300 rpm for 5-7 minutes, washed once with PBS with 1% BSA, counted and pulsed with 40μg/ml of peptide at a cell concentration of 1-2x10%- in the presence of 3μg/ml β_- miσoglobulin for 4 hours at 20°C. The DC are then irradiated (4,200 rads), washed 1 time with medium and counted again.
Setting up induction cultures: 0.25 ml cytokine-generated DC (at 1x105 cells/ml) are co-cultured with 0.25ml of CD8+ T-cells (at 2x106 cell/ml) in each well of a 48-well plate in the presence of 10 ng/ml of IL-7. Recombinant human IL-10 is added the next day at a final concentration of 10 ng/ml and rhu an IL-2 is added 48 hours later at 10 lU/ml.
Restimulation of the induction cultures with peptide-pulsed adherent cells: Seven and fourteen days after the primary induction, the cells are restimulated with peptide-pulsed adherent cells. The PBMCs are thawed and washed twice
with RPMI and DNAse. The cells are resuspended at 5x106 cells/ml and irradiated at -4200 rads. The PBMCs are plated at 2x106 in 0.5 ml complete medium per well and incubated for 2 hours at 37°C. The plates are washed twice with RPMI by tapping the plate gently to remove the nonadherent cells and the adherent cells pulsed with 10μg/ml of peptide in the presence of 3 μg/ml β∑ microglobulin in 0.25ml RPMI/5%AB per well for 2 hours at 37°C. Peptide solution from each well is aspirated and the wells are washed once with RPMI. Most of the media is aspirated from the induction cultures (CD8+ cells) and brought to 0.5 ml with fresh media. The cells are then transferred to the wells containing the peptide-pulsed adherent cells Twenty four hours later recombinant human IL-10 is added at a final concentration of 10 ng/ml and recombinant human IL2 is added the next day and again 2-3 days later at 50IU/ml (Tsai ef al, Critical Reviews in Immunology 18(1-2):65-75, 1998). Seven days later, the cultures are assayed for CTL activity in a 51Cr release assay. In some experiments the cultures are assayed for peptide-specific recognition in the in situ IFNγ ELISA at the time of the second restimulation followed by assay of endogenous recognition 7 days later. After expansion, activity is measured in both assays for a side-by-side comparison.
Measurement of CTL Ivtic activity bv 51Cr release.
Seven days after the second restimulation, cytotoxicity is determined in a standard (5 hr) 5,Cr release assay by assaying individual wells at a single E:T. Peptide-pulsed targets are prepared by incubating the cells with 10μg/ml peptide overnight at 37°C.
Adherent target cells are removed from culture flasks with trypsin-EDTA. Target cells are labeled with 200μCi of 51Cr sodium chromate (Dupont, Wilmington, DE) for 1 hour at 37°C. Labeled target cells are resuspended at 10s per ml and diluted 1:10 with K562 cells at a concentration of 3.3x106/ml (an NK-sensitive erythroblastoma cell line used to reduce nonspecific lysis). Target cells (100 μl) and effedors (100μl) are plated in 96 well round-bottom plates and incubated for 5 hours at 37°C. At that time, 100 μl of supernatant are collected from each well and percent lysis is determined according to the formula:
[(cpm of the test sample- cpm of the spontaneous 51Cr release sample)/(cpm of the maximal 51Cr release sample- cpm of the spontaneous 5,Cr release sample)] x 100.
Maximum and spontaneous release are determined by incubating ttie labeled targets with 1% Triton X-100 and media alone, respectively. A positive culture is, defined as one in which the specific lysis (sample- background) is 10% or higher in the case of individual wells and is 15% or more at the two highest E:T ratios when expanded cultures are assayed.
In situ Measurement of Human IFNγ Production as an Indicator of Peptide-specific and Endogenous Recognition
Immulon 2 plates are coated with mouse anti-human IFNγ monoclonal antibody (4 μg/ml 0.1M NaHC03, pH8.2) overnight at 4°C. The plates are washed with Ca2+, Mg2+-free PBS/ 0.05% Tween 20 and blocked with PBS/10% FCS for two hours, after which the CTLs (100 μl/well) and targets (100 μl/well) are added to each well, leaving empty wells for the standards and blanks (which received media only). The target cells, either peptide-pulsed or endogenous targets, are used at a concentration of 1 x106 cells/ml. The plates are incubated for 48 hours at 37°C with 5% CO2.
Recombinant human IFN-gamma is added to the standard wells starting at 400 pg or 1200pg/100 miσoliter/well and the plate incubated for two hours at 37°C. The plates are washed and 100 μl of biotinylated mouse anti-human IFN- gamma monodonal antibody (2 miαogram/ml in PBS/3%FCS/0.05% Tween 20) are added and incubated for 2 hours at room temperature. After washing again, 100 microliter HRP-sfreptavidin (1:4000) are added and the plates incubated for one hour at room temperature. The plates are then washed 6x with wash buffer, 100 miσoliter well developing solution (TMB 1:1) are added, and the plates allowed to develop for 5-15 minutes. The reaction is stopped with 50 microliter/well 1 H3PO4 and read at OD450. A culture is considered positive if it measured at least 50 pg of IFN-gamma/well above background and is twice the background level of expression.
CTL Expansion.
Those cultures that demonstrate specific lytic activity against peptide-pulsed targets and/or tumor targets are expanded over a two week period with anti-CD3. Briefly, 5x104 CD8+ cells are added to a T25 flask containing the following: 1x106 irradiated (4,200 rad) PBMC (autologous or allogeneic) per ml, 2x105 irradiated (8,000 rad) EBV- transformed cells per ml, and OKT3 (anti-CD3) at 30ng per ml in RPMI-1640 containing 10% (v/v) human AB serum, non-essential amino acids, sodium pyruvate, 25μM 2-mercaptoethanol, L-glutamine and penicillin/streptomycin. Recombinant human IL2 is added 24 hours later at a final concentration of 200IU/ml and every three days thereafter with fresh media at 50IU/ml. The cells are split if the cell concentration exceeds 1x106/ml and the cultures are assayed between days 13 and 15 at E:T ratios of 30, 10, 3 and 1:1 in the 5,Cr release assay or at 1x106/ml in the in situ IFNγ assay using the same targets as before the expansion.
Cultures are expanded in the absence of anti-CD3+ as follows. Those cultures that demonstrate spedfic lytic activity against peptide and endogenous targets are selected and 5x104 CD8* cells are added to a T25 flask containing the following: 1x106 autologous PBMC per ml which have been peptide-pulsed with 10 μg/ml peptide for two hours at 37°C and irradiated (4,200 rad); 2x105 irradiated (8,000 rad) EBV-transformed cells per ml RPMI-1640 containing 10%(v/v) human AB serum, non-essential AA, sodium pyruvate, 25mM 2-ME, L-glutamine and gentamicin.
Immunogenicity of A2 sυpermotif-bearing peptides
A2-supermotif cross-reactive binding peptides are tested in the cellular assay for the ability to induce peptide- specific CTL in normal individuals. In this analysis, a peptide is typically considered to be an epitope if it induces peptide- spedfic CTLs in at least individuals, and preferably, also recognizes the endogenously expressed peptide.
Immunogenicity can also be confirmed using PBMCs isolated from patients bearing a tumor that expresses 24P4C12. Briefly, PBMCs are isolated from patients, re-stimulated with peptide-pulsed monocytes and assayed for the ability to recognize peptide-pulsed target cells as well as transfected cells endogenously expressing the antigen.
Evaluation of A*03/A11 immunogenicity
HLA-A3 supermotif-bearing cross-reactive binding peptides are also evaluated for immunogenicity using methodology analogous for that used to evaluate the immunogeni ty of the HLA-A2 supermotif peptides.
Evaluation of B7 immunogenicity
Immunogenicity screening of the B7-supertype cross-reactive binding peptides identified as set forth herein are confirmed in a manner analogous to the confirmation of A2-and A3-supe.motif-bea.ing peptides.
Peptides bearing other supermotifs/motifs, e.g., HLA-A1, HLA-A24 efc. are also confirmed using similar methodology
Example 15: Implementation of the Extended Supermotif to Improve the Binding Capacity of Native Epitopes bv Creating Analogs
HLA motifs and supermotifs (comprising primary and/or secondary residues) are useful in the identification and preparation of highly cross-reactive native peptides, as demonstrated herein. Moreover, the definition of HLA motifs and supermotifs also allows one to engineer highly cross-reactive epitopes by identifying residues within a native peptide sequence which can be analoged to confer upon the peptide certain characteristics, e.g. greater cross-reactivity within the group of HLA molecules that comprise a supertype, and/or greater binding affinity for some or all of those HLA molecules. Examples of analoging peptides to exhibit modulated binding affinity are set forth in this example.
Analooino at Primary Anchor Residues
Peptide engineering strategies are implemented to further increase the σoss-reactivity of the epitopes. For example, the main anchors of A2-supermotif-bearing peptides are altered, for example, to introduce a preferred L, I, V, or M at position 2, and I or V at the C-terminus.
To analyze the cross-reactivity of the analog peptides, each engineered analog is initially tested for binding to the prototype A2 supertype allele A*0201 , then, if A*0201 binding capacity is maintained, for A2-supertype cross-reactivity.
Alternatively, a peptide is confirmed as binding one or all supertype members and then analoged to modulate binding affinity to any one (or more) of the supertype members to add population coverage.
The selection of analogs for immunogenicity in a cellular sσeening analysis is typically further restricted by the capacity of the parent wild type (WT) peptide to bind at least weakly, i.e., bind at an ICso of 5000nM or less, to three of more A2 supertype alleles. The rationale for this requirement is that the WT peptides must be present endogenously in sufficient quantity to be biologically relevant. Analoged peptides have been shown to have increased immunogenicity and cross- reactivity by T cells specific for the parent epitope (see, e.g., Parkhurst ef al, J. Immunol. 157:2539, 1996; and Pogue ef al, Proc. Natl. Acad. Sci. USA 92:8166, 1995).
In the cellular screening of these peptide analogs, it is important to confirm that analog-specific CTLs are also able to recognize the wild-type peptide and, when possible, target cells that endogenously express the epitope.
Analooing of HLA-A3 and B7-supermotif-bearing peptides
Analogs of HLA-A3 supermotif-bearing epitopes are generated using strategies similar to those employed in analoging HLA-A2 supermotif-bearing peptides. For example, peptides binding to 3/5 of the A3-supertype molecules are engineered at primary anchor residues to possess a preferred residue (V, S, M, or A) at position 2.
The analog peptides are then tested for the ability to bind A*03 and A*11 (prototype A3 supertype alleles). Those peptides that demonstrate < 500 nM binding capadty are then confirmed as having A3-supertype cross-reactivity.
Similarly to the A2- and A3- motif bearing peptides, peptides binding 3 or more B7-supertype alleles can be improved, where possible, to achieve increased cross-reactive binding or greater binding affinity or binding half life. B7 supermotif-bearing peptides are, for example, engineered to possess a preferred residue (V, I, L, or F) at the C-terminal primary anchor position, as demonstrated by Sidney etal. (J. Immunol 157:3480-3490, 1996).
Analoging at primary anchor residues of other motif and/or supermotif-bearing epitopes is performed in a like manner.
The analog peptides are then be confirmed for immunogenidty, typically in a cellular screening assay. Again, it is generally important to demonstrate that analog-specific CTLs are also able to recognize the wild-type peptide and, when possible, targets that endogenously express the epitope.
Analoging at Secondary Anchor Residues
Moreover, HLA supermotifs are of value in engineering highly σoss-reactive peptides and/or peptides that bind HLA molecules with increased affinity by identifying particular residues at secondary anchor positions that are assodated with such properties. For example, the binding capacity of a B7 supermotif-bearing peptide with an F residue at position 1 is analyzed. The peptide is then analoged to, for example, substitute L for F at position 1. The analoged peptide is evaluated for increased binding affinity, binding half life and/or increased cross-reactivity. Such a procedure identifies analoged peptides with enhanced properties.
Engineered analogs with sufficiently improved binding capacity or σoss-reactivity can also be tested for immunogenicity in HLA-B7-transgenic mice, following for example, IFA immunization or lipopeptide immunization. Analoged peptides are additionally tested for the ability to stimulate a recall response using PBMC from patients with 24P4C12- expressing tumors.
Other analoging strategies
Another form of peptide analoging, unrelated to anchor positions, involves the substitution of a cysteine with α- amino butyric add. Due to its chemical nature, cysteine has the propensity to form disulfide bridges and sufficiently alter the peptide structurally so as to reduce binding capacity. Substitution of α-amino butyric acid for cysteine not only alleviates this problem, but has been shown to improve binding and σossbinding capabilities in some instances (see, e.g., the review by Sette ef al, In: Persistent Viral Infections, Eds. R. Ahmed and I. Chen, John Wiley & Sons, England, 1999).
Thus, by the use of single amino acid substitutions, the binding properties and/or cross-reactivity of peptide ligands for HLA supertype molecules can be modulated.
Example 16: Identification and confirmation of 24P4C12-derived seguences with HLA-DR binding motifs
Peptide epitopes bearing an HLA class II supermotif or motif are identified and confirmed as outlined below using methodology similar to that described for HLA Class I peptides.
Selection of HLA-DR-supermotif-bearing epitopes.
To identify 24P4C12-deιived, HLA class II HTL epitopes, a 24P4C12 antigen is analyzed for the presence of sequences bearing an HLA-DR-motif or supermotif. Specifically, 15-mer sequences are selected comprising a DR- supermotif, comprising a 9-mer core, and three-residue N- and C-terminal flanking regions (15 amino adds total).
Protocols for predicting peptide binding to DR molecules have been developed (Southwood ef a/., J. Immunol. 160:3363-3373, 1998). These protocols, specific for individual DR molecules, allow the scoring, and ranking, of 9-mer core regions. Each protocol not only scores peptide sequences for the presence of DR-supermotif primary anchors (i.e., at position 1 and position 6) within a 9-mer core, but additionally evaluates sequences for the presence of secondary anchors. Using allele-specific selection tables (see, e.g., Southwood ef al, ibid.), it has been found that these protocols efficiently select peptide sequences with a high probability of binding a particular DR molecule. Additionally, it has been found that performing these protocols in tandem, specifically those for DR1, DR4w4, and DR7, can efficiently select DR cross-reactive peptides.
The 24P4C12-derived peptides identified above are tested for ttieir binding capacity for various common HLA-DR molecules. All peptides are initially tested for binding to the DR molecules in the primary panel: DR1, DR4w4, and DR7. Peptides binding at least two of these three DR molecules are then tested for binding to DR2w2 β1, DR2w2 β2, DR6w19, and DR9 molecules in secondary assays. Finally, peptides binding at least two of the four secondary panel DR molecules, and thus cumulatively at least four of seven different DR molecules, are screened for binding to DR4w15, DR5w11 , and DR8w2 molecules in tertiary assays. Peptides binding at least seven of the ten DR molecules comprising the primary, secondary, and tertiary screening assays are considered cross-reactive DR binders. 24P4C12-derived peptides found to bind, common HLA-DR alleles are of particular interest.
Selection of DR3 motif peptides
Because HLA-DR3 is an allele that is prevalent in Caucasian, Black, and Hispanic populations, DR3 binding capacity is a relevant criterion in the selection of HTL epitopes. Thus, peptides shown to be candidates may also be assayed for their DR3 binding capacity. However, in view of the binding specificity of the DR3 motif, peptides binding only to ' DR3 can also be considered as candidates for inclusion in a vaccine formulation.
To efficiently identify peptides that bind DR3, target 24P4C12 antigens are analyzed for sequences carrying one of the two DR3-specific binding motifs reported by Geluk etal. (J. Immunol. 152:5742-5748, 1994). The conesponding peptides are then synthesized and confirmed as having the ability to bind DR3 with an affinity of 1μM or better, i.e., less than 1 μM. Peptides are found that meet this binding criterion and qualify as HLA class II high affinity binders.
DR3 binding epitopes identified in this manner are included in vaccine compositions with DR supermotif-bearing peptide epitopes.
Similarly to the case of HLA dass I motif-bearing peptides, the dass II motif-bearing peptides are analoged to improve affinity or cross-reactivity. For example, aspartic acid at position 4 of the 9-mer core sequence is an optimal residue for DR3 binding, and substitution for that residue often improves DR 3 binding. .
Example 17: Immunogenicity of 24P4C12-derived HTL epitopes
This example determines immunogenic DR supermotif- and DR3 motif-bearing epitopes among those identified using the methodology set forth herein.
Immunogenidty of HTL epitopes are confirmed in a manner analogous to the determination of immunogenidty of CTL epitopes, by assessing the ability to stimulate HTL responses and/or by using appropriate transgenic mouse models. Immunogenicity is determined by screening for: 1.) in vitro primary induction using normal PBMC or 2.) recall responses from patients who have 24P4C12-expressing tumors.
Example 18: Calculation of phenotypic freguencies of HLA-supertvpes in various ethnic backgrounds to determine breadth of population coverage
This example illustrates the assessment of the breadth of population coverage of a vacdne composition comprised of multiple epitopes comprising multiple supermotifs and/or motifs.
In order to analyze population coverage, gene frequencies of HLA alleles are determined. Gene frequencies for each HLA allele are calculated from antigen or allele frequences utilizing the binomial distribution formulae gf=1-(SQRT(1- af)) (see, e.g., Sidney ef a/., Human Immunol. 45:79-93, 1996). To obtain overall phenotypic frequendes, cumulative gene frequencies are calculated, and the cumulative antigen frequencies derived by the use of the inverse formula [af=1-(1-Cgf)2j.
Where frequency data is not available at the level of DNA typing, correspondence to the serologically defined antigen frequencies is assumed. To obtain total potential supertype population coverage no linkage disequilibrium is assumed, and only alleles confirmed to belong to each of the supertypes are included (minimal estimates). Estimates of total potential coverage achieved by inter-loci combinations are made by adding to the A coverage the proportion of the non-A covered population that could be expected to be covered by the B alleles considered (e.g., total=A+B*(1-A)). Confirmed members of the A3-like supertype are A3, A11 , A31 , A*3301 , and A*6801. Although the A3-like supertype may also include A34, A66, and A*7401 , these alleles were not included in overall frequency calculations. Likewise, confirmed members of the A2-like supertype family are A*0201 , A'0202, A*0203, A*0204, A*0205, A*0206, A*0207, A*6802, and A*6901. Finally, the B7-like supertype-confirmed alleles are: B7, B*3501-03, B51, B*5301, 13*5401. B*5501-2, B*5601, B*6701, and B7801 (potentially also B1401, B*3504-06, B 201, and B*5602).
Population coverage achieved by combining the A2-, A3- and B7-supertypes is approximately 86% in five major ethnic groups. Coverage may be extended by including peptides bearing the A1 and A24 motifs. On average, A1 is present in 12% and A24 in 29% of the population across five different major ethnic groups (Caucasian, North American Black, Chinese, Japanese, and Hispanic). Together, these alleles are represented with an average frequency of 39% in these same ethnic populations. The total coverage across the major ethnicities when A1 and A24 are combined with the coverage of the A2-, A3- and B7-supertype alleles is >95%, see, e.g., Table IV (G). An analogous approach can be used to estimate population coverage achieved with combinations of class II motif-bearing epitopes.
Immunogenicity studies in humans (e.g., Bertoni ef a/., J. Clin. Invest. 100:503, 1997; Doolan ef al, Immunity 7:97, 1997; and Threlkeld ef al, J. Immunol. 159:1648, 1997) have shown that highly cross-reactive binding peptides are almost always recognized as epitopes. The use of highly cross-reactive binding peptides is an important selection criterion in identifying candidate epitopes for inclusion in a vaccine that is immunogenic in a diverse population.
With a sufficient number of epitopes (as disclosed herein and from the art), an average population coverage is predicted to be greater than 95% in each of five major ethnic populations. The game theory Monte Cario simulation analysis, which is known in the art (see e g., Osborne, M.J. and Rubinstein, A. "A course in game theory" MIT Press, 1994), can be used to estimate what percentage of the individuals in a population comprised of the Caucasian, North American Black, Japanese, Chinese, and Hispanic ethnic groups would recognize the vaccine epitopes described herein. A preferred percentage is 90%. A more preferred percentage is 95%.
Example 19: CTL Recognition Of Endogenously Processed Antigens After Priming
This example confirms that CTL induced by native or analoged peptide epitopes identified and selected as described herein recognize endogenously synthesized, i.e., native antigens.
Effector cells isolated from transgenic mice that are immunized with peptide epitopes, for example HLA-A2 supermotif-bearing epitopes, are re-stimulated in vitro using peptide-coated stimulator cells. Six days later, effector cells are assayed for cytotoxicity and the cell lines that contain peptide-specific cytotoxic activity are further re-stimulated. An additional six days later, these cell lines are tested for cytotoxic activity on 51Cr labeled Jurkat-A2.1/Kb target cells in the absence or presence of peptide, and also tested on 51Cr labeled target cells bearing the endogenously synthesized antigen, le. cells that are stably transfected with 24P4C12 expression vectors.
The results demonstrate that CTL lines obtained from animals primed with peptide epitope recognize endogenously synthesized 24P4C12 antigen. The choice of transgenic mouse model to be used for such an analysis depends upon the epitope(s) that are being evaluated. In addition to HLA-A*0201/Kb transgenic mice, several other transgenic mouse models including mice with human A11, which may also be used to evaluate A3 epitopes, and B7 alleles have been characterized and others (e.g., transgenic mice for HLA-A1 and A24) are being developed. HLA-DR1 and HLA- DR3 mouse models have also been developed, which may be used to evaluate HTL epitopes.
Example 20: Activity Of CTL-HTL Conjugated Epitopes In Transgenic Mice
This example illustrates the induction of CTLs and HTLs in transgenic mice, by use of a 24P4C12-derived CTL and HTL peptide vaccine compositions. The vaccine composition used herein comprise peptides to be administered to a patient with a 24P4C12-expressing tumor. The peptide composition can comprise multiple CTL and/or HTL epitopes. The epitopes are identified using methodology as described herein. This example also illustrates that enhanced immunogenicity can be achieved by inclusion of one or more HTL epitopes in a CTL vaccine composition; such a peptide composition can comprise an HTL epitope conjugated to a CTL epitope. The CTL epitope can be one that binds to multiple HLA family members at an affinity of 500 nM or less, or analogs of that epitope. The peptides may be lipidated, if desired.
Immunization procedures: Immunization of transgenic mice is performed as described (Alexander ef al, J. Immunol. 159:47534761 , 1997). For example, A2/K" mice, which are transgenic for the human HLA A2.1 allele and are used to confirm the immunogenicity of HLA-A*0201 motif- or HLA-A2 supermotif-bearing epitopes, and are primed subcutaneously (base of the tail) with a 0.1 ml of peptide in Incomplete Freund's Adjuvant, or if the peptide composition is a lipidated CTL/HTL conjugate, in DMSO/saliπe, or if the peptide composition is a polypeptide, in PBS or Incomplete Freund's Adjuvant. Seven days after priming, splenocytes obtained from these animals are restimulated with syngenic irradiated LPS- activated lymphoblasts coated with peptide.
Cell lines: Target cells for peptide-specific cytotoxicity assays are Jurkat cells transfected with the HU ^.W chimeric gene (e.g., Vitiello ef al, J. Exp. Med. 173:1007, 1991)
In vitro CTL activation: One week after priming, spleen cells (30x106 cells/flask) are co-cuitured at 37°C with syngeneic, irradiated (3000 rads), peptide coated lymphoblasts (10x106 cells/flask) in 10 ml of culture medium/T25 flask. After six days, effector cells are harvested and assayed for cytotoxic activity.
Assay for cytotoxic activity. Target cells (1.0 to 1.5x10δ) are incubated at 37°C in the presence of 200 μl of 51Cr. After 60 minutes, cells are washed three times and resuspended in R10 medium. Peptide is added where required at a concentration of 1 μg/ml. For the assay, 104 51Cr-labeled target cells are added to different concentrations of effector cells (final volume of 200 μl) in U-bottom 96-well plates. After a six hour incubation period at 37°C, a 0.1 ml aliquot of supernatant is removed from each well and radioactivity is determined in a Micromedic automatic gamma counter. The percent specific lysis is determined by the formula: percent specific release = 100 x (experimental release - spontaneous release)/(maxιmum release - spontaneous release). To facilitate comparison between separate CTL assays run under the same conditions, % 51Cr release data is expressed as lytic units/106 cells. One lytic unit is arbitrarily defined as the number of effector cells required to achieve 30% lysis of 10,000 target cells in a six hour 51Cr release assay. To obtain specific lytic units/106, the lytic units/106 obtained in the absence of peptide is subtracted from the lytic units/106 obtained in the presence of peptide. For example, if 30% 51Cr release is obtained at the effector (E): target (T) ratio of 50:1 (i.e., 5x105 effector cells for 10,000 targets) in the absence of peptide and 5:1 (i.e., 5x104 effector cells for 10,000 targets) in the presence of peptide, the spedfic lytic units would be: [(1/50,000)-(1/500,000)j x 106 = 18 LU.
The results are analyzed to assess the magnitude of the CTL responses of animals injected with the immunogenic CTL HTL conjugate vaccine preparation and are compared to the magnitude of the CTL response achieved using, for example, CTL epitopes as outlined above in the Example entitled "Confirmation of Immunogenicity." Analyses similar to this may be performed to confirm the immunogenicity of peptide conjugates containing multiple CTL epitopes and/or multiple HTL epitopes. In accordance with these procedures, it is found that a CTL response is induced, and concomitantly that an HTL response is induced upon administration of such compositions.
Example 21: Selection of CTL and HTL epitopes for inclusion in a 24P4C12-specific vaccine.
This example illustrates a procedure for selecting peptide epitopes for vaccine compositions of the invention. The peptides in the composition can be in the form of a nucleic acid sequence, either single or one or more sequences (i.e., minigene) that encodes peptide(s), or can be single and/or polyepitopic peptides.
The following principles are utilized when selecting a plurality of epitopes for inclusion in a vaccine composition. Each of the following principles is balanced in order to make the seledion.
Epitopes are selected which, upon administration, mimic immune responses that are correlated with 24P4C12 clearance. The number of epitopes used depends on observations of patients who spontaneously clear 24P4C12. For example, if it has been observed that patients who spontaneously dear 24P4C12-expressing cells generate an immune response to at least three (3) epitopes from 24P4C12 antigen, then at least three epitopes should be included for HLA class I. A similar rationale is used to determine HLA class II epitopes.
Epitopes are often selected that have a binding affinity of an ICso of 500 nM or less for an HLA class I molecule, or for class II, an ICso of 1000 nM or less; or HLA Class I peptides with high binding scores from the BIMAS web site, at URL bimas.dcrt.nih.gov/.
In order to achieve broad coverage of the vaccine through out a diverse population, sufficient supermotif bearing peptides, or a sufficient array of allele-specific motif bearing peptides, are selected to give broad population coverage. In one embodiment, epitopes are selected to provide at least 80% population coverage. A Monte Carlo analysis, a statistical evaluation known in the art, can be employed to assess breadth, or redundancy, of population coverage.
When creating polyepitopic compositions, or a minigene that encodes same, it is typically desirable to generate the smallest peptide possible that encompasses the epitopes of interest. The prindples employed are similar, if not the same, as those employed when selecting a peptide comprising nested epitopes. For example, a protein sequence for the vaccine composition is selected because it has maximal number of epitopes contained within the sequence, i.e., it has a high concentration of epitopes. Epitopes may be nested or overlapping (i.e., frame shifted relative to one another). For example, with overlapping epitopes, two 9-mer epitopes and one 10-mer epitope can be present in a 10 amino acid peptide. Each epitope can be exposed and bound by an HLA molecule upon administration of such a peptide. A multi-epitopic, peptide can be generated synthetically, recombinantly, or via deavage from the native source. Altematively, an analog can be made of this native sequence, whereby one or more of the epitopes comprise substitutions that alter the cross-reactivity and/or binding affinity properties of the polyepitopic peptide. Such a vaccine composition is administered for therapeutic or prophylactic purposes. This embodiment provides for the possibility that an as yet undiscovered aspect of immune system processing will apply to the native nested sequence and thereby facilitate the production of therapeutic or prophylactic immune response-inducing vaccine compositions. Additionally such an embodiment provides for the possibility of motif- bearing epitopes for an HLA makeup that is presently unknown. Furthermore, this embodiment (absent the creating of any analogs) directs the immune response to multiple peptide sequences that are actually present in 24P4C12, thus avoiding the need to evaluate any junctional epitopes. Lastly, the embodiment provides an economy of scale when producing nucleic acid vacdne compositions Related to this embodiment, computer programs can be derived in accordance with principles in the art, which identify in a target sequence, the greatest number of epitopes per sequence length.
A vaccine composition comprised of selected peptides, when administered, is safe, efficacious, and elicits an immune response similar in magnitude to an immune response that controls or clears cells that bear or overexpress 24P4C12.
Example 22: Construction of "Minigene" Multi-Epitope DNA Plasmids
This example discusses the construction of a minigene expression plasmid. Minigene plasmids may, of course, contain various configurations of B cell, CTL and/or HTL epitopes or epitope analogs as described herein.
A minigene expression plasmid typically includes multiple CTL and HTL peptide epitopes. In the present example, HLA-A2, -A3, -B7 supermotif-bearing peptide epitopes and HLA-A1 and -A24 motif-bearing peptide epitopes are used in conjunction with DR supermotif-bearing epitopes and/or DR3 epitopes. HLA dass I supermotif or motif-bearing peptide epitopes derived 24P4C12, are selected such that multiple supermotifs/motifs are represented to ensure broad population coverage. Similarly, HLA class II epitopes are selected from 24P4C12 to provide broad population coverage, i.e. both HLA DR-14-7 supermotif-bearing epitopes and HLA DR-3 motif-bearing epitopes are selected for inclusion in the minigene construct. The selected CTL and HTL epitopes are then incorporated into a minigene for expression in an expression vector.
Such a construct may additionally include sequences that direct the HTL epitopes to the endoplasmic reticulum. For example, the Ii protein may be fused to one or more HTL epitopes as described in the art, wherein the CLIP sequence of the Ii protein is removed and replaced with an HLA class II epitope sequence so that HLA class II epitope is directed to the endoplasmic reticulum, where the epitope binds to an HLA dass II molecules.
This example illustrates the methods to be used for construction of a minigene-bearing expression plasmid. Other expression vectors that may be used for minigene compositions are available and known to those of skill in the art.
The minigene DNA plasmid of this example contains a consensus Kozak sequence and a consensus murine kappa Ig-light chain signal sequence followed by CTL and/or HTL epitopes selected in accordance with principles disclosed herein The sequence encodes an open reading frame fused to the Myc and His antibody epitope tag coded for by the pcDNA 3.1 Myc-His vector.
Overlapping oligonucleotides that can, for example, average about 70 nucleotides in length with 15 nucleotide overlaps, are synthesized and HPLC-purified. The oligonudeotides encode the selected peptide epitopes as well as appropriate linker nudeotides, Kozak sequence, and signal sequence. The final multiepitope minigene is assembled by extending the overlapping oligonucleotides in three sets of reactions using PCR. A Perkin/ Elmer 9600 PCR machine is used and a total of 30 cycles are performed using the following conditions: 95°C for 15 sec, annealing temperature (5° below the lowest calculated Tm of each primer pair) for 30 sec, and 72°C for 1 min.
For example, a minigene is prepared as follows. For a first PCR reaction, 5 μg of each of two oligonucleotides are annealed and extended: In an example using eight oligonucleotides, i.e., four pairs of primers, oligonucleotides 1 +2, 3+4, 5+6, and 7+8 are combined in 100 μl reactions containing Pfu polymerase buffer (1x= 10 mM KCL, 10 mM (NH4)2S04, 20 mM Tris-chloride, pH 8.75, 2 mM MgSO., 0.1% Triton X-100, 100 μg/ml BSA), 0.25 mM each dNTP, and 2.5 U of Pfu polymerase. The full-length dimer products are gel-purified, and two reactions containing the product of 1+2 and 3+4, and the product of 5+6 and 7+8 are mixed, annealed, and extended for 10 cydes. Half of the two reactions are then mixed, and 5 cycles of annealing and extension carried out before flanking primers are added to amplify the full length product The full- length product is gel-purified and cloned into pCR-blunt (Invitrogen) and individual clones are screened by sequendng.
Example 23: The Plasmid Construct and the Degree to Which It Induces Immunogenicity.
The degree to which a plasmid construct, for example a plasmid constructed in accordance with the previous Example, is able to induce immunogenicity is confirmed in vitro by determining epitope presentation by APC following transduction or transfection of the APC with an epitope-expressing nudeic acid construct Such a study determines "antigenicity" and allows the use of human APC. The assay determines the ability of the epitope to be presented by the APC in a context that is recognized by a T cell by quantifying the density of epitope-HLA class I complexes on the cell surface. Quantitation can be performed by directly measuring the amount of peptide eluted from the APC (see, e.g., Sijts ef al, J. Immunol. 156:683-692, 1996; Demotz ef al, Nature 342:682-684, 1989); or the number of peptide-HLA class I complexes can be estimated by measuring the amount of lysis or lymphokine release induced by diseased or transfected target cells, and then determining the concentration of peptide necessary to obtain equivalent levels of lysis or lymphokine release (see, e g., Kageyama etal, J. Immunol. 154:567-576, 1995).
Altematively, immunogenidty is confirmed through in vivo injections into mice and subsequent in vitro assessment of CTL and HTL activity, which are analyzed using cytotoxicity and proliferation assays, respectively, as detailed e.g., in Alexander ef a/., Immunity 1:751 -761, 1994.
For example, to confirm the capacity of a DNA minigene construct containing at least one HLA-A2 supermotif peptide to induce CTLs in vivo, HLA-A2,1/Kb transgenic mice, for example, are immunized intramuscularly with 100 μg of naked cDNA. As a means of comparing the level of CTLs induced by cDNA immunization, a control group of animals is also immunized with an actual peptide composition that comprises multiple epitopes synthesized as a single polypeptide as they would be encoded by the minigene.
Splenocytes from immunized animals are stimulated twice with each of the respective compositions (peptide epitopes encoded in the minigene or the polyepitopic peptide), then assayed for peptide-specific cytotoxic activity in a 51Cr release assay. The results indicate the magnitude of the CTL response directed against the A2-restricted epitope, thus indicating the in vivo immunogenicity of the minigene vaccine and polyepitopic vaccine.
It is, therefore, found that the minigene elicits immune responses directed toward the HLA-A2 supermotif peptide epitopes as does the polyepitopic peptide vaccine. A similar analysis is also performed using other HLA-A3 and HLA-B7 transgenic mouse models to assess CTL induction by HLA-A3 and HLA-B7 motif or supermotif epitopes, whereby it is also found that the minigene elicits appropriate immune responses directed toward the provided epitopes.
To confirm the capacity of a class II epitope-encoding minigene to induce HTLs in vivo, DR transgenic mice, or for those epitopes that cross react with the appropriate mouse MHC molecule, l-A -restricted mice, for example, are immunized intramuscularly with 100 μg of plasmid DNA. As a means of comparing the level of HTLs induced by DNA immunization, a group of control animals is also immunized with an actual peptide composition emulsified in complete Freund's adjuvant. CD4+ T cells, i.e. HTLs, are purified from splenocytes of immunized animals and stimulated with each of the respective compositions (peptides encoded in the minigene). The HTL response is measured using a 3H-thymidine incorporation proliferation assay, (see, e.g., Alexander ef al. Immunity 1:751-761, 1994). The results indicate the magnitude of the HTL response, thus demonstrating the in vivo immunogenicity of the minigene.
DNA minigenes, constructed as described in the previous Example, can also be confirmed as a vaccine in combination with a boosting agent using a prime boost protocol. The boosting agent can consist of recombinant protein (e.g., Barnett ef al, Aids Res. and Human Retroviruses 14, Supplement 3:S299-S309, 1998) or recombinant vac nia, for example, expressing a minigene or DNA encoding the complete protein of interest (see, e.g., Hanke et a/., Vaccine 16:439- 445, 1998; Sedegah ef al, Proc. Natl. Acad. Sci USA 95:7648-53, 1998; Hanke and McMichael, Immunol. Letters 66:177- 181, 1999; and Robinson etal, Nature Med. 5:526-34, 1999).
For example, the efficacy of the DNA minigene used in a prime boost protocol is initially evaluated in transgenic mice. In this example, A2.1/Kb transgenic mice are immunized IM with 100 μg of a DNA minigene encoding the immunogenic peptides including at least one HLA-A2 supermotif-bearing peptide. After an incubation period (ranging from 3- 9 weeks), the mice are boosted IP with 107 pfu/mouse of a recombinant vaccinia virus expressing the same sequence encoded by the DNA minigene. Control mice are immunized with 100 μg of DNA or recombinant vaccinia without the minigene sequence, or with DNA encoding the minigene, but without the vaccinia boost. After an additional incubation period of two weeks, splenocytes from the mice are immediately assayed for peptide-specific activity in an ELISPOT assay. Additionally, splenocytes are stimulated in vitro with the A2-restricted peptide epitopes encoded in the minigene and recombinant vacdnia, then assayed for peptide-spedfic activity in an alpha, beta and/or gamma IFN ELISA.
It is found that the minigene utilized in a prime-boost protocol elicits greater immune responses toward the HLA-A2 supermotif peptides than with DNA alone. Such an analysis can also be performed using HLA-A11 or HLA-B7 transgenic mouse models to assess CTL induction by HLA-A3 or HLA-B7 motif or supermotif epitopes. The use of prime boost protocols in humans is described below in the Example entitled "Induction of CTL Responses Using a Prime Boost Protocol."
Example 24: Peptide Compositions for Prophylactic Uses
Vaccine compositions of the present invention can be used to prevent 24P4C12 expression in persons who are at risk for tumors that bear this antigen. For example, a polyepitopic peptide epitope composition (or a nucleic acid comprising the same) containing multiple CTL and HTL epitopes such as those selected in the above Examples, which are also selected to target greater than 80% of the population, is administered to individuals at risk for a 24P4C12-associated tumor.
For example, a peptide-based composition is provided as a single polypeptide that encompasses multiple epitopes. The vaccine is typically administered in a physiological solution that comprises an adjuvant, such as Incomplete Freunds Adjuvant. The dose of peptide for the initial immunization is from about 1 to about 50,000 μg, generally 100-5,000 μg, for a 70 kg patient The initial administration of vaccine is followed by booster dosages at 4 weeks followed by evaluation of the magnitude of the immune response in the patient, by techniques that determine the presence of epitope- specific CTL populations in a PBMC sample. Additional booster doses are administered as required. The composition is found to be both safe and efficacious as a prophylaxis against 24P4C12-associated disease.
Alternatively, a composition typically comprising transfecting agents is used for the administration of a nucleic acid- based vaccine in accordance with methodologies known in the art and disclosed herein.
-Example 25: Polyepitopic Vaccine Compositions Derived from Native 24P4C12 Seguences
A native 24P4C12 polyprotein sequence is analyzed, preferably using computer algorithms defined for each class I and/or class II supermotif or motif, to identify "relatively short" regions of the polyprotein that comprise multiple epitopes. The "relatively short" regions are preferably less in length than an entire native antigen. This relatively short sequence that contains multiple distinct or overlapping, "nested" epitopes can be used to generate a minigene construct. The construct is engineered to express the peptide, which corresponds to the native protein sequence. The "relatively short" peptide is generally less than 250 amino acids in length, often less than 100 amino acids in length, preferably less than 75 amino acids in length, and more preferably less than 50 amino acids in length. The protein sequence of the vaccine composition is selected because it has maximal number of epitopes contained within the sequence, i.e., it has a high concentration of epitopes. As noted herein, epitope motifs may be nested or overlapping (i.e., frame shifted relative to one another). For example, with overlapping epitopes, two 9-mer epitopes and one 10-mer epitope can be present in a 10 amino acid peptide. Such a vaccine composition is administered for therapeutic or prophylactic purposes.
The vaccine composition will include, for example, multiple CTL epitopes from 24P4C12 antigen and at least one HTL epitope. This polyepitopic native sequence is administered either as a peptide or as a nucleic acid sequence which encodes the peptide. Alternatively, an analog can be made of this native sequence, whereby one or more of the epitopes comprise substitutions that alter the σoss-r eactivity and/or binding affinity properties of the polyepitopic peptide.
The embodiment of this example provides for the possibility that an as yet undiscovered aspect of immune system processing will apply to the native nested sequence and thereby facilitate the production of therapeutic or prophylactic immune response-inducing vaccine compositions. Additionally, such an embodiment provides for the possibility of motif- bearing epitopes for an HLA makeup(s) that is presently unknown. Furthermore, this embodiment (excluding an analoged embodiment) directs the immune response to multiple peptide sequences that are actually present in native 24P4C12, thus avoiding the need to evaluate any junctional epitopes. Lastly, the embodiment provides an economy of scale when producing peptide or nucleic acid vaccine compositions.
Related to this embodiment, computer programs are available in the art which can be used to identify in a target sequence, the greatest number of epitopes per sequence length.
Example 26: Polyepitopic Vaccine Compositions from Multiple Antigens
The 24P4C12 peptide epitopes of the present invention are used in conjunction with epitopes from other target tumor-assodated antigens, to create a vaccine composition that is useful for the prevention or treatment of cancer that expresses 24P4C12 and such other antigens. For example, a vaccine composition can be provided as a single polypeptide that incorporates multiple epitopes from 24P4C12 as well as tumor-associated antigens that are often expressed with a target cancer associated with 24P4C12 expression, or can be administered as a composition comprising a cocktail of one or more discrete epitopes. Alternatively, the vaccine can be administered as a minigene construct or as dendritic cells which have been loaded with the peptide epitopes in vitro.
Example 27: Use of peptides to evaluate an immune response
Peptides of the invention may be used to analyze an immune response for the presence of specific antibodies, CTL or HTL directed to 24P4C12. Such an analysis can be performed in a manner described by Ogg ef al, Science 279:2103-2106, 1998. In this Example, peptides in accordance with the invention are used as a reagent for diagnostic or prognostic purposes, not as an immunogen.
In this example highly sensitive human leukocyte antigen tetrameric complexes ("tetramers") are used for a cross- sectional analysis of, for example, 24P4C12 HLA-A*0201 -specific CTL frequencies from HLA A*0201-positive individuals at different stages of disease or following immunization comprising a 24P4C12 peptide containing an A*0201 motif. Tetrameric complexes are synthesized as described (Musey ef al., N. Engl. J. Med. 337:1267, 1997). Briefly, purified HLA heavy chain (A*0201 in this example) and p2-microglobulin are synthesized by means of a prokaryotic expression system. The heavy chain is modified by deletion of the transmembrane-cytosolic tail and COOH-terminal addition of a sequence containing a BirA enzymatic biotinylation site. The heavy chain, β2-microglobulin, and peptide are refolded by dilution. The 45-kD refolded product is isolated by fast protein liquid chromatography and then biotinylated by BirA in the presence of biotin (Sigma, St. Louis, Missouri), adenosine 5' triphosphate and magnesium. Streptavidin-phycoerythrin conjugate is added in a 1:4 molar ratio, and the tetrameric product is concentrated to 1 mg/ml. The resulting product is referred to as tetramer- phycoerythrin.
For the analysis of patient blood samples, approximately one million PBMCs are centrifuged at 300g for 5 minutes and resuspended in 50 μl of cold phosphate-buffered saline. Tri-color analysis is performed with the tetramer-phycoerythrin, along with anti-CD8-Tr icolor, and anti-CD38. The PBMCs are incubated with teframer and antibodies on ice for 30 to 60 min and then washed twice before formaldehyde fixation. Gates are applied to contain >99.98% of control samples. Controls for the tetramers include both A*0201 -negative individuals and A*0201 -positive non-diseased donors. The percentage of cells stained with the teframer is then determined by flow cytometry. The results indicate the number of cells in the PBMC sample that contain epitope-restricted CTLs, thereby readily indicating the extent of immune response to the 24P4C12 epitope, and thus the status of exposure to 24P4C12, or exposure to a vaccine that elicits a protective or therapeutic response.
Example 28: Use of Peptide Epitopes to Evaluate Recall Responses
The peptide epitopes of the invention are used as reagents to evaluate T cell responses, such as acute or recall responses, in patients. Such an analysis may be performed on patients who have recovered from 24P4C12-associated disease or who have been vaccinated with a 24P4C12 vaccine.
For example, the class I restricted CTL response of persons who have been vaccinated may be analyzed. The vaccine may be any 24P4C12 vaccine. PBMC are collected from vacdnated individuals and HLA typed. Appropriate peptide epitopes of the invention that, optimally, bear supermotifs to provide cross-reactivity with multiple HLA supertype family members, are then used for analysis of samples derived from individuals who bear that HLA type.
PBMC from vaccinated individuals are separated on Ficoll-Histopaque density gradients (Sigma Chemical Co., St. Louis, MO), washed three times in HBSS (GIBCO Laboratories), resuspended in RPMI-1640 (GIBCO Laboratories) supplemented with L-glutamine (2mM), penicillin (50U/ml), streptomycin (50 μg/ml), and Hepes (10mM) containing 10% heat-inactivated human AB serum (complete RPMI) and plated using miσoculture formats. A synthetic peptide comprising an epitope of the invention is added at 10 μg/ml to each well and HBV core 128-140 epitope is added at 1 μg/ml to each well as a source of T cell help during the first week of stimulation.
In the microculture format, 4 x 105 PBMC are stimulated with peptide in 8 replicate cultures in 96-well round bottom plate in 100 μl/well of complete RPMI. On days 3 and 10, 100 μl of complete RPMI and 20 U/ml final concentration of rlL-2 are added to each well. On day 7 the cultures are transferred into a 96-well flat-bottom plate and restimulated with peptide, rlL-2 and 105 irradiated (3,000 rad) autologous feeder cells. The cultures are tested for cytotoxic activity on day 14. A positive CTL response requires two or more of the eight replicate cultures to display greater than 10% specific 51Cr release, based on comparison with non-diseased control subjects as previously described (Rehermann, ef a/., Nature Med. 2:1104,1108, 1996; Rehermann etal, J. Clin. Invest. 97:1655-1665, 1996; and Rehermann ef al J. Clin. Invest. 98:1432- 1440, 1996).
Target cell lines are autologous and allogeneic EBV-transformed B-LCL that are either purchased from the American Society for Histocompatibility and Immunogenetics (ASHI, Boston, MA) or established from the pool of patients as described (Guilhot, etal. J. Virol. 66:2670-2678, 1992).
Cytotoxicity assays are performed in the following manner. Target cells consist of either allogeneic HLA-matched or autologous EBV-transformed B lymphoblastoid cell line that are incubated overnight with the synthetic peptide epitope of the invention at 10 μM, and labeled with 100 μCi of 1Cr (Amersham Corp., Ariington Heights, IL) for 1 hour after which they are washed four times with HBSS
Cytolytic activity is determined in a standard 4-h, split well 51Cr release assay using U-bottomed 96 well plates containing 3,000 targets/well. Stimulated PBMC are tested at effector/target (E/T) ratios of 20-50:1 on day 14. Percent cytotoxicity is determined from the formula: 100 x [(experimental release-spontaneous release)/ maximum release- spontaneous release)]. Maximum release is determined by lysis of targets by detergent (2% Triton X-100; Sigma Chemical Co., St. Louis, MO). Spontaneous release is <25% of maximum release for all experiments.
The results of such an analysis indicate the extent to which HLA-restricted CTL populations have been stimulated by previous exposure to 24P4C12 or a 24P4C12 vaccine.
Similarly, Class II restricted HTL responses may also be analyzed. Purified PBMC are cultured in a 96-well flat bottom plate at a density of 1.5x105 cells/well and are stimulated with 10 μg/ml synthetic peptide of the invention, whole 24P4C12 antigen, or PHA. Cells are routinely plated in replicates of 4-6 wells for each condition. After seven days of culture, the medium is removed and replaced with fresh medium containing 10U/ml IL-2. Two days later, 1 μCi 3H-thymidine is added to each well and incubation is continued for an additional 18 hours. Cellular DNA is then harvested on glass fiber mats and analyzed for 3H-thymidine incorporation. Antigen-spedfic T cell proliferation is calculated as the ratio of 3H- thymidine incorporation in the presence of antigen divided by the 3H-thymidine incorporation in the absence of antigen.
Example 29: Induction Of Specific CTL Response In Humans
A human clinical trial for an immunogenic composition comprising CTL and HTL epitopes of the invention is set up as an IND Phase I, dose escalation study and carried out as a randomized, double-blind, placebo-controlled trial. Such a trial is designed, for example, as follows:
A total of about 27 individuals are enrolled and divided into 3 groups:
Group I: 3 subjects are injected with placebo and 6 subjects are injected with 5 μg of peptide composition;
Group II: 3 subjects are injected with placebo and 6 subjects are injected with 50 μg peptide composition;
Group III: 3 subjects are injected with placebo and 6 subjects are injected with 500 μg of peptide composition.
After 4 weeks following the first injection, all subjects receive a booster inoculation at the same dosage.
The endpoints measured in this study relate to the safety and tolerability of the peptide composition as well as its immunogenicity. Cellular immune responses to the peptide composition are an index of the intrinsic activity of this the peptide composition, and can therefore be viewed as a measure of biological efficacy. The following summarize the clinical and laboratory data that relate to safety and efficacy endpoints.
Safety: The incidence of adverse events is monitored in the placebo and drug treatment group and assessed In terms of degree and reversibility.
Evaluation of Vacdne Efficacy: For evaluation of vaccine efficacy, subjects are bled before and after injection. Peripheral blood monoπuclear cells are isolated from fresh heparinized blood by Ficoll-Hypaque density gradient centrifugation, aliquoted in freezing media and stored frozen. Samples are assayed for CTL and HTL activity.
The vaccine is found to be both safe and efficadous.
Ill
Example 30: Phase II Trials In Patients Expressing 24P4C12
Phase II trials are performed to study the effect of administering the CTL-HTL peptide compositions to patients having cancer that expresses 24P4C12. The main objectives of the trial are to determine an effective dose and regimen for inducing CTLs in cancer patients that express 24P4C12, to establish the safety of inducing a CTL and HTL response in these patients, and to see to what extent activation of CTLs improves the clinical picture of these patients, as manifested, e.g., by the reduction and/or shrinking of lesions. Such a study is designed, for example, as follows:
The studies are performed in multiple centers. The trial design is an open-label, uncontrolled, dose escalation protocol wherein the peptide composition is administered as a single dose followed six weeks later by a single booster shot of the same dose. The dosages are 50, 500 and 5,000 miσograms per injection. Drug-assodated adverse effects (severity and reversibility) are recorded.
There are three patient groupings. The first group is injected with 50 micrograms of the peptide composition and the second and third groups with 500 and 5,000 micrograms of peptide composition, respectively. The patients within each group range in age from 21-65 and represent diverse ethnic backgrounds. All of them have a tumor that expresses 24P4C12.
Clinical manifestations or antigen-specific T-cell responses are monitored to assess the effects of administering the peptide compositions. The vaccine composition is found to be both safe and efficacious in the treatment of 24P4C12- associated disease.
Example 31 : Induction of CTL Responses Using a Prime Boost Protocol
A prime boost protocol similar in its underlying principle to that used to confirm the efficacy of a DNA vaccine in transgenic mice, such as described above in the Example entitled "The Plasmid Construct and the Degree to Which It Induces Immunogenidty," can also be used for the administration of the vaccine to humans. Such a vaccine regimen can include an initial administration of, for example, naked DNA followed by a boost using recombinant virus encoding the vaccine, or recombinant protein/polypeptide or a peptide mixture administered in an adjuvant.
For example, the initial immunization may be performed using an expression vector, such as that constructed in the Example entitled "Construction of "Minigene" Multi-Epitope DNA Plasmids" in the form of naked nudeic acid administered IM (or SC or ID) in the amounts of 0.5-5 mg at multiple sites. The nucleic acid (0.1 to 1000 μg) can also be administered using a gene gun. Following an incubation period of 34 weeks, a booster dose is then administered. The booster can be recombinant fowlpox virus administered at a dose of 5-107 to 5x109 pfu. An alternative recombinant virus, such as an MVA, canarypox, adenovirus, or adeno-associated virus, can also be used for the booster, or the polyepitopic protein or a mixture of the peptides can be administered. For evaluation of vaccine efficacy, patient blood samples are obtained before immunization as well as at intervals following administration of the initial vaccine and booster doses of the vaccine. Peripheral blood mononuclear cells are isolated from fresh heparinized blood by Ficoll-Hypaque density gradient centrifugation, aliquoted in freezing media and stored frozen. Samples are assayed for CTL and HTL activity.
Analysis of the results indicates that a magnitude of response sufficient to achieve a therapeutic or protective immunity against 24P4C12 is generated.
Example 32: Administration of Vaccine Compositions Using Dendritic Cells (DC)
Vaccines comprising peptide epitopes of the invention can be administered using APCs, or "professional" APCs such as DC. In this example, peptide-pulsed DC are administered to a patient to stimulate a CTL response in vivo. In this method, dendritic cells are isolated, expanded, and pulsed with a vaccine comprising peptide CTL and HTL epitopes of the invention. The dendritic cells are infused back into the patient to elicit CTL and HTL responses in vivo. The induced CTL
and HTL then destroy or facilitate destruction, respectively, of the target cells that bear the 24P4C12 protein from which the epitopes in the vaccine are derived.
For example, a cocktail of epitope-compiising peptides is administered ex vivo to PBMC, or isolated DC therefrom. A pharmaceutical to facilitate harvesting of DC can be used, such as Progenipoietin™ (Monsanto, St. Louis, MO) or GM- CSF/IL4. After pulsing the DC with peptides, and prior to reinfusion into patients, the DC are washed to remove unbound peptides.
As appreciated clinically, and readily determined by one of skill based on clinical outcomes, the number of DC reinfused into the patient can vary (see, e.g., Nature Med.4:328, 1998; Nature Med. 2:52, 1996 and Prosfafe 32:272, 1997). Although 2-50 x 106 DC per patient are typically administered, larger number of DC, such as 107 or 103 can also be provided. Such cell populations typically contain between 50-90% DC.
In some embodiments, peptide-loaded PBMC are injected into patients without purification of the DC. For example, PBMC generated after treatment with an agent such as Progenipoietin™ are injected into patients without purification of the DC. The total number of PBMC that are administered often ranges from 108 to 1010. Generally, the cell doses injected into patients is based on the percentage of DC in the blood of each patient, as determined, for example, by immunofluorescence analysis with specific anti-DC antibodies. Thus, for example, if Progenipoietin™ mobilizes 2% DC in the peripheral blood of a given patient, and that patient is to receive 5 x 106 DC, then the patient will be injected with a total of 2.5 x 108 peptide-loaded PBMC. The percent DC mobilized by an agent such as Progenipoietin™ is typically estimated to be between 2-10%, but can vary as appreciated by one of skill in the art.
Ex vivo activation of CTL/HTL responses
Alternatively, ex vivo CTL or HTL responses to 24P4C12 antigens can be induced by incubating, in tissue culture, the patient's, or genetically compatible, CTL or HTL precursor cells together with a source of APC, such as DC, and immunogenic peptides. After an appropriate incubation time (typically about 7-28 days), in which the precursor cells are activated and expanded into effector cells, the cells are infused into the patient, where they will destroy (CTL) or facilitate destruction (HTL) of their specific target cells, i.e., tumor cells.
Example 33: An Alternative Method of Identifying and Confirming Motif-Bearing Peptides
Another method of identifying and confirming motif-bearing peptides is to elute them from cells bearing defined MHC molecules. For example, EBV transformed B cell lines used for tissue typing have been extensively characterized to determine which HLA molecules they express. In certain cases these cells express only a single type of HLA molecule. These cells can be transfected with nucleic acids that express the antigen of interest, e.g. 24P4C12. Peptides produced by endogenous antigen processing of peptides produced as a result of transfection will then bind to HLA molecules within the cell and be fransported and displayed on the cell's surface. Peptides are then eluted from the HLA molecules by exposure to mild acid conditions and their amino acid sequence determined, e.g., by mass spectral analysis (e.g., Kubo ef al, J. Immunol. 152:3913, 1994). Because the majority of peptides that bind a particular HLA molecule are motif-bearing, this is an alternative modality for obtaining the motif-bearing peptides correlated with the particular HLA molecule expressed on (he cell.
Alternatively, cell lines that do not express endogenous HLA molecules can be transfected with an expression construct encoding a single HLA allele. These cells can then be used as described, i.e., they can then be transfected with nudeic acids that encode 24P4C12 to isolate peptides corresponding to 24P4C12 that have been presented on the cell surface. Peptides obtained from such an analysis will bear moti'f(s) that correspond to binding to the single HLA allele that is expressed in the cell.
As appredated by one in the art, one can perform a similar analysis on a cell bearing more than one HLA allele and subsequently determine peptides specific for each HLA allele expressed. Moreover, one of skill would also recognize that means other than transfection, such as loading with a protein antigen, can be used to provide a source of antigen to the cell.
Example 34: Complementary Polynucleotides
Sequences complementary to the 24P4C12-encoding sequences, or any parts thereof, are used to detect, decrease, or inhibit expression of naturally occurring 24P4C12. Although use of oligonucleotides comprising from about 15 to 30 base pairs is described, essentially the same procedure is used with smaller or with larger sequence fragments. Appropriate oligonucleotides are designed using, e.g., OLIGO 4.06 software (National Biosciences) and the coding sequence of 24P4C12. To inhibit transcription, a complementary oligonucleotide is designed from the most unique 5' sequence and used to prevent promoter binding to the coding sequence. To inhibit translation, a complementary oligonucleotide is designed to prevent ribosomal binding to a 24P4C12-encoding transcript
Example 35: Purification of Naturally-occurring or Recombinant 24P4C12 Using 24P4C12-Specific Antibodies
Naturally occurring or recombinant 24P4C12 is substantially purified by immunoaffinity chromatography using antibodies specific for 24P4C12. An immunoaffinity column is constructed by covalently coupling anti-24P4C12 antibody to an activated chromatographic resin, such as CNBr-activated SEPHAROSE (Amersham Pharmacia Biotech). After the coupling, the resin is blocked and washed according to the manufacturer's instructions.
Media containing 24P4C12 are passed over the immunoaffinity column, and the column is washed under conditions that allow the preferential absorbance of 24P4C12 (e.g., high ionic strength buffers in the presence of detergent). The column is eluted under conditions that disrupt antibody/24P4C12 binding (e.g., a buffer of pH 2 to pH 3, or a high concentration of a chaotrope, such as urea or thiocyanate ion), and GCR.P is collected.
Example 36: Identification of Molecules Which Interact with 24P4C12
24P4C12, or biologically active fragments thereof, are labeled with 121 1 Bolton-Hunter reagent. (See, e.g., Bolton ef al. (1973) Biochem. J. 133:529.) Candidate molecules previously arrayed in the wells of a multi-well plate are incubated with the labeled 24P4C12, washed, and any wells with labeled 24P4C12 complex are assayed. Data obtained using different concentrations of 24P4C12 are used to calculate values for the number, affinity, and association of 24P4C12 with the candidate molecules.
Example 37: In Vivo Assay for 24P4C12 Tumor Growth Promotion
The effect of the 24P4C12 protein on tumor cell growth is evaluated in vivo by evaluating tumor development and growth of cells expressing or lacking 24P4C12. For example, SCID mice are injected subcutaneously on each flank with 1 x 106 of either 3T3, prostate, colon, ovary, lung, or bladder cancer cell lines (e.g. PC3, Caco, PA-1, CaLu or J82 cells) containing tkNeo empty vector or 24P4C12. At least two strategies may be used: (1) Constitutive 24P4C12 expression under regulation of a promoter, such as a constitutive promoter obtained from the genomes of viruses such as polyoma virus, fowlpox virus (UK 2,211 ,504 published 5 July 1989), adenovirus (such as Adenovirus 2), bovine papilloma virus, avian sarcoma virus, cytomegalovirus, a retrovirus, hepatitis-B virus and Simian virus 40 (SV40), or from heterologous mammalian promoters, e.g., the actin promoter or an immunoglobulin promoter, provided such promoters are compatible with the host cell systems, and (2) Regulated expression under control of an indudble vector system, such as ecdysone, tetracydine, etc., provided such promoters are compatible with the host cell systems. Tumor volume is then monitored by caliper
measurement at the appearance of palpable tumors and followed over time to determine if 24P4C12-expressing cells grow at a faster rate and whether tumors produced by 24P4C12-expressing cells demonstrate characteristics of altered aggressiveness (e.g. enhanced metastasis, vascularization, reduced responsiveness to chemotherapeutic drugs). As shown in figure 31 and Figure 32, 24P4C12 has a profound effect on tumor growth in SCID mice. The prostate cancer cells PC3 and PC3-24P4C12 were injected subcutaneously in the right flank of SCID mice. Tumor growth was evaluated by caliper measurements. An increase in tumor growth was observed in PC3-24P4C12 tumors within 47 days of injection (fig 31). In addition, subcutaneous injection of 3T3-24P4C12 induced tumor formation in SCID mice (Figure 32). This finding is significant as control 3T3 cells fail to form tumors, indicating that 24P4C12 has several tumor enhancing capabilities, including transformation, as well as tumor initiation and promotion.
Example 38: 24P4C12 Monoclonal Antibody-mediated Inhibition of Prostate Tumors In Vivo.
The significant expression of 24P4C12 in cancer tissues, together with its restrictive expression in normal tissues and cell surface localization, make 24P4C12 a good target for antibody therapy. Similarly, 24P4C12 is a target for T cell- based immunotherapy. Thus, the therapeutic efficacy of anti-24P4C12 mAbs in human prostate cancer xenograft mouse models is evaluated by using recombinant cell lines such as PC3-24P4C12, and 3T3-24P4C12 (see, e.g., Kaighn, M.E., ef a/., Invest Urol, 1979. 17(1): p. 16-23), as well as human prostate xenograft models such as LAPC9 (Saffran et al, Proc Natl Acad Sci U S A. 2001 , 98:2658). Similarly, anti-24P4C12 mAbs are evaluated in xenograft models of human bladder cancer colon cancer, ovarian cancer or lung cancer using recombinant cell lines such as J82-24P4C12, Caco-24P4C12, PA- 24P4C1 or CaLu-24P4C12, respectively.
Antibody efficacy on tumor growth and metastasis formation is studied, e.g., in a mouse orthotopic bladder cancer xenograft model, and a mouse prostate cancer xenograft model, The antibodies can be unconjugated, as discussed in this Example, or can be conjugated to a therapeutic modality, as appreciated in the art. Anti-24P4C12 mAbs inhibit formation of prostate and bladder xenografts. Anti-24P4C12 mAbs also retard the growth of established orthotopic tumors and prolonged survival of tumor-bearing mice. These results indicate the utility of anti-24P4C12 mAbs in the treatment of local and advanced stages of prostate, colon, ovarian, lung and bladder cancer. (See, e.g., Saffran, D., et al., PNAS 10:1073-1078 or www.pnas.org/ cgι7doi/10.1073/ pnas.051624698).
Administration of the anti-24P4C12 mAbs led to retardation of established orthotopic tumor growth and inhibition of metastasis to distant sites, resulting in a significant prolongation in the survival of tumor-bearing mice. These studies indicate that 24P4C12 as an attractive target for immunotherapy and demonstrate the therapeutic potential of anti-24P4C12 mAbs for the treatment of local and metastatic cancer. This example demonstrates that unconjugated 24P4C12 monoclonal antibodies are effective to inhibit the growth of human prostate, colon, ovarian, lung and bladder cancer tumor xenografts grown in SCID mice; accordingly a combination of such efficacious monoclonal antibodies is also effective.
Tumor inhibition using multiple unconjugated 24P4C12 mAbs Materials and Methods
24P4C12 Monoclonal Antibodies:
Monodonal antibodies are raised against 24P4C12 as described in the Example entitled "Generation of 24P4C12 Monoclonal Antibodies (mAbs)." The antibodies are characterized by ELISA, Western blot, FACS, and immunoprecipitation for their capacity to bind 24P4C12. Epitope mapping data for the anti-24P4C12 mAbs, as determined by ELISA and Western analysis, recognize epitopes on the 24P4C12 protein. Immunohistochemical analysis of prostate cancer tissues and cells with these antibodies is performed.
The monoclonal antibodies are purified from asdtes or hybridoma tissue culture supernatants by Protein-G Sepharose chromatography, dialyzed against PBS, filter sterilized, and stored at -20CC. Protein determinations are performed by a Bradford assay (Bio-Rad, Hercules, CA). A therapeutic monoclonal antibody or a cocktail comprising a mixture of individual monoclonal antibodies is prepared and used for the treatment of mice receiving subcutaneous or orthotopic injections of SCABER, J82, A498, 769P, CaOvl or PA1 tumor xenografts.
Cell Lines
The prostate, colon, ovarian, lung and bladder cancer carcinoma cell lines, , Caco, PA-1 , CaLu or J82 cells as well as the fibroblast line NIH 3T3 (American Type Culture Collection) are maintained in media supplemented with L-glutamine and 10% FBS.
PC3-24P4C12, Caco-24P4C12, PA-24P4C12, CaLu-24P4C12 or J82-24P4C12 cells and 3T3-24P4C 2 cell populations are generated by retroviral gene transfer as described in Hubert, R.S., et al., Proc Natl Acad Sci U S A, 1999. 96(25): 14523.
Xenograft Mouse Models.
Subcutaneous (s.c.) tumors are generated by injection of 1 x 106 cancer cells mixed at a 1 :1 dilution with Matrigel (Collaborative Research) in the right flank of male SCID mice. To test antibody efficacy on tumor formation, i.p. antibody injections are started on the same day as tumor-cell injections. As a control, mice are injected with either purified mouse IgG (ICN) or PBS; or a purified monoclonal antibody that recognizes an irrelevant antigen not expressed in human cells. Tumor sizes are determined by caliper measurements, and the tumor volume is calculated as: Length x Width x Height. Mice with s.c. tumors greater than 1.5 cm in diameter are sacrificed.
Orthotopic injections are performed under anesthesia by using ketamine/xylazine. For bladder orthotopic studies, an incision is made through the abdomen to expose the bladder, and tumor cells (5 x 105) mixed with Matrigel are injected into the bladder wall in a 10-μl volume. To monitor tumor growth, mice are palpated and blood is collected on a weekly basis to measure BTA levels. For prostate orthopotic models, an incision is made through the abdominal usdes to expose the bladder and seminal vesicles, which then are delivered through the incision to expose the dorsal prostate. Tumor cells e.g. LAPC-9 cells (5 x 105 ) mixed with Matrigel are injected into the prostate in a 10-μl volume (Yoshida Y et al, Anticancer Res. 1998, 18:327; Ahn et al, Tumour Biol. 2001 , 22:146). To monitor tumor growth, blood is collected on a weekly basis measuring PSA levels. Similar procedures are followed for lung and ovarian xenograft models. The mice are segregated into groups for the appropriate treatments, with anti-24P4C12 or control mAbs being injected i.p.
Anti-24P4C12 mAbs Inhibit Growth of 24P4C12-Expressing Xenoqraft-Cancer Tumors
The effect of anti-24P4C12 mAbs on tumor formation is tested on the growth and progression of bladder, and prostate cancer xenografts using PC3-24P4C12, Caco-24P4C12, PA-24P4C12, CaLu-24P4C12 or J82-24P4C12 orthotopic models. As compared with the s.c. tumor model, the orthotopic model, which requires injection of tumor cells directly in the mouse prostate, colon, ovary, lung and bladder, respectively, results in a local tumor growth, development of metastasis in distal sites, deterioration of mouse health, and subsequent death (Saffran, D., et al., PNAS supra; Fu, X., et al., Int J Cancer, 1992. 52(6): p. 987-90; Kubota, T., J Cell Biochem, 1994.56(1): p.4-8). The features make the orthotopic model more representative of human disease progression and allowed us to follow the therapeutic effect of mAbs on dinically relevant end points.
Accordingly, tumor cells are injected into the mouse organs, and 2 days later, the mice are segregated into two groups and freated with either: a) 200-500μg, of anti-24P4C12 Ab, or b) PBS three times per week for two to five weeks.
A major advantage of the orthotopic cancer models is the ability to study the development of metastases. Formation of metastasis in mice bearing established orthotopic tumors is studies by IHC analysis on lung sections using an
antibody against a tumor-specific cell-surface protein such as anti-CK20 for bladder cancer, anti-STEAP-1 for prostate cancer models (Lin S et al, Cancer Detect Prev.2001 ;25:202; Saffran, D., et al., PNAS supra).
Mice bearing established orthotopic tumors are administered 10OOμg injections of either anti-24P4C12 mAb or PBS over a 4-week period. Mice in both groups are allowed to establish a high tumor burden, to ensure a high frequency of metastasis formation in mouse lungs. Mice then are killed and their bladders, livers, bone and lungs are analyzed for the presence of tumor cells by IHC analysis.
These studies demonstrate a broad anti-tumor efficacy of anti-24P4C12 antibodies on initiation and progression of prostate and kidney cancer in xenograft mouse models. Anti-24P4C12 antibodies inhibit tumor formation of tumors as well as retarding the growth of already established tumors and prolong the survival of treated mice. Moreover, anti-24P4C12 mAbs demonstrate a dramatic inhibitory effect on the spread of local bladder and prostate tumor to distal sites, even in the presence of a large tumor burden. Thus, anti-24P4C12 mAbs are efficacious on major clinically relevant end points (tumor growth), prolongation of survival, and health.
Example 39: Therapeutic and Diagnostic use of Anti-24P4C12 Antibodies in Humans.
Anti-24P4C12 monoclonal antibodies are safely and effectively used for diagnostic, prophylactic, prognostic and/or therapeutic purposes in humans. Western blot and immunohistochemical analysis of cancer tissues and cancer xenografts with anti-24P4C12 mAb show strong extensive staining in carcinoma but significantly lower or undetectable levels in normal tissues. Detection of 24P4C12 in carcinoma and in metastatic disease demonstrates the usefulness of the mAb as a diagnostic and/or prognostic indicator. Anti-24P4C12 antibodies are therefore used in diagnostic applications such as immunohistochemistry of kidney biopsy specimens to detect cancer from suspect patients.
As determined by flow cytometry, anti-24P4C12 mAb specifically binds to carcinoma cells. Thus, anti-24P4C12 antibodies are used in diagnostic whole body imaging applications, such as radioimmunoscintigraphy and radioimmunotherapy, (see, e.g., Potamianos S., et al. Anticancer Res 20(2A):925-948 (2000)) for the detection of localized and metastatic cancers that exhibit expression of 24P4C12. Shedding or release of an extracellular domain of 24P4C12 into the extracellular milieu, such as that seen for alkaline phosphodiesterase B10 (Meerson, N. R., Hepatology 27:563-568 (1998)), allows diagnostic detection of 24P4C12 by anti-24P4C12 antibodies in serum and/or urine samples from suspect patients.
Anti-24P4C12 antibodies that specifically bind 24P4C12 are used in therapeutic applications for the treatment of cancers that express 24P4C12. Anti-24P4C12 antibodies are used as an unconjugated modality and as conjugated form in which the antibodies are attached to one of various therapeutic or imaging modalities well known in the art, such as a prodrugs, enzymes or radioisotopes. In preclinical studies, unconjugated and conjugated anti-24P4C12 antibodies are tested for efficacy of tumor prevention and growth inhibition in the SCID mouse cancer xenograft models, e.g., kidney cancer models AGS-K3 and AGS-K6, (see, e.g., the Example entitled "24P4C12 Monoclonal Antibody-mediated Inhibition of Bladder and Lung Tumors In Vivo"). Either conjugated and unconjugated anti-24P4C12 antibodies are used as a therapeutic modality in human clinical trials either alone or in combination with other treatments as desσibed in following Examples.
Example 40: Human Clinical Trials for the Treatment and Diagnosis of Human Carcinomas through use of Human Anti-24P4C12 Antibodies In vivo
Antibodies are used in accordance with the present invention which recognize an epitope on 24P4C12, and are used in the treatment of certain tumors such as those listed in Table I. Based upon a number of factors, including 24P4C12 expression levels, tumors such as those listed in Table I are presently preferred indications. In connection with each of these indications, three clinical approaches are successfully pursued.
I.) Adjunctive therapy: In adjunctive therapy, patients are treated with anti-24P4C12 antibodies in combination with a chemotherapeutic or antineoplastic agent and/or radiation therapy. Primary cancer targets, such as those listed in Table I, are treated under standard protocols by the addition anti-24P4C12 antibodies to standard first and second line therapy. Protocol designs address effectiveness as assessed by reduction in tumor mass as well as the ability to reduce usual doses of standard chemotherapy. These dosage reductions allow additional and/or prolonged therapy by reducing dose-related toxicity of the chemotherapeutic agent. Anti-24P4C12 antibodies are utilized in several adjunctive clinical trials in combination with the chemotherapeutic or antineoplastic agents adriamycin (advanced prostrate carcinoma), cisplatin (advanced head and neck and lung carcinomas), taxol (breast cancer), and doxorubicin (predinical).
II.) Monotherapy: In connection with the use of the anti-24P4C12 antibodies in monotherapy of tumors, the antibodies are administered to patients without a chemotherapeutic or antineoplastic agent. In one embodiment, monotherapy is conducted clinically in end stage cancer patients with extensive metastatic disease. Patients show some disease stabilization. Trials demonstrate an effect in refractory patients with cancerous tumors.
III.) Imaging Agent: Through binding a radionuclide (e.g., iodine or yttrium (I131, Y90) to anti-24P4C12 antibodies, the radiolabeled antibodies are utilized as a diagnostic and/or imaging agent. In such a role, the labeled antibodies localize to both solid tumors, as well as, metastatic lesions of cells expressing 24P4C12. In connection with the use of the anti-24P4C12 antibodies as imaging agents, the antibodies are used as an adjunct to surgical treatment of solid tumors, as both a pre-surgical screen as well as a post-operative follow-up to determine what tumor remains and/or returns. In one embodiment, a (111 ln)-24P4C12 antibody is used as an imaging agent in a Phase I human clinical trial in patients having a carcinoma that expresses 24P4C12 (by analogy see, e.g., Divgi etal. 1 Natl. Cancer Inst. 83:97-104 (1991)). Patients are followed with standard anterior and posterior gamma camera. The results indicate that primary lesions and metastatic lesions are identified
Dose and Route of Administration
As appreciated by those of ordinary skill in the art, dosing considerations can be determined through comparison with the analogous products that are in the clinic. Thus, anti-24P4C12 antibodies can be administered with doses in the range of 5 to 400 mg/m 2 , with the lower doses used, e.g., in connection with safety studies. The affinity of anti-24P4C12 antibodies relative to the affinity of a known antibody for its target is one parameter used by those of skill in the art for determining analogous dose regimens. Further, anti-24P4C12 antibodies that are fully human antibodies, as compared to the chimeric antibody, have slower clearance; accordingly, dosing in patients with such fully human anti-24P4C12 antibodies can be lower, perhaps in the range of 50 to 300 mg/m2 , and still remain efficadous. Dosing in mg/m2 , as opposed to the conventional measurement of dose in mg/kg, is a measurement based on surface area and is a convenient dosing measurement that is designed to include patients of all sizes from infants to adults.
Three distinct delivery approaches are useful for delivery of anti-24P4C12 antibodies. Conventional intravenous delivery is one standard delivery technique for many tumors. However, in connection with tumors in the peritoneal cavity, such as tumors of the ovaries, biliary duct, other ducts, and the like, infraperitoneal administration may prove favorable for obtaining high dose of antibody at the tumor and to also minimize antibody clearance. In a similar manner, certain solid tumors possess vasculature that is appropriate for regional perfusion. Regional perfusion allows for a high dose of antibody at the site of a tumor and minimizes short term clearance of the antibody.
Clinical Development Plan (CDP)
Overview: The CDP follows and develops treatments of anti-24P4C12 antibodies in connection with adjunctive therapy, monotherapy, and as an imaging agent. Trials initially demonstrate safety and thereafter confirm efficacy in repeat doses. Trails are open label comparing standard chemotherapy with standard therapy plus anti-24P4C12 antibodies. As will
be appreciated, one criteria that can be utilized in connection with enrollment of patients is 24P4C12 expression levels in their tumors as determined by biopsy.
As with any protein or antibody infusion-based therapeutic, safety concerns are related primarily to (i) cytokine release syndrome, i.e., hypotension, fever, shaking, chills; (ii) the development of an immunogenic response to the material (i.e., development of human antibodies by the patient to the antibody therapeutic, or HAHA response); and, (iii) toxidty to normal cells that express 24P4C12. Standard tests and follow-up are utilized to monitor each of these safety concerns. Anti-24P4C12 antibodies are found to be safe upon human administration.
Example 41: Human Clinical Trial Adjunctive Therapy with Human Anti-24P4C12 Antibody and Chemotherapeutic Agent
A phase I human clinical trial is initiated to assess the safety of six intravenous doses of a human anti-24P4C12 antibody in connection with the treatment of a solid tumor, e.g., a cancer of a tissue listed in Table I. In the study, the safety of single doses of anti-24P4C12 antibodies when utilized as an adjunctive therapy to an antineoplastic or chemotherapeutic agent as defined herein, such as, without limitation: cisplatin, topotecan, doxorubicin, adriamycin, taxol, or the like, is assessed. The trial design includes delivery of six single doses of an anti-24P4C12 antibody with dosage of antibody escalating from approximately about 25 mg/m 2 to about 275 mg/m 2 over the course of the treatment in accordance with the following schedule:
Day O Day 7 Day 14 Day 21 Day 28 Day 35
mAb Dose 25 75 125 175 225 275 mg/m 2 mg/m 2 mg/m 2 mg/m 2 mg/m 2 mg/m 2
Chemotherapy + + + + + + (standard dose)
Patients are closely followed for one-week following each administration of antibody and chemotherapy. In particular, patients are assessed for the safety concerns mentioned above: (i) cytokine release syndrome, i.e., hypotension, fever, shaking, chills; (ii) the development of an immunogenic response to the material (i.e., development of human antibodies by the patient to the human antibody therapeutic, or HAHA response); and, (iii) toxicity to normal cells that express 24P4C12. Standard tests and follow-up are utilized to monitor each of these safety concerns. Patients are also assessed for clinical outcome, and particularly reduction in tumor mass as evidenced by MRI or other imaging.
The anti-24P4C12 antibodies are demonstrated to be safe and efficacious, Phase II trials confirm the efficacy and refine optimum dosing.
Example 42: Human Clinical Trial: Monotherapy with Human Anti-24P4C12 Antibody
Anti-24P4C12 antibodies are safe in connection with the above-discussed adjunctive trial, a Phase II human clinical trial confirms the efficacy and optimum dosing for monotherapy. Such trial is accomplished, and entails the same safety and outcome analyses, to the above-described adjunctive trial with the exception being that patients do not receive chemotherapy concurrently with the receipt of doses of anti-24P4C12 antibodies.
Example 43: Human Clinical Trial: Diagnostic Imaging with Anti-24P4C12 Antibody
Once again, as the adjunctive therapy discussed above is safe within the safety criteria discussed above, a human clinical trial is conducted concerning the use of anti-24P4C12 antibodies as a diagnostic imaging agent. The protocol is
designed in a substantially similar manner to those described in the art, such as in Divgi ef al. J. Natl. Cancer Inst. 83:97-104 (1991). The antibodies are found to be both safe and efficacious when used as a diagnostic modality.
Example 44: Homology Comparison of 24P4C12 to Known Seguences
The 24P4C12 protein of Figure 3 has 710 amino acids with calculated molecular weight of 79.3 kDa, and pi of 8.9. Several variants of 24P4C12 have been identified, including 4 SNPs (namely v.1 , v.3, v.5, v.6) and 3 splice variants (namely v.7, v.8 and v.9) (figures 10 and 11). 24P4C12 variants v.3, v.5, and v.6 differ from 24P4C12 v.1 by 1 amino acid each, at aa positions 187, 326 and 436. respectively. Variant v.7 carries a deletion of 111 aa long starting at aa 237, while variant v.8 and v.9 contain insertions at aa 642 and 378, respectively. The 24P4C12 protein exhibits homology to a previously cloned human gene, namely NG22 also known as chorine transporter-like protein 4 (gi 14249468). It shows 99% identity and 99% homology to the CTL4 protein over the length of that protein (Figure 4). 24P4C12 is a multi-transmembrane protein, predicted to carry 10, 11 or 13 transmembrane domains. Bioinformatic analysis indicates that the 24P4C12 protein localizes to the plasma membrane with some endoplasmic reticulum localization (see Table L). Recent evidence indicates that the 24P4C12 protein is a 10 transmembrane protein that localizes to the cell surface (O'Regan S et al PNAS 2000, 97:1835).
Choline as an essential component of cell membranes that plays an important role in cell integrity, growth and survival of normal and tumor cells. Choline accumulates at increased concentration in tumor cells relative to their normal counterparts and as such constitutes a tool for the detection of cancer cells by magnetic resonance imaging (Kurhanewicz J et al, J Magn Reson Imaging. 2002.). In addition to its role in maintaining membrane integrity, choline mediates signal transduction event from the membrane to the nucleus (Spiegel S, Milstien S. J Me br Biol. 1995, 146:225). Choline metabolites include sphingosylphosphorylcholine and lysophosphatidylcholine, both of which activate G-protein coupled receptors (Xu F et al Biochim Biophys Acta 2002, 1582:81 ). In addition, choline results in the activation of kinase pathways including Raf-1 (Lee M, Han SS, Cell Signal 2002, 14:373.). Choline also plays a role in regulating DNA methylation and regulation of gene expression. For example, choline methabolites regulate the expression of cytokines and chemokines essential for tumor growth (Schwartz BM et al, Gynecol Oncol. 2001, 81:291; Denda A et al, Carcinogenesis. 2002, 23:245). Due to its effect on cell signaling and gene expression, choline controls cell growth and survival (Holmes-McNary MQet al, J Biol Chem. 2001, 276:41197; Albright et al, FASEB 1996, 10:510). Choline deficiency results in cell death, apoptosis and transformation, while accumulation of choline is associated with tumor growth (Zeisel S et al, Carcinogenesis 1997, 18:731). Accordingly, when 24P4C12 functions as a regulator of tumor formation, cell proliferation, invasion or cell signaling, 24P4C12 is used for therapeutic, diagnostic, prognostic and/or preventative purposes.
Example 45: Identification and Confirmation of Potential Signal Transduction Pathways
Many mammalian proteins have been reported to interact with signaling molecules and to participate in regulating signaling pathways. (J Neurochem. 2001; 76:217-223). In particular, choline have been reported to activate MAK cascades as well as G proteins, and been associated with the DAG and ceramide and sphingophosphorylcholine signaling pathway (Cummings et al, above). In addition, choline transmit its signals by regulating choline-kinase and phospholipase activity, ■ resulting in enhance tumorigenic effect (Ramirez et al, Oncogene. 2002, 21:4317; Lucas et al, Oncogene.2001, 20:1110; Chung T etal, Cell Signal. 2000, 12:279).
Using immunopredpitation and Western blotting techniques, proteins are identified that associate with 24P4C12 and mediate signaling events. Several pathways known to play a role in cancer biology can be regulated by 24P4C12, including phosphoiipid pathways such as PI3K, AKT, etc, adhesion and migration pathways, induding FAK, Rho, Rac-1, etc, as well as mitogenic/survival cascades such as ERK, p38, etc (Cell Growth Differ. 2000,11:279; J Biol Chem. 1999, 274:801 , Oncogene. 2000, 19:3003; J. Cell Biol. 1997, 138:913). Using Western blotting and other techniques, the ability of
24P4C12 to regulate these pathways is confirmed. Cells expressing or lacking 24P4C12 are either left untreated or stimulated with cytokines, androgen and anti-integrin antibodies. Cell lysates are analyzed using anti-phospho-spedfic antibodies (Cell Signaling, Santa Cruz Biotechnology) in order to detect phosphorylation and regulation of ERK, p38, AKT, PI3K, PLC and other signaling molecules.
To confirm that 24P4C12 directly or indirectly activates known signal transduction pathways in cells, luciferase (luc) based transcriptional reporter assays are carried out in cells expressing individual genes. These transσiptional reporters contain consensus-binding sites for known transcription factors that lie downstream of well-characterized signal transduction pathways. The reporters and examples of these associated transcription factors, signal transduction pathways, and activation stimuli are listed below.
1. NFkB-luc, NFkB/Rel; Ik-kinase/SAPK; growth/apoptosis/stress
2. SRE-luc, SRF/TCF/ELK1; MAPK/SAPK; growth/differentiation
3. AP-1-luc, FOS/JUN; MAPK/SAPK/PKC; growth/apoptosis/stress
4. ARE-luc, androgen receptor; steroids/MAPK; growtfi/differentiation/apoptosis
5. p53-luc, p53; SAPK; growth/differ entiation/apoptosis
6. CRE-luc, CREB/ATF2; PKA/p38; growth/apoptosis/stress
7. TCF-luc, TCF/Lef; Q-catenin, Adhesion invasion
Gene-mediated effects can be assayed in cells showing mRNA expression. Luciferase reporter plasmids can be introduced by lipid-mediated transfection (TFX-50, Promega). Luciferase activity, an indicator of relative transσiptional activity, is measured by incubation of cell extracts with luciferin substrate and luminescence of the reaction is monitored in a luminometer.
Signaling pathways activated by 24P4C12 are mapped and used for the identification and validation of therapeutic targets. When 24P4C12 is involved in cell signaling, it is used as target for diagnostic, prognostic, preventative and/or therapeutic purposes.
Example 46: 24P4C12 Functions as a Choline transporter
Sequence and homology analysis of 24P4C12 indicate that 24P4C12 carries a transport domain and that 24P4C12 functions as a choline transporter. In order to confirm that 24P4C12 transports choline, primary and tumor cells, includeing prostate, colon, bladder and lung lines, are grown in the presence and absence of 3H-choline. Radioactive choline uptake is measured by counting incorporated counts per minutes (cpm). Parental 24P4C12 negative cells are compared to 24P4C12- expressing cells using this and similar assays. Similarly, parental and 24P4C12-expressing cells can be compared for choline content using NMR specfroscopy. These assay systems can be used to identify small molecules and antibodies that interfere with choline uptake and/or with the function of 24P4C12.
Thus, compounds and small molecules designed to inhibit 24P4C12 function and downstream signaling events are used for therapeutic diagnostic, prognostic and/or preventative purposes.
Example 47: Regulation of Transcription
The cell surface localization of 24P4C12 and its ability to regulate DNA methylation indicate that it is effectively used as a modulator of the transcriptional regulation of eukaryotic genes. Regulation of gene expression is confirmed, e.g., by studying gene expression in cells expressing or lacking 24P4C12. For this purpose, two types of experiments are performed.
In the first set of experiments, RNA from parental and 24P4C12-expressing cells are extracted and hybridized to commercially available gene arrays (Clontech) (Smid-Koopman E et al. Br J Cancer. 2000. 83:246). Resting cells as well as cells treated with FBS, pheromones, or growth factors are compared. Differentially expressed genes are identified in accordance with procedures known in the art. The differentially expressed genes are then mapped to biological pathways (Chen K et al. Thyroid. 2001. 11:41.).
In the second set of experiments, specific transcriptional pathway activation is evaluated using commercially available (Stratagene) luciferase reporter constructs including: NFkB-luc, SRE-luc, ELK1-luc, ARE-luc, p53-luc, and CRE-luc. These transcriptional reporters contain consensus binding sites for known transcription factors that lie downstream of well- characterized signal transduction pathways, and represent a good tool to ascertain pathway activation and screen for positive and negative modulators of pathway activation.
Thus, 24P4C12 plays a role in gene regulation, and it is used as a target for diagnostic, prognostic, preventative and/or therapeutic purposes.
Example 48 : Involvement in Tumor Progression
The 24P4C12 gene can contribute to the growth of cancer cells. The role of 24P4C12 in tumor growth is confirmed in a variety of primary and transfected cell lines including prostate, and bladder cell lines, as well as NIH 3T3 cells engineered to stably express 24P4C12. Parental cells lacking 24P4C12 and cells expressing 24P4C12 are evaluated for cell growth using a well-documented proliferation assay (Fraser SP, et al., Prostate 2000;44:61 , Johnson DE, Ochieng J, Evans SL. Anticancer Drugs. 1996, 7:288). Such a study was performed on prostate cancer cells and the results are shown in figure 28. The growth of parental PC3 and PC3-24P4C12 cells was compared in low (0.1%) and 10% FBS. Expression of 24P4C12 imparted a growth advantage to PC3 cells grown in 10% FBS. Similarly, expression of 24P4C12 in NIH-3T3 cells enhances the proliferation of these cells relative to control 3T3-neo cells. The effect of 24P4C12 can also be observed on cell cycle progression. Control and 24P4C12-expressing cells are grown in low serum overnight, and treated with 10% FBS for 48 and 72 hrs. Cells are analyzed for BrdU and propidium iodide incorporation by FACS analysis.
To confirm the role of 24P4C12 in the transformation process, its effect in colony forming assays is investigated. Parental NIH-3T3 cells lacking 24P4C12 are compared to NIH-3T3 cells expressing 24P4C12, using a soft agar assay under stringent and more permissive conditions (Song Z. et al. Cancer Res. 2000:60:6730).
To confirm the role of 24P4C12 in invasion and metastasis of cancer cells, a well-established assay is used. A non-limiting example is the use of an assay which provides a basement membrane or an analog thereof used to detect whether cells are invasive (e.g., a Transwell Insert System assay (Becton Dickinson) (Cancer Res. 1999; 59:6010)). Confrol cells, including prostate, and bladder cell lines lacking 24P4C12 are compared to cells expressing 24P4C12. Cells are loaded with the fluorescent dye, calcein, and plated in the top well of a support structure coated with a basement membrane analog (e.g. the Transwell insert) and used in the assay. Invasion is determined by fluorescence of cells in the lower chamber relative to the fluorescence of the entire cell population.
24P4C12 can also play a role in cell cycle and apoptosis. Parental cells and cells expressing 24P4C12 are compared for differences in cell cycle regulation using a well-established BrdU assay (Abdel-Malek ZA. J Cell Physiol. 1988, 136:247). In short, cells are grown under both optimal (full serum) and limiting (low serum) conditions are labeled with BrdU and stained with anti-BrdU Ab and propidium iodide. Cells are analyzed for entry into the G1, S, and G2M phases of the cell cycle. Alternatively, the effect of stress on apoptosis is evaluated in control parental cells and cells expressing 24P4C12, including normal and tumor prostate, colon and lung cells. Engineered and parental cells are treated with various chemotherapeutic agents, such as etoposide, flutamide, etc, and protein synthesis inhibitors, such as cycloheximide. Cells
are stained with annexin V-FITC and cell death is measured by FACS analysis. The modulation of cell death by 24P4C12 can play a critical role in regulating tumor progression and tumor load.
When 24P4C12 plays a role in cell growth, transformation, invasion or apoptosis, it is used as a target for diagnostic, prognostic, preventative and/or therapeutic purposes.
Example 49: Involvement in Angiogenesis
Angiogenesis or new capillary blood vessel formation is necessary for tumor growth (Hanahan D, Folkman J. Cell. 1996, 86:353; Folkman J. Endocrinology. 1998139:441). Based on the effect of phsophodieseterase inhibitors on endothelial cells, 24P4C12 plays a role in angiogenesis (DeFouw L et al, Miσovasc Res 2001, 62:263). Several assays have been developed to measure angiogenesis in vitro and in vivo, such as the tissue culture assays endothelial cell tube formation and endothelial cell proliferation. Using these assays as well as in vitro neo-vascularization, the role of 24P4C12 in angiogenesis, enhancement or inhibition, is confirmed.
For example, endothelial cells engineered to express 24P4C12 are evaluated using tube formation and proliferation assays. The effect of 24P4C12 is also confirmed in animal models in vivo. For example, cells either expressing or lacking 24P4C12 are implanted subcutaneously in immunocompromised mice. Endothelial cell migration and angiogenesis are evaluated 5-15 days later using immunohistochemistry techniques. 24P4C12 affects angiogenesis and it is used as a target for diagnostic, prognostic, preventative and/or therapeutic purposes.
Example 50: Involvement in Adhesion
Cell adhesion plays a critical role in tissue colonization and metastasis. The presence of leucine rich and cysteine rich motifs in 24P4C12 is indicative of its role in cell adhesion. To confirm that 24P4C12 plays a role in cell adhesion, confrol cells lacking 24P4C12 are compared to cells expressing 24P4C12, using techniques previously described (see, e.g., Haieret al, Br. J. Cancer. 1999, 80:1867; Lehr and Pienta, J. Natl. Cancer Inst 1998, 90:118). Briefly, in one embodiment, cells labeled with a fluorescent indicator, such as calcein, are incubated on tissue culture wells coated with media alone or with matrix proteins. Adherent cells are detected by fluorimetric analysis and percent adhesion is calculated. This experimental system can be used to identify proteins, antibodies and/or small molecules that modulate cell adhesion to extracellular matrix and cell-cell interaction. Since cell adhesion plays a critical role in tumor growth, progression, and, colonization, the gene involved in this process can serves as a diagnostic, preventative and therapeutic modality.
Example 51: Detection of 24P4C12 protein in cancer patient specimens
To determine the expression of 24P4C12 protein, specimens were obtained from various cancer patients and stained using an affinity purified polyclonal rabbit antibody raised against the peptide encoding amino acids 1-14 of 24P4C12 variant 1 and conjugated to KLH (See, Example 10: Generation of 24P4C12 Polyclonal Antibodies.) This antiserum exhibited a high titer to the peptide (>10,000) and recognized 24P4C12 in transfected 293T cells by Western blot and flow cytometry (Figure 24) and in stable recombinant PC3 cells by Western blot and immunohistochemistry (Figure 25). Formalin fixed, paraffin embedded tissues were cut into 4 iσon sections and mounted on glass slides. The sections were dewaxed, rehydrated and treated with antigen retrieval solution (0.1 M Tris, pH10) at high temperature. Sections were then incubated in polyclonal rabbit anti-24P4C12 antibody for 3 hours. The slides were washed three times in buffer and further incubated with DAKO En Vision+™ per oxidase-conjugated goat anti-rabbit immunoglobulin secondary antibody (DAKO Corporation, Carpenteria, CA) for 1 hour. The sections were then washed in buffer, developed using the DAB kit (SIGMA Chemicals), counterstained using hematoxylin, and analyzed by bright field microscopy. The results showed expression of 24P4C12 in cancer patients' tissue (Figures 29 and 30). Tissue from prostate cancer patients showed expression of 24P4C12 in the
tumor cells and in the prostate epithelium of tissue normal adjacent to tumor (Figure 29). Generally, expression of 24P4C12 was high in all prostate tumors and was expressed mainly around the cell membrane indicating that 24P4C12 is membrane associated in prostate tissues. All of the prostate samples tested were positive for 24P4C12. Other tumors that were positive for 24P4C12 included colon adenocarcinoma, breast ductal carcinoma, pancreatic adenocarcinoma, lung adenocarcinoma, bladder transitional cell carcinoma and renal clear cell carcinoma (Figure 30). Normal tissues investigated for expression of 24P4C12 included heart, skeletal muscle, liver, brain, spinal cord, skin, adrenal, lymph node, spleen, salivary gland, small intestine and placenta. None demonstrated any expression of 24P4C12 by immunohistochemistry. Normal adjacent to tumor tissues were also studied to determine the presence of 24P4C12 protein by immunohistochemistry. These included breast, lung, colon, ileum, bladder, kidney and panσeas. In some of the tissues from these organs there was weak expression of 24P4C12. This expression may relate to the fact that the samples were not truly normal and may indicate a precancerous change. The ability to identify malignancy in tissue that has not undergone obvious morphological changes is an important diagnostic modality for cancerous and precancerous conditions.
These results indicate that 24P4C12 is a target for diagnostic, prophylactic, prognostic and therapeutic applications in cancer.
Throughout this application, various website data content, publications, patent applications and patents are referenced. (Websites are referenced by their Uniform Resource Locator, or URL, addresses on the World Wide Web.)
The present invention is not to be limited in scope by the embodiments disclosed herein, which are intended as single illustrations of individual aspects of the invention, and any that are functionally equivalent are within the scope of the invention. Various modifications to the models and methods of the invention, in addition to those described herein, will become apparent to those skilled in the art from the foregoing description and teachings, and are similarly intended to fall within the scope of the invention. Such modifications or other embodiments can be practiced without departing from the frue scope and spirit of the invention.
TABLES:
TABLE I: Tissues that Express 24P4C12: a. Malignant Tissues
.Prostate
Bladder
Kidney
Lung
Colon
Ovary
Breast
Uterus
Stomach
TABLE II: Amino Acid Abbreviations
TABLE III : Amino Acid Substitution Matrix
Adapted from the GCG Software 9.0 BLOSUM62 amino acid substitution matrix (block substitution matrix). The higher the value, the more likely a substitution is found in related, natural proteins. (See world wide web URL ikp unibe.ch/manual/blosum62.html )
A C D E F G H I K L M N P Q R S T V W Y .
4 0 -2 -1 -2 0 -2 -1 - 1 -1 -1 -2 - 1 -1 -1 1 0 0 -3 -2 A
9 -3 -4 -2 -3 -3 -1 -3 -1 -1 -3 -3 -3 -3 -1 - 1 -1 -2 -2 C
6 2 -3 - 1 -1 -3 - 1 -4 -3 1 - 1 0 -2 0 -1 -3 -4 -3 D
5 -3 -2 0 -3 1 -3 -2 0 - 1 2 0 0 -1 -2 -3 -2 E
6 -3 -1 0 - 3 0 0 -3 -4 -3 -3 -2 -2 -1 1 3 F
6 -2 -4 -2 -4 -3 0 -2 -2 -2 0 -2 -3 -2 -3 G
8 -3 - 1 -3 -2 1 -2 0 0 -1 -2 -3 -2 2 H
4 -3 2 1 -3 -3 -3 -3 -2 - 1 3 -3 -1 I
5 -2 -1 0 - 1 1 2 0 -1 -2 -3 -2 K
4 2 -3 - 3 -2 -2 -2 - 1 1 -2 - 1 L
5 -2 -2 0 -1 -1 -1 1 -1 -1 M
6 -2 0 0 1 0 -3 -4 -2 N
7 - 1 -2 -1 -1 -2 -4 -3 P 5 1 0 -1 -2 -2 -1 Q 5 -1 -1 -3 -3 -2 R 4 1 -2 -3 -2 S
5 0 -2 -2 T 4 -3 -1 V 11 2 W 7 Y
TABLE IV:
HLA Class l/ll Motifs/Super otifs
TABLE IV (A): HLA Class I Supermotifs/Motifs
Bolded residues are preferred, italidzed residues are less preferred: A peptide is considered motif-bearing if it has primary anchors at each primary anchor position for a motif or supermotif as specified in the above table.
TABLE IV (B): HU Class II Supermotif
TABLE IV (C): HLA Class II Motifs
MOTIFS 1° anchor 1 2 3 4 5 1° anchor 6 7 8 9
DR4 preferred FMYL/VIV M T I VSTCPALIM MH MH deleterious W R WDE
DR1 preferred UΨLIVWY PAMQ VMATSPL/C M AVM deleterious C CH FD CWD GDE D
DR7 preferred ψuvw M W A IVMSACTPZ. M IV deleterious C G GRD N G
DR3 MOTIFS 1° anchor 1 2 3 1° anchor 4 5 1° anchor 6
Motif a preferred LIVMFY D
Motif b preferred LIVMFAY DNQEST KRH
DR Supermotif MFL/VWY VMSTACPL/
Italicized residues indicate less preferred or "tolerated" residues
TABLE IV (D): HLA Class I Supermotifs
POSITION: 1 C-terminus
TABLE IV (E): HU Class I Motifs
POSITION 1 C- terminus or C-terminus
A1 preferred GFYW 1 "Anchor DEA YFW P DEQN YFW TAnchor 9-mer STM Y deleterious DE RHKLIVMP A G A
A1 preferred GRHK ASTCLIVM 1 "Anchor GSTC ASTC LIVM DE TAnchor 9-mer DBAS Y deleterious A RHKDEPYFW DE PQN RHK PG GP
A1 prefened YFW 1 "Anchor DEAQN A YFWQN PASTC GDE P 1 "Anchor 10- STM Y mer deleterious GP RHKGLIVM DE RHK QNA RHKYFW RHK A
A1 preferred YFW STCLIVM 1° Anchor A YFW PG G YFW 1 "Anchor 10- DEAS Y mer deleterious RHK RHKDEPYFW P G PRHK QN
A2.1 preferred YFW 1 "Anchor YFW STC YFW A P 1 "Anchor 9-mer LM. VQAT VLIMAT deleterious DEP DERKH RKH DERKH
POSITION: ! 2 3 4 5 6 7 8 9 C- Terminus
A2.1 preferred AYFW 1 "Anchor LVIM G FYWL 1 "Anchor 10- IMIVQAT VIM VUMAT mer deleterious DEP DE RKHA RKH DERK RKH H
A3 preferred RHK 1 "Anchor YFW PRHKYF A YFW P 1 "Anchor LMVISATFCGD W KYRHFA deleterious DEP DE
A11 preferred A 1 "Anchor YFW YFW A YFW YFW P 1 "Anchor VTLMISAGNCD KRYH r deleterious DEP A G
A24 prefened YFWRHK 1 "Anchor STC YFW YFW 1 "Anchor 9-mer YFWM FLIW deleterious DEG DE G QNP DERH G AQN K
A24 Preferred 1 "Anchor P YFWP P 1 "Anchor 10- YFWM FLIW mer
Deleterious GDE QN RHK DE A QN DEA
A310 Preferred RHK 1 "Anchor YFW P YFW YFW AP 1 "Anchor 1 MVTAL/S RK
Deleterious DEP DE ADE DE DE DE
A330 Preferred 1 "Anchor YFW AYFW 1 "Anchor 1 MVALF/ST RK
Deleterious GP DE
A680 Preferred YFWSTC 1 "Anchor YFWLIV YFW P 1 "Anchor 1 AVTMSU M RK deleterious GP DEG RHK A
B070 Preferred RHKFWY 1 "Anchor RHK RHK RHK RHK PA 1° Anchor 2 P LMFWYAI
V deleterious DEQNP DEP DE DE GDE QN DE
POSITION 1 9 C- terminus or C-terminus
A1 prefened GFYW 1 "Anchor DEA YFW P DEQN YFW 1 "Anchor 9-mer STM Y deleterious DE RHKLIVMP A G A
A1 prefened GRHK ASTCLIVM 1 "Anchor GSTC ASTC LIVM DE 1 "Anchor 9-mer DBAS Y deleterious A RHKDEPYFW DE PQN RHK PG GP
B350 Preferred FWYLIVM 1 "Anchor FWY FWY 1 "Anchor 1 P LMFWY/V
A deleterious AGP G G
B51 Prefe ed LIVMFWY 1 "Anchor FWY STC FWY G FWY 1 "Anchor P UVFWYA M deletenous AGPDER DE G DEQN GDE HKSTC
B530 preferred LIVMFWY 1 "Anchor FWY STC FWY LIVMFW FWY 1 "Anchor 1 P Y IMFWY- .L V deleterious AGPQN G RHKQN DE
B540 prefened FWY 1 "Anchor FWYLIVM LIVM ALIVM FWYA . 1 "Anchor 1 P P ATIVLMF WY deleterious GPQNDE GDESTC RHKDE DE QNDGE DE
TABLE IV (F):
Table VI: Motifs and Post-translational Modifications of 24P4C12
N-glycosylation site
29-32 NRSC (SEQ ID NO: 48)
69-72 NSTG (SEQ ID NO: 49) 155-158 NMTV (SEQ ID NO: 50) 197-200 NDTT (SEQ ID NO: 51) 298-301 NLSA (SEQ ID NO: 52) 393-396 NISS (SEQ ID NO: 53) 405-408 NTSC (SEQ ID NO: 54) 416-419 NSSC (SEQ ID NO: 55) 678-681 NGSL (SEQ ID NO: 56)
Protein kinase C phosphorylation site 22-24 SfR 218-220 SvK 430-432 SsK 494-496 TIR 573-575 SaK 619-621 SgR
Casein kinase II phosphorylation site 31 - 34 SCTD (SEQ ID NO: 57) 102-105 SVAE (SEQ ID NO: 58) 119-122 SCPE (SEQ ID NO: 59) 135-138 TVGE (SEQ ID NO: 60) 304 - 307 SVQE (SEQ ID NO: 61)
Tyrosine kinase phosphorylation site
6 - 13 RDEDDEAY (SEQ ID NO: 62)
N-myristoylation site
72 - 77 GAYCGM (SEQ ID NO: 63)
76 - 81 GMGENK (SEQ ID NO: 64) 151 - 156 GVPWNM (SEQ ID NO: 65) 207 - 212 GLIDSL (SEQ ID NO: 66) 272 - 277 GIYYCW (SEQ ID NO: 67) 287 - 292 GASISQ (SEQ ID NO: 68) 349 - 354 GQMMST (SEQ ID NO: 69) 449- 454 GLFWTL (SEQ ID NO: 70) 467 - 472 GAFASF (SEQ ID NO: 71)
Amidation site
695 - 698 IGKK (SEQ ID NO: 72)
Leucine zipper pattern
245 - 266 LFILLLRLVAGPLVLVLILGVL (SEQ ID NO: 73)
Cysteine-rich region
536 - 547 CIMCCFKCCLWC (SEQ ID NO. 74)
Table VII:
Search Peptides
Variant 1, 9- ers, 10-mers, 15- ers (SEQ ID NO: 75)
MGGKQRDEDD EAYGKPVKYD PSFRGPIKNR SCTDVICCVL FLLFILGYIV VGIVAWLYGD
PRQVLYPRNS TGAYCGMGEN KDKPYLLYFN IFSCILSSNI ISVAENGLQC PTPQVCVSSC
PEDPWTVGKN EFSQTVGEVF YTKNRNFCLP GVPWNMTVIT SLQQELCPSF LLPSAPALGR
CFPWTNVTPP ALPGITNDTT IQQGISGLID SLNARDISVK IFEDFAQSWY WILVALGVAL
VLSLLFILLL RLVAGPLVLV LILGVLGVLA YGIYYC EEY RVLRDKGASI SQLGFTTNLS
AYQSVQETWL AALIVLAVLE AILLLMLIFL RQRIRIAIAL LKEASKAVGQ MMSTMFYPLV
TFVLLLICIA YWAMTALYLA TSGQPQYVLW ASNISSPGCE KVPINTSCNP TAHLVNSSCP
GLMCVFQGYS SKGLIQRSVF NLQIYGVLGL FWTLNWVLAL GQCVLAGAFA SFYWAFHKPQ
DIPTFPLISA FIRTLRYHTG SLAFGALILT LVQIARVILE YIDHKLRGVQ NPVARCIMCC
FKCCLWCLEK FIKFLNRNAY IMIAIYGKNF CVSAKNAFML LMRNIVRVW LDKVTDLLLF
FGKLLWGGV GVLSFFFFSG RIPGLGKDFK SPHLNYYWLP IMTSILGAYV I SGFFSVFG
MCVDTLFLCF LEDLERNNGS LDRPYYMSKS LLKILGKKNE APPDNKKRKK
Variant 3 :
9-mers
GRCFPWTNITPPALPGI (SEQ ID NO: 76)
10-mers
LGRCFPWTNITPPALPGIT (SEQ ID NO: 77)
15-mers
PSAPALGRCFPWTNITPPALPGITNDTTI (SEQ ID NO: 78)
Variant 5 :
9-mers
VLEAILLLVLIFLRQRI (SEQ ID NO: 79)
10-mers
AVLEAILLLVLIFLRQRIR (SEQ ID NO: 80)
15-mers
ALIVLAVLEAILLLVLIFLRQRIRIAIAL (SEQ ID NO: 81)
Variant 6:
9-mers
GYSSKGLIPRSVFNLQI (SEQ ID NO: 82)
10-mers
QGYSSKGLIPRSVFNLQIY (SEQ ID NO : 83 )
15-mers
LMCVFQGYSSKGLI PRSVFNLQIYGVLGL ( SEQ ID NO : 84 )
Variant 7
9-mers
SWYWILVAVGQMMSTM ( SEQ ID NO : 85 )
10-mers
QSWYWILVAVGQMMSTMF (SEQ ID NO: 86)
15-mers
FEDFAQSWYWILVAVGQMMSTMFYPLVT (SEQ ID NO: 87)
Variant 8
9-mers
NYYWLPIMRNPITPTGHVFQTSILGAYV (SEQ ID NO: 88)
10-mers
LNYYWLPIMRNPITPTGHVFQTSIEGAYVI (SEQ ID NO: 89)
15-mers
FKSPHLNYYWLPIMRNPITPTGHVFQTSILGAYVIASGFF (SEQ ID NO: 90)
Variant 9
9-mers
YWAMTALYPLPTQPATLGYVLWASNI (SEQ ID NO: 91)
10-mers
AYWAMTALYPLPTQPATLGYVLWASNIS (SEQ ID NO: 92)
15-mers
LLICIAYWAMTALYPLPTQPATLGYVLWASNISSPGCE (SEQ ID NO: 93)
Tables VIII -XXI:
Table VIII-V3-HLA-Al-9mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 7; each start position is specified, the length of peptide is
9 amino acids, and the end position for each peptide is the start position plus eight.
Start II Subsequence Score
Table VIII-V6-HLA-A1-9mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 13; each start position is spedfied, the length of peptide is
9 amino acids, and the end position for each peptide is the start position plus eight.
Start I Subsequence [ Score
Table IX-V3-HLA-A1-10mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 7; each start position is spedfied, the length of peptide is
10 amino acids, and the end position for each peptide is the start position plus nine.
Table X-V1-HLA-A0201-9mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 3; each start position is specified, the length of peptide is
9 amino adds, and the end position for each peptide is the start position plus eight.
Start || Subsequence ||Score
Table X-V9-HLA-A0201-9mers- 24P4C12
Table XI-V8-HLA-A0201-10mers-
24P4C12
Each peptide is a portion of SEQ iTable XI-V6-HLA-A0201-10mers- ID NO: 17; each start position is 24P4C12 specified, the length of peptide is
10 amino acids, and the end position for each peptide is the start position plus nine.
Start jl Subsequence ||Score[
Table XII-V9-HLA-A3-9mers- 24P4C12
Table XIII-V8-HLA-A3-10mers-
24P4C12
Each peptide is a portion of SEQ
Table XIII-V3-HLA-A3-10mers- is 24P4C12 Table XIII-V6-HLA-A3-1 Omers- ID NO: 17; each start position 24P4C12 specified, the length of peptide is
Start || Subsequence [Score 10 amino acids, and the end position for each peptide is the start position plus nine-
Start || Subsequence Score
18 ~|| HVFQTSILGA 0.300
Table XIII-V8-HLA-A3-10mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 17; each start position is specified, the length of peptide is
10 amino acids, and the end position for each peptide is the start position plus nine.
Start || Subsequence Score
5 II WLPIMRNPIT 0.100
21 II QTSILGAYVI 0.090
_UL LNYYWLPIMR 0.080
- 3-JL ITPTGHVFQT 0.045
-JUL NPITPTGHVF 0.030
- jc IMRNPITPTG 0.030
15 II PTGHVFQTSI 0.009 DC FQTSILGAYV 0.006
-HE PIMRNPITPT 0.003
14 II TPTGHVFQTS 0.003
_πJUL YWLPIMRNPI 0.001
- LPIMRNPITP 0.001
16 II TGHVFQTSIL 0.001
2 II NYYWLPIMRN 0.000 n MRNPITPTGH 0.000
-JET PITPTGHVFQ 0.000
17 II GHVFQTSILG 0.000
Z- RNPITPTGHV 0.000
3 II YYWLPIMRNP 0.000
[Table XIV-V6-HLA-A1101 -9mers- 24P4C12
Start || Subsequence [[Score
Each peptide is a portion of SEQ ID NO: 13; each start position is specified, the length of peptide is
9 amino acids, and the end position for each peptide is the start position plus eight.
Table XV-V1-A1101-10mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 3; each start position is specified, the length of peptide is
10 amino acids, and the end position for each peptide is the start position plus nine.
Start || Subsequence ||Scorel
Table XV-V9-HLA-A1101- 10mers-24P4C12
Table XVI-V3-HLA-A24-9n.ers- 24P4C12
Table XVII-V9-HLA-A24-10mers- 24P4C12
Each peptide is a portion of SEQ
ID NO: 19; each start position is specified, the length of peptide is
10 amino acids, and the end position for each peptide is the start position plus nine.
I Start [ Subsequence |Scorej
10 PLPTQPATLG ||0.002
Table XIX-V1-HLA-B7-10mers- 24P4C12
Table XIX-V7-HLA-B7-10mers-
24P4C12
Each peptide is a portion of SEQ
Table XIX-V5-HLA-B7-10mers-
ID NO: 15; each start position is 24P4C12 specified, the length of peptide is
10 amino adds, and the end position for each peptide is the start position plus nine.
Table XIX-V9-HLA-B7-10mers- 24P4C12
TableXXII-V1-HLA-A1-9mers.
24P4C12
Each peptide is a portion of
SEQ ID NO: 3; each start position is specified, the i length of peptide is 9 amino acids, and the end position for each peptide is the start position plus eight.
Pos 123456789 score
80 NKDKPYLLY 34
58 YGDPRQVLY 33
222 FEDFAQSWY 26
5 QRDEDDEAY 25
77 MGENKDKPY 25
263 LGVLGVLAY 24
489 SAFIRTLRY 23
513 QIARVILEY 23
628 DFKSPHLNY 22
40 LFLLFILGY 21
267 GVL-AYG1YY 21
363 VLLLICIAY 21
421 GLMCVFQGY 21
50 WGIVAWLY 20
318 VLEAILLLM 20
629 FKSPHLNYY 20
133 SQTVGEVFY 19
437 RSVFNLQIY 19
662 CVDTLFLCF 19
11 EAYGKPVKY 18
370 AYWAMTALY 18
18 KYDPSFRGP 17
32 CTDVICCVL 17
66 YPRNSTGAY 17
277 WEEYRVLRD 17
379 LATSGQPQY 17
594 VTDLLLFFG 17
165 ELCPSFLLP 16
353 STMFYPLVT 16
398 GCEKVPINT 16
552 IKFLNRNAY 16
590 VLDKVTDLL 16
678 NGSLDRPYY 16
TableXXII-V3-HLA-A1 -9mers- 24P4C12
Each peptide is a portion of
SEQ ID NO: 7; each start position is specified, the length of peptide is 9 amino acids, and the end position for each peptide is the start position plus eight. Pos 123456789 score
TableXXII-V3-HLA-A1 -9mers- 24P4C12
Each peptide is a portion of
SEQ ID NO: 7; each start position is specified, the length of peptide is 9 amino acids, and the end position for each peptide is the start position plus eight. Pos 123456789 score
8 NITPPALPG 11
9 ITPPALPGI 10 6 WTNITPPAL 6 3 CFPWTNjTP 5
6 LVAVGQMMS 3 TableXXIII-V1-HLA-A0201-
TableXXII-V5-HLA-A1 -9mers- 1 SWYWILVAV 2 9mers-24P4C12 24P4C12 2 WYWILVAVG 2 Each peptide is a portion of
Each peptide is a portion of SEQ ID NO: 3; each start
SEQ ID NO: 11; each start TableXXII-V8-HLA-A1-9mers- position is specified, the length position is specified, the length 24P4C12 of peptide is 9 amino acids, and of peptide is 9 amino acids, and Each peptide is a portion of SEQ the end position for each the end position for each ID NO: 17; each start position is peptide is the start position plus peptide is the start position plus specified, the length of peptide is eight. eight. 9 amino acids, and the end Pos 123456789 score Pos 123456789 score position for each peptide is the 260 VULGVLGV 31 1 VLEAILLLV 20 start position plus eight. 244 LLFILLLRL 29
7 LLVLIFLRQ 10 580 LLMRNIVRV 29
Pos 123456789 e 95 ILSSNΪISV 28
TableXXII-V6-HLA-A1-9mers- 19 FQTSILGAY 16 204 GISGLIDSL 28 24P4C12 14 PTGHVFQTS 11 261 LILGVLGVL 28
Each peptide is a portion of SEQ 12 ITPTGHVFQ 8 322 ILLLMLIFL 28 ID NO: 13; each start position is 18 VFQTSILGA 7 506 ALILTLVQI 28 specified, the length of peptide is 20 QTSILGAYV 7 170 FLLPSAPAL 27
9 amino acids, and the end 252 LVAGPLVLV 27 position for each peptide is the TableXXII-V9-HLA-A1-9mers- 449 GLFWTLNWV 27 start position plus eight. 24P4C12 487 LISAFIRTL 27 Pos 123456789 score Each peptide is a portion of 604 LLWGGVGV 27
2 YSSKGLIPR 12 SEQ ID NO: 19; each start 45 ILGYIWGI 26 1 GYSSKGLIP 7 position is specified, the length 232 ILVALGVAL 26
3 SSKGLIPRS 7 of peptide is 9 amino acids, and 233 LVALGVALV 26
8 IPRSVFNLQ 7 the end position for each 315 VLAVLEAIL 26
9 PRSVFNLQI 7 peptide is the start position plus 501 SLAFGALIL 26
6 GLIPRSVFN 5 eight. 521 YIDHKLRGV 26
Pos 123456789 score 42 LLFILGYIV 25
TableXXII-V7-HLA-A1 -9mers- 11 PIQPATLGY 31 107 GLQCPIPQV 25 24P4C12 15 AILGYVLWA 16 200 TIQQGISGL 25
Each peptide is a portion of 211 SLNARDISV 25
SEQ ID NO: 15; each start TableXXIII-V1-HLA-A0201- 239 ALVLSLLFI 25 position is specified, the length 9mers-24P4C12 257 LVLVLILGV 25 of peptide is 9 amino acids, and Each peptide is a portion of 258 VLVLILGVL 25 the end position for each SEQ ID NO: 3; each start 282 VLRDKGASI 25 peptide is the start position plus position is specified, the length 317 AVLEAILLL 25 eight. of peptide is 9 amino acids, and 457 VLALGCJCVL 25
Pos 123456789 score the end position for each 598 LLFFGKLLV 25
5 ILVAVGQMM 5 peptide is the start position plus 650 VIASGFFSV 25
3 YWILVAVGQ 4 eight. 686 YMSKSLLKI 25
7 VAVGQMMST 4 Pos 123456789 score 41 FLLFILGYI 24
TableXXIII.V1-HLA.A0201- TableXXIII-V1-HLA-A0201- TableXXIII-V1-HLA-A0201-
9mers-24P4C12 9mers-24P4C12 9mers-24P4C12
Each peptide is a portion of Each peptide is a portion of Each | peptide is a portion of
SEQ ID NO: 3; each start SEQ ID NO: 3; each start SEQ ID NO: 3; each start position is specified, the length position is specified, the I engt position is specified, the I ength of peptide is 9 amino acids, and of peptide is 9 amino acids, and of peptide is 9 amino acids, and the end position for each the end position for each the end position for each peptide i s the start position plus peptide i is the start position plus peptide is the start position plus eight. eight. eight.
Pos 123456789 score Pos 123456789 score Pos 123456789 score
49 IWGIVAWL 24 34 DVICCVLFL 20 514 IARVILEYI 18
310 LAAUVLAV 24 38 CVLFLLFIL 20 517 VILEYIDHK 18
311 AALIVLAVL 24 44 FILGYI G 20 583 RNIVRVWL 18
333 RIRIAIALL 24 207 GUDSLNAR 20 602 GKLLWGGV 18
434 LIQRSVFNL 24 228 SWYWTLVAL 20 645 ILGAYVIAS 18
509 LTLVQIARV 24 234 VALGVALVL 20 46 LGYIVVGIV 17
525 KLRGVQNPV 24 236 LGVALVLSL 20 128 GKNEFSQTV 17
564 AIYGKNFCV 24 242 LSLLFILLL 20 154 WNMTVITSL 17
581 LMRNIVRVV 24 319 LEAILLLML 20 177 ALGRCFPWT 17
596 DLLLFFGKL 24 326 MLIFLRQRI 20 184 WTNVTPPAL 17
605 LWGGVGVL 24 339 ALLKEASKA 20 213 NARDISVKI 17
35 VICCVLFLL 23 364 LLLICIAYW 20 246 FILLLRLVA 17
56 WLYGDPRQV 23 417 SSCPGLMCV 20 289 SISQLGFTT 17
240 LVLSLLFIL 23 503 AFGALILTL 20 300 SAYQSVQET 17
251 RLVAGPLVL 23 633 HLNYYWLPI 20 305 VQETWLAAL 17
253 VAGPLVLVL 23 644 SILGAYVIA 20 312 ALIVLAVLE 17
309 WLAAUVLA 23 673 DLERNNGSL 20 325 LMLIFLRQR 17
340 LLKEASKAV 23 690 SLLKILGKK 20 335 RIAIALLKE 17
358 PLVTFVLLL 23 48 YIWGIVAW 19 354 TMFYPLVTF 17
494 TLRYHTGSL 23 245 LFILLLRLV 19 359 LVTFVLLLI 17
518 ILEYIDHKL 23 255 GPLVLVLIL 19 453 TLNWVLALG 17
547 CLEKF1KFL 23 262 ILGVLGVLA 19 456 WVLALGQCV 17
589 WLDKVTDL 23 268 VLAYGIYYC 19 502 LAFGALILT 17
590 VLDKVTDLL 23 291 SQLGFTTNL 19 504 FGALILTLV 17
597 LLLFFGKLL 23 318 VLEAILLLM 19 513 QIARVILEY 17
100 IISVAENGL 22 323 LLLMLIFLR 19 554 FLNRNAYIM 17
241 VLSLLFILL 22 329 FLRQRIRIA 19 560 YIMIAIYGK 17
248 LLLRLVAGP 22 351 MMSTMFYPL 19 586 VRV LDKV 17
249 LLRLVAGPL 22 365 LLICIAYWA 19 642 MTSILGAYV 17
265 VLGVLAYGI 22 414 LVNSSCPGL 19 658 VFGMCVDTL 17
446 GVLGLFWTL 22 464 VLAGAFASF 19 31 SCTDVICCV 16
452 WTLNWVLAL 22 544 CLWCLEKFI 19 43 LFILGΫIW 16
578 FMLLMRNIV 22 617 FFSGRIPGL 19 64 VLYPRNSTG 16
638 WLPIMTSIL 22 666 LFLCFLEDL 19 90 NIFSCILSS 16
660 GMCVDTLFL 22 86 LLYFNIFSC 18 119 SCPEDPWTV 16
158 VITSLQQEL 21 231 WILVALGVA 18 144 NRNFCLPGV 16
187 VTPPALPGI 21 235 ALGVAIVLS 18 148 CLPGVPWNM 16
191 ALPGITNDT 21 243 SLLFILLLR 18 161 SLQQELCPS 16
237 GVALVLSLL 21 336 IAIALLKEA 18 230 YWILVALGV 16
247 ILLLRLVAG 21 355 MFYPLVTFV 18 254 AGPLVLVLI 16
313 LIVLAVLEA 21 369 IAYWAMTAL 18 308 TWLAALIVL 16
314 IVLAVLEAI 21 380 ATSGQPQYV 18 316 LAVLEAILL 16
442 LQIYGVLGL 21 394 ISSPGCEKV 18 320 EAILLLMLI 16
507 LILTLVQIA 21 439 VFNLQ1YGV 18 357 YPLVTFVLL 16
537 IMCCFKCCL 21 459 ALGQCVLAG 18 362 FVLLLICIA 16
599 LFFGKLLW 21 510 TLVQIARVI 18 373 AMTALΫLAT 16
693 KILGKKNEA 21 511 LVQIARVIL 18 376 ALYLATSGQ 16
TableXXIII-V1-HLA-A0201- TableXXIII-V5-HLA-A0201- Each peptide is a portion of j )mers-24P4C12 9mers-24P4C12 SEQ ID NO: 17; each start
Each peptide is a portion of Each peptide is a portion of position is specified, the length
SEQ ID NO: 3; each start SEQ ID NO: 11; each start of peptide is 9 amino acids, and position i is specified, the length position is specified, the length the end position for each of peptide is 9 amino acids, and of peptide is 9 amino acids, and peptide is the start position plus the end position for each the end position for each eight. peptide is the start position plus peptide is the start position plus Pos 123456789 score eight. eight. 4 WLPIMRNPI 19
Pos 123456789 score Pos 123456789 score 7 IMRNPITPT 19
407 SCNPTAHLV 16 1 VLEAILLLV 25 20 QTSILGAYV 17
458 LALGQCVLA 16 9 VLIFLRQRI 21 10 NPITPTGHV 15
637 YWLPIMTSI 16 2 LEAILLLVL 20 16 GHVFQISIL 12
640 PIMTSILGA 16 6 LLLVLIFLR 19 15 TGHVFQTSI 11
52 GIVAWLYGD 15 3 EAILLLVLI 18 18 VFQTSILGA 11
141 YTKNRNFCL 15 4 AILLLVLIF 18 12 ITPTGHVFQ 10
225 FAQSWYWIL 15 7 LLVLIFLRQ 13 5 LPIMRNPIT 9
250 LRLVAGPLV 15 8 LVLIFLRQR 13 13 TPTGHVFQT 9
264 GVLGVLAYG 15
275 YCWEEΫRVL 15 TableXXIII-V9-HLA-A0201-
366 LICIAYWAM 15 TableXXIII-V6-HLA-A0201- 9mers-24P4C12
368 CIAYWAMTA 15 9mers-24P4C12 Each peptide is a portion of
371 YWAMTALYL 15 Each peptide is a portion of SEQ ID NO: 19; each start
374 MTALYLATS 15 SEQ ID NO: 13; each start position is specified, the length
406 TSCNPTAHL 15 position is specified, the length of peptide is 9 amino acids,
433 GLIQRSVFN 15 of peptide is 9 amino acids, and and the end position for each
443 QIYGVLGLF 15 the end position for each peptide is the start position plus
491 FIRTLRYHT 15 peptide is the start position plus eight.
573 SAKNAFMLL 15 eight. Pos 123456789 score
657 SVFGMCVDT 15 Pos 123456789 score 9 PLPTQPATL 21
663 VDTLFLCFL 15 2 YSSKGUPR 12 2 WAMTALYPL 20 1 GYSSKGUP 7 15 ATLGYVLWA 20
TableXXIII-V3-HLA-A0201- 3 SSKGLIPRS 7 6 ALYPLPTQP 16 9mers-24P4C12 8 IPRSVFNLQ 7 12 TQPATLGYV 14
Each peptide is a portion of SEQ 9 PRSVFNLQI 7 13 QPATLGYVL 14
ID NO: 7; each start position is 6 GUPRSVFN 5 16 TLGYVLWAS 14 specified, the length of peptide is 5 TALYPLPTQ 13
9 amino acids, and the end TableXXIII-V7-HLA-A0201- 4 MTALYPLPT 12 position for each peptide is the 9mers-24P4C12 8 YPLPTQPAT 12 start position plus eight. Each peptide is a portion of SEQ 3 AMTALYPLP 11
Pos 123456789 score ID NO: 15; each start position is
9 ITPPALPGI 22 specified, the length of peptide
6 WTNITPPAL 17 is 9 amino adds, and the end TableXXIV-V1-HLA-A0203-
8 NITPPALPG 11 position for each peptide is the 9mers-24P4C12
2 RCFPWTNIT 10 start position plus eight. Pos 1234567890 score
Pos 123456789 score NoResultsFound.
TableXXIII-V5-HLA-A0201- 1 SWYWILVAV 20
9mers-24P4C12 4 WILVAVGQM 18 TableXXIV-V3-HLA-A0203-
Each peptide is a portion of 5 ILVAVGQMM 16 9mers-24P4C12
SEQ ID NO: 11 ; each start 7 VAVGQMMST 13 Pos 1234567890 score position is specified, the length 8 AVGQMMSTM 12 NoResultsFound. of peptide is 9 amino acids, and 6 LVAVGQMMS 10 the end position for eacfj TableXXIV-V5-HLA-A0203- peptide is the start position plus TableXXIII-V8-HLA-A0201- 9mers-24P4C12 eight. 9mers-24P4C12 Pos 1234567890 score Pos 123456789 score NoResultsFound. 5 ILLLVLIFL 28
TableXXIV-V6-HLA-A0203- TableXXV-V1-HLA-A3-9mers- TableXXV-VI -HLA-A3-9mers- 9mers-24P4C12 24P 24P
Pos 1234567890 score Each peptide is a portion of Each peptide is a portion of NoResultsFound. SEQ ID NO: 3; each start SEQ ID NO: 3; each start position is specified, the length position is specified, the length
TableXXIV-V7-HLA-A0203- of peptide is 9 amino acids, and of peptide is 9 amino acids, and
9mers-24P4C12 the end position for each the end position for each
Pos 1234567890 score peptide is the start position plus peptide is the start position plus
NoResultsFound. eight. eight.
Pos 123456789 score Pos 123456789 score
TableXXIV-V8-HLA-A0203- 393 NISSPGCEK 21 457 VLALGQCVL 18
9mers-24P4C12 517 VILEYIDHK 21 564 AIYGKNFCV 18
Pos 1234567890 score 593 KVTDLLLFF 21 587 RV VLDKVT 18
NoResultsFound. 619 SGRIPGLGK 21 649 YVIASGFFS 18
621 RIPGLGKDF 21 10 DEAYGKPVK 17
TableXXIV-V9-HLA-A0203- 44 FILGYIVVG 20 63 QVLYPRNST 17
9mers-24P4C12 56 WLYGDPRQV 20 121 PEDPW GK 17
Pos 1234567890 score 243 SLLFILLLR 20 177 ALGRCFPWT 17
NoResultsFound. 259 LVLILGVLG 20 211 SLNARD1SV 17
347 AVGQMMSTM 20 233 LVALGVALV 17
TableXXV-V1-HLA-A3-9mers- 363 VLLLICIAY 20 235 ALGVALVLS 17
24P 463 CVLAGAFAS 20 239 ALVLSLLFI 17
Each peptide is a portion of 501 SLAFGALIL 20 252 LVAGPLVLV 17
SEQ ID NO: 3; each start 606 WGGVGVLS 20 309 WLAALIVLA 17 position i is specified, the length 689 KSLLKILGK 20 335 RIAIALLKE 17 of peptide is 9 amino acids, and 16 PVKYDPSFR 19 365 LUCIAYWA 17 the end position for each 170 FLLPSAPAL 19 368 CIAYWAMTA 17 peptide i∑ > the start position plus 186 NVTPPALPG 19 401 KVPINISCN 17 eight. 207 GLIDSLNAR 19 421 GLMCVFQGY 17
Pos 123456789 score 246 FILLLRLVA 19 456 WVLALGQCV 17
585 IVRVWLDK 29 249 LLRLVAGPL 19 459 ALGQCVLAG 17
424 CVFQGYSSK 27 260 VLILGVLGV 19 510 TLVQIARVI 17
64 VLYPRNSTG 26 262 ILGVLGVLA 19 542 KCCLWCLEK 17
135 TVGEVFYTK 26 298 NLSAYQSVQ 19 562 MIAIYGKNF 17
251 RLVAGPLVL 26 317 AVLEAILLL 19 580 LLMRNIVRV 17
506 ALILTLVQI 24 333 RIRIAIALL 19 583 RNIVRWVL 17
513 QIARVILEY 24 433 GLIQRSVFN 19 644 SILGAYVIA 17
603 KLLWGGVG 24 508 ILTLVQIAR 19 657 SVFGMCVDT 17
690 SLLKILGKK 24 525 KLRGVQNPV 19 662 CVDTLFLCF 17
267 GVLAYGIYY 23 560 YIMIAIYGK 19 26 PIKNRSCTD 16
282 VLRDKGASI 23 588 WVLDKVTD 19 34 DVICCVLFL 16
312 ALIVLAVLE 23 604 LLWGGVGV 19 45 ILGYIWGI 16
334 IRIAIALLK 23 605 LWGGVGVL - 19 86 LLYFNjFSC 16
102 SVAENGLQC 22 681 LDRPYYMSK 19 157 TVITSLQQE 16
232 ILVALGVAL 22 11 EAYGKPVKY 18 165 ELCPSFLLP 16
247 ILLLRLVAG 22 49 IWGIVAWL 18 237 GVALVLSLL 16
443 QIYGVLGLF 22 73 AYCGMGENK 18 258 VLVLILGVL 16
464 VLAGAFASF 22 220 KIFEDFAQS 18 289 SISQLGFTT 16
516 RVILEYIDH 22 248 LLLRLVAGP 18 304 SVQETWLAA 16
579 MLLMRNIVR 22 261 LILGVLGVL 18 323 LLLMLJFLR 16
50 WGIVAWLY 21 264 GVLGVLAYG 18 364 LLLICJAYW 16
212 LNARDISVK 21 272 GIYYCWEEY 18 470 ASFYWAFHK 16
281 RVLRDKGAS 21 278 EEYRVLRDK 18 494 TLRYHTCSL 16
321 AILLLMLIF 21 314 IVLAVLEAI 18 511 LVQIARVIL 16
338 IALLKEASK 21 432 KGLIQRSVF 18 554 FLNRNAYIM 16
339 ALLKEASKA 21 441 NLQIYGVLG 18 571 CVSAKNAFM 16
376 ALYLATSGQ 21 446 GVLGLFWTL 18 584 NIVRVWLD 16
TableXXV-V1 -HLA-A3-9mers- TableXXV-V1 -HLA-A3-9mers- Each peptide is a portion of SEQ
24P 24P ID NO: 13; each start position is
Each | .eptide is a portion of Each peptide is a portion of specified, the length of peptide is
SEQ ID NO: 3; each start SEQ ID NO: 3; each start 9 amino acids, and the end position is specified, the length position is specified, the length position for each peptide is the of peptide is 9 amino acids, and of peptide is 9 amino acids, and start position plus eight. the end position for each the end position for each Pos 123456789 score peptide i s the start position plus peptide is the start position plus 6 GLIPRSVFN 22 eight. eight. 5 KGLIPRSVF 18
Pos 123456789 score Pos 123456789 score 7 LIPRSVFNL 11
673 DLERNNGSL 16 527 RGVQNPVAR 14
693 KILGKKNEA 16 528 GVQNPVARC 14 TableXXV-V7-HLA-A3-9mers-
698 KNEAPPDNK 16 534 ARCIMCCFK 14 24P4C12
20 DPSFRGPIK 15 558 NAYIMIAIY 14 Each peptide is a portion of
48 YIWGIVAW 15 567 GKNFCVSAK 14 SEQ ID NO: 15; each start
58 YGDPRQVLY 15 596 DLLLFFGKL 14 position is specified, the length
99 NIISVAENG 15 609 GVGVLSFFF 14 of peptide is 9 amino acids, and
151 GVPWNMTVI 15 638 WLPIMTSIL 14 the end position for each
191 ALPGITNDT 15 647 GAYVIASGF 14 peptide is the start position plus
231 ILVALGVA 15 665 TLFLCFLED 14 eight.
234 VALGVALVL 15 685 YYMSKSLLK 14 Pos 123456789 score
257 LVLVLILGV 15 694 ILGKKNEAP 14 8 AVGQMMSTM 20
318 VLEAILLLM 15 699 NEAPPDNKK 14 5 ILVAVGQMM 19
322 ILLLMLIFL 15 701 APPDNKKRK 14 6 LVAVGQMMS 15
327 LIFLRQRIR 15 4 WILVAVGQM 14
329 FLRQRIRIA 15 TableXXV-V3-HLA-A3-9mers- 3 YWILVAVGQ 12
532 PVARCIMCC 15 24P4C12 1 SWΫWILVAV 10
589 WLDKVTDL 15 Each peptide is a portion of
597 LLLFFGKLL 15 SEQ ID NO: 7; each start TableXXV-V8-HLA-A3-9mers-
598 LLFFGKLLV 15 position is specified, the length 24P4C12
622 IPGLGKDFK 15 of peptide is 9 amino acids, and Each peptide is a portion of SEQ
645 ILGAYVIAS 15 the end position for each ID NO: 17; each start position is
651 IASGFFSVF 15 peptide is the start position plus spedfied, the length of peptide is
680 SLDRPYYMS 15 eight. 9 amino acids, and the end
691 LLKILGKKN 15 Pos 123456789 score position for each peptide is the
7 DEDDEAYGK 14 8 NIIPPALPG 17 start position plus eight.
42 LLFILGYIV 14 Pos 123456789 score
53 IVAWLYGDP 14 TableXXV-V5-HLA-A3-9mers- 11 PIIPTGHVF 22
81 KDKPYLLYF 14 24P4C12 6 PIMRNPJTP 16
95 ILSSNIISV 14 Each peptide is a portion of SEQ 4 WLPIMRNPI 12
148 CLPGVP~WNM 14 ID NO: 11; each start position is 9 RNPITPTGH 11
171 LLPSAPALG 14 spedfied, the length of peptide is 1 NYYWLΠMR 10
244 LLFILLLRL 14 9 amino acids, and the end 17 HVFQTSILG 10
311 AALIVLAVL 14 position for each peptide is the
315 VLAVLEAIL 14 start position plus eight.
324 LLMLIFLRQ 14 Pos 123456789 score TableXXV-V9-HLA-A3-9mers-
326 MLIFLRQRI 14 4 AILLLVLIF 21 24P4C12
337 AIAILKEAS 14 8 LVUFLRQR 20 Each peptide is a portion of SEQ
359 LVTFVLLLI 14 5 ILLLVLIFL 16 ID NO: 19; each start position is
370 AYWAMTALY 14 6 LLLVLIFLR 16 specified, the length of peptide is
378 YLATSGQPQ 14 1 VLEAILLLV 15 9 amino acids, and the end
388 VLWASNISS 14 7 LLVLIFLRQ 14 position for each peptide is the
453 TLN VLALG 14 9 VUFLRQRI 14 start position plus eight.
465 LAGAFASFY 14 Pos 123456789 score
487 LISAFIRTL 14 TableXXV-V6-HLA-A3-9mers- 6 ALYPLPJQP 25
496 RYHTGSLAF 14 24P4C12 9 PLPTQPATL 18
523 DHKLRGVQN 14 11 PTQPAJJ-GY 12
16 TLGYVLWAS 12 TableXXVI-V1-HLA-A26- Pos 123456789 score 9mers-24P4C12 7 LIPRSVFNL 16
TableXXVI-V1-HLA-A26- Each peptide is a portion of 5 KGLIPRSVF 9
9mers-24P4C12 SEQ ID NO: 3; each start
Each peptide is a portion of position is specified, the length TableXXVI-V7-HLA-A26-9mers-
SEQ ID NO: 3; each start of peptide is 9 amino acids, and 24P4C12 positioi ι is specified, the length the end position for each Each peptide is a portion of SEQ ID of peptide is 9 amino acids, and peptide is the start position plus NO: 15; each start position is the end position for each eight. specified, the length of peptide is 9 peptide ! is the start position plus Pos 123456789 score amino adds, and the end position eight. 184 WTNVTPPAL 17 for each peptide is the start position
Pos 123456789 score 216 DISVKIFED 17 plus eight.
34 DVICCVLFL 35 261 LILGVLGVL 17 Pos 123456789 score
49 IWGIVAWL 28 358 PLVTFVLLL 17 8 AVGQMMSTM 12
483 PTFPLISAF 28 438 SVFNLQIYG 17 6 LVAVGQMMS 11 .
605 LWGGVGVL 27 442 LQIYGVLGL 17 4 WILVAVGQM 10
593 KVTDLLLFF 26 443 QIYGVLGLF 17 1 SWYWILVAV 8
317 AVLEAILLL 25 487 LISAFIRTL 17 5 ILVAVGQMM 6
592 DKVTDLLLF 25 608 GGVGVLSFF 17 2 WYWILVAVG 5
138 EVFYTKNRN 24 664 DTLFLCFLE 17 7 VAVGQMMST 5
240 LVLSLLFIL 24
589 WLDKVTDL 24 TableXXVI-V3-HLA-A26-9mers- TableXXVI-V8-HLA-A26-9mers-
38 CVLFLLFIL 23 24P4C12 24P4C12
237 GVALVLSLL 23 Each peptide is a portion of SEQ Each peptide is a portion of SEQ ID
11 EAYGKPVKY 22 ID NO: 7; each start position is NO: 17; each start position is
267 GVLAYGIYY 22 specified, the length of peptide is 9 specified, the length of peptide is 9
285 DKGASISQL 22 amino acids, and the end position amino acids, and the end position
452 WTLNWVLAL 22 for each peptide is the start for each peptide is the start position
50 WGIVAWLY 20 position plus eight. plus eight.
79 ENKDKPYLL 20 Pos 123456789 score Pos 123456789 score
157 TVITSLQQE 20 6 WTNITPPAL 17 19 FQTSILGAY 20
263 LGVLGVLAY 20 9 ITPPALPGI 13 11 PITPTGHVF 15
446 GVLGLF TL 20 17 HVFQTSILG 15
628 DFKSPHLNY 20 TableXXVI-V5-HLA-A26-9mers- 16 GHVFQTSIL 13
641 IMTSILGAY 20 24P4C12 20 QTSILGAYV 10
662 CVDTLFLCF 20 Each peptide is a portion of SEQ 14 PTGHVFQTS 9
236 LGVALVLSL 19 ID NO: 11; each start position is
258 VLVLILGVL 19 specified, the length of peptide is TableXXVI-V9-HLA-A26-9mers-
307 ETWLAAUV 19 9 amino acids, and the end 24P4C12
320 EAILLLMLI 19 position for each peptide is the Each peptide is a portion of SEQ
414 LVNSSCPGL 19 start position plus eight. ID NO: 19; each start position is
437 RSVFNLQIY 19 scor specified, the length of peptide is 9
Pos 123456789
513 QIARVILEY 19 amino acids, and the end position
609 GVGVLSFFF 19 3 EAILLLVU 19 for each peptide is the start
673 DLERNNGSL 19 4 AILLLVLIF 18 position plus eight.
32 CTDVICCVL 18 8 LVUFLRQR 15 Pos 123456789 score
198 DTTIQQGIS 18 2 LEAILLLVL 14 11 PTQPATLGY 20
200 TIQQGISGL 18 5 ILLLVLIFL 13 15 ATLGYVLWA 13
204 GISGLIDSL 18 2 WA TALYPL 12
244 LLFILLLRL 18 TableXXVI-V6-HLA-A26-9mers- 13 QPATLGYVL 10
294 GFTTNLSAY 18 24P4C12 4 MTALYPLPT 9
354 TMFYPLVTF 18 Each peptide is a portion of SEQ ID 9 PLPTQPATL 9
360 VTFVLLLIC 18 NO: 13; each start position is
400 EKVPINTSC 18 specified, the length of peptide is 9 TableXXVII-V1 -HLA-B0702-
511 LVQIARVIL 18 amino acids, and the end position for 9mers-24P4C12
596 DLLLFFGKL 18 each peptide is the start position
102 SVAENGLQC 17 plus eight.
Each peptide is a portion of SEQ TableXXVII-V1-HLA-B0702- TableXXVII-V1-HLA-B0702-
ID NO: 3; each start position is 9mers-24P4C12 9mers-24P4C12 specified, the length of peptide is 9 Each peptide is a portion of SEQ Each peptide is a portion of SEQ amino acids, and the end position ID NO: 3; each start position is ID NO: 3; each start position is for each peptide is the start specified, the length of peptide is 9 spedfied, the length of peptide is 9 position plus eight. amino acids, and the end position amino acids, and the end position
Pos 123456789 score for each peptide is the start for each peptide is the start
255 GPLVLVLIL 23 position plus eight. position plus eight.
357 YPLVTFVLL 23 Pos 123456789 score Pos 123456789 score
683 RPYYMSKSL 21 170 FLLPSAPAL 13 104 AENGLQCPT 11
149 LPGVPWNMT 20 182 FPWTNVTPP 13 107 GLQCPTPQV 11
396 SPGCEKVPI 20 228 SWYWILVAL 13 109 QCPTPQVCV 11
482 IPTFPLISA 20 241 VLSLLFILL 13 112 TPQVCVSSC 11
631 SPHLNYYWL 20 249 LLRLVAGPL 13 123 DPWTVGKNE 11
15 KPVKYDPSF 19 261 LILGVLGVL 13 163 QQELCPSFL 11
152 VPWNMTVIT 19 302 YQSVQETWL 13 169 SFLLPSAPA 11
167 CPSFLLPSA 19 319 LEAILLLML 13 177 ALGRCFPWT 11
25 GPIKNRSCT 18 358 PLVTFVLLL 13 191 ALPGITNDT 11
172 LPSAPALGR 18 369 IAYWAMTAL 13 237 GVALVLSLL 11
83 KPYLLYFNI 17 371 YWAMTALYL 13 239 ALVLSLLFI 11
188 TPPALPGIT 17 409 NPTAHLVNS 13 258 VLVLILGVL 11 192 LPGITNDTT 17 442 LQIYGVLGL 13 262 ILGVLGVLA 11 57 LYGDPRQVL 16 446 GVLGLFWTL 13 275 YC EEYRVL 11 232 ILVALGVAL 16 478 KPQDIPTFP 13 310 L-AALIVLAV 11 253 VAGPLVLVL 16 487 LISAFIRTL 13 332 QRIRIAIAL 11 479 PQDIPTFPL 16 494 TLRYHTGSL 13 343 EASKAVGQM 11 503 AFGALILTL 16 501 SLAFGALIL 13 354 TMFYPLVTF 11 49 IWGIVAWL 15 511 LVQIARVIL 13 384 QPQYVL AS 11 120 CPEDPWTVG 15 590 VLDKVTDLL 13 414 LVNSSCPGL 11 175 APALGRCFP 15 622 IPGLGKDFK 13 426 FQGYSSKGL 11
189 PPALPGITN 15 651 IASGFFSVF 13 434 LIQRSVFNL 11 234 VALGVALVL 15 32 CTDVICCVL 12 440 FNLQIYGVL 11
251 RLVAGPLVL 15 78 GENKDKPYL 12 450 LFWTLN VL 11 381 TSGQPQYVL 15 154 WNMTVITSL 12 464 VLAGAFASF 11 406 TSCNPTAHL 15 184 WTNVTPPAL 12 518 ILEYIDHKL 11 583 RNIVRVWL 15 242 LSLLFILLL 12 531 NPVARCIMC 11 617 FFSGRIPGL 15 244 LLFILLLRL 12 537 IMCCFKCCL 11
20 DPSFRGPIK 14 285 DKGASISQL 12 571 CVSAKNAFM 11
34 DVICCVLFL 14 305 VQETWLAAL 12 573 SAKNAFMLL 11
66 YPRNSTGAY 14 308 TWLAAUVL 12 574 AKNAFMLLM 11
204 GISGLIDSL 14 315 VLAVLEAIL 12 596 DLLLFFGKL 11
236 LGVALVLSL 14 322 ILLLMLIFL 12 597 LLLFFGKLL 11
252 LVAGPLVLV 14 356 FYPLVTFVL 12 599 LFFGKLLW 11 291 SQLGFTTNL 14 373 AMTALYLAT 12 638 WLPIMTSIL 11 311 AALIVLAVL 14 380 ATSGQPQYV 12 663 VDTLFLCFL 11 317 AVLEAILLL 14 457 VLALGQCVL 12 686 YMSKSLLKI 11 333 RIRIAIALL 14 525 KLRGVQNPV 12 702 PPDNKKRKK 11 351 MMSTMFYPL 14 547 CLEKFIKFL 12 419 CPGLMCVFQ 14 572 VSAKNAFML 12 TableXXVII-V3-HLA-B0702- 452 WTLNWVLAL 14 589 WLDKVTDL 12 9mers-24P4C12 499 TGSLAFGAL 14 591 LDKVTDLLL 12 Each peptide is a portion of SEQ ID 605 LWGGVGVL 14 626 GKDFKSPHL 12 NO: 7; each start position is 660 GMCVDTLFL 14 658 VFGMCVDTL 12 spedfied, the length of peptide is 9 60 DPRQVLYPR 13 701 APPDNKKRK 12 amino acids, and the end position 100 IISVAENGL 13 28 KNRSCTDVI 11 for each peptide is the start position 110 CPTPQVCVS 13 45 ILGYIWGI 11 plus eight. 164 QELCPSFLL 13 79 ENKDKPYLL 11 Pos 123456789 score
TableXXVII-V3-HLA-B0702- e TableXXVIII-V1 -HLA-B08-9mers 9mers-24P4C12 1 SWYWILVAV 9 Each peptide is a portion of SEQ
Each peptide is a portion of SEQ ID 5 ILVAVGQMM 9 ID NO: 3; each start position is
NO: 7; each start position is 8 AVGQMMSTM 9 specified, the length of peptide is 9 specified, the length of peptide is 9 7 VAVGQMMST 8 amino acids, and the end position amino acids, and the end position 4 WILVAVGQM 7 for each peptide is the start for each peptide is the start position position plus eight. plus eight. TableXXVII-V8-HLA-B0702-9mers- Pos 123456789 score Pos 123456789 score 24P4C12 589 WLDKVTDL 22
4 FPWTNITPP 12 Each peptide is a portion of SEQ ID 333 RIRIAIALL 21 6 TNITPPAL 12 NO: 17; each start position is 583 RNIVRVWL 21
1 GRCFPWTNI 10 specified, the length of peptide is 9 591 LDKVTDLLL 21
2 RCFPWTNIT 9 amino acids, and the end position 626 GKDFKSPHL 21
5 PWTNITPPA 9 for each peptide is the start position 687 MSKSLLKIL 21 9 ITPPALPGI 9 plus eight. 340 LLKEASKAV 20 8 NITPPALPG 7 Pos 123456789 score 474 WAFHKPQDI 20
19 FQTSILGAY 20 523 DHKLRGVQN 20
TableXXVII-V5-HLA-B0702- 11 PITPTGHVF 15 540 CFKCCLWCL 20 9mers-24P4C12 17 HVFQTSILG 15 617 FFSGRIPGL 20
Each peptide is a portion of SEQ ID 16 GHVFQTSIL 13 2 GGKQRDEDD 19
NO: 11 ; each start position is 20 QTSILGAYV 10 232 ILVALGVAL 19 specified, the length of peptide is 9 14 PTGHVFQTS 9 255 GPLVLVLIL 19 amino acids, and the end position, 631 SPHLNYYWL 19 for each peptide is the start position 694 ILGKKNEAP 19 plus eight. TableXXVII-V9-HLA-B0702-9mers- 139 VFYTKNRNF 18
Pos 123456789 score 24P4C12 170 FLLPSAPAL 18
2 LEAILLLVL 14 Each peptide is a portion of SEQ ID 241 VLSLLFILL 18 5 ILLLVLIFL 12 NO: 19; each start position is 247 ILLLRLVAG 18
4 AILLLVLIF 11 specified, ttie length of peptide is 9 258 VLVLILGVL 18 1 VLEAILLLV 9 amino acids, and the end position 315 VLAVLEAIL 18
3 EAILLLVLI 9 for each peptide is the start position 322 ILLLMLIFL 18 9 VLIFLRQRI 7 plus eight. 357 YPLVTFVLL 18 Pos 123456789 score 457 VLALGQCVL 18
TableXXVII-V6-HLA-B0702- 13 QPATLGYVL 23 501 SLAFGALIL 18 9mers-24P4C12 8 YPLPTQPAT 19 514 IARVILEYI 18
Each peptide is a portion of SEQ ID 10 LPTQPATLG 14 518 ILEYIDHKL 18
NO: 13; each start position is 15 ATLGYVLWA 13 546 WCLEKFIKF 18 specified, the length of peptide is 9 2 WAMTALYPL 12 547 CLEKFIKFL 18 amino acids, and the end position 7 LYPLPTQPA 11 683 RPYYMSKSL 18 for each peptide is the start position 9 PLPTQPATL 11 11 EAYGKPVKY 17 plus eight. 213 NARDISVKI 17
Pos 123456789 score TableXXVIII-V1 -HLA-B08-9mers 216 DISVKIFED 17
8 IPRSVFNLQ 14 Each peptide is a portion of SEQ 358 PLVTFVLLL 17
5 KGLIPRSVF 12 ID NO: 3; each start position is 533 VARCIMCCF 17 7 UPRSVFNL 11 specified, the length of peptide is 9 590 VLDKVTDLL 17
9 PRSVFNLQI 10 amino adds, and the end position 596 DLLLFFGKL 17
4 SKGLIPRSV 7 for each peptide is the start 597 LLLFFGKLL 17 position plus eight. 673 DLERNNGSL 17
TableXXVII-V7-HLA-B0702- Pos 123456789 score 691 LLKILGKKN 17 9mers-24P4C12 79 ENKDKPYLL 32 45 ILGYIWGI 16
Each peptide is a portion of SEQ ID 141 YTKNRNFCL 29 64 VLYPRNSTG 16
NO: 15; each start position is 282 VLRDKGASI 29 81 KDKPYLLYF 16 specified, the length of peptide is 9 573 SAKNAFMLL 26 100 IISVAENGL 16 amino acids, and the end position 249 LLRLVAGPL 23 158 VITSLQQEL 16 for each peptide is the start position 494 TLRYHTGSL 23 204 GISGLIDSL 16 plus eight. 26 PIKNRSCTD 22 211 SLNARDISV 16
Pos 123456789 scor 329 FLRQRIRIA 22 244 LLFILLLRL 16
TableXXVIII-V1-HLA-B08-9mers TableXXVIII-V5-B08-9mers- TableXXVIII-V8-HLA-B08-9mers-
Each peptide is a portion of SEQ 24P4C12 24P4C12
ID NO: 3; each start position is Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ specified, the length of peptide is 9 NO: 11 ; each start position is ID NO: 17; each start position is amino acids, and the end position specified, the length of peptide is 9 specified, the length of peptide is 9 for each peptide is the start amino acids, and the end position amino acids, and the end position position plus eight. for each peptide is the start position for each peptide is the start
Pos 123456789 score plus eight. position plus eight.
251 RLVAGPLVL 16 Pos 123456789 score Pos 123456789 score
253 VAGPLVLVL 16 2 LEAILLLVL 10 15 TGHVFQTSI 7
338 IALLKEASK 16 6 LLLVLIFLR 8
369 IAYWAMTAL 16 TableXXVIII-V9-HLA-B08-
433 GLIQRSVFN 16 TableXXVIII-V6-HLA-B08-9mers- 9mers-24P4C12
551 FIKFLNRNA 16 24P4C12 Each peptide is a portion of SEQ
638 WLPIMTSIL 16 Each peptide is a portion of SEQ ID NO: 19; each start position is
702 PPDNKKRKK 16 ID NO: 13; each start position is specified, the length of peptide is
35 VICCVLFLL 15 specified, the length of peptide is 9 9 amino acids, and the end
200 TIQQGISGL 15 amino acids, and the end position position for each peptide is the
225 FAQSWYWIL 15 for each peptide is the start start position plus eight.
234 VALGVALVL 15 position plus eight Pos 123456789 score
316 LAVLEAILL 15 Pos 123456789 score 9 PLPTQPATL 16
331 RQRIRIAIA 15 6 GLIPRSVFN 16 13 QPATLGYVL 16
396 SPGCEKVPI 15 7 LIPRSVFNL 15 2 WAMTALYPL 14
434 LIQRSVFNL 15 3 SSKGLIPRS 13 16 TLGYVLWAS 8
487 LISAFIRTL 15 8 IPRSVFNLQ 13 18 GYVLWASNI 8
553 KFLNRNAYI 15 1 GYSSKGLIP 11 8 YPLPTQPAT 7
564 AIYGKNFCV 15 9 PRSVFNLQI 8
579 MLLMRNIVR 15 TableXXIX-V1-HLA-B1510-9mers-
693 KILGKKNEA 15 TableXXVIII-V7-HLA-B08-9mers- 24P4C12 24P4C12 Each peptide is a portion of SEQ ID
TableXXVIII-V3-HLA-B08-9mers- Each peptide is a portion of SEQ NO: 3; each start position is 24P4C12 ID NO: 15; each start position is specified, the length of peptide is 9
Each peptide is a portion of SEQ specified, the length of peptide is 9 amino acids, and the end position ID NO: 7; each start position is amino acids, and the end position for each peptide is the start position specified, the length of peptide is 9 for each peptide is the start plus eight. amino acids, and the end position position plus eight. Pos 123456789 score for each peptide is the start Pos 123456789 score 275 YCWEEYRVL 16 position plus eight. 5 ILVAVGQMM 7 583 RNIVRVWL 16
Pos 123456789 score 4 WILVAVGQM 6 57 LYGDPRQVL 15 6 TNITPPAL 11 7 VAVGQMMST 5 232 ILVALGVAL 15
4 FPWTNITPP 8 1 SWYWILVAV 4 253 VAGPLVLVL 15
1 GRCFPWTNI 7 381 TSGQPQYVL 15
9 ITPPALPGI 7 TableXXVIII-V8-HLA-B08-9mers- 487 LISAFIRTL 15 24P4C12 605 LWGGVGVL 15
TableXXVIII-V5-B08-9mers- Each peptide is a portion of SEQ 49 IWGIVAWL 14 24P4C12 ID NO: 17; each start position is 78 GENKDKPYL 14
Each peptide is a portion of SEQ ID specified, the length of peptide is 9 100 IISVAENGL 14
NO: 11 ; each start position is amino acids, and the end position 170 FLLPSAPAL 14 specified, the length of peptide is 9 for each peptide is the start 184 WTNVTPPAL 14 amino acids, and the end position position plus eight. 200 TIQQGISGL 14 for each peptide is the start position Pos 123456789 score 204 GISGLIDSL 14 plus eight. 5 LPIMRNPIT 15 251 RLVAGPLVL 14
Pos 123456789 score 4 WLPIMRNPI 12 357 YPLVTFVLL 14
5 ILLLVLIFL 18 16 GHVFQTSIL 11 369 IAYWAMTAL 14
3 EAILLLVLI 14 11 PITPTGHVF 10 457 VLALGQCVL 14 9 VLIFLRQRI 13 7 IMRNPITPT 8 617 FFSGRIPGL 14
4 AILLLVLIF 12 13 TPTGHVFQT 7 32 CTDVICCVL 13
TableXXIX-V1-HLA-B1510-9mers- TableXXIX-V1 -HLA-B1510-9mers- TableXXIX-V1-HLA-B1510-9mers-
24P4C12 24P4C12 24P4C12
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID
NO: 3; each start position is NO: 3; each start position is NO: 3; each start position is specified, the length of peptide is 9 specified, the length of peptide is 9 specified, the length of peptide is 9 amino acids, and the end position amino acids, and the end position amino adds, and the end position for each peptide is the start position for each peptide is the start position for each peptide is the start position plus eight. plus eight. plus eight.
Pos 123456789 score Pos 123456789 score Pos 123456789 score
79 ENKDKPYLL 13 236 LGVALVLSL 11 679 GSLDRPYYM 9
228 SWYWILVAL 13 241 VLSLLFILL 11 15 KPVKYDPSF 8
234 VALGVALVL 13 242 LSLLFILLL 11 81 KDKPYLLYF 8
255 GPLVLVLIL 13 285 DKGASISQL 11 132 FSQTVGEVF 8
261 LILGVLGVL 13 291 SQLGFTTNL 11 139 VFYTKNRNF 8
302 YQSVQETWL 13 319 LEAILLLML 11 148 CLPGVPWNM 8
308 TWLAALIVL 13 332 QRIRIAIAL 11 162 LQQELCPSF 8
440 FNLQIYGVL 13 333 RIRIAIALL 11 174 SAPALGRCF 8
446 GVLGLFWTL 13 351 MMSTMFYPL 11 287 GASISQLGF 8
499 TGSLAFGAL 13 354 TMFYPLVTF 11 415 VNSSCPGLM 8
511 LVQIARVIL 13 358 PLVTFVLLL 11 464 VLAGAFASF 8
518 ILEYIDHKL 13 414 LVNSSCPGL 11 468 AFASFYWAF 8
537 IMCCFKCCL 13 434 LIQRSVFNL 11 496 RYHTGSLAF 8
547 CLEKFIKFL 13 479 PQDIPTFPL 11 530 QNPVARCIM 8
572 VSAKNAFML 13 494 TLRYHTGSL 11 570 FCVSAKNAF 8
163 QQELCPSFL 12 590 VLDKVTDLL 11 608 GGVGVLSFF 8
237 GVALVLSLL 12 591 LDKVTDLLL 11 609 GVGVLSFFF 8
244 LLFILLLRL 12 631 SPHLNYYWL 11 647 GAYVIASGF 8
258 VLVLILGVL 12 684 PYYMSKSLL 11 48 YIWGIVAW 7
305 VQETWLAAL 12 35 VICCVLFLL 10 69 NSTGAYCGM 7
311 AALIVLAVL 12 38 CVLFLLFIL 10 214 ARDISVKIF 7
315 VLAVLEAIL 12 124 PWTVGKNEF 10 238 VALVLSLLF 7
317 AVLEAILLL 12 225 FAQSWYWIL 10 318 VLEAILLLM 7
322 ILLLMLIFL 12 240 LVLSLLFIL 10 321 AILLLMLIF 7
356 FYPLVTFVL 12 249 LLRLVAGPL 10 366 LICIAYWAM 7
371 YWAMTALYL 12 316 LAVLEAILL 10 443 QIYGVLGLF 7
406 TSCNPTAHL 12 343 EASKAVGQM 10 533 VARCIMCCF 7
412 AHLVNSSCP 12 418 SCPGLMCVF 10 546 WCLEKFIKF 7
442 LQIYGVLGL 12 426 FQGYSSKGL 10 554 FLNRNAYIM 7
450 LFWTLNWVL 12 477 HKPQDIPTF 10 562 MIAIYGKNF 7
452 WTLNWVLAL 12 483 PTFPLISAF 10 571 CVSAKNAFM 7
476 FHKPQDIPT 12 540 CFKCCLWCL 10 574 AKNAFMLLM 7
497 YHTGSLAFG 12 573 SAKNAFMLL 10 593 VTDLLLFF 7
501 SLAFGALIL 12 596 DLLLFFGKL 10 621 RIPGLGKDF 7
503 AFGALILTL 12 597 LLLFFGKLL 10 634 LNYYWLPIM 7
523 DHKLRGVQN 12 632 PHLNYYWLP 10 653 SGFFSVFGM 7
589 WLDKVTDL 12 638 WLPIMTSIL 10
626 GKDFKSPHL 12 663 VDTLFLCFL 10 TableXXIX-V3-HLA-B1510-9mers-
651 IASGFFSVF 12 666 LFLCFLEDL 10 24P4C12
658 VFGMCVDTL 12 683 RPYYMSKSL 10 Each peptide is a portion of SEQ ID
660 GMCVDTLFL 12 687 MSKSLLKIL 10 NO: 7; each start position is
673 DLERNNGSL 12 33 TDVICCVLF 9 specified, the length of peptide is 9
34 DVICCVLFL 11 36 ICCVLFLLF 9 amino acids, and the end position
88 YFNIFSCIL 11 217 ISVKIFEDF 9 for each peptide is the start position
141 YTKNRNFCL 11 347 AVGQMMSTM 9 plus eight.
154 WNMTVITSL 11 432 KGLIQRSVF 9 Pos 123456789 score
158 VITSLQQEL 11 461 GQCVLAGAF 9 6 WTNITPPAL 13
164 QELCPSFLL 11 607 VGGVGVLSF 9
TableXXIX-V5-B1510-9mers- TableXXIX-V9-B1510-9mers-24P4C12 TableXXX-V1-HLA-B2705-9mers- 24P4C12 Each peptide is a portion of SEQ ID NO: 24P4C12
Each peptide is a portion of SEQ 19; each start position is specified, the Each peptide is a portion of SEQ ID
ID NO: 11; each start position is length of peptide is 9 amino acids, and NO: 3; each start position is specified, the length of peptide is 9 the end position for each peptide is the specified, the length of peptide is 9 amino acids, and the end position start position plus eight. amino acids, and the end position for each peptide is the start Pos 123456789 score for each peptide is the start position position plus eight. 13 QPATLGYVL 13 plus eight.
Pos 123456789 score 9 PLPTQPATL 12 Pos 123456789 score
2 LEAILLLVL 13 2 WAMTALYPL 10 237 GVALVLSLL 17
5 ILLLVLIFL 12 242 LSLLFILLL 17
TableXXX-V1 -HLA-B2705-9mers- 261 LILGVLGVL 17
TableXXIX-V6-B1510-9mers- 24P4C12 287 GASISQLGF 17
24P4C12 Each peptide is a portion of SEQ ID 311 AALIVLAVL 17
Each peptide is a portion of SEQ ID NO: 3; each start position is 338 IALLKEASK 17
NO: 13; each start position is specified, the length of peptide is 9 354 TMFYPLVTF 17 specified, the length of peptide is 9 amino acids, and the end position 381 TSGQPQYVL 17 amino acids, and the end position for for eacr i peptide is the start position 429 YSSKGLIQR 17 each peptide is the start position plus plus eight. 477 HKPQDIPTF 17 eight. Pos 123456789 score 503 AFGALILTL 17
Pos 123456789 score 334 IRIAIALLK 26 516 RVILEYIDH 17
7 LIPRSVFNL 11 332 QRIRIAIAL 25 546 WCLEKFIKF 17
5 KGLIPRSVF 10 675 ERNNGSLDR 24 549 EKFIKFLNR 17
3 SSKGLIPRS 5 214 ARDISVKIF 23 605 LWGGVGVL 17
6 GLIPRSVFN 5 534 ARCIMCCFK 21 621 RIPGLGKDF 17
620 GRIPGLGKD 21 11 EAYGKPVKY 16
TableXXIX-V7-B1510-9mers- 5 QRDEDDEAY 20 23 FRGPIKNRS 16
24P4C12 204 GISGLIDSL 20 137 GEVFYTKNR 16
Each peptide is a portion of SEQ ID 446 GVLGLFWTL 20 139 VFYTKNRNF 16 O: 15; each start position is specified, 689 KSLLKILGK 20 170 FLLPSAPAL 16 the length of peptide is 9 amino acids, 251 RLVAGPLVL 19 283 LRDKGASIS 16 and the end position for each peptide 424 CVFQGYSSK 19 285 DKGASISQL 16 is the start position plus eight. 436 QRSVFNLQI 19 321 AILLLMLIF 16
Pos 123456789 score 483 PTFPLISAF 19 322 ILLLMLIFL 16
8 AVGQMMSTM 9 583 RNIVRVWL 19 323 LLLMLIFLR 16
4 WILVAVGQM 8 608 GGVGVLSFF 19 327 LIFLRQRIR 16
5 ILVAVGQMM 8 15 KPVKYDPSF 18 432 KGLIQRSVF 16
1 SWYWILVAV 3 22 SFRGPIKNR 18 440 FNLQIYGVL 16
2 WYWILVAVG 3 179 GRCFPWTNV 18 442 LQIYGVLGL 16
3 YWILVAVGQ 3 200 TIQQGISGL 18 443 QIYGVLGLF 16
6 LVAVGQMMS 3 207 GLIDSLNAR 18 457 VLALGQCVL 16
234 VALGVALVL 18 508 ILTLVQIAR 16
TableXXIX-V8-B1510-9mers- 244 LLFILLLRL 18 517 VILEYIDHK 16
24P4C12 255 GPLVLVLIL 18 589 WLDKVTDL 16
Each peptide is a portion of SEQ ID 291 SQLGFTTNL 18 617 FFSGRIPGL 16
NO: 17; each start position is 317 AVLEAILLL 18 626 GKDFKSPHL 16 specified, the length of peptide is 9 330 LRQRIRIAI 18 699 NEAPPDNKK 16 amino acids, and the end position 333 - RIRIAIALL 18 10 DEAYGKPVK 15 for each peptide is the start position 496 RYHTGSLAF 18 40 LFLLFILGY 15 plus eight. 527 RGVQNPVAR 18 60 DPRQVLYPR 15
Pos 123456789 score 647 GAYVIASGF 18 73 AYCGMGENK 15
16 GHVFQTSIL 21 668 LCFLEDLER 18 81 KDKPYLLYF 15
11 PITPTGHVF 10 683 RPYYMSKSL 18 124 PWTVGKNEF 15
13 QPATLGYVL 13 690 SLLKILGKK 18 212 LNARDISVK 15
9 PLPTQPATL 12 49 IWGIVAWL 17 217 ISVKIFEDF 15
2 WAMTALYPL 10 78 GENKDKPYL 17 228 SWYWILVAL 15
154 WNMTVITSL 17 236 LGVALVLSL 15
TableXXX-VI -HLA-B2705-9mers- TableXXX-V1-HLA-B2705-9mers- TableXXX-V1 -HLA-B2705-9mers-
24P4C12 24P4C12 24P4C12
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID
NO: 3, each start position is NO: 3; each start position is NO: 3; each start position is specified, the length of peptide is 9 specified, the length of peptide is 9 specified, the length of peptide is 9 amino acids, and the end position amino acids, and the end position amino adds, and the end position for each peptide is the start position for each peptide is the start position for each peptide is the start position plus eight. plus eight. plus eight.
Pos 123456789 score Pos 123456789 score Pos 123456789 score
238 VALVLSLLF 15 464 VLAGAFASF 14 582 MRNIVRVW 13
243 SLLFILLLR 15 485 FPLISAFIR 14 590 VLDKVTDLL 13
253 VAGPLVLVL 15 487 LISAFIRTL 14 592 DKVTDLLLF 13
258 VLVLILGVL 15 488 ISAFIRTLR 14 610 VGVLSFFFF 13
308 TWLAALIVL 15 489 SAFIRTLRY 14 637 YWLPIMTSI 13
316 LAVLEAILL 15 501 SLAFGALIL 14 648 AYVIASGFF 13
369 IAYWAMTAL 15 513 QIARVILEY 14 653 SGFFSVFGM 13
461 GQCVLAGAF 15 515 ARVILEYID 14 666 LFLCFLEDL 13
470 ASFYWAFHK 15 552 IKFLNRNAY 14 681 LDRPYYMSK 13
518 ILEYIDHKL 15 556 NRNAYIMIA 14 682 DRPYYMSKS 13
542 KCCLWCLEK 15 558 NAYIMIAIY 14 685 YYMSKSLLK 13
543 CCLWCLEKF 15 560 YIMIAIYGK 14 686 YMSKSLLKI 13
547 CLEKFIKFL 15 575 KNAFMLLMR 14 29 NRSCTDVIC 12
567 GKNFCVSAK 15 585 IVRVWLDK 14 32 CTDVICCVL 12
579 MLLMRNIVR 15 595 TDLLLFFGK 14 33 TDVICCVLF 12
586 VRWVLDKV 15 613 LSFFFFSGR 14 35 VICCVLFLL 12
593 KVTDLLLFF 15 643 TSILGAYVI 14 57 LYGDPRQVL 12
596 DLLLFFGKL 15 659 FGMCVDTLF 14 58 YGDPRQVLY 12
607 VGGVGVLSF 15 660 GMCVDTLFL 14 79 ENKDKPYLL 12
609 GVGVLSFFF 15 679 GSLDRPYYM 14 80 NKDKPYLLY 12
622 IPGLGKDFK 15 700 EAPPDNKKR 14 93 SCILSSNII 12
651 IASGFFSVF 15 701 APPDNKKRK 14 100 IISVAENGL 12
684 PYYMSKSLL 15 702 PPDNKKRKK 14 121 PEDPWTVGK 12
698 KNEAPPDNK 15 7 DEDDEAYGK 13 132 FSQTVGEVF 12
34 DVICCVLFL 14 36 ICCVLFLLF 13 144 NRNFCLPGV 12
38 CVLFLLFIL 14 172 LPSAPALGR 13 151 GVPWNMTVI 12
61 PRQVLYPRN 14 241 VLSLLFILL 13 163 QQELCPSFL 12
75 CGMGENKDK 14 249 LLRLVAGPL 13 190 PALPGITND 12
83 KPYLLYFNI 14 250 LRLVAGPLV 13 193 PGITNDTTI 12
84 PYLLYFNIF 14 273 IYYCWEEYR 13 239 ALVLSLLFI 12
135 TVGEVFYTK 14 275 YCWEEYRVL 13 276 CWEEYRVLR 12
148 CLPGVPWNM 14 280 YRVLRDKGA 13 302 YQSVQETWL 12
158 VITSLQQEL 14 294 GFTTNLSAY 13 305 VQETWLAAL 12
162 LQQELCPSF 14 319 LEAILLLML 13 315 VLAVLEAIL 12
164 QELCPSFLL 14 347 AVGQMMSTM 13 320 EAILLLMLI 12
232 ILVALGVAL 14 348 VGQMMSTMF 13 328 IFLRQRIRI 12
240 LVLSLLFIL 14 349 GQMMSTMFY 13 343 EASKAVGQM 12
263 LGVLGVLAY 14 356 FYPLVTFVL 13 371 YWAMTALYL 12
267 GVLAYGIYY 14 357 YPLVTFVLL 13 386 QYVLWASNI 12
272 GIYYCWEEY 14 358 PLVTFVLLL 13 393 NISSPGCEK 12
278 EEYRVLRDK 14 363 VLLLICIAY 13 406 TSCNPTAHL 12
325 LMLIFLRQR 14 492 IRTLRYHTG 13 414 LVNSSCPGL 12
379 LATSGQPQY 14 495 LRYHTGSLA 13 421 GLMCVFQGY 12
418 SCPGLMCVF 14 506 ALILTLVQI 13 426 FQGYSSKGL 12
434 LIQRSVFNL 14 526 LRGVQNPVA 13 468 AFASFYWAF 12
437 RSVFNLQIY 14 545 LWCLEKFIK 13 490 AFIRTLRYH 12
450 LFWTLNWVL 14 570 FCVSAKNAF 13 500 GSLAFGALI 12
452 WTLNWVLAL 14 572 VSAKNAFML 13 510 TLVQIARVI 12
TableXXX-V1-HLA-B27( )5-9mers- TableXXX-V6-HLA-B2705-9mers- Each peptide is a portion of SEQ
24P4C12 24P4C12 ID NO. 19, each start position is
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ specified, the length of peptide is 9
NO. 3, each start position is ID NO. 13; each start position is amino acids, and the end position specified, the length of peptide is 9 specified, the length of peptide is 9 for each peptide is the start am o i acids, and the end position ammo acids, and the end position position plus eight. for each peptide is the start position for each peptide is the start Pos 123456789 score plus eight. position plus eight 18 GYVLWASNI 15
Pos 123456789 score Pos 123456789 score 13 QPATLGYVL 13
519 LEYIDHKLR 12 9 PRSVFNLQI 19 2 WAMTALYPL 12
537 IMCCFKCCL 12 5 KGLIPRSVF 17 9 PLPTQPATL 12
540 CFKCCLWCL 12 2 YSSKGLIPR 16 11 PTQPATLGY 10
553 KFLNRNAYI 12 7 LIPRSVFNL 14 6 ALYPLPTQP 8
557 RNAYIMIAI 12 3 SSKGLIPRS 9 15 ATLGYVLWA 7
562 MIAIYGKNF 12
591 LDKVTDLLL 12 TableXXX-V7-HLA-B2705- TableXXXI-V1-HLA-B2709-
597 LLLFFGKLL 12 9mers-24P4C12 9merse-24P4C12
614 SFFFFSGRI 12 Each peptide is a portion of SEQ Each peptide is a portion of SEQ
619 SGRIPGLGK 12 ID NO: 15; each start position is ID NO: 3; each start position is
628 DFKSPHLNY 12 specified, the length of peptide is specified, the length of peptide is
631 SPHLNYYWL 12 9 amino acids, and the end 9 amino acids, and the end
634 LNYYWLPIM 12 position for each peptide is the position for each peptide is the
658 VFGMCVDTL 12 start position plus eight. start position plus eight.
662 CVDTLFLCF 12 Pos 123456789 score Pos 123456789 score
663 VDTLFLCFL 12 8 AVGQMMSTM 13 332 QRIRIAIAL 23
673 DLERNNGSL 12 4 WILVAVGQM 12 179 GRCFPWTNV 22
687 MSKSLLKIL 12 5 ILVAVGQMM 11 250 LRLVAGPLV 21
3 YWILVAVGQ 6 214 ARDISVKIF 20
TableXXX-V3-HLA-B2705-9mers- 436 QRSVFNLQI 20 24P4C12 TableXXX-V8-HLA-B2705-9mers- 144 NRNFCLPGV 19
Each peptide is a portion of SEQ ID 24P4C12 330 LRQRIRIAI 19
NO: 7; each start position is Each peptide is a portion of SEQ ID 582 MRNIVRVW 19 specified, the length of peptide is 9 NO: 17, each start position is 586 VRVWLDKV 19 ammo acids, and the end position for specified, the length of peptide is 9 255 GPLVLVLIL 17 each peptide is the start position plus amino ; acids, and the end position 583 RNIVRVWL 17 eight. for each peptide is the start position 251 RLVAGPLVL 16
Pos 123456789 score plus eight. 683 RPYYMSKSL 16
1 GRCFPWTNI 24 Pos 123456789 score 78 GENKDKPYL 15 6 WTNITPPAL 11 16 GHVFQTSIL 15 170 FLLPSAPAL 15
1 NYYWLPIMR 14 334 IRIAIALLK 15
TableXXX-V5-HLA-B2705-9mers- 8 MRNPITPTG 14 446 GVLGLFWTL 15 24P4C12 9 RNPITPTGH 14 620 GRIPGLGKD 15
Each peptide is a portion of SEQ ID 11 PITPTGHVF 12 647 GAYVIASGF 15
NO: 11, each start position is 15 TGHVFQTSI 11 660 GMCVDTLFL 15 specified, the lengtii of peptide is 9 19 FQTSILGAY 10 49 IWGIVAWL 14 amino acids, and the end position 2 YYWLPIMRN 8 228 SWYWILVAL 14 for each peptide is the start position 4 WLPIMRNPI 7 234 VALGVALVL 14 plus eight. 7 IMRNPITPT 7 244 LLFILLLRL 14 Pos 123456789 score 17 HVFQTSILG 7 317 AVLEAILLL 14
4 AILLLVLIF 17 333 RIRIAIALL 14
5 ILLLVLIFL 17 452 WTLNWVLAL 14
6 LLLVLIFLR 16 TableXXX-V9-HLA-B2705-9mers- 602 GKLLWGGV 14
2 LEAILLLVL 14 24P4C12 626 GKDFKSPHL 14
8 LVLIFLRQR 14 679 GSLDRPYYM 14
3 EAILLLVLI 12 23 FRGPIKNRS 13
9 VLIFLRQRI 11 34 DVICCVLFL 13 83 KPYLLYFNI 13
TableXXXI-V1-HLA-B2709- TableXXXI-V1-HLA-B270J )- TableXXXI-V1-HLA-B2709-
9merse-24P4C12 9merse-24P4C12 9merse-24P4C12
Each peptide is a portion of SEQ Each peptide is a portion of SEQ Each peptide is a portion of SEQ
ID NO: 3; each start position is ID NO: 3; each start position is ID NO: 3; each start position is specified, the length of peptide is specified, the length of peptide is specified, the length of peptide is
9 amino acids, and the end 9 amino acids, and the end 9 amino acids, and the end position for each peptide s the position for each peptide is the position for each peptide is the start position plus eight. start position plus eight. start position plus eight.
Pos 123456789 score Pos 123456789 score Pos 123456789 score
107 GLQCPTPQV 13 518 ILEYIDHKL 2 509 LTLVQIARV 11
204 GISGLIDSL 13 553 KFLNRNAYI 2 510 TLVQIARVI 11
232 ILVALGVAL 13 593 KVTDLLLFF 2 511 LVQIARVIL 11
236 LGVALVLSL 13 596 DLLLFFGKL 2 526 LRGVQNPVA 11
237 GVALVLSLL 13 597 LLLFFGKLL 2 534 ARCIMCCFK 11
240 LVLSLLFIL 13 605 LWGGVGVL 2 537 IMCCFKCCL 11
242 LSLLFILLL 13 608 GGVGVLSFF 2 564 AIYGKNFCV 11
253 VAGPLVLVL 13 621 RIPGLGKDF 2 572 VSAKNAFML 11
291 SQLGFTTNL 13 637 YWLPIMTSI 2 591 LDKVTDLLL 11
311 AALIVLAVL 13 666 LFLCFLEDL 2 592 DKVTDLLLF 11
322 ILLLMUFL 13 684 PYYMSKSLL 2 598 LLFFGKLLV 11
357 YPLVTFVLL 13 5 QRDEDDEAY 599 LFFGKLLW 11
358 PLVTFVLLL 13 28 KNRSCTDVI 609 GVGVLSFFF 11
369 IAYWAMTAL 13 29 NRSCTDVIC 614 SFFFFSGRI 11
440 FNLQIYGVL 13 32 CTDVICCVL 617 FFSGRIPGL 11
442 LQIYGVLGL 13 41 FLLFILGYI 631 SPHLNYYWL 11
449 GLFWTLNWV 13 42 LLFILGYIV 634 LNYYWLPIM 11
496 RYHTGSLAF 13 46 LGYIWGIV 643 TSILGAYVI 11
500 GSLAFGALI 13 67 PRNSTGAYC 653 SGFFSVFGM 11
515 ARVILEYID 13 79 ENKDKPYLL 658 VFGMCVDTL 11
557 RNAYIMIAI 13 87 LYFNIFSCI 663 VDTLFLCFL 11
589 WLDKVTDL 13 100 IISVAENGL 675 ERNNGSLDR 11
15 KPVKYDPSF 12 128 GKNEFSQTV 687 MSKSLLKIL 11
38 CVLFLLFIL 12 139 VFYTKNRNF
45 ILGYIWGI 12 151 GVPWNMTVI TableXXXI-V3-HLA-B2709-
56 WLYGDPRQV 12 184 WTNVTPPAL 9mers-24P4C12
61 PRQVLYPRN 12 217 ISVKIFEDF Each peptide is a portion of SEQ
81 KDKPYLLYF 12 225 FAQSWYWIL ID NO: 7; each start position is
158 VITSLQQEL 12 230 YWILVALGV specified, the length of peptide is
164 QELCPSFLL 12 238 VALVLSLLF 9 amino acids, and the end
258 VLVLILGVL 12 239 ALVLSLLFI position for each peptide is the
261 LILGVLGVL 12 249 LLRLVAGPL start position plus eight.
287 GASISQLGF 12 257 LVLVLILGV Pos 123456789 score
308 TWLAALIVL 12 260 VLILGVLGV 1 GRCFPWTNI 22
316 - LAVLEAILL 12 280 YRVLRDKGA 6 WTNITPPAL 11
321 AILLLMLIF 12 283 LRDKGASIS 9 ITPPALPGI 11
328 IFLRQRIRI 12 285 DKGASISQL
355 MFYPLVTFV 12 297 TNLSAYQSV TableXXXI-V5-B2709-9mers-
371 YWAMTALYL 12 310 LAALIVLAV 24P4C12
414 LVNSSCPGL 12 314 IVLAVLEAI Each peptide is a portion of
432 KGLIQRSVF 12 319 LEAILLLML SEQ ID NO: 11; each start
434 LIQRSVFNL J 12 351 MMSTMFYPL position is specified, the length
461 GQCVLAGAF 12 354 TMFYPLVTF of peptide is 9 amino adds,
492 IRTLRYHTG 12 381 TSGQPQYVL and the end position for each
495 LRYHTGSLA 12 386 QYVLWASNI peptide is the start position plus
501 SLAFGALIL 12 427 QGYSSKGLI eight
503 AFGALILTL 12 480 QDIPTFPLI Pos 123456789 score
506 ALILTLVQI 12 483 PTFPLISAF 4 AILLLVLIF 13
ILLLVLIFL 13 Each pepti'de is a portion of TableXXXII-V1 -HLA-B4402- LEAILLLVL 11 SEQ ID NO: 19; each start 9mers-24P4C12 VLEAILLLV 10 position is specified, the Each peptide is a portion of SEQ EAILLLVLI 10 length of peptide is 9 amino ID NO: 3; each start position is VLIFLRQRI 10 acids, and the end position for spedfied, the length of peptide is each peptide is the start 9 amino acids, and the end
TableXXXI-V6-HLA-B2709- position plus eight. position for each peptide is the 9mers-24P4C12 Pos 123456789 i score start position plus eight.
Each peptide is a portion of SEQ 18 GYVLWASNI 14 Pos 123456789 score ID NO: 13; each start position is 2 WAMTALYPL 11 629 FKSPHLNYY 16 specified, the length of peptide is 13 QPATLGYVL 11 699 NEAPPDNKK 16
9 amino acids, and the end 9 PLPTQPATL 10 34 DVICCVLFL 15 position for each peptide is the 12 TQPATLGYV 8 79 ENKDKPYLL 15 start position plus eight. 130 NEFSQTVGE 15
Pos 123456789 score TableXXXII-V1-HLA-B4402- 154 WNMTVITSL 15
9 PRSVFNLQI 20 9mers-24P4C12 204 GISGLIDSL 15
5 KGLIPRSVF 12 Each peptide is a portion of SEQ 234 VALGVALVL 15
7 LIPRSVFNL 12 ID NO: 3; each start position is 241 VLSLLFILL 15
4 SKGLIPRSV 9 specified, the length of peptide is 263 LGVLGVLAY 15
9 amino acids, and the end 278 EEYRVLRDK 15
TableXXXI-V7-HLA-B2709- position for each peptide is the 294 GFTTNLSAY 15 9mers-24P4C12 start position plus eight. 354 TMFYPLVTF 15
Each peptide is a portion of SEQ Pos 123456789 score 370 AYWAMTALY 15 ID NO: 15, each start position is 164 QELCPSFLL 22 399 CEKVPINTS 15 specified, the length of peptide is 319 LEAILLLML 22 442 LQIYGVLGL 15
9 amino acids, and the end 222 FEDFAQSWY 21 468 AFASFYWAF 15 position for each peptide is the 78 GENKDKPYL 20 477 HKPQDIPTF 15 start position plus eight. 306 QETWLAALI 20 499 TGSLAFGAL 15 Pos 123456789 score 483 PTFPLISAF 20 513 QIARVILEY 15
I SWYWILVAV 12 317 AVLEAILLL 19 547 CLEKFIKFL 15
4 WILVAVGQM 12 332 QRIRIAIAL 19 66 YPRNSTGAY 14
5 ILVAVGQMM 10 503 AFGALILTL 18 80 NKDKPYLLY 14 8 AVGQMMSTM 9 506 ALILTLVQI 18 84 PYLLYFNIF 14
552 IKFLNRNAY 18 93 SCILSSNII 14
TableXXXI-V8-HLA-B2709- 58 YGDPRQVLY 17 104 AENGLQCPT 14 9mers-24P4C12 170 FLLPSAPAL 17 193 PGITNDTTI 14
Each peptide is a portion of 214 ARDISVKIF 17 223 EDFAQSWYW 14 SEQ ID NO: 17; each start 242 LSLLFILLL 17 239 ALVLSLLFI 14 position is specified, the length 583 RNIVRVWL 17 244 LLFILLLRL 14 of peptide is 9 amino acids, 11 EAYGKPVKY 16 258 VLVLILGVL 14 and the end position for each 40 LFLLFILGY 16 261 LILGVLGVL 14 peptide is the start position 48 YIWGIVAW 16 285 DKGASISQL 14 plus eight. 81 KDKPYLLYF 16 291 SQLGFTTNL 14
Pos 123456789 score 121 PEDPWTVGK 16 301 AYQSVQETW 14
16 GHVFQTSIL 14 228 SWYWILVAL 16 305 VQETWLAAL 14
8 MRNPITPTG 13 253 VAGPLVLVL 16 308 TWLAALIVL 14
II PITPTGHVF 10 254 AGPLVLVLI 16 316 LAVLEAILL 14
10 NPITPTGHV 9 311 AALIVLAVL 16 322 ILLLMLIFL 14 4 WLPIMRNPI 8 320 EAILLLMLI 16 330 LRQRIRIAI 14 15 TGHVFQTSI 8 321 AILLLMLIF 16 333 RIRIAIALL 14 20 QTSILGAYV 8 363 VLLLICIAY 16 356 FYPLVTFVL 14
382 SGQPQYVLW 16 357 YPLVTFVLL 14
TableXXXI-V9-HLA-B2709- 452 WTLNWVLAL 16 358 PLVTFVLLL 14 9mers-24P4C12 480 QDIPTFPLI 16 364 LLLICIAYW 14
487 LISAFIRTL 16 418 SCPGLMCVF 14
489 SAFIRTLRY 16 432 KGLIQRSVF 14
617 FFSGRIPGL 16 446 GVLGLFWTL 14
TableXXXII-V1 -HLA-B4402- TableXXXII-V1-HLA-B4402- TableXXXII-V1-HLA-B4402-
9mers-24P4C12 9mers-24P4C12 9mers-24P4C12
Each peptide is a portion of SEQ Each peptide is a portion of SEQ Each peptide is a portion of SEQ
ID NO: 3; each start position is ID NO: 3; each start position is ID NO: 3; each start position is specified, the length of peptide is specified, the length of peptide is specified, the length of peptide is
9 amino acids, and the end 9 amino acids, and the end 9 amino acids, and the end position for each peptide is the position for each peptide is the position for each peptide is the start position plus eight. start position plus eight. start position plus eight. Pos 123456789 score Pos 123456789 score Pos 123456789 score
496 RYHTGSLAF 14 519 LEYIDHKLR 13 548 LEKFIKFLN 12
546 WCLEKFIKF 14 529 VQNPVARCI 13 553 KFLNRNAYI 12
558 NAYIMIAIY 14 543 CCLWCLEKF 13 557 RNAYIMIAI 12
573 SAKNAFMLL 14 570 FCVSAKNAF 13 562 MIAIYGKNF 12
577 AFMLLMRNI 14 589 WLDKVTDL 13 572 VSAKNAFML 12
592 DKVTDLLLF 14 590 VLDKVTDLL 13 591 LDKVTDLLL 12
593 KVTDLLLFF 14 605 LWGGVGVL 13 607 VGGVGVLSF 12
596 DLLLFFGKL 14 631 SPHLNYYWL 13 608 GGVGVLSFF 12
597 LLLFFGKLL 14 637 YWLPIMTSI 13 610 VGVLSFFFF 12
621 RIPGLGKDF 14 648 AYVIASGFF 13 630 KSPHLNYYW 12
641 IMTSILGAY 14 674 LERNNGSLD 13 638 WLPIMTSIL 12
643 TSILGAYVI 14 687 MSKSLLKIL 13 647 GAYVIASGF 12
651 IASGFFSVF 14 33 TDVICCVLF 12 658 VFGMCVDTL 12
662 CVDTLFLCF 14 35 VICCVLFLL 12 659 FGMCVDTLF 12
671 LEDLERNNG 14 38 CVLFLLFIL 12 660 GMCVDTLFL 12
678 NGSLDRPYY 14 50 WGIVAWLY 12 663 VDTLFLCFL 12
5 QRDEDDEAY 13 100 IISVAENGL 12 666 LFLCFLEDL 12
7 DEDDEAYGK 13 132 FSQTVGEVF 12 673 DLERNNGSL 12
32 CTDVICCVL 13 133 SQTVGEVFY 12 677 NNGSLDRPY 12
36 ICCVLFLLF 13 139 VFYTKNRNF 12 683 RPYYMSKSL 12
49 IWGIVAWL 13 141 YTKNRNFCL 12 686 YMSKSLLKI 12
57 LYGDPRQVL 13 163 QQELCPSFL 12 10 DEAYGKPVK 11
77 MGENKDKPY 13 217 ISVKIFEDF 12 15 KPVKYDPSF 11
87 LYFNIFSCI 13 221 IFEDFAQSW 12 28 KNRSCTDVI 11
137 GEVFYTKNR 13 236 LGVALVLSL 12 37 CCVLFLLFI 11
146 NFCLPGVPW 13 240 LVLSLLFIL 12 41 FLLFILGYI 11
174 SAPALGRCF 13 249 LLRLVAGPL 12 45 ILGYIWGI 11
176 PALGRCFPW 13 267 GVLAYGIYY 12 117 VSSCPEDPW 11
184 WTNVTPPAL 13 269 LAYGIYYCW 12 124 PWTVGKNEF 11
187 VTPPALPGI 13 275 YCWEEYRVL 12 151 GVPWNMTVI 11
200 TIQQGISGL 13 287 GASISQLGF 12 197 NDTTIQQGI 11
209 IDSLNARDI 13 314 IVLAVLEAI 12 201 IQQGISGLI 11
213 NARDISVKI 13 326 MLIFLRQRI 12 266 LGVLAYGIY 11
232 ILVALGVAL 13 328 IFLRQRIRI 12 302 YQSVQETWL 11
237 GVALVLSLL 13 349 GQMMSTMFY 12 359 LVTFVLLLI 11
238 VALVLSLLF 13 369 IAYWAMTAL 12 361 TFVLLLICI 11
251 RLVAGPLVL 13 371 YWAMTALYL 12 379 LATSGQPQY 11
255 GPLVLVLIL 13 406 TSCNPTAHL 12 381 TSGQPQYVL 11
277 WEEYRVLRD 13 421 GLMCVFQGY 12 436 QRSVFNLQI 11
342 KEASKAVGQ 13 426 FQGYSSKGL 12 444 IYGVLGLFW 11
351 MMSTMFYPL 13 434 LIQRSVFNL 12 465 LAGAFASFY 11
440 FNLQIYGVL 13 437 RSVFNLQIY 12 474 WAFHKPQDI 11
443 QIYGVLGLF 13 450 LFWTLNWVL 12 484 TFPLISAFI 11
448 LGLFWTLNW 13 457 VLALGQCVL 12 494 TLRYHTGSL 11
461 GQCVLAGAF 13 464 VLAGAFASF 12 533 VARCIMCCF 11
466 AGAFASFYW 13 479 PQDIPTFPL 12 538 MCCFKCCLW 11
501 SLAFGALIL 13 510 TLVQIARVI 12 540 CFKCCLWCL 11
518 ILEYIDHKL 13 511 LVQIARVIL 12 614 SFFFFSGRI 11
TableXXXII I -HLA-B4402- 2 LEAILLLVL 23 Each peptide is a portion of SEQ ID 9mers-24P4C12 3 EAILLLVLI 17 NO: 19; each start position is
Each peptide is a portion of SEQ 4 AILLLVLIF 17 specified, the length of peptide is 9
ID NO: 3; each start position is 5 ILLLVLIFL 14 amino acids, and the end position for specified, the length of peptide is 9 VLIFLRQRI 12 each peptide is the start position plus
9 amino acids, and the end eight. position for each peptide is the TableXXXII-V6-HLA-B4402- Pos 123456789 score start position plus eight. 9mers-24P4C12 11 PTQPATLGY 15
Pos 123456789 score Each peptide is a portion of SEQ 9 PLPTQPATL 14
626 GKDFKSPHL 11 ID NO: 13; each start position is 2 WAMTALYPL 13
628 DFKSPHLNY 11 specified, the length of peptide is 14 PATLGYVLW 13
684 PYYMSKSLL 11 9 amino acids, and the end 13 QPATLGYVL 12
19 YDPSFRGPI 10 position for each peptide is the 18 GYVLWASNI 10
83 KPYLLYFNI 10 start position plus eight. 6 ALYPLPTQP 8
88 YFNIFSCIL 10 'OS 123456789 score 15 ATLGYVLWA 7
158 VITSLQQEL 10 5 KGUPRSVF 14
162 LQQELCPSF 10 7 LIPRSVFNL 13 TableXXXIII-V1-HLA-B5101-
225 FAQSWYWIL 10 9 PRSVFNLQI 11 9mers-24P4C12
272 GIYYCWEEY 10 6 GLIPRSVFN 8 Each peptide is a portion of SEQ
315 VLAVLEAIL 10 ID NO: 3; each start position is
348 VGQMMSTMF 10 TableXXXII-V7-HLA-B4402- specified, the length of peptide is 9
386 QYVLWASNI 10 9mers-24P4C12 amino acids, and the end position
396 SPGCEKVPI 10 Each peptide is a portion of SEQ for each peptide is the start
414 LVNSSCPGL 10 ID NO: 15; each start position is position plus eight.
500 GSLAFGALI 10 specified, the length of peptide is Pos 123456789 score
514 IARVILEYI 10 9 amino acids, and the end 234 VALGVALVL 27
537 IMCCFKCCL 10 position for each peptide is the 213 NARDISVKI 25
544 CLWCLEKFI 10 start position plus eight. 46 LGYIWGIV 24
555 LNRNAYIMI 10 Pos 123456789 score 83 KPYLLYFNI 24
609 GVGVLSFFF 10 1 SWYWILVAV 6 311 AALIVLAVL 24
3 YWILVAVGQ 6 253 VAGPLVLVL 23
TableXXXII-V3-HLA-B4402- 8 AVGQMMSTM 4 310 LAALIVLAV 23
9mers-24P4C12 4 WILVAVGQM 3 357 YPLVTFVLL 23
Each i peptide is a portion of 2 WYWILVAVG 2 369 IAYWAMTAL 23
SEQ ID NO: 7; each start 474 WAFHKPQDI 23 position is specified, the length TableXXXII-V8-HLA-B4402- 514 IARVILEYI 23 of peptide is 9 amino acids, and 9mers-24P4C12 683 RPYYMSKSL 22 the end position for each Each peptide is a portion of SEQ 254 AGPLVLVLI 21 peptide is the start position plus ID NO: 17; each start position is 255 GPLVLVLIL 21 eight. specified, the length of peptide is 9 320 EAILLLMLI 21
Pos 123456789 score amino acids, and the end position 396 SPGCEKVPI 21
6 WTNITPPAL 13 for each peptide is the start 427 QGYSSKGLI 21
9 ITPPALPGI 13 position plus eight. 11 EAYGKPVKY 20
1 GRCFPWTNI 8 Pos 123456789 score 193 PGITNDTTI 20
2 RCFPWTNIT 7 11 PITPTGHVF 15 316 LAVLEAILL 20
7 TNITPPALP 6 19 FQTSILGAY 14 123 DPWTVGKNE 19
8 NITPPALPG 6 4 WLPIMRNPI 11 236 LGVALVLSL 18
16 GHVFQTSIL 11 314 IVLAVLEAI 18
TableXXXII-V5-HLA-B4402- 15 TGHVFQTSI 8 599 LFFGKLLW 18 9mers-24P4C12 686 YMSKSLLKI 18
Each peptide is a portion of SEQ TableXXXII-V9-HLA-B4402-9mers- 60 DPRQVLYPR 17 ID NO: 11; each start position is 24P4C12 150 PGVPWNMTV 17 specified, the length of peptide is 225 FAQSWYWIL 17
9 amino acids, and the end 261 LILGVLGVL 17 position for each peptide is the 269 LAYGIYYCW 17 start position plus eight. 300 SAYQSVQET 17 Pos 123456789 score 504 FGALILTLV 17
TableXXXIII-V1-HLA-B5101- TableXXXIII-V1-HLA-B5101- Pos 123456789 score
9mers-24P4C12 9mers-24P4C12 4 FPWTNITPP 15
558 NAYIMIAIY 17 499 TGSLAFGAL 14 9 ITPPALPGI 14
573 SAKNAFMLL 17 509 LTLVQIARV 14 1 GRCFPWTNI 11
651 IASGFFSVF 17 576 NAFMLLMRN 14 6 WTNITPPAL 8
182 FPWTNVTPP 16 586 VRWVLDKV 14
192 LPGITNDTT 16 589 WLDKVTDL 14 TableXXXIII-V5-HLA-B5101-9mers-
328 IFLRQRIRI 16 602 GKLLWGGV 14 24P4C12
355 MFYPLVTFV 16 605 LWGGVGVL 14 Each peptide is a portion of SEQ ID
359 LVTFVLLLI 16 639 LPIMTSILG 14 NO: 11; each start position is
458 LALGQCVLA 16 701 APPDNKKRK 14 spedfied, the length of peptide is 9
502 LAFGALILT 16 702 PPDNKKRKK 14 amino acids, and the end position for
505 GALILTLVQ 16 19 YDPSFRGPI 13 each peptide is the start position plus
510 TLVQIARVI 16 28 KNRSCTDVI 13 eight.
581 LMRNIVRW 16 34 DVICCVLFL 13 Pos 123456789 score
631 SPHLNYYWL 16 54 VAWLYGDPR 13 3 EAILLLVLI 22
9 DDEAYGKPV 15 66 YPRNSTGAY 13 5 ILLLVLIFL 14
45 ILGYIVVGI 15 112 TPQVCVSSC 13 2 LEAILLLVL 13
56 WLYGDPRQV 15 149 LPGVPWNMT 13 1 VLEAILLLV 12
110 CPTPQVCVS 15 174 SAPALGRCF 13 9 VLIFLRQRI 12
120 CPEDPWTVG 15 176 PALGRCFPW 13
151 GVPWNMTVI 15 187 VTPPALPGI 13 TableXXXIII-V6-HLA-B5101-
172 LPSAPALGR 15 189 PPALPGITN 13 9mers-24P4C12
224 DFAQSWYWI 15 201 IQQGISGLI 13 Each peptide is a portion of SEQ
275 YCWEEYRVL 15 239 ALVLSLLFI 13 ID NO: 13; each start position is
308 TWLAALIVL 15 252 LVAGPLVLV 13 specified, the length of peptide is 9
336 IAIALLKEA 15 282 VLRDKGASI 13 amino acids, and the end position
338 IALLKEASK 15 285 DKGASISQL 13 for each peptide is the start
375 TALYLATSG 15 293 LGFTTNLSA 13 position plus eight.
485 FPUSAFIR 15 322 ILLLMUFL 13 Pos 123456789 score
529 VQNPVARCI 15 330 LRQRIRIAI 13 8 IPRSVFNLQ 16
564 AIYGKNFCV 15 340 LLKEASKAV 13 7 LIPRSVFNL 12
582 MRNIVRVW 15 343 EASKAVGQM 13 9 PRSVFNLQI 12
596 DLLLFFGKL 15 356 FYPLVTFVL 13 5 KGLIPRSVF 11
637 YWLPIMTSI 15 361 TFVLLLICI 13 4 SKGLIPRSV 10
643 TSILGAYVI 15 384 QPQYVLWAS 13
647 GAYVIASGF 15 478 KPQDIPTFP 13 TableXXXIII-V7-HLA-B5101-
700 EAPPDNKKR 15 487 LISAFIRTL 13 9mers-24P4C12
20 DPSFRGPIK 14 489 SAFIRTLRY 13 Each peptide is a portion of SEQ
41 FLLFILGYI 14 500 GSLAFGALI 13 ID NO: 15; each start position is
43 LFILGYIW 14 506 ALILTLVQI 13 specified, the length of peptide is 9
72 GAYCGMGEN 14 521 YIDHKLRGV 13 amino acids, and the end position
87 LYFNIFSCI 14 531 NPVARCIMC 13 for each peptide is the start
119 SCPEDPWTV 14 553 KFLNRNAYI 13 position plus eight.
152 VPWNMTVIT 14 555 LNRNAYIMI 13 Pos 123456789 score
188 TPPALPGIT 14 563 IAIYGKNFC 13 1 SWYWILVAV 14
190 PALPGITND 14 578 FMLLMRNIV 13 7 VAVGQMMST 12
209 IDSLNARDI 14 580 LLMRNIVRV 13 2 WYWILVAVG 6
230 YWILVALGV 14 3 YWILVAVGQ 6
238 VALVLSLLF 14 TableXXXIII-V3-HLA-B5101-
257 LVLVLILGV 14 9mers-24P4C12 TableXXXIII-V8-HLA-B5101-9mers-
409 NPTAHLVNS 14 Each peptide is a portion of SEQ 24P4C12
411 TAHLVNSSC 14 ID NO: 7; each start position is
450 LFWTLNWVL 14 specified, the length of peptide is 9
465 LAGAFASFY 14 amino acids, and the end position
467 GAFASFYWA 14 for each peptide is the start
482 IPTFPLISA 14 position plus eight.
Each peptide is a portion of SEQ ID TableXXXIV-V1 -HLA-A1 -1 Omers- TableXXXIV-V3-HLA-A1-10mers-
NO: 17; each start position is 24P4C12 24P4C12 specified, the length of peptide is 9 Each peptide is a portion of SEQ Each peptide is a portion of SEQ ID amino acids, and the end position for ID NO: 3; each start position is NO: 7; each start position is each peptide is the start position plus specified, the length of peptide is specified, the length of peptide is eight. 10 amino acids, and the end 10 amino acids, and the end
Pos 123456789 score position for each peptide is the position for each peptide is the start
10 NPITPTGHV 21 start position plus nine. position plus nine.
15 TGHVFQTSI 18 Pos 1234567890 score Pos 1234567890 score
13 TPTGHVFQT 14 49 IWGIVAWLY 18 10 IIPPALPGIT 10
4 WLPIMRNPI 13 378 YLATSGQPQY 18 3 RCFPWTNITP 9
5 LPIMRNPIT 13 420 PGLMCVFQGY 18 7 WINITPPALP 8
464 VLAGAFASFY 18 8 TNITPPALPG 6
TableXXXIII-V9-HLA-B5101- 10 DEAYGKPVKY 17 9 N1TPPALPGI 4
9mers-24P4C12 57 LYGDPRQVLY 17
Each peptide is a portion of SEQ 121 PEDPWTVGKN 17 TableXXXIV-V5-HLA.A1-
ID NO: 19; each start position is 265 VLGVLAYGIY 17 10mers-24P4C12 specified, the length of peptide is 9 271 YGIYYCWEEY 17 Each peptide is a portion of amino acids, and the end position 276 CWEEYRVLRD 17 SEQ ID NO: 11; each start for each peptide is the start 369 IAYWAMJALY 17 position is specified, the length position plus eight. 551 FIKFLNRNAY 17 of peptide is 10 amino acids,
Pos 123456789 score 80 NKDKPYLLYF 16 and the end position for each
13 QPATLGYVL 20 348 VGQMMSIMFY 16 peptide is the start position plus
2 WAMTALYPL 18 676 RNNGSLDRPY 16 nine.
5 TALYPLPTQ 16 677 NNGSLDRPYY 16 Pos 1234567890 score
8 YPLPTQPAT 15 4 KQRDEDDEAY 15 2 VLEAILLLVL 19
10 LPTQPATLG 14 18 KYDPSFRGPI 15 7 LLLVLIFLRQ 10
12 TQPATLGYV 13 65 LYPRNSTGAY 15 1 AVLEAILLLV 9
17 LGYVLWASN 12 76 GMGENKDKPY 15
9 PLPTQPATL 11 214 ARDISVKIFE 15 TableXXXIV-V6-HLA-A1 -10mers-
14 PATLGYVLW 11 293 LGFTTNLSAY 15 24P4C12
18 GYVLWASNI 11 436 QRSVFNLQIY 15 Each peptide is a portion of SEQ 479 PQDIPTFPLI 15 ID NO: 13; each start position is
TableXXXIV-VI -HLA-A1 -1 Omers- 557 RNAYIMIAIY 15 specified, the length of peptide is 24P4C12 628 DFKSPHLNYY 15 10 amino acids, and the end
Each peptide is a portion of SEQ 640 PIMTSILGAY 15 position for each peptide is the
ID NO: 3; each start position is 664 DTLFLCFLED 15 start position plus nine. specified, the length of peptide is 283 LRDKGASISQ 14 Pos 1234567890 score
10 amino acids, and the end 521 YIDHKLRGVQ 14 10 PRSVFNLQIY 15 position for each peptide is the 673 DLERNNGSLD 14 1 QGYSSKGLIP 7 start position plus nine. 141 YIKNRNFCLP 13 4 SSKGLIPRSV 7
Pos 1234567890 score 305 VQETWLAALI 13 9 IPRSVFNLQI 7
221 IFEDFAQSWY 25 382 SGQPQYVLWA 13
488 ISAFIRTLRY 25 407 SCNPTAHLVN 13 TableXXXIV-V7-HLA-A1-10mers-
39 VLFLLFILGY 23 518 ILEYIDHKLR 13 24P4C12
58 YGDPRQVLYP 23 547 CLEKFIKFLN 13 Each peptide is a portion of SEQ>
79 ENKDKPΫLLY 23 670 FLEDLERNNG 13 ID NO: 15; each start position is
262 ILGVLGVLAY 23 680 SLDRPYYMSK 13 specified, the length of peptide is
512 VQJARVILEY 22 7 DEDDEAYGKP 12 10 amino acids, and the end
627 KDFKSPHLNY 21 35 VICCVLFLLF 12 position for each peptide is the
132 FSQTVGEVFY 20 159 ITSLQQELCP 12 start position plus nine.
266 LGVLAYGIYY 20 163 QQELCPSFLL 12 Pos 1234567890 score
362 FVLLLICIAY 20 242 LSLLFILLLR 12 1 QSWYWILVAV 4
590 VLDKVTDLLL 20 618 FSGRIPGLGK 12 2 SWYWILVAVG 4
594 VTDLLLFFGK 20 626 GKDFKSPHLN 12 4 YWILVAVGQM 3
318 VLEAILLLML 19 698 KNEAPPDNKK 12 5 WILVAVGQMM 2
32 CTDVICCVLF 18 6 ILVAVGQMMS 2
8 VAVGQMMSTM 2 TableXXXV-V1-HLA-A0201- TableXXXV-V1-HLA-A0201 •
9 AVGQMMSTMF 2 10mers-24P4C12 10mers-24P4C12
Each peptide is a portion of SEQ Each peptide is a portion of SEQ
TableXXXIV-V8-HLA-A1- ID NO: 3; each start position is ID NO: 3; each start position is 10mers-24P4C12 specified, the length of peptide is specified, the length of peptide is
Each peptide is a portion of SEQ 10 amino acids, and the end 10 amino acids, and the end
ID NO: 17; each start position is position for each peptide is the position for each peptide is the specified, the length of peptide is start position plus nine. start position plus nine.
10 amino acids, and the end Pos 1234567890 score Pos 1234567890 score position for each peptide is the 441 NLQIYGVLGL 26 95 ILSSNIISVA 20 start position plus nine. 502 LAFGALILTL 26 191 ALPGITNDTT 20
Pos 1234567890 score 517 VILEYIDHKL 26 238 VALVLSLLFI 20
19 VFQTSILGAY 16 603 KLLWGGVGV 26 261 LILGVLGVLA 20
4 YWLPIMRNPI 7 604 LLWGGVGVL 26 314 IVLAVLEAIL 20
13 ITPTGHVFQT 7 45 ILGYIWGIV 25 325 LMLIFLRQRI 20
21 QTSILGAYVI 7 252 LVAGPLVLVL 25 329 FLRQRIRIAI 20
304 SVQETWLAAL 25 350 QMMSTMFYPL 20
TableXXXI V-V9-HLA-A1 -1 Omers- 312 ALIVLAVLEA 25 358 PLVTFVLLLI 20 24P4C12 318 VLEAILLLML 25 368 CIAYWAMTAL 20
Each peptide is a portion of SEQ ID 486 PLISAFIRTL 25 393 NISSPGCEKV 20
NO: 19; each start position is 657 SVFGMCVDTL 25 554 FLNRNAYIMI 20 specified, the length of peptide is 10 665 TLFLCFLEDL 25 596 DLLLFFGKLL 20 amino acids, and the end position for 248 LLLRLVAGPL 24 645 ILGAYVIASG 20 each peptide is the start position plus 259 LVLILGVLGV 24 649 YVIASGFFSV 20 nine. 310 LAALIVLAVL 24 34 DVICCVLFLL 19
Pos 1234567890 score 339 ALLKEASKAV 24 64 VLYPRNSTGA 19
11 LPTQPAJJ.GY 21 597 LLLFFGKLLV 24 85 YLLYFNIFSC 19
12 PTQPATLGYV 10 41 FLLFILGYIV 23 186 NVTPPALPGI 19
42 LLFILGYIW 23 233 LVALGVALVL 19
56 WLYGDPRQVL 23 264 GVLGVLAYGI 19
TableXXXV-V1-HLA-A0201- 231 WILVALGVAL 23 317 AVLEAILLLM 19
10mers-24P4C12 249 LLRLVAGPLV 23 327 LIFLRQRIRI 19
Each peptide is a portion of SEQ 256 PLVLVLILGV 23 335 RIAIALLKEA 19
ID NO : 3; each start position is 313 LIVLAVLEAI 23 351 MMSTMFYPLV 19 specified, the length of peptide is 315 VLAVLEAILL 23 357 YPLVTFVLLL 19
10 amino acids, and the end 438 SVFNLGjYGV 23 363 VLLLICIAYW 19 position for each peptide is the 459 ALGQCVLAGA 23 364 LLLICIAYWA 19 start position plus nine. 686 YMSKSLLKIL 23 365 LLICIAYWAM 19
Pos 1234567890 score 99 NIISVAENGL 22 380 ATSGQPQYVL 19
235 ALGVALVLSL 29 257 LVLVLILGVL 22 457 VLALGQCVLA 19
44 FILGYIVVGI 28 354 TMFYPLVTFV 22 536 CIMCCFKCCL 19
232 ILVALGVALV 28 413 HLVNSSCPGL 22 588 VWLDKVTDL 19
243 SLLFILLLRL 28 449 GLFWTLNWVL 22 633 HLNYYWLPIM 19
309 WLAALIVLAV 28 506 ALILTLVQIA 22 644 SILGAYVIAS 19
579 MLLMRNIVRV 28 510 TLVQΪARVIL 22 39 VLFLLFILGY 18
244 LLFILLLRLV 27 513 QIARVILEYI 22 157 TVITSLQQEL 18
260 VULGVLGVL 27 581 LMRNIVRVW 22 203 QGISGLIDSL 18
433 GLIQRSVFNL 27 585 IVRVWLDKV 22 208 LIDSLNARDI 18
508 ILTLVQIARV 27 590 VLDKVTDLLL 22 240 LVLSLLFILL 18
580 LLMRNIVRW 27 199 TTIQQGISGL 21 246 FILLLRLVAG 18
598 LLFFGKLLW 27 247 ILLLRLVAGP 21 262 ILGVLGVLAY 18
48 YIWGIVAWL 26 253 VAGPLVLVLI 21 281 RVLRDKGASI 18
94 CILSSNIISV 26 316 LAVLEAILLL 21 322 ILLLMLIFLR 18
239 ALVLSLLFIL 26 501 SLAFGALILT 21 332 QRIRIAIALL 18
241 VLSLLFΪLLL 26 505 GALILTLVQI 21 360 VTFVLLLICI 18
251 RLVAGPLVLV 26 641 IMTSILGAYV 21 388 VLWASNISSP 18
321 AILLLMLIFL 26 86 LLYFNIFSCI 20 448 LGLFWTLNWV 18
TableXXXV-V1-HLA-A0201- TableXXXV-V1-HLA-A0201- Pos 1234567890 score 10mers-24P4C12 10mers-24P4C12 9 NITPPALPGI 23
Each peptide is a portion of SEQ Each peptide is a portion of SEQ 10 ITPPALPGIT 12
ID NO: 3; each start position is ID NO: 3; each start position is spedfied, the length of peptide is specified, the length of peptide is TableXXXV-V5-HLA-A0201-
10 amino acids, and the end 10 amino acids, and the end 10mers-24P4C12 position for each peptide is the position for each peptide is the Each peptide is a portion of SEQ start position plus nine. start position plus nine. ID NO: 11; each start position is
Pos 1234567890 score Pos 1234567890 score spedfied, the length of peptide is
493 RTLRYHTGSL 18 323 LLLMUFLRQ 15 10 amino acids, and the end
525 KLRGVQNPVA 18 340 LLKEASKAVG 15 position for each peptide is the
589 WLDKVTDLL 18 378 YLATSGQPQY 15 start position plus nine.
616 FFFSGRIPGL 18 379 LATSGQPQYV 15 Pos 1234567890 score
662 CVDTLFLCFL 18 430 SSKGLIQRSV 15 5 AILLLVLIFL 26
685 YYMSKSLLKI 18 464 VLAGAFASFY 15 1 AVLEAjLLLV 25
130 NEFSQTVGEV 17 498 HTGSLAFGAL 15 2 VLEAILLLVL 25
143 KNRNFCLPGV 17 520 EYIDHKLRGV 15 3 LEAILLLVLI 18
148 CLPGVPWNMT 17 539 CCFKCCLWCL 15 6 ILLLVLIFLR 18
170 FLLPSAPALG 17 601 FGKLLWGGV 15 8 LLVLIFLRQR 16
211 SLNARDISVK 17 690 SLLKILGKKN 15 9 LVLIFLRQRI 16
227 QSWYWILVAL 17 26 PIKNRSCTDV 14 7 LLLVLIFLRQ 15
254 AGPLVLVLIL 17 30 RSCTDVICCV 14 10 VLIFLRQRIR 12
296 TTNLSAYQSV 17 37 CCVLFLLFIL 14
324 LLMLIFLRQR 17 102 SVAENGLQCP 14 TableXXXV-V6-HLA-A0201 -
373 AMTALYLATS 17 149 LPGVPWNMTV 14 10mers-24P4C12
481 DIPTFPLISA 17 153 PWNMTVITSL 14 Each peptide is a portion of SEQ
546 WCLEKFIKFL 17 162 LQQELCPSFL 14 ID NO: 13; each start position is
563 IAIYGKNFCV 17 165 ELCPSFLLPS 14 specified, the length of peptide is
582 MRNIVRVWL 17 171 LLPSAPALGR 14 10 amino acids, and the end
40 LFLLFILGYI 16 177 ALGRCFPWTN 14 position for each peptide is the
108 LQCPTPQVCV 16 220 KIFEDFAQSW 14 start position plus nine.
118 SSCPEDPWTV 16 273 IYYCWEEYRV 14 Pos 1234567890 score
169 SFLLPSAPAL 16 338 IALLKEASKA 14 7 GLIPRSVFNL 29
200 TIQQGISGLI 16 353 STMFYPLVTF 14 4 SSKGUPRSV 15
207 GLIDSLNARD 16 370 AYWAMTALYL 14
212 LNARDISVKI 16 395 SSPGCEKVPI 14 TableXXXV-V7-HLA-A0201-
236 LGVALVLSLL 16 416 NSSCPGLMCV 14 10mers-24P4C12
292 QLGFTTNLSA 16 445 YGVLGLFWTL 14 Each peptide is a portion of SEQ
307 ETWLAALIVL 16 483 PTFPLISAFI 14 ID NO: 15; each start position is
319 LEAILLLMLI 16 500 GSLAFGALIL 14 specified, the length of peptide is
337 AIALLKEASK 16 571 CVSAKNAFML 14 10 amino acids, and the end
366 LICIAYWAMT 16 577 AFMLLMRNIV 14 position for each peptide is the
405 NTSCNPTAHL 16 595 TDLLLFFGKL 14 start position plus nine.
451 FWTLNWVLAL 16 606 WGGVGVLSF 14 Pos 1234567890 score
456 WVLALGQCVL 16 639 LPIMTSILGA 14 1 QSWYWILVAV 4
458 LALGQCVLAG 16 680 SLDRPYYMSK 14 2 SWYWILVAVG 4
503 AFGALILTLV 16 693 KILGKKNEAP 14 4 YWILVAVGQM 3
509 LTLVQΪARVI 16 694 ILGKKNEAPP 14 5 WILVAVGQMM 2
637 YWLPIMTSIL 16 6 ILVAVGQMMS 2
33 TDVICCVLFL 15 TableXXXV-V3-HLA-A0201- 8 VAVGQMMSTM 2
36 ICCVLFLLFI 15 10mers-24P4C12 9 AVGQMMSTMF 2
90 NIFSCILSSN 15 Each peptide is a portion of SEQ
161 SLQQELCPSF 15 ID NO: 7; each start position is TableXXXV-V8-HLA-A0201-
225 FAQSWYWILV 15 specified, the length of peptide is 10mers-24P4C12
234 VALGVALVLS 15 10 amino acids, and the end
250 LRLVAGPLVL 15 position for each peptide is the
284 RDKGASISQL 15 start position plus nine.
Each peptide is a portion of SEQ TableXXXVI-V1 -HLA-A0203- TableXXXVI-V1-HLA-A0203- ID NO: 17; each start position is 10mers-24P4C12 10mers-24P4C12 specified, the length of peptide Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID is 10 amino acids, and the end NO: 3; each start position is NO: 3; each start position is position for each peptide is the specified, the length of peptide is 10 specified, the length of peptid. s is 10 start position plus nine. amino acids, and the end position amino acids, and the end position Pos 1234567890 score for each peptide is the start position for each peptide is the start position
4 YWLPIMRNPI 15 plus nine. plus nine.
5 WLPIMRNPIT 15 Pos 1234567890 score Pos 1234567890 i score 18 HVFQTSILGA 15 46 LGYIWGIVA 10 218 SVKIFEDFAQ 9
7 PIMRNPITPT 14 64 VLYPRNSTGA 10 227 QSWYWILVAL 9 13 ITPTGHVFQT 14 95 ILSSNIISVA 10 231 WILVALGVAL 9
8 IMRNPITPTG 13 166 LCPSFLLPSA 10 246 FILLLRLVAG 9 21 QTSILGAYVI 13 182 FPWTNVIPPA 10 262 ILGVLGVLAY 9 20 FQTSILGAYV 12 205 ISGLIDSLNA 10 280 YRVLRDKGAS 9
15 PTGHVFQTSI 11 217 ISVKIFEDFA 10 293 LGFTTNLSAY 9 10 RNPITPTGHV 10 226 AQSWYWILVA 10 309 WLAALIVLAV 9
16 TGHVFQTSIL 10 230 YWILVALGVA 10 313 UVLAVLEAI 9 12 PITPTGHVFQ 8 245 - LFILLLRLVA 10 329 FLRQRIRIAI 9 261 LILGVLGVLA 10 331 RQRIRIAIAL 9
TableXXXV-V9-HLA-A0201 - 279 EΫRVLRDKGA 10 336 IAIALLKEAS 9 10mers-24P4C12 292 QLGFTTNLSA 10 339 ALLKEASKAV 9
Each peptide is a portion of SEQ 302 YQSVQEIWLA 10 362 FVLLLICIAY 9 ID NO: 19; each start position is 308 TWLAALIVLA 10 365 LLICIAYWAM 9 specified, the length of peptide is 312 ALIVLAVLEA 10 368 CIAYWAMTAL 9
10 amino acids, and the end 328 IFLRQRIRIA 10 372 WAMTALYLAT 9 position for each peptide is the 335 RIAIALLKEA 10 383 GQPQYVLWAS 9 start position plus nine. 338 IALLKEASKA 10 404 INTSCNPTAH 9
Pos 1234567890 score 361 TFVLLLICIA 10 451 FWTLNWVLAL 9 9 YPLPTQPATL 20 364 LLLICIAΫWA 10 458 LALGQCVLAG 9
2 YWAMTALYPL 19 367 ICIAYWAMTA 10 460 LGQCVLAGAF 9 7 ALYPLPTQPA 19 371 YWAMTALYLA 10 462 QCVLAGAFAS 9
12 PTQPATLGYV 17 382 SGQPQYVLWA 10 467 GAFASFYWAF 9
16 ATLGYVLWAS 15 403 PINTSCNPTA 10 482 IPTFPLISAF 9
4 AMTALYPLPT 14 450 LFWTLNWVLA 10 495 LRYHTG'SLAF 9
5 MTALYPLPTQ 13 457 VLALGQCVLA 10 498 HTGSLAFGAL 9
17 TLGYVLWASN 13 466 AGAFASFYWA 10 507 LILTLVQIAR 9
13 TQPATLGYVL 11 481 DIPTFPLISA 10 526 LRGVQNPVAR 9
18 LGYVLWASNI 11 494 TLRYHTGSLA 10 551 FIKFLNRNAY 9 15 PATLGYVLWA 9 497 YHTGSLAFGA 10 556 NRNAYIMIAI 9 506 ALILTLVQIA 10 566 YGKNFCVSAK 9
TableXXXVI-V1 -HLA-A0203- 525 KLRGVQNPVA 10 569 NFCVSAKNAF 9 10mers-24P4C12 550 KFIKFLNRNA 10 640 PIMTSILGAY 9
Each peptide is a portion of SEQ ID 555 LNRNAYIMIA 10 644 SILGAYVIAS 9
NO: 3; each start position is 565 IYGKNFCVSA 10 693 KILGKKNEAP 9 specified, the length of peptide is 10 568 KNFCVSAKNA 10 amino acids, and the end position 639 LPIMTSΪLGA 10 for each peptide is the start position 643 TSILGAΫVIA 10 TableXXXVI-V3-HLA-A0203-1 Omers- plus nine. 692 LKILGKKNEA 10 24P4C12
Pos 1234567890 score 4 KQRDEDDEAY 9 Each peptide is a portion of SEQ ID
303 QSVQETWLAA 19 47 GYIWGIVAW 9 NO: 7; each start position is specified, 168 PSFLLPSAPA 18 65 LYPRNSTGAY 9 the length of peptide is 10 amino 330 LRQRIRIAIA 18 96 LSSNIISVAE 9 acids, and Uie end position for each 459 ALGQCVLAGA 18 167 CPSFLLPSAP 9 peptide is the start position plus nine. 461 GQCVLAGAFA 18 169 SFLLPSAPAL 9 Pos 1234567890 score
304 SVQETWLAAL 17 183 PWTNVTPPAL 9 5 FPWTNIIPPA 10 3 GKQRDEDDEA 10 206 SGLIDSLNAR 9 6 PWTNITPPAL 9
TableXXXVI-V3-HLA-A0203-1 Omers- 16 AILGYVLWAS 9 TableXXXVII-V1-HLA-A3-10mers- 24P4C12 ' 9 YPLPTQPATL 8 24P4C12
Each peptide is a portion of SEQ ID 17 TLGYVLWASN 8 Each peptide is a portion of SEQ ID NO: 7; each start position is specified, NO: 3; each start position is specified, the length of peptide is 10 amino TableXXXVII-V1 -HLA-A3-10mers- the length of peptide is 10 amino acids, and the end position for each 24P4C12 acids, and the end position for each peptide is the start position plus nine. Each peptide is a portion of SEQ ID peptide is the start position plus nine. Pos 1234567890 score NO: 3; each start position is specified, Pos 1234567890 score
7 WJNITPPALP 8 the length of peptide is 10 amino 340 LLKEASKAVG 19 acids, and the end position for each 347 AVGQMMSTMF 19
TableXXXVI-V5-HLA-A0203- peptide is the start position plus nine. 494 TLRYHJGSLA 19 10mers-24P4C12 Pos 1234567890 score 605 LVVGGVGVLS 19
Pos 1234567890 score 333 RIRIAIALLK 32 618 FSGRIPGLGK 19 NoResultsFound. 211 SLNARDISVK 30 645 ILGAYVJASG 19
337 AIALLKEASK 28 673 DLERNNGSLD 19
TableXXXVI-V6-HLA-A0203- 516 RVILEYIDHK 28 6 RDEDDEAYGK 18 10mers-24P4C12 281 RVLRDKGASI 27 64 VLYPRNSTGA 18
Pos 1234567890 score 680 SLDRPYYMSK 27 134 QTVGEVFYTK 18
NoResultsFound. 464 VLAGAFASFY 25 231 WILVALGVAL 18
584 NIVRVWLDK 24 235 ALGVALVLSL 18
621 RIPGLGKDFK 24 247 ILLLRLVAGP 18
TableXXXVI-V7-HLA-A0203-1 Omers- 49 IWGIVAWLY 23 258 VLVLILGVLG 18 24P4C12 463 CVLAGAFASF 23 324 LLMLIFLRQR 18
Each peptide is a portion of SEQ ID 233 ' LVALGVALVL 22 456 WVLALGQCVL 18
NO: 15; each start position is specified, 262 ILGVLGVLAY 22 532 PVARCIMCCF 18 the length of peptide is 10 amino acids, 376 ALYLATSGQP 22 72 GAYCGMGENK 17 and the end position for each peptide is 443 QIYGVLGLFW 22 86 LLYFNJFSCI 17 the start position plus nine. 525 KLRGVQNPVA 22 161 SLQQELCPSF 17
Pos 1234567890 score 587 RVWLDKVTD 22 207 GUDSLNARD 17
1 QSWYWILVAV 9 603 KLLVVGGVGV 22 220 KIFEDFAQSW 17
2 SWYWILVAVG 8 56 WLΫGDPRQVL 21 232 ILVALGVALV 17
63 QVLYPRNSTG 21 249 LLRLVAGPLV 17
TableXXXVI-V8-HLA-A0203-10mers- 177 ALGRCFPWTN 21 257 LVLVLJLGVL 17 24P4C12 564 AIYGKNFCVS 21 264 GVLGVLAYGI 17
Each peptide is a portion of SEQ ID 606 WGGVGVLSF 21 265 VLGVLAYGIY 17
NO: 17; each start position is 39 VLFLLFILGY 20 292 QLGF7TNLSA 17 specified, the length of peptide is 10 53 IVAWLYGDPR 20 309 WLAAUVLAV 17 amino acids, and the end position for 171 LLPSAPALGR 20 326 MLIFLRQRIR 17 each peptide is the start position plus 251 RLVAGPLVLV 20 364 LLLICJAYWA 17 nine. 252 LVAGPLVLVL 20 388 VLWASNISSP 17 Pos 1234567890 score 282 VLRDKGASIS 20 392 SNISSPGCEK 17
18 HVFQTSILGA 10 362 FVLLUCIAY 20 486 PLISARRTL 17
19 VFQTSILGAY 9 378 YLATSGQPQY 20 506 ALΪLTLVQIA 17
20 FQTSILGAYV 8 544 CLWCLEKFIK 20 551 FIKFLNRNAY 17
650 VIASGFFSVF 20 580 LLMRNIVRW 17
TableXXXVI-V9-HLA-A0203-1 Omers- 95 ILSSNIISVA 19 598 LLFFGKLLW 17 24P4C12 170 FLLPSAPALG 19 612 VLSFFFFSGR 17
Each peptide is a portion of SEQ ID 191 ALPGITNDTT 19 624 GLGKDFKSPH 17
NO: 19; each start position is 237 GVALVLSLLF 19 649 YVIASGFFSV 17 specified, the length of peptide is 10 248 LLLRLVAGPL 19 657 SVFGMCVDTL 17 amino acids, and the end position for 260 VLΪLGVLGVL 19 667 FLCFLEDLER 17 each peptide is the start position plus 261 LILGVLGVLA 19 684 PYYMSKSLLK 17 nine. 298 NLSAYQSVQE 19 689 KSLLK1LGKK 17 Pos 1234567890 score 312 ALIVLAVLEA 19 9 DDEAYGKPVK 16
7 ALYPLPIQPA 10 314 IVLAVLEAIL 19 44 FILGYIVVGI 16 15 PATLGYVLWA 10 317 AVLEAILLLM 19 126 TVGKNEFSQT 16
8 LYPLPTQPAT 9 322 ILLLMLIFLR 19 165 ELCPSFLLPS 16
TableXXXVII-V1-HLA-A3-1 Omers- Each peptide is a portion of SEQ ID Pos 1234567890 score
24P4C12 NO: 7; each start position is 9 AVGQMMSTMF 19
Each peptide is a portion of SEQ ID specified, the length of peptide is 10 6 ILVAVGQMMS 16 O: 3; each start position is specified, amino acids, and the end position for 5 WILVAVGQMM 14 the length of peptide is 10 amino each peptide is the start position plus 7 LVAVGQMMST 14 acids, and the end position for each nine. 2 SWYWILVAVG 12 peptide is the start position plus nine. Pos 1234567890 score 8 VAVGQMMSTM 9
Pos 1234567890 score 3 RCFPWINITP 11
243 SLLFILLLRL 16 9 NIPPALPGI 11 TableXXXVII-V8-HLA-A3-1 Omers-
246 FILLLRLVAG 16 8 TNITPPALPG 9 24P4C12
259 LVLILGVLGV 16 10 ITPPALPGIT 7 Each peptide is a portion of SEQ ID
272 GIYΫCWEEYR 16 7 WTNITPPALP 5 NO: 17; each start position is
304 SVQETWLAAL 16 spedfied, the length of peptide is 10
318 VLEAILLLML 16 amino acids, and the end position for
339 ALLKEASKAV 16 TableXXXVII-V5-HLA-A3-1 Omers- each peptide is the start position plus
363 VLLLICIAYW 16 24P4C12 nine.
453 TLNWVLALGQ 16 Each peptide is a portion of SEQ ID Pos 1234567890 score
457 VLALGQCVLA 16 NO: 11; each start position is specified, 12 PIPTGHVFQ 15
459 ALGQCVLAGA 16 the length of peptide is 10 amino acids, 11 NPITPTCHVF 14
487 LISAFIRTLR 16 and the end position for each peptide is 18 HVFQTSILGA 13
508 ILTLVQJARV 16 the start position plus nine. 7 PIMRNPJTPT 12
518 ILEYIDHKLR 16 Pos 1234567890 score 5 WLPIMRNPIT 11
559 AYIMIAIYGK 16 1 AVLEAILLLV 19 1 LNYYWLPIMR 10
566 YGKNFCVSAK 16 2 VLEAILLLVL 19 8 IMRNPITPTG 10
571 CVSAKNAFML 16 6 ILLLVLIFLR 19 21 QTSILGAYVI 10
579 MLLMRNIVRV 16 8 LLVLIFLRQR 18 9 MRNPΠPTGH 9
596 DLLLFFGKLL 16 10 VLIFLRQRIR 17 6 LPIMRNPITP 8
640 PIMTSILGAY 16 7 LLLVLIFLRQ 15 19 VFQTSJLGAY 8
690 SLLKILGKKN 16 5 AILLLVLIFL 14
693 KILGKKNEAP 16 9 LVLIFLRQRI 14 TableXXXVII-V9-HLA-A3-10mers-
35 VICCVLFLLF 15 4 EAΪLLJNLIF 11 24P4C12
41 FLLFILGYIV 15 Each peptide is a portion of SEQ ID
42 LLFILGYIVV 15 TableXXXVII-V6-HLA-A3-10mers- NO: 19; each start position is
107 GLQCPTPQVC 15 24P4C12 specified, the length of peptide is 10
120 CPEDPWTVGK 15 Each peptide is a portion of SEQ ID amino acids, and the end position for
180 RCFPWTNVTP 15 NO: 13; each start position is each peptide is the start position plus
323 LLLMLIFLRQ 15 specified, the length of peptide is 10 nine.
329 FCRQRIRIAI 15 amino acids, and the end position for Pos 1234567890 score
367 ICIAYWAMTA 15 each peptide is the start position plus 7 ALYPLPJQPA 20
369 IAΫWAMTALY 15 nine. 17 TLGYVLWASN 15
423 MCVFQGYSSK 15 Pos 1234567890 score 10 PLPTQPATLG 14
446 GVLGLFWTLN 15 7 GLIPRSVFNL 16 9 YPLPTQPATL 13
491 FIRTLRYHTG 15 5 SKGLIPRSVF 14 1 AYWAMJALYP 11
507 LILTLVQIAR 15 1 QGYSSKGLIP 12 18 LGYVLWASNI 10
510 TLVQIARVIL 15 8 LIPRSVFNLQ 11 4 AMIALYPLPT 9
585 IVRVWLDKV 15 9 IPRSVFNLQI 11 11 LPIQPAJLGY 9
597 LLLFFGKLLV 15 6 KGLIPRSVFN 10 13 TQPATLGYVL 9
604 LLVVGGVGVL 15 4 SSKGLIPRSV 7
688 SKSLLKILGK 15 TableXXXVIII-V1-HLA-A26-10mers-
694 ILGKKNEAPP 15 TableXXXVII-V7-HLA-A3-1 Omers- 24P4C12
697 KKNEAPPDNK 15 24P4C12 Each peptide is a portion of SEQ ID
698 KNEAPPDNKK 15 Each peptide is a portion of SEQ ID NO: 3; each start position is
NO: 15; each start position is spedfied, the length of peptide is 10
TableXXXVII-V3-HLA-A3-1 Omers- spedfied, the length of peptide is 10 amino acids, and the end position for 24P4C12 amino adds, and the end position for each peptide is the start position each peptide is the start position plus plus nine. nine. Pos 1234567890 score
TableXXXVIII-VI -HLA-A26-10mers- TableXXXVIII-V1-HLA-A26-10mers- 10 ITPPALPGIT 10
24P4C12 24P4C12 7 WTNITPPALP 8
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID 3 RCFPWTNITP 7
NO: 3; each start position is NO: 3; each start position i 8 TNITPPALPG 6 specified, the length of peptide is 10 specified, the length of peptide is 10 4 CFPWTNITPP 4 amino acids, and the end position for amino acids, and the end position for each peptide is the start position each pepti'de is the start position TableXXXVIII-V5-HLA-A26- plus nine. plus nine. 10mers-24P4C12
Pos 1234567890 score Pos 1234567890 score Each peptide is a portion of
34 DVICCVLFLL 34 532 PVARCIMCCF 18 SEQ ID NO: 11; each start
138 EVFYTKNRNF 32 549 EKFIKFLNRN 18 position is specified, the length
307 ETWLAALIVL 31 609 GVGVLSFFFF 18 of peptide is 10 amino acids,
657 SVFGMCVDTL 28 99 NIISVAENGL 17 and the end position for each
199 TTIQQGISGL 26 102 SVAENGLQCP 17 peptide is the start position plus
304 SVQETWLAAL 26 156 MTVITSLQQE 17 nine.
588 VWLDKVTDL 26 236 LGVALVLSLL 17 Pos 1234567890 score
592 DKVTDLLLFF 25 260 VLILGVLGVL 17 4 EAILLLVLIF 27
49 IWGIVAWLY 24 316 LAVLEAILLL 17 1 AVLEAILLLV 17
606 WGGVGVLSF 24 317 AVLEAILLLM 17 5 AILLLVLIFL 17
157 TVITSLQQEL 23 321 AILLLMLIFL 17 2 VLEAILLLVL 13
252 LVAGPLVLVL 23 360 VTFVLLLICI 17
257 LVLVLILGVL 23 442 LQIYGVLGLF 17 TableXXXVIII-V6-HLA-A26-
320 EAILLLMLIF 23 596 DLLLFFGKLL 17 10mers-24P4C12
628 DFKSPHLNYY 23 604 LLWGGVGVL 17 Each peptide is a portion of
79 ENKDKPYLLY 22 616 FFFSGRIPGL 17 SEQ ID NO: 13; each start
353 STMFYPLVTF 22 664 DTLFLCFLED 17 position is specified, the length
362 FVLLLICIAY 22 665 TLFLCFLEDL 17 of peptide is 10 amino acids,
662 CVDTLFLCFL 22 682 DRPYYMSKSL 17 and the end position for each
672 EDLERNNGSL 22 32 CTDVICCVLF 16 peptide is the start position plus
48 YIWGIVAWL 20 37 CCVLFLLFIL 16 nine.
198 DTTIQQGISG 20 123 DPWTVGKNEF 16 Pos 1234567890 score
216 DISVKIFEDF 20 165 ELCPSFLLPS 16 7 GLIPRSVFNL 17
240 LVLSLLFILL 20 186 NVTPPALPGI 16 10 PRSVFNLQIY 14
293 LGFTTNLSAY 20 224 DFAQSWYWIL 16 5 SKGLIPRSVF 10
640 PIMTSILGAY 20 239 ALVLSLLFIL 16
10 DEAYGKPVKY 19 262 ILGVLGVLAY 16 TableXXXVIII-V7-HLA-A26-
39 VLFLLFILGY 19 266 LGVLAYGIYY 16 10mers-24P4C12
131 EFSQTVGEVF 19 332 QRIRIAIALL 16 Each peptide is a portion of SEQ
233 LVALGVALVL 19 359 LVTFVLLLIC 16 ID NO: 15; each start position is
237 GVALVLSLLF 19 380 ATSGQPQYVL 16 specified, the length of peptide is
347 AVGQMMSTMF 19 400 EKVPINTSCN 16 10 amino adds, and the end
438 SVFNLQIYGV 19 405 NTSCNPTAHL 16 position for each peptide is the
463 CVLAGAFASF 19 424 CVFQGYSSKG 16 start position plus nine.
498 HTGSLAFGAL 19 433 GLIQRSVFNL 16 Pos 1234567890 score
512 VQIARVILEY 19 539 CCFKCCLWCL 16 9 AVGQMMSTMF 19
520 EYIDHKLRGV 19 593 KVTDLLLFFG 16 7 LVAVGQMMST 11
571 CVSAKNAFML 19 4 YWILVAVGQM 10
589 WLDKVTDLL 19 TableXXXVIII-V3-HLA-A26-1 Omers-
33 TDVICCVLFL 18 24P4C12 TableXXXVIII-V8-HLA-A26-
203 QGISGLIDSL 18 Each peptide is a portion of SEQ ID NO: 10mers-24P4C12
314 IVLAVLEAIL 18 7; each start position is specified, the Each peptide is a portion of SEQ ID
456 WVLALGQCVL 18 length of peptide is 10 amino acids, and NO: 17; each start position is
481 DIPTFPLISA 18 . the end position for each peptide is the specified, the length of peptide is 10
486 PLISAFIRTL 18 start position plus nine. amino acids, and the end position
493 RTLRYHTGSL 18 Pos 1234567890 score for each peptide is the start position
502 LAFGALILTL 18 6 PWTNITPPAL 10 plus nine.
516 RVILEYIDHK 18 9 NITPPALPGI 10 Pos 1234567890 score
18 HVFQTSILGA 19 TableXXXIX-VI -HLA-B0702- TableXXXIX-V1-HLA-B0702-
19 VFQTSILGAY 16 10mers-24P4C12 10mers-24P4C12
11 NPITPTGHVF 13 Each peptide is a portion of SEQ Each peptide is a portion of SEQ
13 ITPTGHVFQT 13 ID NO: 3; each start position is ID NO: 3; each start position is
16 TGHVFQTSIL 10 specified, the length of peptide is specified, the length of peptide is
15 PTGHVFQTSI 9 10 amino acids, and the end 10 amino acids, and the end position for each peptide s the position for each peptide s the
TableXXXVHI-V9-HLA-A26-10mers- start position plus nine. start position plus nine
24P4C12 Pos 1234567890 score Pos 1234567890 score
Each peptide is a portion of SEQ ID 331 RQRIRIAIAL 14 316 LAVLEAILLL 12
NO: 19; each start position is 405 NTSCNPTAHL 14 409 NPTAHLVNSS 12 specifiec , the length of peptide is 10 451 FWTLNWVLAL 14 419 CPGLMCVFQG 12 amino acids, and the end position for 502 LAFGALILTL 14 425 VFQGYSSKGL 12 each peptide is the start position plus 582 MRNIVRVWL 14 456 WVLALGQCVL 12 nine. 590 VLDKVTDLLL 14 493 RTLRYHTGSL 12
Pos 1234567890 score 15 KPVKYDPSFR 13 581 LMRNIVRVW 12
12 PTQPATLGYV 14 60 DPRQVLYPRN 13 588 WVLDKVTDL 12
5 MTALYPLPTQ 13 66 YPRNSTGAYC 13 604 LLWGGVGVL 12
16 ATLGYVLWAS 13 110 CPTPQVCVSS 13 606 WGGVGVLSF 12
2 YWAMTALYPL 12 120 CPEDPWTVGK 13 622 IPGLGKDFKS 12
11 LPTQPATLGY 12 167 CPSFLLPSAP 13 637 YWLPIMTSIL 12
9 YPLPTQPATL 10 172 LPSAPALGRC 13 662 CVDTLFLCFL 12
13 TQPATLGYVL 10 226 AQSWYWILVA 13 701 APPDNKKRKK 12
15 PATLGYVLWA 6 227 QSWYWILVAL 13 18 KYDPSFRGPI 11
231 WILVALGVAL 13 25 GPIKNRSCTD 11
TableXXXIX-V1 -HLA-B0702- 250 LRLVAGPLVL 13 31 SCTDVICCVL 11
10mers-24P4C12 284 RDKGASISQL 13 44 FILGYIWGI 11
Each peptide is a portion of SEQ 290 ISQLGFTTNL 13 77 MGENKDKPYL 11
ID NO: 3; each start position is 301 AYQSVQETWL 13 78 GENKDKPYLL 11 specified, the length of peptide is 310 LAALIVLAVL 13 140 FYTKNRNFCL 11
10 amino acids, and the end 314 IVLAVLEAIL 13 152 VPWNMTVITS 11 position for each peptide s the 318 VLEAILLLML 13 153 PWNMTVITSL 11 start position plus nine. 321 AILLLMLIFL 13 162 LQQELCPSFL 11
Pos 1234567890 score 350 QMMSTMFYPL 13 188 TPPALPGITN 11
357 YPLVTFVLLL 23 355 MFYPLVTFVL 13 224 DFAQSWYWIL 11
478 KPQDIPTFPL 23 356 FYPLVTFVLL 13 236 LGVALVLSLL 11
683 RPYYMSKSLL 21 368 CIAYWAMTAL 13 240 LVLSLLFILL 11
182 FPWTNVTPPA 19 396 SPGCEKVPIN 13 248 LLLRLVAGPL 11
83 KPYLLYFNIF 18 441 NLQIYGVLGL 13 257 LVLVLILGVL 11
192 LPGΓΓNDTTI 18 498 HTGSLAFGAL 13 260 VLILGVLGVL 11
482 IPTFPLISAF 18 500 GSLAFGALIL 13 274 YYCWEEYRVL 11
639 LPIMTSILGA 18 510 TLVQIARVIL 13 312 ALIVLAVLEA 11
149 LPGVPWNMTV 17 525 KLRGVQNPVA 13 315 VLAVLEAILL 11
252 LVAGPLVLVL 17 571 CVSAKNAFML 13 332 QRIRIAIALL 11
380 ATSGQPQYVL 17 572 VSAKNAFMLL 13 384 QPQYVLWASN 11
402 VPINTSCNPT 17 657 SVFGMCVDTL 13 395 SSPGCEKVPI 11
485 FPLISAFIRT 17 686 YMSKSLLKIL 13 413 HLVNSSCPGL 11
123 DPWTVGKNEF 16 20 DPSFRGPIKN 12 433 GLIQRSVFNL 11
235 ALGVALVLSL 16 48 YIWGIVAWL 12 435 IQRSVFNLQI 11
254 AGPLVLVLIL 15 169 SFLLPSAPAL 12 439 VFNLQIYGVL 11
370 AYWAMTALYL 15 183 PWTNVTPPAL 12 445 YGVLGLFWTL 11
659 FGMCVDTLFL 15 189 PPALPGITND 12 449 GLFWTLNWVL 11
33 TDVICCVLFL 14 239 ALVLSLLFIL 12 503 AFGALILTLV 11
56 WLYGDPRQVL 14 243 SLLFILLLRL 12 531 NPVARCIMCC 11
175 APALGRCFPW 14 304 SVQETWLAAL 12 536 CIMCCFKCCL 11
233 LVALGVALVL 14 307 ETWLAALIVL 12 539 CCFKCCLWCL 11
241 VLSLLFILLL 14 309 WLAALIVLAV 12 546 WCLEKFIKFL 11
TableXXXIX-VI -HLA-B0702- 24P4C12 10mers-24P4C12 Pos 1234567890 score
Each peptide is a portion of SEQ TableXXXIX-V7-HLA-B0702- NoResultsFound.
ID NO: 3; each start position is 10mers-24P4C12 specified, the length of peptide is Each peptide is a portion of SEQ ID TableXL-V3-HLA-B08-1 Omers-
10 amino acids, and the end NO: 15; each start position is 24P4C12 position for each peptide is the specified, the length of peptide is 10 Pos 1234567890 score start position plus nine. amino acids, and the end position for NoResultsFound.
Pos 1234567890 score each peptide is the start position plus
565 IYGKNFCVSA 11 nine. TableXL-V5-HLA-B08-10mers-
589 WLDKVTDLL 11 Pos 1234567890 score 24P4C12
595 TDLLLFFGKL 11 9 AVGQMMSTMF 10 Pos 1234567890 score
616 FFFSGRIPGL 11 1 QSWYWILVAV 9 NoResultsFound.
625 LGKDFKSPHL 11 8 VAVGQMMSTM 8
630 KSPHLNYYWL 11 4 YWILVAVGQM 7 TableXL-V6-HLA-B08-10mers-
672 EDLERNNGSL 11 7 LVAVGQMMST 7 24P4C12
5 WILVAVGQMM 6 Pos 1234567890 score
TableXXXIX-V3-HLA-B0702- NoResultsFound. 10mers-24P4C12 TableXXXIX-V8-HLA-B0702-
Each peptide is a portion of SEQ ID 10mers-24P4C12 TableXL-V7-HLA-B08-10mers-
NO: 7; each start position is Each peptide is a portion of SEQ 24P4C12 specified, the length of peptide is 10 ID NO: 17; each start position is Pos 1234567890 score amino acids, and the end position specified, the length of peptide is NoResultsFound. for each peptide is the start position 10 amino acids, and the end plus nine. position for each peptide is the TableXL-V8-HLA-B08-10mers-
Pos 1234567890 score start position plus nine. 24P4C12
5 FPWTNITPPA 19 Pos 1234567890 score Pos 1234567890 score
6 PWTNITPPAL 12 11 NPITPTGHVF 17 NoResultsFound.
1 LGRCFPWTNI 9 14 TPTGHVFQTS 13
16 TGHVFQTSIL 11 TableXL-V9-HLA-B08-
TableXXXIX-V5-HLA-B0702- 6 LPIMRNPITP 10 10mers-24P4C12 10mers-24P4C12 4 YWLPIMRNPI 9 Pos 1234567890 score
Each peptide is a portion of SEQ 7 PIMRNPITPT 9 NoResultsFound.
ID NO: 11 ; each start position is 21 QTSILGAYVI 9 specified, the length of peptide is 10 RNPITPTGHV 8 TableXLI-V1-HLA-B1510-10mers-
10 amino acids, and the end 13 ITPTGHVFQT 8 24P4C12 position for each peptide is the 15 PTGHVFQTSI 8 Pos 1234567890 score start position plus nine. 18 HVFQTSILGA 8 NoResultsFound. Pos 1234567890 score
2 VLEAILLLVL 14 TableXXXIX-V9-HLA-B0702- TableXLI-V3-HLA-B1510-10mers- 5 AILLLVLIFL 13 10mers-24P4C12 24P4C12 1 AVLEAILLLV 10 Each peptide is a portion of SEQ Pos 1234567890 score 4 EAILLLVLIF 10 ID NO: 19; each start position is NoResultsFound.
3 LEAILLLVLI 9 specified, the length of peptide is 9 LVLIFLRQRI 7 10 amino acids, and the end TableXLI-V5-HLA-B1510-1 Omers- position for each peptide is the 24P4C12
TableXXXIX-V6-HLA-B0702- start position plus nine. Pos 1234567890 score 10mers-24P4C12 Pos 1234567890 score NoResultsFound.
Each peptide is a portion of SEQ ID 9 YPLPTQPATL 22
NO: 13; each start position is 11 LPTQPATLGY 13 TableXLI-V6-HLA-B1510- specified, the length of peptide is 10 14 QPATLGYVLW 13 10mers-24P4C12 amino acids, and the end position 2 YWAMTALYPL 12 Pos 1234567890 score for each peptide is the start position 4 AMTALYPLPT 12 NoResultsFound. plus nine. 13 TQPATLGYVL 12
Pos 1234567890 score 7 ALYPLPTQPA 11 TableXLI-V7-HLA-B1510-1 Omers-
9 IPRSVFNLQI 21 24P4C12
7 GLIPRSVFNL 12 TableXL-V1-HLA-B08-10mers-
Pos 1234567890 score TableXUII-V3-HLA-B2709-1 Omers- TableXLIV.V1-HLA-B4402.
NoResultsFound. 24P4C12 10mers-24P4C12 Pos 1234567890 score Each peptide is a portion of SEQ ID
TableXLI-V8-HLA-B1510-1 Omers- NoResultsFound. NO: 3; each start position > is
24P4C12 specified, the length of peptid e is 10
Pos 1234567890 score TableXLIII-V5-HLA-B2709-1 Omers- amino ; acids, and the end position
NoResultsFound. 24P4C12 for each peptide is the start position Pos 1234567890 score plus nine.
TableXLI-V9-HLA-B1510-1 Omers- NoResultsFound. Pos 1234567890 score 24P4C12 199 TTIQQGISGL 16
Pos 1234567890 score TableXLIII-V6-HLA-B2709-1 Omers- 203 QGISGLIDSL 16
NoResultsFound. 24P4C12 260 VLILGVLGVL 16
Pos 1234567890 score 293 LGFTTNLSAY 16
NoResultsFound. 307 ETWLAALIVL 16
TableXLII I -HLA-B2705-10mers- 316 LAVLEAILLL 16
24P4C12 TableXLIII-V7-HLA-B2709-10mers-24P4C12 380 ATSGQPQYVL 16
Pos 1234567890 score Pos 1234567890 score 546 WCLEKFIKFL 16
NoResultsFound. NoResultsFound. 657 SVFGMCVDTL 16
34 DVICCVLFLL 15
TableXLII-V3-HLA-B2705-10mers-24P4C12 TableXLIII-V8-HLA-B2709-10mers- 65 LYPRNSTGAY 15
Pos 1234567890 score 24P4C12 79 ENKDKPYLLY 15
NoResultsFound. Pos 1234567890 score 99 NIISVAENGL 15
NoResultsFound. 104 AENGLQCPTP 15
TableXLII-V5-HLA-B2705-1 Omers- 138 EVFYTKNRNF 15 24P4C12 TableXLIII-V9-HLA-B2709-1 Omers- 213 NARDISVKIF 15
Pos 1234567890 score 24P4C12 235 ALGVALVLSL 15 NoResultsFound. Pos 1234567890 score 239 ALVLSLLFIL 15 NoResultsFound. 278 EEYRVLRDKG 15
TableXLII-V6-HLA-B2705-1 Omers- 284 RDKGASISQL 15
24P4C12 TableXLIV-V1-HLA-B4402- 353 STMFYPLVTF 15 Pos 1234567890 score 10mers-24P4C12 355 MFYPLVTFVL 15
NoResultsFound. Each peptide is a portion of SEQ ID 356 FYPLVTFVLL 15
NO: 3; each start positior l is 362 FVLLLICIAY 15
TableXLII-V7.HLA.B2705-10me.s- specified, the length of peptide is 10 363 VLLLICIAYW 15
24P4C12 amino acids, and the end position 370 AYWAMTALYL 15 Pos 1234567890 score for each peptide is the start position 417 SSCPGLMCVF 15
NoResultsFound. plus nine. 442 LQIYGVLGLF 15
Pos 1234567890 score 451 FWTLNWVLAL 15
TableXLII-V8-HLA-B2705-1 Omers- 10 DEAYGKPVKY 23 482 IPTFPLISAF 15
24P4C12 78 GENKDKPYLL 22 561 IMIAIYGKNF 15
Pos 1234567890 score 222 FEDFAQSWYW 21 596 DLLLFFGKLL 15
NoResultsFound. 319 LEAILLLMLI 20 616 FFFSGRIPGL 15
47 GYIWGIVAW 19 637 YWLPIMTSIL 15
TableXLII-V9-HLA-B2705-1 Omers- 332 QRIRIAIALL 18 640 PIMTSILGAY 15
24P4C12 486 PLISAFIRTL 18 4 KQRDEDDEAY 14
Pos 1234567890 score 502 LAFGALILTL 18 18 KYDPSFRGPI 14
NoResultsFound. 620 GRIPGLGKDF 18 80 NKDKPYLLYF 14
39 VLFLLFILGY 17 83 KPYLLYFNIF 14
TableXLIII-V1-HLA-B2709-10mers- 241 VLSLLFILLL 17 130 NEFSQTVGEV 14
24P4C12 254 AGPLVLVLIL 17 131 EFSQTVGEVF 14 Pos 1234567890 score 320 EAILLLMLIF 17 157 TVITSLQQEL 14 NoResultsFound. 321 AILLLMLIFL 17 164 QELCPSFLLP 14
476 FHKPQDIPTF 17 173 PSAPALGRCF 14
TableXLIII-V3-HLA-B2709-10mers- 512 VQIARVILEY 17 175 APALGRCFPW 14 24P4C12 699 NEAPPDNKKR 17 183 PWTNVTPPAL 14
Pos 1234567890 score 121 PEDPWTVGKN 16 220 KIFEDFAQSW 14
169 SFLLPSAPAL 16 227 QSWYWILVAL 14
TableXLIV-V1-HLA-B4402- TableXLIV-V1-HLA-B4402- TableXLIV-V1-HLA-B4402-
10mers-24P4C12 10mers-24P4C12 10mers-24P4C12
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID
NO: 3; each start positior is NO: 3; each start positior l is NO: 3; each start position is specified, the length of peptide is 10 specified, the length of peptide is 10 specified, the length of peptide is 10 amino acids, and the end position amino acids, and the end position amino acids, and the end position for each peptide is the start position for each peptide is the start position for each peptide is the start position plus nine. plus nine. plus nine.
Pos 1234567890 score Pos 1234567890 score Pos 1234567890 score
231 WILVALGVAL 14 445 YGVLGLFWTL 13 368 CIAYWAMTAL 12
233 LVALGVALVL 14 447 VLGLFWTLNW 13 369 IAYWAMTALY 12
240 LVLSLLFILL 14 449 GLFWTLNWVL 13 378 YLATSGQPQY 12
243 SLLFILLLRL 14 460 LGQCVLAGAF 13 381 TSGQPQYVLW 12
250 LRLVAGPLVL 14 478 KPQDIPTFPL 13 395 SSPGCEKVPI 12
252 LVAGPLVLVL 14 483 PTFPLISAFI 13 420 PGLMCVFQGY 12
253 VAGPLVLVLI 14 493 RTLRYHTGSL 13 436 QRSVFNLQIY 12
262 ILGVLGVLAY 14 495 LRYHTGSLAF 13 439 VFNLQIYGVL 12
304 SVQETWLAAL 14 498 HTGSLAFGAL 13 443 QIYGVLGLFW 12
331 RQRIRIAIAL 14 500 GSLAFGALIL 13 456 WVLALGQCVL 12
357 YPLVTFVLLL 14 517 VILEYIDHKL 13 463 CVLAGAFASF 12
431 SKGUQRSVF 14 539 CCFKCCLWCL 13 464 VLAGAFASFY 12
433 GUQRSVFNL 14 557 RNAYIMIAIY 13 488 ISAFIRTLRY 12
467 GAFASFYWAF 14 582 MRNIVRVWL 13 505 GALILTLVQI 12
542 KCCLWCLEKF 14 590 VLDKVTDLLL 13 509 LTLVQIARVI 12
545 LWCLEKFIKF 14 591 LDKVTDLLLF 13 510 TLVQIARVIL 12
551 FIKFLNRNAY 14 592 DKVTDLLLFF 13 548 LEKFIKFLNR 12
569 NFCVSAKNAF 14 606 WGGVGVLSF 13 556 NRNAYIMIAI 12
589 WLDKVTDLL 14 659 FGMCVDTLFL 13 571 CVSAKNAFML 12
595 TDLLLFFGKL 14 661 MCVDTLFLCF 13 572 VSAKNAFMLL 12
627 KDFKSPHLNY 14 662 CVDTLFLCFL 13 576 NAFMLLMRNI 12
629 FKSPHLNYYW 14 671 LEDLERNNGS 13 588 VWLDKVTDL 12
665 TLFLCFLEDL 14 672 EDLERNNGSL 13 604 LLWGGVGVL 12
686 YMSKSLLKIL 14 682 DRPYYMSKSL 13 628 DFKSPHLNYY 12
7 DEDDEAYGKP 13 33 TDVICCVLFL 12 630 KSPHLNYYWL 12
31 SCTDVICCVL 13 37 CCVLFLLFIL 12 650 VIASGFFSVF 12
32 CTDVICCVLF 13 44 FILGYIVVGI 12 674 LERNNGSLDR 12
35 VICCVLFLLF 13 76 GMGENKDKPY 12 676 RNNGSLDRPY 12
49 IWGIVAWLY 13 123 DPWTVGKNEF 12 677 NNGSLDRPYY 12
56 WLYGDPRQVL 13 132 FSQTVGEVFY 12 685 YYMSKSLLKI 12
57 LYGDPRQVLY 13 150 PGVPWNMTVI 12 14 GKPVKYDPSF 11
87 LYFNIFSCIL 13 163 QQELCPSFLL 12 27 IKNRSCTDVI 11
145 RNFCLPGVPW 13 216 DISVKIFEDF 12 40 LFLLFILGYI 11
153 PWNMTVITSL 13 223 EDFAQSWYWI 12 48 YIWGIVAWL 11
186 NVTPPALPGI 13 236 LGVALVLSLL 12 77 MGENKDKPYL 11
237 GVALVLSLLF 13 266 LGVLAYGIYY 12 116 CVSSCPEDPW 11
248 LLLRLVAGPL 13 274 YYCWEEYRVL 12 137 GEVFYTKNRN 11
257 LVLVLILGVL 13 277 WEEYRVLRDK 12 161 SLQQELCPSF 11
271 YGIYYCWEEY 13 286 KGASISQLGF 12 162 LQQELCPSFL 11
301 AYQSVQETWL 13 290 ISQLGFTTNL 12 208 LIDSLNARDI 11
310 LAALIVLAVL 13 300 SAYQSVQETW 12 212 LNARDISVKI 11
315 VLAVLEAILL 13 306 QETWLAALIV 12 221 IFEDFAQSWY 11
327 LIFLRQRIRI 13 313 LIVLAVLEAI 12 238 VALVLSLLFI 11
342 KEASKAVGQM 13 318 VLEAILLLML 12 264 GVLGVLAYGI 11
347 AVGQMMSTMF 13 329 FLRQRIRIAI 12 305 VQETWI-AALI 11
405 NTSCNPTAHL 13 350 QMMSTMFYPL 12 314 IVLAVLEAIL 11
425 VFQGYSSKGL 13 358 PLVTFVLLLI 12 348 VGQMMSTMFY 11
441 NLQIYGVLGL 13 360 VTFVLLLICI 12 413 HLVNSSCPGL 11
TableXLIV-V1-HLA-B4402- 18 LGYVLWASNI 9
10mers-24P4C12 TableXLIV-V6-HLA-B4402- 16 ATLGYVLWAS 8
Each peptide is a portion of SEQ ID 10mers-24P4C12 7 ALYPLPTQPA 7
NO: 3; each start position i is Each peptide is a portion of SEQ ID specified, the length of peptide is 10 NO: 13; each start position is amino acids, and the end position specified, the length of peptide is 10 TableXLVΛ I -HLA-B5101 -1 Omers- for each peptide is the start position amino acids, and the end position 24P4C12 plus nine. for each peptide is the start position Pos 1234567890 score
Pos 1234567890 score plus nine. NoResultsFound.
479 PQDIPTFPLI 11 Pos 1234567890 score
499 TGSLAFGALI 11 7 GLIPRSVFNL 17 TableXLV-V3-HLA-B5101-10mers-
519 LEYIDHKLRG 11 5 SKGLIPRSVF 14 24P4C12
528 GVQNPVARCI 11 10 PRSVFNLQIY 12 Pos 1234567890 score
532 PVARCIMCCF 11 9 IPRSVFNLQI 10 NoResultsFound.
536 CIMCCFKCCL 11
537 IMCCFKCCLW 11 TableXLIV-V7-HLA-B4402- TableXLV-V5-HLA-B5101-10mers-
543 CCLWCLEKFI 11 10mers-24P4C12 24P4C12
552 IKFLNRNAYI 11 Each peptide is a portion of SEQ ID Pos 1234567890 score
607 VGGVGVLSFF 11 NO: 15; each start position is NoResultsFound.
608 GGVGVLSFFF 11 specified, the length of peptide is 10
609 GVGVLSFFFF 11 amino acids, and the end position TableXLV-V6-HLA-B5101 -1 Omers-
625 LGKDFKSPHL 11 for each peptide is the start position 24P4C12
632 PHLNYYWLPI 11 plus nine. Pos 1234567890 score
642 MTSILGAYVI 11 Pos 1234567890 score NoResultsFound.
646 LGAYVIASGF 11 9 AVGQMMSTMF 13
658 VFGMCVDTLF 11 4 YWILVAVGQM 6 TableXLV-V7-HLA-B5101-10mers-
683 RPYYMSKSLL 11 24P4C12
TableXLIV-V8-HLA-B4402- Pos 1234567890 score
TableXLIV-V3-HLA-B4402-1 Omers- 10mers-24P4C12 NoResultsFound. 24P4C12 Each peptide is a portion of SEQ
Each peptide is a portion of SEQ ID ID NO: 17; each start position is TableXLV-V8-HLA-B5101 -1 Omers-
NO: 7; each start position is specified, the length of peptide is 24P4C12 specified, the length of peptide is 10 10 amino acids, and the end Pos 1234567890 score amino acids, and the end position position for each peptide is the NoResultsFound. for each peptide is the start position start position plus nine. plus nine. Pos 1234567890 score TableXLV-V9-HLA-B5101-10mers- Pos 1234567890 score 11 NPITPTGHVF 17 24P4C12 6 PWTNITPPAL 14 4 YWLPIMRNPI 14 Pos 1234567890 score
9 NITPPALPGI 13 19 VFQTSILGAY 14 NoResultsFound.
1 LGRCFPWTNI 8 16 TGHVFQTSIL 11
3 RCFPWTNITP 7 21 QTSILGAYVI 11
8 TNITPPALPG 6 15 PTGHVFQTSI 8
TableXLIV-V5-HLA-B4402-10mers- TableXLIV-V9-HLA-B4402- 24P4C12 10mers-24P4C12
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ
NO: 11 ; each start position is ID NO: 19; each start position is specified, the length of peptide is 10 specified, the length of peptide is amino acids, and the end position for 10 amino acids, and the end each peptide is the start position position for each peptide is the plus nine. start position plus nine. Pos 1234567890 score Pos 1234567890 score
3 LEAILLLVLI 21 9 YPLPTQPATL 16
4 EAILLLVLIF 18 14 QPATLGYVLW 13
5 AILLLVLIFL 17 11 LPTQPATLGY 12 2 VLEAILLLVL 13 13 TQPATLGYVL 12 9 LVLIFLRQRI 10 2 YWAMTALYPL 11
TableXLVI-VI -HLA-DRB1 -0101 - TableXLVI-VI -HLA-DRB1 -0101 - 15mers-24P4C12 15mers-24P4C12
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID
NO: 3; each start position is NO: 3; each start position is specified, the length of peptide is 15 specified, the length of peptide is 15 amino acids, and the end position for amino adds, and the end position for each peptide is the start position plus each peptide is the start position plus fourteen. fourteen. scor scor
Pos 123456789012345 e Pos 123456789012345
227 QSWYWILVALGVALV 39 231 WILVALGVALVLSLL 25
206 SGLIDSLNARDISVK 33 239 ALVLSLLFILLLRLV 25
247 ILLLRLVAGPLVLVL 33 293 LGFTTNLSAYQSVQE 25
313 LIVLAVLEAILLLML 33 299 LSAYQSVQETWLAAL 25
601 FGKLLWGGVGVLSF 33 304 SVQETWLAALIVLAV 25
246 FILLLRLVAGPLVLV 32 319 LEAILLLMUFLRQR 25
262 ILGVLGVLAYGIYYC 32 326 MLIFLRQRIRIAIAL 25
353 STMFYPLVTFVLLLI 32 337 AIALLKEASKAVGQM 25
368 CIAYWAMTALYLATS 32 354 TMFYPLVTFVLLLIC 25
652 ASGFFSVFGMCVDTL 32 371 YWAMTALYLATSGQP 25
39 VLFLLFILGYIVVGI 31 399 CEKVPINTSCNPTAH 25
181 CFPWTNVTPPALPGI 31 451 FWTLNWVLALGQCVL 25
277 WEEYRVLRDKGASIS 31 454 LNWVLALGQCVLAGA 25
559 AYIMIAIYGKNFCVS 31 471 SFYWAFHKPQDIPTF 25
639 LPIMTSILGAYVIAS 31 482 IPTFPLISAFIRTLR 25
85 YLLYFNIFSCILSSN 30 526 LRGVQNPVARCIMCC 25
89 FNIFSCILSSNIISV 30 583 RNIVRWVLDKVTDL 25
257 LVLVLILGVLGVLAY 30 603 KLLWGGVGVLSFFF 25
259 LVLILGVLGVLAYGI 30 51 VGIVAWLYGDPRQVL 24
635 NYYWLPIMTSILGAY 30 97 SSNIISVAENGLQCP 24
646 LGAYVIASGFFSVFG 30 229 WYWILVALGVALVLS 24
235 ALGVALVLSLLFILL 29 238 VALVLSLLFILLLRL 24
345 SKAVGQMMSTMFYPL 29 255 GPLVLVLILGVLGVL 24
40 LFLLFILGYIWGIV 28 256 PLVLVLILGVLGVLA 24
242 LSLLFILLLRLVAGP 28 279 EYRVLRDKGASISQL 24
359 LVTFVLLLICIAYWA 28 307 ETWLAALIVLAVLEA 24
453 TLNWVLALGQCVLAG 28 310 LAALIVLAVLEAILL 24
612 VLSFFFFSGRIPGLG 28 383 GQPQYVLWASNISSP 24
640 PIMTSILGAYVIASG 28 420 PGLMCVFQGYSSKGL 24
167 CPSFLLPSAPALGRC 27 459 ALGQCVLAGAFASFY 24
243 SLLFILLLRLVAGPL 27 506 ALILTLVQIARVILE 24
280 YRVLRDKGASISQLG 27 523 DHKLRGVQNPVARCI 24
362 FVLLLICIAYWAMTA 27 569 NFCVSAKNAFMLLMR 24
423 MCVFQGYSSKGLIQR 27 579 MLLMRNIVRVWLDK 24
501 SLAFGALILTLVQIA 27 588 VWLDKVTDLLLFFG 24
575 KNAFMLLMRNIVRVV 27 607 VGGVGVLSFFFFSGR 24
129 KNEFSQTVGEVFYTK 26 644 SILGAYVIASGFFSV 24
230 YWILVALGVALVLSL 26 660 GMCVDTLFLCFLEDL 24
254 AGPLVLVULGVLGV 26 47 GYIWGIVAWLYGDP 23
384 QPQYVLWASNISSPG 26 59 GDPRQVLYPRNSTGA 23
436 QRSVFNLQIYGVLGL 26 165 ELCPSFLLPSAPALG 23
437 RSVFNLQIYGVLGLF 26 166 LCPSFLLPSAPALGR 23
448 LGLFWTLNWVU.LGQ 26 241 VLSLLFILLLRLVAG 23
492 IRTLRYHTGSLAFGA 26 374 MTALYLATSGQPQYV 23
551 FIKFLNRNAYIMIAI 26 412 AHLVNSSCPGLMCVF 23
594 VTDLLLFFGKLLWG 26 507 LILTLVQIARVILEY 23
633 HLNYYWLPIMTSILG 26 508 ILTLVQIARVILEYI 23
688 SKSLLKILGKKNEAP 26 566 YGKNFCVSAKNAFML 23
44 FILGYIVVGIVAWLY 25 604 LLWGGVGVLSFFFF 23
53 IVAWLYGDPRQVLYP 25 636 YYWLPIMTSILGAYV 23
62 RQVLYPRNSTGAYCG 25 33 TDVICCVLFLLFILG 22
90 NIFSCILSSNIISVA 25 43 LFILGYIWGIVAWL 22
228 SWYWILVALGVALVL 25 86 LLYFNIFSCILSSNI 22
TableXLVI-V1-HLA-DRB1 -0101 - TableXLVI-VI -HLA-DRB1 -0101 - 15mers-24P4C12 15mers-24P4C12
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID
NO: 3; each start position is NO: 3; each start position is specified, the length of peptide is 15 specified, the length of peptide is 15 amino acids, and the end position for amino acids, and the end position for each peptide is the start position plus each peptide is the start position plus fourteen. fourteen. scor
Pos 123456789012345 ! 6789012345 e P Pooss 1 1223344556789012345 scor e
160 TSLQQELCPSFLLPS 22 411 TAHLVNSSCPGLMCV 19
198 DTTIQQGISGLIDSL 22 442 LQIYGVLGLFWTLNW 19
312 ALIVLAVLEAILLLM 22 460 LGQCVLAGAFASFYW 19
316 LAVLEAILLLMLIFL 22 495 LRYHTGSLAFGALIL 19
349 GQMMSTMFYPLVTFV 22 503 AFGALILTLVQIARV 19
363 VLLLICIAYWAMTAL 22 557 RNAYIMIAIYGKNFC 19
419 CPGLMCVFQGYSSKG 22 586 VRVWLDKVTDLLLF 19
439 VFNLQIYGVLGLFWT 22 683 RPYYMSKSLLKILGK 19
441 NLQIYGVLGLFWTLN 22 684 PYYMSKSLLKILGKK 19
458 LALGQCVLAGAFASF 22
481 DIPTFPLISAFIRTL 22 TableXLVI-V3-HLA-DRB1-0101.
511 LVQIARVILEYIDHK 22 15mers-24P4C12
587 RWVLDKVTDLLLFF 22 Each peptide is a portion of SEQ ID NO:
598 LLFFGKLLWGGVGV 22 7; each start position is specified, the
655 FFSVFGMCVDTLFLC 22 length of peptide is 15 amino acids, and
689 KSLLKILGKKNEAPP 22 the end position for each peptide is the
138 EVFYTKNRNFCLPGV 21 start position plus fourteen.
151 GVPWNMTVITSLQQE 21 Pos 123456789012345 score
153 PWNMTVITSLQQELC 21 9 CFPWTNITPPALPGI 31
203 QGISGLIDSLNARDI 21 7 GRCFPWTNITPPALP 19
300 SAYQSVQETWLAALI 21 12 WTNITPPALPGITND 19
329 FLRQRIRIAIALLKE 21 10 FPWTNITPPALPGIT 18
331 RQRIRIAIALLKEAS 21 14 NITPPALPGITNDTT 16
409 NPTAHLVNSSCPGLM 21
518 ILEYIDHKLRGVQNP 21 TableXLVI-V5-HLA-DRB1-0101-
548 LEKFIKFLNRNAYIM 21 15mers-24P4C12
606 WGGVGVLSFFFFSG 21 Each peptide is a portion of SEQ ID NO:
10 DEAYGKPVKYDPSFR 20 11; each start position is specified, the
20 DPSFRGPIKNRSCTD 20 length of peptide is 15 amino adds, and
272 GIYYCWEEYRVLRDK 20 the end position for each peptide is the
333 RIRIAIALLKEASKA 20 start position plus fourteen.
449 GLFWTLNWVLALGQC 20 Pos 123456789012345 score
476 FHKPQDIPTFPLISA 20 2 LIVLAVLEAILLLVL 33
543 CCLWCLEKFIKFLNR 20 8 LEAILLLVLIFLRQR 25
563 IAIYGKNFCVSAKNA 20 15 VLIFLRQRIRIAIAL 25
599 LFFGKLLWGGVGVL 20 I ALIVLAVLEAILLLV 22
614 SFFFFSGRIPGLGKD 20 5 LAVLEAILLLVLIFL 22
634 LNYYWLPIMTSILGA 20 6 AVLEAILLLVLIFLR 19
645 ILGAYVIASGFFSVF 20 12 LLLVLIFLRQRIRIA 19
656 FSVFGMCVDTLFLCF 20 13 LLVLIFLRQRIRIAI 18
657 SVFGMCVDTLFLCFL 20 7 VLEAILLLVLIFLRQ 17
37 CCVLFLLFILGYIW 19 II ILLLVLIFLRQRIRI 17
38 CVLFLLFILGYIWG 19 14 LVLIFLRQRIRIAIA 17
82 DKPYLLYFNIFSCIL 19 4 VLAVLEAILLLVLIF 16
122 EDPWTVGKNEFSQTV 19 10 AILLLVUFLRQRIR 16
179 GRCFPWTNVTPPALP 19
184 WTNVTPPALPGITND 19 TableXLVI-V6-HLA-DRB1-0101-
245 LFILLLRLVAGPLVL 19 15mers-24P4C12
271 YGIYYCWEEYRVLRD 19
317 AVLEAILLLMLIFLR 19
323 LLLMLIFLRQRIRIA 19
336 IAIALLKEASKAVGQ 19
369 lAYWAMTALYLATSG 19
Each peptide is a portion of SEQ ID Each peptide is a portion of SEQ ID NO:
NO: 13; each start position is 19; each start position is specified, the specified, the length of peptide is 15 length of peptide is 15 amino acids, and amino aαds, and the end position for the end position for each peptide is the each peptide is the start position plus start position plus fourteen. fourteen. Pos 123456789012345 score
Pos 123456789012345 score 4 CIAYWAMTALYPLPT 32
2 MCVFQGYSSKGLIPR 27 10 MTALYPLPTQPATLG 30
15 PRSVFNLQIYGVLGL 26 22 TLGYVLWASNISSPG 26
7 GYSSKGLIPRSVFNL 24 21 ATLGYVLWASNISSP 24 4 VFQGYSSKGLIPRSV 16 7 YWAMTALYPLPTQPA 23
10 SKGLIPRSVFNLQIY 16 13 LYPLPTQPATLGYVL 23 12 GLIPRSVFNLQIYGV 16 5 IAYWAMTALYPLPTQ 19 1 LMCVFQGYSSKGLIP 15 2 LICIAYWAMTALYPL 17
8 YSSKGLIPRSVFNLQ 15 1 LLICIAYWAMTALYP 16 16 LPTQPATLGYVLWAS 16
TableXLVI-V7-HLA-DRB1-0101- 23 LGYVLWASNISSPGC 16 15mers-24P4C12 24 GYVLWASNISSPGCE 16
Each peptide is a portion of SEQ ID 9 AMTALYPLPTQPATL 15 NO: 15; each start position is specified, the length of peptide is 15 amino adds, TableXLVII-V1 -HLA-DRB1 -0301 - and the end position for each peptide is 15mers-24P4C12 the start position plus fourteen. Each peptide is a portion of SEQ ID NO: Pos 123456789012345 score 3; each start position is specified, the
6 QSWYWILVAVGQMMS 31 length of peptide is 15 amino acids, and 12 LVAVGQMMSTMFYPL 29 the end position for each peptide is the
7 SWYWILVAVGQMMST 25 start position plus fourteen.
8 WYWILVAVGQMMSTM 24 Pos 123456789012345 score
9 YWILVAVGQMMSTMF 24 54 VAWLYGDPRQVLYPR 36 1 FEDFAQSWYWILVAV 18 586 VRWVLDKVTDLLLF 31 5 AQSWYWILVAVGQMM 16 667 FLCFLEDLERNNGSL 29
11 ILVAVGQMMSTMFYP 15 312 ALIVLAVLEAILLLM 28
97 SSNIISVAENGLQCP 27
TableXLVI-V8-HLA-DRB1 -0101- 155 NMTVITSLQQELCPS 27
15mers-24P4C12 454 LNWVLALGQCVLAGA 27
Each peptide is a portion of SEQ ID NO: 549 EKFIKFLNRNAYIMI 27
17; each start position is specified, the 136 VGEVFYTKNRNFCLP 26 length of peptide is 15 amino acids, and 508 ILTLVQIARVILEYI 26 the end position for each peptide is the 622 IPGLGKDFKSPHLNY 26 start position plus fourteen. 376 ALYLATSGQPQYVLW 25
Pos 123456789012345 score 447 VLGLFWTLNWVLALG 25
24 VFQTSILGAYVIASG 28 279 EYRVLRDKGASISQL 24
7 NYYWLPIMRNPITPT 24 534 ARCIMCCFKCCLWCL 24
23 HVFQTSILGAYVIAS 23 567 GKNFCVSAKNAFMLL 24
6 LNYYWLPIMRNPITP 20 229 WYWiLVALGVALVLS 23
5 HLNYYWLPIMRNPIT 18 238 VALVLSLLFILLLRL 23
21 TGHVFQTSILGAYVI 18 14 GKPVKYDPSFRGPIK 22
3 SPHLNYYWLPIMRNP 17 218 SVKIFEDFAQSWYWI 22
8 YYWLPIMRNPITPTG 17 219 VKIFEDFAQSWYWIL 22
13 IMRNPITPTGHVFQT 17 235 ALGVALVLSLLFILL 22
11 LPIMRNPITPTGHVF 16 241 VLSLLFILLLRLVAG 22
12 PIMRNPITPTGHVFQ 16 360 VTFVLLLICIAYWAM 22
14 MRNPITPTGHVFQTS 16 515 ARVILEYIDHKLRGV 22
26 QTSILGAYVIASGFF 16 594 VTDLLLFFGKLLWG 22
9 YWLPIMRNPITPTGH 15 33 TDVICCVLFLLFILG 21
18 ITPTGHVFQTSILGA 15 167 CPSFLLPSAPALGRC 21
19 TPTGHVFQTSILGAY 14 192 LPGITNDTTIQQGIS 21
20 PTGHVFQTSILGAYV 14 237 GVALVLSLLFILLLR 21
239 ALVLSLLFILLLRLV 21
TableXLVI-V9-HLA-DRB1 -0101 • 260 VLILGVLGVLAYGIY 21 15mers-24P4C12 302 YQSVQETWLAALIVL 21 319 LEAILLLMUFLRQR 21 431 SKGLIQRSVFNLQIY 21
TableXLVII-VI -HLA-DRB1 -0301 - TableXLVII-V1 -HLA-DRB1 -0301 - 15mers-24P4C12 15mers-24P4C12
Each peptide is a portion of SEQ ID NO: Each peptide is a portion of SEQ ID NO:
3; each start position is specified, the 3; each start position is specified, the lengtti of peptide is 15 amino acids, and length of peptide is 15 amino acids, and the end position for each peptide is the the end position for each peptide is the start position plus fourteen. start position plus fourteen.
Pos 123456789012345 score Pos 123456789012345 score
461 GQCVLAGAFASFYWA 21 462 QCVLAGAFASFYWAF 18
587 RVWLDKVTDLLLFF 21 530 QNPVARCIMCCFKCC 18 590 VLDKVTDLLLFFGKL 21 560 YIMIAIYGKNFCVSA 18 595' TDLLLFFGKLLVVGG 21 569 NFCVSAKNAFMLLMR 18 658 VFGMCVDTLFLCFLE 21 579 MLLMRNIVRVWLDK 18 32 CTDVICCVLFLLFIL 20 585 IVRVWLDKVTDLLL 18 37 CCVLFLLFILGYIW 20 655 FFSVFGMCVDTLFLC 18
46 LGYIWGIVAWLYGD 20 656 FSVFGMCVDTLFLCF 18
47 GYIWGIVAWLYGDP 20 660 GMCVDTLFLCFLEDL 18 74 YCGMGENKDKPYLLY 20 664 DTLFLCFLEDLERNN 18 76 GMGENKDKPYLLYFN 20 284 RDKGASISQLGFTTN 17 231 WILVALGVALVLSLL 20 290 ISQLGFTTNLSAYQS 17 233 LVALGVALVLSLLFI 20 324 LLMLIFLRQRIRIAI 17 246 FILLLRLVAGPLVLV 20 325 LMLIFLRQRIRIAIA 17 250 LRLVAGPLVLVLILG 20 353 STMFYPLVTFVLLLI 17 255 GPLVLVLILGVLGVL 20 423 MCVFQGYSSKGLIQR 17 258 VLVLILGVLGVLAYG 20 437 RSVFNLQIYGVLGLF 17 313 LIVLAVLEAILLLML 20 485 FPLISAFIRTLRYHT 17 316 LAVLEAILLLMLIFL 20 517 VILEYIDHKLRGVQN 17 323 LLLMLIFLRQRIRIA 20 519 LEYIDHKLRGVQNPV 17 338 IALLKEASKAVGQMM 20 523 DHKLRGVQNPVARCI 17 411 TAHLVNSSCPGLMCV 20 542 KCCLWCLEKFIKFLN 17 439 VFNLQIYGVLGLFWT 20 545 LWCLEKFIKFLNRNA 17 484 TFPLISAFIRTLRYH 20 548 LEKFIKFLNRNAYIM 17 559 AYIMIAIYGKNFCVS 20 614 SFFFFSGRIPGLGKD 17
588 VWLDKVTDLLLFFG 20 619 SGRIPGLGKDFKSPH 17 602 GKLLWGGVGVLSFF 20 670 FLEDLERNNGSLDRP 17 604 LLWGGVGVLSFFFF 20 692 LKILGKKNEAPPDNK 17 691 LLKILGKKNEAPPDN 20 156 MTVITSLQQELCPSF 19 TableXLVII-V3-HLA-DRB1.0301-15mers- 159 ITSLQQELCPSFLLP 19 24P4C12 205 ISGUDSLNARDISV 19 Each peptide is a portion of SEQ ID NO: 335 RIAIALLKEASKAVG 19 7; each start position is specified, the 348 VGQMMSTMFYPLVTF 19 length of peptide is 15 amino acids, and 366 LICIAYWAMTALYLA 19 the end position for each peptide is the 385 PQYVLWASNISSPGC 19 start position plus fourteen. 505 GALILTLVQIARVIL 19 Pos 123456789012345 score 576 NAFMLLMRNIVRVW 19 12 WTNITPPALPGITND 12 607 VGGVGVLSFFFFSGR 19 3 APALGRCFPWTNITP 10 626 GKDFKSPHLNYYWLP 19 9 CFPWTNITPPALPGI 10 638 WLPIMTSILGAYVIA 19 7 GRCFPWTNITPPALP 8 648 AYVIASGFFSVFGMC 19 6 LGRCFPWTNITPPAL 7 663 VDTLFLCFLEDLERN 19 668 LCFLEDLERNNGSLD 19 684 PYYMSKSLLKILGKK 19 TableXLVII-V5-HLA-DRB1-0301- 689 KSLLKILGKKNEAPP 19 15mers-24P4C12
3 GKQRDEDDEAYGKPV 18 Each peptide is a portion of SEQ ID NO:
61 PRQVLYPRNSTGAYC 18 11 ; each start position is spedfied, the
98 SNIISVAENGLQCPT 18 length of peptide is 15 amino acids, and
114 QVCVSSCPEDPWTVG 18 the end position for each peptide is the
214 ARDISVKIFEDFAQS 18 start position plus fourteen.
243 SLLFILLLRLVAGPL 18 Pos 123456789012345 score
263 LGVLGVLAYGIYYCW 18 1 ALIVLAVLEAILLLV 28
327 LIFLRQRIRIAIALL 18 8 LEAILLLVUFLRQR 21
345 SKAVGQMMSTMFYPL 18 2 LIVLAVLEAILLLVL 20
TableXLVII-V5-HLA-DRB1 -0301 - 14 MRNPITPTGHVFQTS 9 15mers-24P4C12 19 TPTGHVFQTSILGAY 8
Each peptide is a portion of SEQ ID NO:
11 ; each start position is specified, the TableXLVII-V9-HLA-DRB1-0301-15mers- length of peptide is 15 amino adds, and 24P4C12 the end position for each peptide is the Each peptide is a portion of SEQ ID NO: start position plus fourteen. 19; each start position is specified, the
Pos 123456789012345 score length of peptide is 15 amino acids, and the
5 LAVLEAILLLVLIFL 20 end position for each peptide is the start
12 LLLVLIFLRQRIRIA 20 position plus fourteen.
13 LLVLIFLRQRIRIAI 17 Pos 123456789012345 score
14 LVLIFLRQRIRIAIA 17 2 LICIAYWAMTALYPL 19
4 VLAVLEAILLLVLIF 15 23 LGYVLWASNISSPGC 19
9 EAILLLVLIFLRQRI 15 10 MTALYPLPTQPATLG 13
10 AILLLVLIFLRQRIR 13 7 YWAMTALYPLPTQPA 12
12 ALYPLPTQPATLGYV 12
TableXLVII-V6-HLA-DRB1-0301- 13 LYPLPTQPATLGYVL 12 15mers-24P4C12 20 PATLGYVLWASNISS 12
Each peptide is a portion of SEQ ID NO: 3 ICIAYWAMTALYPLP 10 13; each start position is specified, the 14 YPLPTQPATLGYVLW 10 length of peptide is 15 amino acids, and 24 GYVLWASNISSPGCE 10 the end position for each peptide is the 5 IAYWAMTALYPLPTQ 9 start position plus fourteen. 16 LPTQPATLGYVLWAS 9
Pos 123456789012345 score
10 SKGLIPRSVFNLQIY 22 TableXLVIII-VI -DR1 -0401-15mers-
2 MCVFQGYSSKGLIPR 17 24P4C12
8 YSSKGLIPRSVFNLQ 16 Each peptide is a portion of SEQ ID NO:
11 KGLIPRSVFNLQIYG 12 3; each start position is specified, the
1 LMCVFQGYSSKGLIP 11 length of peptide is 15 amino acids, and
15 PRSVFNLQIYGVLGL 10 the end position for each peptide is the start position plus fourteen.
TableXLVH-V7-HLA-DRB1-0301-15mers- Pos 123456789012345 score 24P4C12 85 YLLYFNIFSCILSSN 28
Each peptide is a portion of SEQ ID NO: 89 FNIFSCILSSNIISV 28
15; each start position is specified, the 243 SLLFILLLRLVAGPL 28 length of peptide is 15 amino acids, and 353 STMFYPLVTFVLLLI 28 the end position for each peptide is the 469 FASFYWAFHKPQDIP 28 start position plus fourteen. 548 LEKFIKFLNRNAYIM 28
Pos 123456789012345 score 575 KNAFMLLMRNIVRW 28
9 YWILVAVGQMMSTMF 18 635 NYYWLPIMTSILGAY 28
12 LVAVGQMMSTMFYPL 18 54 VAWLYGDPRQVLYPR 26 1 FEDFAQSWYWILVAV 16 98 SNIISVAENGLQCPT 26 8 WYWILVAVGQMMSTM 13 153 PWNMTVITSLQQELC 26
10 WILVAVGQMMSTMFY 10 189 PPALPGITNDTTIQQ 26
13 VAVGQMMSTMFYPLV 10 192 LPGITNDTTIQQGIS 26 323 LLLMLIFLRQRIRIA 26
TableXLVII-V8-HLA-DRB1-0301-15mers- 337 AIALLKEASKAVGQM 26 24P4C12 385 PQYVLWASNISSPGC 26
Each peptide is a portion of SEQ ID NO: 419 CPGLMCVFQGYSSKG 26 17; each start position is specified, the 454 LNWVLALGQCVLAGA 26 length of peptide is 15 amino adds, and 508 ILTLVQIARVILEYI 26 the end position for each peptide is the 523 DHKLRGVQNPVARCI 26 start position plus fourteen. 579 MLLMRNIVRVWLDK 26
Pos 123456789012345 score 16 PVKYDPSFRGPIKNR 22
22 GHVFQTSILGAYVIA 17 38 CVLFLLFILGYIWG 22
8 YYWLPIMRNPITPTG 16 82 DKPYLLYFNIFSCIL 22
15 RNPITPTGHVFQTSI 14 86 LLYFNIFSCILSSNI 22
26 QTSILGAYVIASGFF 13 122 EDPWTVGKNEFSQTV 22
21 TGHVFQTSILGAYVI 12 138 EVFYTKNRNFCLPGV 22
10 WLPIMRNPITPTGHV 11 181 CFPWTNVTPPALPGI 22
11 LPIMRNPITPTGHVF 11 219 VKIFEDFAQSWYWIL 22
3 SPHLNYYWLPIMRNP 10 227 QSWYWILVALGVALV 22
7 NYYWLPIMRNPITPT 10 228 SWYWILVALGVALVL 22
TableXLVIII rl -DR1 -0401 -15mere- TableXLVIII-V1 -DR1 -0401-15mers- 24P4C12 24P4C12
Each peptide is a portion of SEQ ID NO: Each peptide is a portion of SEQ ID NO:
3; each start position is specified, the 3; each start position is specified, the length of peptide is 15 amino acids, and length of peptide is 15 amino acids, and the end position for each peptide is the the end position for each peptide is the start position plus fourteen. start position plus fourteen.
Pos 123456789012345 score Pos 123456789012345 score
272 GIYYCWEEYRVLRDK 22 312 ALIVLAVLEAILLLM 20
277 WEEYRVLRDKGASIS 22 313 UVLAVLEAILLLML 20
292 QLGFTTNLSAYQSVQ 22 315 VLAVLEAILLLMLIF 20
299 LSAYQSVQETWLAAL 22 316 LAVLEAILLLMLIFL 20
306 QETWLAALIVLAVLE 22 319 LEAILLLMLIFLRQR 20 354 TMFYPLVTFVLLLIC 22 321 AILLLMLIFLRQRIR 20 359 LVTFVLLLICIAYWA 22 324 LLMLIFLRQRIRIAI 20 384 QPQYVLWASNISSPG , 22 331 RQRIRIAIALLKEAS 20 423 MCVFQGYSSKGLIQR 22 333 RIRIAIALLKEASKA 20 442 LQIYGVLGLFWTLNW 22 335 RIAIALLKEASKAVG 20 448 LGLFWTLNWVLALGQ 22 356 FYPLVTFVLLLICIA 20 453 TLNWVLALGQCVLAG 22 363 VLLLICIAYWAMTAL 20 488 ISAFIRTLRYHTGSL 22 364 LLLICIAYWAMTALY 20 501 SLAFGALILTLVQIA 22 371 YWAMTALYLATSGQP 20 557 RNAYIMIAIYGKNFC 22 374 MTALYLATSGQPQYV 20 633 HLNYYWLPIMTSILG 22 401 KVPINTSCNPTAHLV 20 646 LGAYVIASGFFSVFG 22 420 PGLMCVFQGYSSKGL 20 652 ASGFFSVFGMCVDTL 22 436 QRSVFNLQIYGVLGL 20 667 FLCFLEDLERNNGSL 22 444 IYGVLGLFWTLNWVL 20 682 DRPYYMSKSLLKILG 22 445 YGVLGLFWTLNWVLA 20 14 GKPVKYDPSFRGPIK 20 447 VLGLFWTLNWVLALG 20
39 VLFLLFILGYIVVGI 20 451 FWTLNWVLALGQCVL 20
40 LFLLFILGYIWGIV 20 479 PQDIPTFPLISAFIR 20 43 LFILGYIWGIVAWL 20 484 TFPLISAFIRTLRYH 20 97 SSNIISVAENGLQCP 20 485 FPLISAFIRTLRYHT 20 133 SQTVGEVFYTKNRNF 20 505 GALILTLVQIARVIL 20 146 NFCLPGVPWNMTVIT 20 506 ALILTLVQIARVILE 20 149 LPGVPWNMTVITSLQ 20 511 LVQIARVILEYIDHK 20
155 NMTVITSLQQELCPS 20 514 IARVILEYIDHKLRG 20
156 MTVITSLQQELCPSF 20 516 RVILEYIDHKLRGVQ 20 198 DTTIQQGISGLIDSL 20 542 KCCLWCLEKFIKFLN 20 202 QQGISGLIDSLNARD 20 545 LWCLEKFIKFLNRNA 20 206 SGLIDSLNARDISVK 20 549 EKFIKFLNRNAYIMI 20 216 DISVKIFEDFAQSWY 20 558 NAYIMIAIYGKNFCV 20
229 WYWILVALGVALVLS 20 582 MRNIVRVWLDKVTD 20
230 YWILVALGVALVLSL 20 583 RNIVRVWLDKVTDL 20 233 LVALGVALVLSLLFI 20 586 VRVWLDKVTDLLLF 20 235 ALGVALVLSLLFILL 20 588 VWLDKVTDLLLFFG 20
238 VALVLSLLFILLLRL 20 594 VTDLLLFFGKLLWG 20
239 ALVLSLLFILLLRLV 20 595 TDLLLFFGKLLWGG 20
241 VLSLLFILLLRLVAG 20 601 FGKLLWGGVGVLSF 20
242 LSLLFILLLRLVAGP 20 619 SGRIPGLGKDFKSPH 20
246 FILLLRLVAGPLVLV 20 639 LPIMTSILGAYVIAS 20
247 ILLLRLVAGPLVLVL 20 642 MTSILGAYVIASGFF 20
254 AGPLVLVLILGVLGV 20 660 GMCVDTLFLCFLEDL 20
255 GPLVLVLILGVLGVL 20 668 LCFLEDLERNNGSLD 20 257 LVLVLILGVLGVLAY 20 688 SKSLLKILGKKNEAP 20 259 LVLILGVLGVLAYGI 20 90 NIFSCILSSNIISVA 18 262 ILGVLGVLAYGIYYC 20 125 WTVGKNEFSQTVGEV 18 279 EYRVLRDKGASISQL 20 152 VPWNMTVITSLQQEL 18 287 GASISQLGFTTNLSA 20 166 LCPSFLLPSAPALGR 18 290 ISQLGFTTNLSAYQS 20 195 ITNDπiQQGISGLI 18
307 ETWLAALIVLAVLEA 20 203 QGISGLIDSLNARDI 18
310 LAALIVLAVLEAILL 20 210 DSLNARDISVKIFED 18
311 AALIVLAVLEAILLL 20 289 SISQLGFTTNLSAYQ 18
TableXLVIII-V1 -DR1 -0401 -15mers- TableXLVIII-V1-DR1-0401-15mers- 24P4C12 24P4C12
Each peptide is a portion of SEQ ID NO: Each peptide is a portion of SEQ ID NO:
3; each start position is specified, the 3; each start position is specified, the length of peptide is 15 amino acids, and length of peptide is 15 amino acids, and the end position for each peptide is the the end position for each peptide is the start position plus fourteen. start position plus fourteen.
Pos 123456789012345 score Pos 123456789012345 score
295 FTTNLSAYQSVQETW 18 36 ICCVLFLLFILGYIV 14
342 KEASKAVGQMMSTMF 18 37 CCVLFLLFILGYIVV 14
373 AMTALYLATSGQPQY 18 42 LLFILGYIWGIVAW 14
398 GCEKVPINTSCNPTA 18 46LGYIV VGIVAWLYGD 14
428 GYSSKGLIQRSVFNL 18 47 GYIWGIVAWLYGDP 14
433 GLIQRSVFNLQIYGV 18 48 YIWGIVAWLYGDPR 14
476 FHKPQDIPTFPLISA 18 51 VGIVAWLYGDPRQVL 14
481 DIPTFPLISAFIRTL 18 61 PRQVLYPRNSTGAYC 14
502 LAFGALILTLVQIAR 18 83 KPYLLYFNIFSCILS 14
527 RGVQNPVARCIMCCF 18 84 PYLLYFNIFSCILSS 14
568 KNFCVSAKNAFMLLM 18 88 YFNIFSCILSSNIIS 14
611 GVLSFFFFSGRIPGL 18 92 FSCILSSNIISVAEN 14
623 PGLGKDFKSPHLNYY 18 93 SCILSSNIISVAENG 14
657 SVFGMCVDTLFLCFL 18 124 PWTVGKNEFSQTVGE 14
669 CFLEDLERNNGSLDR 18 136 VGEVFYTKNRNFCLP 14
20 DPSFRGPIKNRSCTD 16 159 ITSLQQELCPSFLLP 14
45 ILGYIVVGIVAWLYG 16 163 QQELCPSFLLPSAPA 14
53 IVAWLYGDPRQVLYP 16 169 SFLLPSAPALGRCFP 14
55 AWLYGDPRQVLYPRN 16 175 APALGRCFPWTNVTP 14
63 QVLYPRNSTGAYCGM 16 184 WTNVTPPALPGITND 14
144 NRNFCLPGVPWNMTV 16 205 ISGLIDSLNARDISV 14
151 GVPWNMTVITSLQQE 16 218 SVKIFEDFAQSWYWI 14
167 CPSFLLPSAPALGRC 16 231 WILVALGVALVLSLL 14
222 FEDFAQSWYWILVAL 16 237 GVALVLSLLFILLLR 14
226 AQSWYWILVALGVAL 16 244 LLFILLLRLVAGPLV 14
271 YGIYYCWEEYRVLRD 16 249 LLRLVAGPLVLVLIL 14
326 MLIFLRQRIRIAIAL 16 250 LRLVAGPLVLVLILG 14
368 CIAYWAMTALYLATS 16 256 PLVLVLILGVLGVLA 14
369 IAYWAMTALYLATSG 16 258 VLVLILGVLGVLAYG 14
375 TALYLATSGQPQYVL 16 260 VLILGVLGVLAYGIY 14
387 YVLWASNISSPGCEK 16 263 LGVLGVLAYGIYYCW 14
437 RSVFNLQIYGVLGLF 16 296 TTNLSAYQSVQETWL 14
449 GLFWTLNWVLALGQC 16 302 YQSVQETWLAALIVL 14
466 AGAFASFYWAFHKPQ 16 322 ILLLMLIFLRQRIRI 14
470 ASFYWAFHKPQDIPT 16 338 IALLKEASKAVGQMM 14
471 SFYWAFHKPQDIPTF 16 345 SKAVGQMMSTMFYPL 14
473 YWAFHKPQDIPTFPL 16 348 VGQMMSTMFYPLVTF 14
482 IPTFPLISAFIRTLR 16 349 GQMMSTMFYPLVTFV 14
518 ILEYIDHKLRGVQNP 16 352 MSTMFYPLVTFVLLL 14
543 CCLWCLEKFIKFLNR 16 357 YPLVTFVLLLICIAY 14
563 IAIYGKNFCVSAKNA 16 360 VTFVLLLICIAYWAM 14
598 LLFFGKLLWGGVGV 16 361 TFVLLLICIAYWAMT 14
612 VLSFFFFSGRIPGLG 16 362 FVLLLICIAYWAMTA 14
613 LSFFFFSGRIPGLGK 16 366 LICIAYWAMTALYLA 14
614 SFFFFSGRIPGLGKD 16 376 ALYLATSGQPQYVLW 14
634 LNYYWLPIMTSILGA 16 391 ASNISSPGCEKVPIN 14
653 SGFFSVFGMCVDTLF 16 399 CEKVPINTSCNPTAH 14
664 DTLFLCFLEDLERNN 16 411 TAHLVNSSCPGLMCV 14
62 RQVLYPRNSTGAYCG 15 412 AHLVNSSCPGLMCVF 14
325 LMLIFLRQRIRIAIA 15 422 LMCVFQGYSSKGLIQ 14
327 LIFLRQRIRIAIALL 15 432 KGLIQRSVFNLQIYG 14
519 LEYIDHKLRGVQNPV 15 439 VFNLQIYGVLGLFWT 14
587 RVWLDKVTDLLLFF 15 441 NLQIYGVLGLFWTLN 14
32 CTDVICCVLFLLFIL 14 455 NWVLALGQCVLAGAF 14
33 TDVICCVLFLLFILG 14 457 VLALGQCVLAGAFAS 14
TableXLVIII-V1-DR1-0401-15mers- Each peptide is a portion of SEQ ID NO:
24P4C12 11; each start position is specified, the
Each peptide is a portion of SEQ ID NO: length of peptide is 15 amino acids, and
3; each start position is specified, the the end position for each peptide is the length of peptide is 15 amino adds, and start position plus fourteen. the end position for each peptide is the Pos 123456789012345 score start position plus fourteen. 12 LLLVLIFLRQRIRIA 26
Pos 123456789012345 score 1 ALIVLAVLEAILLLV 20
462 QCVLAGAFASFYWAF 14 2 LIVLAVLEAILLLVL 20
489 SAFIRTLRYHTGSLA 14 4 VLAVLEAILLLVUF 20
492 IRTLRYHTGSLAFGA 14 5 LAVLEAILLLVUFL 20
499 TGSLAFGALILTLVQ 14 8 LEAILLLVLIFLRQR 20
504 FGALILTLVQIARVI 14 10 AILLLVLIFLRQRIR 20
509 LTLVQIARVILEYID 14 13 LLVLIFLRQRIRIAI 20
515 ARVILEYIDHKLRGV 14 15 VLIFLRQRIRIAIAL 16
526 LRGVQNPVARCIMCC 14 14 LVLIFLRQRIRIAIA 15
534 ARCIMCCFKCCLWCL 14 9 EAILLLVLIFLRQRI 14
535 RCIMCCFKCCLWCLE 14 11 ILLLVLIFLRQRIRI 14
552 IKFLNRNAYIMIAIY 14 3 IVLAVLEAILLLVLI 12
559 AYIMIAIYGKNFCVS 14 6 AVLEAILLLVLIFLR 12
576 NAFMLLMRNIVRVW 14
578 FMLLMRNIVR WLD 14 TableXLVIII-V6-HLA-DR1 -0401-15mers-
585 IVRVWLDKVTDLLL 14 24P4C12
591 LDKVTDLLLFFGKLL 14 Each peptide is a portion of SEQ ID NO:
596 DLLLFFGKLLVVGGV 14 13; each start position is specified, the
602 GKLLVVGGVGVLSFF 14 length of peptide is 15 amino acids, and
603 KLLWGGVGVLSFFF 14 the end position for each peptide is the
604 LLWGGVGVLSFFFF 14 start position plus fourteen.
607 VGGVGVLSFFFFSGR 14 Pos 123456789012345 score
609 GVGVLSFFFFSGRIP 14 2 MCVFQGYSSKGLIPR 22
610 VGVLSFFFFSGRIPG 14 15 PRSVFNLQIYGVLGL 20
622 IPGLGKDFKSPHLNY 14 12 GLIPRSVFNLQIYGV 18
631 SPHLNYYWLPIMTSI 14 I - LMCVFQGYSSKGLIP 14
636 YYWLPIMTSILGAYV 14 II KGLIPRSVFNLQIYG 14
647 GAYVIASGFFSVFGM 14 7 GYSSKGLIPRSVFNL 12
655 FFSVFGMCVDTLFLC 14 8 YSSKGLIPRSVFNLQ 12
658 VFGMCVDTLFLCFLE 14 9 SSKGLIPRSVFNLQI 12
663 VDTLFLCFLEDLERN 14
665 TLFLCFLEDLERNNG 14 TableXLVIII-V7-HLA-DR1-0401-15me.s-
678 NGSLDRPYYMSKSLL 14 24P4C12
684 PYYMSKSLLKILGKK 14 Each peptide is a portion of SEQ ID NO:
689 KSLLKILGKKNEAPP 14 15; each start position is specified, the length of peptide is 15 ammo acids, and
TableXLVIII-V3-H .DR1-0401- the end position for each peptide is the 15mers-24P4C12 start position plus fourteen.
Each peptide is a portion of SEQ ID NO: Pos 123456789012345 score
7; each start position is specified, the 9 YWILVAVGQMMSTMF 26 length of peptide is 15 amino acids, and 6 QSWYWILVAVGQMMS 22 the end position for each peptide is the 7 SWYWILVAVGQMMST 22 start position plus fourteen. 8 WYWILVAVGQMMSTM 20
Pos 123456789012345 score 1 FEDFAQSWYWILVAV 16
9 CFPWTNITPPALPGI 22 5 AQSWYWILVAVGQMM 16
3 APALGRCFPWTNITP 14 10 WILVAVGQMMSTMFY 14
12 WTNITPPALPGITND 14 12 LVAVGQMMSTMFYPL 14
4 PALGRCFPWTNITPP 12
5 ALGRCFPWTNITPPA 12 TableXLVIII-V8-HLA-DR1-0401-15mers-
8 RCFPWTNITPPALPG 12 24P4C12
13 TNITPPALPGITNDT 12 Each peptide is a portion of SEQ ID NO: 3;
14 NITPPALPGITNDTT 12 each start position is specified, the lengtti of
7 GRCFPWTNITPPALP 10 peptide is 17 amino acids, and the end position for each peptide is the start
TableXLVM-V5-DR1-0401-15mers- position plus fourteen.
24P4C12 Pos 123456789012345 score
TableXLVIII.V8-HLA-DR1-0401-15mers- TableXLIX-V1 -DRB1 -1101-15mers- 24P4C12 24P4C12
Each pepti'de is a portion of SEQ ID NO: 3; Each peptide is a portion of SEQ ID NO: each start position is specified, the length of 3; each start position is specified, the peptide is 17 amino acids, and the end length of peptide is 15 amino acids, and position for each peptide is the start the end position for each peptide is the position plus fourteen. start position plus fourteen.
Pos 123456789012345 score Pos 123456789012345 score
7 NYYWLPIMRNPITPT 28 276 CWEEYRVLRDKGASI 21 5 HLNYYWLPIMRNPIT 22 338 IALLKEASKAVGQMM 21
8 YYWLPIMRNPITPTG 20 508 ILTLVQIARVILEYI 21 15 RNPITPTGHVFQTSI 20 516 RVILEYIDHKLRGVQ 21 26 QTSILGAYVIASGFF 20 542 KCCLWCLEKFIKFLN 21
18 ITPTGHVFQTSILGA 18 585 IVRVWLDKVTDLLL 21
19 TPTGHVFQTSILGAY 18 685 YYMSKSLLKILGKKN 21 3 SPHLNYYWLPIMRNP 14 172 LPSAPALGRCFPWTN 20
10 WLPIMRNPITPTGHV 14 334 IRIAIALLKEASKAV 20
11 LPIMRNPITPTGHVF 14 371 YWAMTALYLATSGQP 20 21 TGHVFQTSILGAYVI 14 549 EKFIKFLNRNAYIMI 20
591 LDKVTDLLLFFGKLL 20
TablGXLVIII-V9-HLA-DR1-0401- 619 SGRIPGLGKDFKSPH 20 15mers-24P4C12 689 KSLLKILGKKNEAPP 20
Each peptide is a portion of SEQ ID 36 ICCVLFLLFILGYIV 19
NO: 19; each start position is 122 EDPWTVGKNEFSQTV 19 specified, the length of peptide is 15 256 PLVLVLILGVLGVLA 19 amino acids, and the end position for 259 LVLILGVLGVLAYGI 19 each peptide is the start position plus 310 LAALIVLAVLEAILL 19 fourteen. 353 STMFYPLVTFVLLLI 19 Pos 123456789012345 score 523 DHKLRGVQNPVARCI 19
10 MTALYPLPTQPATLG 26 567 GKNFCVSAKNAFMLL 19 23 LGYVLWASNISSPGC 26 612 VLSFFFFSGRIPGLG 19
11 TALYPLPTQPATLGY 22 636 YYWLPIMTSILGAYV 19 22 TLGYVLWASNISSPG 22 16 PVKYDPSFRGPIKNR 18 7 YWAMTALYPLPTQPA 20 48 YIVVGIVAWLYGDPR 18
20 PATLGYVLWASNISS 20 85 YLLYFNIFSCILSSN 18 5 IAYWAMTALYPLPTQ 16 137 GEVFYTKNRNFCLPG 18
2 LICIAYWAMTALYPL 14 181 CFPWTNVTPPALPGI 18
3 ICIAYWAMTALYPLP 12 227 QSWYWILVALGVALV 18 15 PLPTQPATLGYVLWA 12 244 LLFILLLRLVAGPLV 18
21 ATLGYVLWASNISSP 12 326 MLIFLRQRIRIAIAL 18
419 CPGLMCVFQGYSSKG 18
TableXLIX-V1 -DRB1 -1101 -15mβrs- 469 FASFYWAFHKPQDIP 18 24P4C12 470 ASFYWAFHKPQDIPT 18
Each peptide is a portion of SEQ ID NO: 488 ISAFIRTLRYHTGSL 18
3; each start position is specified, the 489 SAFIRTLRYHTGSLA 18 length of peptide is 15 amino acids, and 597 LLLFFGKLLWGGVG 18 the end position for each peptide is the 41 FLLFILGYIWGIVA 17 start position plus fourteen. 45 ILGYIWGIVAWLYG 17
Pos 123456789012345 score 71 TGAYCGMGENKDKPY 17
243 SLLFILLLRLVAGPL 31 86 LLYFNIFSCILSSNI 17
10 DEAYGKPVKYDPSFR 26 306 QETWLAALIVLAVLE 17
20 DPSFRGPIKNRSCTD 26 325 LMLIFLRQRIRIAIA 17
668 LCFLEDLERNNGSLD 26 354 TMFYPLVTFVLLLIC 17
575 KNAFMLLMRNIVRW 25 369 IAYWAMTALYLATSG 17
613 LSFFFFSGRIPGLGK 25 384 QPQYVLWASNISSPG 17
226 AQSWYWILVALGVAL 23 442 LQIYGVLGLFWTLNW 17
228 SWYWILVALGVALVL 23 482 IPTFPLISAFIRTLR 17
277 WEEYRVLRDKGASIS 23 501 SLAFGALILTLVQIA 17
359 LVTFVLLLICIAYWA 23 548 LEKFIKFLNRNAYIM 17
448 LGLFWTLNWVLALGQ 23 615 FFFFSGRIPGLGKDF 17
579 MLLMRNIVRVWLDK 23 635 NYYWLPIMTSILGAY 17
598 LLFFGKLLWGGVGV 22 652 ASGFFSVFGMCVDTL 17
633 HLNYYWLPIMTSILG 22 82 DKPYLLYFNIFSCIL 16
TableXLIX-VI -DRB1 -1101 -15mers- Pos 123456789012345 score 24P4C12 15 VLIFLRQRIRIAIAL 18
Each peptide is a portion of SEQ ID NO: 14 LVLIFLRQRIRIAIA 17
3, each start position is specified, the 12 LLLVLIFLRQRIRIA 16 length of peptide is 15 amino acids, and 10 AILLLVLIFLRQRIR 15 the end position for each peptide is the 2 LIVLAVLEAILLLVL 14 start position plus fourteen. 8 LEAILLLVLIFLRQR 14
Pos 123456789012345 score 13 LLVLIFLRQRIRIAI 14
89 FNIFSCILSSNIISV 16 1 ALIVLAVLEAILLLV 13
179 GRCFPWTNVTPPALP 16 5 LAVLEAILLLVLIFL 13
253 VAGPLVLVLILGVLG 16 9 EAILLLVUFLRQRI 13
299 LSAYQSVQETWLAAL 16 11 ILLLVLIFLRQRIRI 13
323 LLLMLIFLRQRIRIA 16
368 CIAYWAMTALYLATS 16 TableXLIX-V6-HLA-DRB1 -1101-
387 YVLWASNISSPGCEK 16 15mers-24P4C12
490 AFIRTLRYHTGSLAF 16 Each peptide is a portion of SEQ ID NO:
494 TLRYHTGSLAFGALI 16 13; each start position is specified, the
506 ALILTLVQIARVILE 16 length of peptide is 15 amino acids, and
517 VILEYIDHKLRGVQN 16 the end position for each peptide is the
557 RNAYIMIAIYGKNFC 16 start position plus fourteen.
563 IAIYGKNFCVSAKNA 16 Pos 123456789012345 score
583 RNIVRVWLDKVTDL 16 8 YSSKGLIPRSVFNLQ 15
646 LGAYVIASGFFSVFG 16 1 LMCVFQGYSSKGLIP 14
43 LFILGYIWGIVAWL 15 15 PRSVFNLQIYGVLGL 13
44 FILGYIWGIVAWLY 15 2 MCVFQGYSSKGLIPR 10
47 GYIWGIVAWLYGDP 15 5 FQGYSSKGLIPRSVF 10
54 VAWLYGDPRQVLYPR 15 3 CVFQGYSSKGLIPRS 9
73 AYCGMGENKDKPYLL 15 11 KGLIPRSVFNLQIYG 9
153 PWNMTVITSLQQELC 15 6 QGYSSKGLIPRSVFN 8
156 MTVITSLQQELCPSF 15 4 VFQGYSSKGLIPRSV 7
195 ITNDTTIQQGISGU 15 7 GYSSKGLIPRSVFNL 7
207 GLIDSLNARDISVKI 15
242 LSLLFILLLRLVAGP 15 TableXUX-V7-HLA-DRB1 -1101-15mer s-
357 YPLVTFVLLLICIAY 15 24P4C12
429 YSSKGLIQRSVFNLQ 15 Each peptide is a portion of SEQ ID NO:
485 FPLISAFIRTLRYHT 15 15; each start position is specified, the
519 LEYIDHKLRGVQNPV 15 length of peptide is 15 amino acids, and the
527 RGVQNPVARCIMCCF 15 end position for each peptide is the start
545 LWCLEKFIKFLNRNA 15 position plus fourteen.
595 TDLLLFFGKLLWGG 15 Pos 123456789012345 score
600 FFGKLLWGGVGVLS 15 5 AQSWYWILVAVGQMM 23
603 KLLWGGVGVLSFFF 15 6 QSWYWILVAVGQMMS 18
681 LDRPYYMSKSLLKIL 15 9 YWILVAVGQMMSTMF 18
7 SWYWILVAVGQMMST 16
TableXLIX-V3-HLA-DRB1-1101-15mers- 12 LVAVGQMMSTMFYPL 12
24P4C12 1 FEDFAQSWYWILVAV 11
Each peptide is a portion of SEQ ID NO: 7; each start position is specified, the length of TableXLIX-V8-HLA-DRB1-1101-15mers- peptide is 15 amino acids, and the end 24P4C12 position for each peptide is the start position Each peptide is a portion of SEQ ID NO: plus fourteen. 17; each start position is specified, the os 123456789012345 score length of peptide is 15 amino acids, and the
9 CFPWTNITPPALPGI 18 end position for each peptide is the start
7 GRCFPWTNITPPALP 16 position plus fourteen.
12 WTNITPPALPGITND 8 Pos 123456789012345 score
7 NYYWLPIMRNPITPT 24
TableXLIX-V5-HLA-DRB1-1101-15mers- 5 HLNYYWLPIMRNPIT 18 24P4C12 6 LNYYWLPIMRNPITP 17
Each peptide is a portion of SEQ ID NO: 15 RNPITPTGHVFQTSI 16
11 ; each start position is specified, the 8 YYWLPIMRNPITPTG 13 length of peptide is 15 amino adds, and the 21 TGHVFQTSILGAYVI 13 end position for each peptide is the start position plus fourteen. TableXLIX-V9-HLA-DRB1 -1101 -15mers-
24P4C12
Each peptide is a portion of SEQ ID NO:
19; each start position is spedfied, the length of peptide is 15 amino acids, and the end position for each peptide is the start position plus fourteen. Pos 123456789012345 score
4 CIAYWAMTALYPLPT 22
10 MTALYPLPTQPATLG 18
22 TLGYVLWASNISSPG 17 7 YWAMTALYPLPTQPA 14 13 LYPLPTQPATLGYVL 13 20 PATLGYVLWASNISS 12
23 LGYVLWASNISSPGC 12
24 GYVLWASNISSPGCE 12
5 IAYWAMTALYPLPTQ 10
11 TALYPLPTQPATLGY 10
Table L: Properties of 24P4C12
Bioinformatic URL Outcome Program
ORF ORF finder 6 to 2138
Protein length 710aa Transmembrane region TM Pred http://www.ch.embnet.org HTM, 39-59, 86-104,
231-250, 252-273, 309-
330, 360-380, 457-474,
497-515, 559-581, 604-
626, 641-663
HMMTop http://www.enzim.hu hmmtop/ 11TM, 35-59 84-104231 -
250257-277 308-330 355-
377456-475 500-519 550-
572597-618649-671
Sosui http://www.genome.ad.jp/SOSui/ 13TM, 34-65, 86-108, 145- 167, 225-247, 307-329, 357-379, 414^.36, 447-469, 501-523, 564-586, 600-622, 644-666
TMHMM http://www.cbs.dtu.dk services/TMHMM 10TM, 36-58,228-250, 252- 274, 308-330, 356-378, 454-476, 497-519, 559-581, 597-619
Signal Peptide Signal P http://www.cbs.dtu.dk/services/SignalP/ no pi pI/MW tool http://www.expasy.ch tools 8.9 pi
Molecular weight pI/MW tool http://www.expasy.ch/tools/ 79.3 kD
Localization PSORT http://psort.nibb.ac.jp/ 80% Plasma Membrane,
40% Golgi
PSORT II http://psort.nibb.ac.jp/ 65% Plasma Membrane, 38% endoplasmic reticulum
Motifs Pfam http://www.sanger.ac.uk/Pfam/ DUF580, uknown function
Prints http://www.biochem.ucl.ac.uk
Blocks http://www.blocks.fhcrc.org Anion exchanger family 313-359
Prosite http://www.prosite.org/ CYS-RICH 536 - 547
Table LI . Exon compositions of 24P4C12 v.1

Table LII . Nucleotide sequence of transcript variant 24P4C12 v.7 (SEQ ID NO: 94) gagccatggg gggaaagcag cgggacgagg atgacgaggc ctacgggaag ccagtcaaat 60 acgacccctc ctttcgaggc cccatcaaga acagaagctg cacagatgtc atctgctgcg 120 tcctcttcct gctcttcatt ctaggttaca tcgtggtggg gattgtggcc tggttgtatg 180 gagacccccg gcaagtcctc taccccagga actctactgg ggcctactgt ggcatggggg 240 agaacaaaga taagccgtat ctcctgtact tcaacatctt cagctgcatc ctgtccagca 300 acatcatctc agttgctgag aacggcctac agtgccccac accccaggtg tgtgtgtcct 360 cctgcccgga ggacccatgg actgtgggaa aaaacgagtt ctcacagact gttggggaag 420 tcttctatac aaaaaacagg aacttttgtc tgccaggggt accctggaat atgacggtga 480 tcacaagcct gcaacaggaa ctctgcccca gtttcctcct cccctctgct ccagctctgg 540 ggcgctgctt tccatggacc aacgttactc caccggcgct cccagggatc accaatgaca 600 ccaccataca gcaggggatc agcggtctta ttgacagcct caatgcccga gacatcagtg 660 ttaagatctt tgaagatttt gcccagtcct ggtattggat tcttgtggct gtgggacaga 720 tgatgtctac catgttctac ccactggtca cctttgtcct cctcctcatc tgcattgcct 780 actgggccat gactgctctg tacctggcta catcggggca accccagtat gtgctctggg 840 catccaacat cagctccccc ggctgtgaga aagtgccaat aaatacatca tgcaacccca 900 cggcccacct tgtgaactcc tcgtgcccag ggctgatgtg cgtcttccag ggctactcat 960 ccaaaggcct aatccaacgt tctgtcttca atctgcaaat ctatggggtc ctggggctct 1020 tctggaccct taactgggta ctggccctgg gccaatgcgt cctcgctgga gcctttgcct 1080 ccttctactg ggccttccac aagccccagg acatccctac cttcccctta atctctgcct 1140 tcatccgcac actccgttac cacactgggt cattggcatt tggagccctc atcctgaccc 1200 ttgtgcagat agcccgggtc atcttggagt atattgacca caagctcaga ggagtgcaga 1260 accctgtagc ccgctgcatc atgtgctgtt tcaagtgctg cctctggtgt ctggaaaaat 1320 ttatcaagtt cctaaaccgc aatgcataca tcatgatcgc catctacggg aagaatttct 1380 gtgtctcagc caaaaatgcg ttcatgctac tcatgcgaaa cattgtcagg gtggtcgtcc 1440 tggacaaagt cacagacctg ctgctgttct ttgggaagct gctggtggtc ggaggcgtgg 1500 gggtcctgtc cttctttttt ttctccggtc gcatcccggg gctgggtaaa gactttaaga 1560 gcccccacct caactattac tggctgccca tcatgacctc oatcctgggg gcctatgtca 1620 tcgccagcgg cttcttcagc gttttcggca tgtgtgtgga cacgctcttc ctctgcttcc 1680 tggaagacct ggagcggaac aacggctccc tggaccggcc ctactacatg tccaagagcc 1740 ttctaaagat tctgggcaag aagaacgagg cgcccccgga caacaagaag aggaagaagt 1800 gacagctccg gccctgatcc aggactgcac cccaccccca ccgtccagcc atccaacctc 1860 acttcgcctt acaggtctcc attttgtggt aaaaaaaggt tttaggccag gcgccgtggc 1920 tcacgcctgt aatccaacac tttgagaggc tgaggcgggc ggatcacctg agtcaggagt 1980 tcgagaccag cctggccaac atggtgaaac ctccgtctct attaaaaata caaaaattag 2040 ccgagagtgg tggcatgcac ctgtcatccc agctactcgg gaggctgagg caggagaatc 2100 gcttgaaccc gggaggcaga ggttgcagtg agccgagatc gcgccactgc actccaacct 2160 gggtgacaga ctctgtctcc aaaacaaaac aaacaaacaa aaagatttta ttaaagatat 2220 tttgttaact cagtaaaaaa aaaaaaaaaa a 2251
Table LIII. Nucleotide sequence alignment of 24P4C12V.1 v.1 (SEQ ID NO: 95) and 24P4C12 v.7 (SEQ ID NO: 96).
Score = 1358 bits (706), Expect = O.OIdentities = 706/706 (100%) Strand = Plus / Plus
24P4C12v.l: 1 gagccatggggggaaagcagcgggacgaggatgacgaggcctacgggaagccagtcaaat 60
I II I I I I II I I I I I I I I I I I I I I I I I I I I I I II I I I I I I I I I I I I I I I I I II I I I I I I I I 24P4C12v.7: 1 gagccatggggggaaagcagcgggacgaggatgacgaggcctacgggaagccagtcaaat 60
24P4C12V.1: 61 acgacccctcctttcgaggccccatcaagaacagaagctgcacagatgtcatctgctgcg 120 I I I II I II I Mil I I I II M I I III I I I I I I I III II M I I I I I II I I I I I I I I I I I II I
24P4C12V.7: 61 acgacccctcctttcgaggccccatcaagaacagaagctgcacagatgtcatctgctgcg 120
24P4C12v.l: 121 tcctcttcctgctcttcattctaggttacatcgtggtggggattgtggcctggttgtatg 180
I I II I I I I I II II I I I I I I I I I III I I I I I I I I II I I I I I I I I I I II I II I I I I I I I II I 2 P4C12v.7: 121 tcctcttcctgctcttcattctaggttacatcgtggtggggattgtggcctggttgtatg 180
24P4C12v.l: 181 gagacccccggcaagtcctctaccccaggaactctactggggcctactgtggcatggggg 240
I I I I I I I I I I I I II II I I I I I I I I I I I I I I I I I II I I I I I I I II I II I II I I I I I II I I I 24P4C12v.7: 181 gagacccccggcaagtcctctaccccaggaactctactggggcctactgtggcatggggg 240
24P4C12v.l: 241 agaacaaagataagccgtatctcctgtacttcaacatcttcagctgcatcctgtccagca 300
I I I I I I I I I I I I I I I I I I I I I I II I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I i I I I 24P4C12V.7: 241 agaacaaagataagccgtatctcctgtacttcaacatcttcagctgcatcctgtccagca 300
24P4C12v.l: 301 acatcatctcagttgctgagaacggcctacagtgccccacaccccaggtgtgtgtgtcct 360
I I I I I I I I I I I I I I I I I I Ml I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 24P4C12v.7: 301 acatcatctcagttgctgagaacggcctacagtgccccacaccccaggtgtgtgtgtcct 360
24P4C12v.l: 361 cctgcccggaggacccatggactgtgggaaaaaacgagttctcacagactgttggggaag 420 I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
24P4C12V.7: 361 cctgcccggaggacccatggactgtgggaaaaaacgagttctcacagactgttggggaag 420
24P4C12v.l: 421 tcttctatacaaaaaacaggaacttttgtctgccaggggtaccctggaatatgacggtga 480 I I I I I I I I I I I I I I I I I I I I II I I I I I I I I I I I I I I I I I I I I I I I I I II I I I I I I I I I I I
24P4C12v.7: 421 tcttctatacaaaaaacaggaacttttgtctgccaggggtaccctggaatatgacggtga 480
24P4C12v.l: 481 tcacaagcctgcaacaggaactctgccccagtttcctcctcccctctgctccagctctgg 540
I I I I I I I I I I I I I I II I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I
24P4C12v.7: 481 tcacaagcctgcaacaggaactctgccccagtttcctcctcccctctgctccagctctgg 540
24P4C12v.l: 541 ggcgctgctttccatggaccaacgttactccaccggcgctcccagggatcaccaatgaca 600
I I I I I I I I I I I I I II I II I I I I I I I II I I I I I I I I I I I I I I I I II I I I I I I I I I I I I I I I
24P4C12v.7: 541 ggcgctgctttccatggaccaacgttactccaccggcgctcccagggatcaccaatgaca 600
24P4C12v.l: 601 ccaccatacagcaggggatcagcggtcttattgacagcctcaatgcccgagacatcagtg 660
I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I II II I I I I I I I II I I I I I I I I I I I
24P4C12v.7: 601 ccaccatacagcaggggatcagcggtcttattgacagcctcaatgcccgagacatcagtg 660
24P4C12v.l: 661 ttaagatctttgaagattttgcccagtcctggtattggattcttgt 706
I I I I I I I I I I II I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I LI I 24P4C12v.7: 661 ttaagatctttgaagattttgcccagtcctggtattggattcttgt 706
Score = 2971 bits (1545), Expect O.OIdentities = 1545/1545 (100%) Strand = Plus / Plus
24P4C12v.l: 1043 ggctgtgggacagatgatgtctaccatgttctacccactggtcacctttgtcctcctcct 1102
I II I I I I I I I I II I I I I I I I I I I I I I II I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 24P4C12v.7: 707 ggctgtgggacagatgatgtctaccatgttctacccactggtcacctttgtcctcctcct 766
24P4C12v.l: 1103 catctgcattgcctactgggccatgactgctctgtacctggctacatcggggcaacccca 1162
I I I I I I I I Ml I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I I 24P4C12v.7: 767 catctgcattgcctactgggccatgactgctctgtacctggctacatcggggcaacccca 826
24P4C12v.l: 1163 gtatgtgctctgggcatccaacatcagctcccccggctgtgagaaagtgccaataaatac 1222
I I I I II II I I I I II I I I I I I II III I I II I I II I II I I II II II I II I I II I II II II I I 24P4C12v.7: 827 gtatgtgctctgggcatccaacatcagctcccccggctgtgagaaagtgccaataaatac 886
24P4C12v.l: 1223 atcatgcaaccccacggcccaccttgtgaactcctcgtgcccagggctgatgtgcgtctt 1282
II II I I II I I II I I I I II I I Ml I I I I I I I II I II II II I II I III II II I I I I I I I I I I 24P4C12v.7: 887 atcatgcaaccccacggcccaccttgtgaactcctcgtgcccagggctgatgtgcgtctt 946
24P4C12v.l: 1283 ccagggctactcatccaaaggcctaatccaacgttctgtcttcaatctgcaaatctatgg 1342
II I II III llllll I II II I MM II MM I II II IMMIII I Ml II I I MM II I I I 24P4C12v.7: 947 ccagggctactcatccaaaggcctaatccaacgttctgtcttcaatctgcaaatctatgg 1006
24P4C12v.l: 1343 ggtcctggggctcttctggacccttaactgggtactggccctgggccaatgcgtcctcgc 1402
II I ! Ml I Mill! MM II II Ml I II I I M I II II I MM I II M I I I I I I I III I I I 24P4C12v.7: 1007 ggtcctggggctcttctggacccttaactgggtactggccctgggccaatgcgtcctcgc 1066
P4C12v.l: 1403 tggagcctttgcctccttctactgggccttccacaagccccaggacatccctaccttccc 1462
I I II I I I II II I II I I II I II II I II II I I I II I II II I I I I II I II I II II II II II I I P4C12V.7-. 1067 tggagcctttgcctccttctactgggccttccacaagccccaggacatccctaccttccc 1126
P4C12v.l: 1463 cttaatctctgccttcatccgcacactccgttaccacactgggtcattggcatttggagc 1522
MM II II I II II II II II II I I I II II II I I I II II I M I I II I I I I I I II I I II I II I P4C12v.7: 1127 cttaatctctgccttcatccgcacactccgttaccacactgggtcattggcatttggagc 1186
P4C12v.l: 1523 cctcatcctgacccttgtgcagatagcccgggtcatcttggagtatattgaccacaagct 1582 i i i 1 1 1 1 i i i i i i 1 1 1 i i I I I n i i I I I i i i n 1 1 m i 1 1 1 i n n 1 M U M n u n P4C12v.7: 1187 cctcatcctgacccttgtgcagatagcccgggtcatcttggagtatattgaccacaagct 1246
P4C12V.1: 1583 cagaggagtgcagaaccctgtagcccgctgcatcatgtgctgtttcaagtgctgcctctg 1642
I II I I II II I I I I I MMMI I II llllll II II II III II I I II I II I II I I I II II II P4C12v.7: 1247 cagaggagtgcagaaccctgtagcccgctgcatcatgtgctgtttcaagtgctgcctctg 1306
P4C12v.l: 1643 gtgtctggaaaaatttatcaagttcctaaaccgcaatgcatacatcatgatcgccatcta 1702
II II II I II II II I III II III II II I I II I I II II I II I I II II II II llllll II II I P4C12v.7: 1307 gtgtctggaaaaatttatcaagttcctaaaccgcaatgcatacatcatgatcgccatcta 1366
P4C12v.l: 1703 cgggaagaatttctgtgtctcagccaaaaatgcgttcatgctactcatgcgaaacattgt 1762
I M II I I II M II U III I III II IIIl I U II II IIIl II II II II I I II I M II II II P4C12v.7: 1367 cgggaagaatttctgtgtctcagccaaaaatgcgttcatgctactcatgcgaaacattgt 1426
P4C12v.l: 1763 cagggtggtcgtcctggacaaagtcacagacctgctgctgttctttgggaagctgctggt 1822
I II I II II II II I II II II I I II I I II I I I II II I II II I I I I II II II I I I II II I I II P4C12V.7: 1427 cagggtggtcgtcctggacaaagtcacagacctgctgctgttctttgggaagctgctggt 1486
P4C12v.l: 1823 ggtcggaggcgtgggggtcctgtccttcttttttttctccggtcgcatcccggggctggg 1882
I II II II II II I I I MM II I II I I II I II I II II I I I I I I I I II II II II I II II II II P4C12v.7: 1487 ggtcggaggcgtgggggtcctgtccttcttttttttctccggtcgcatcccggggctggg 1546
P4C12V.1: 1883 taaagactttaagagcccccacctcaactattactggctgcccatcatgacctccatcct 1942
II II II I II II I II III I III I II III III II II I II I I II I I II I I II II II I I II I II P4C12v.7: 1547 taaagactttaagagcccccacctcaactattactggctgcccatcatgacctccatcct 1606
P4C12v.l: 1943 gggggcctatgtcatcgccagcggcttcttcagcgttttcggcatgtgtgtggacacgct 2002
I IIIl I I Mill II MM lllllll MM I II lllllllll I MM llinillll II II P4C12v.7: 1607 gggggcctatgtcatcgccagcggcttcttcagcgttttcggcatgtgtgtggacacgct 1666
P4C12v.l: 2003 cttcctctgcttcctggaagacctggagcggaacaacggctccctggaccggccctacta 2062
II II I I I I II I I I II I II II II II I I I II I I I I II II I I I I I I I II II I II I II II I I I I P4C12v.7: 1667 cttcctctgcttcctggaagacctggagcggaacaacggctccctggaccggccctacta 1726
P4C12v.l: 2063 catgtccaagagccttctaaagattctgggcaagaagaacgaggcgcccccggacaacaa 2122
II I II II I II I I I I II I I II II II I II I II I I I II II I I I I I I I I I I I II II II II I I I I P4C12v.7: 1727 catgtccaagagccttctaaagattctgggcaagaagaacgaggcgcccccggacaacaa 1786
P4C12v.l: 2123 gaagaggaagaagtgacagctccggccctgatccaggactgcaccccacccccaccgtcc 2182
1 1 i i i i i i i i i i i i i M I m i 1 1 i n u i u u u u u u u u u u i m i u i u P4C12v.7: 1787 gaagaggaagaagtgacagctccggccctgatccaggactgcaccccacccccaccgtcc 1846
P4C12v.l: 2183 agccatccaacctcacttcgccttacaggtctccattttgtggtaaaaaaaggttttagg 2242
I I I I II II I I 11 I II II II I III I I II II I I II I I I II II II I I I I I I I I I M I I I I I I I P4C12v.7: 1847 agccatccaacctcacttcgccttacaggtctccattttgtggtaaaaaaaggttttagg 1906
24P4C12v.l: 2243 ccaggcgccgtggctcacgcctgtaatccaacactttgagaggctgaggcgggcggatca 2302
I I I II II II II II II M II I II I I II I II I I I II II II II I I I II I I III I I I III I I 24P4C12v.7: 1907 ccaggcgccgtggctcacgcctgtaatccaacactttgagaggctgaggcgggcggatca 1966
24P4C12v.l: 2303 cctgagtcaggagttcgagaccagcctggccaacatggtgaaacctccgtctctattaaa 2362
I I I III I I II II I I I II I II II II II I II II II I I I I II I I II I II I I I II I I II I I I II 24P4C12v,7: 1967 cctgagtcaggagttcgagaccagcctggccaacatggtgaaacctccgtctctattaaa 2026
24P4C12v.l: 2363 aatacaaaaattagccgagagtggtggcatgcacctgtcatcccagctactcgggaggct 2422 i i i i i i i 1 1 1 1 i i 1 1 m i u m i 1 1 i i 1 1 i i 1 1 u u i u u u 1 1 i n n u u i u
24P4C12v.7: 2027 aatacaaaaattagccgagagtggtggcatgcacctgtcatcccagctactcgggaggct 2086
24P4C12v.l: 2423 gaggcaggagaatcgcttgaacccgggaggcagaggttgcagtgagccgagatcgcgcca 2482
I I II II II I I II II I III II I II II I 11 II II I II II II I II I I II I I I MM II I II II 24P4C12v.7: 2087 gaggcaggagaatcgcttgaacccgggaggcagaggttgcagtgagccgagatcgcgcca 2146
24P4C12v.l: 2483 ctgcactccaacctgggtgacagactctgtctccaaaacaaaacaaacaaacaaaaagat 2542
II II II I II I II I II III II II II II II II I II I I II I I I I I I II II I I III I I I I I I II 24P4C12v.7: 2147 ctgcactccaacctgggtgacagactctgtctccaaaacaaaacaaacaaacaaaaagat 2206
24P4C12v.l: 2543 tttattaaagatattttgttaactcagtaaaaaaaaaaaaaaaaa 2587
I I I II I I III II II I I I II II II II II II II II IIIl I I I I II II 24P4C12v.7: 2207 tttattaaagatattttgttaactcagtaaaaaaaaaaaaaaaaa 2251
Table LIV. Peptide sequences of protein coded by 24P4C12 v.7 (SEQ ID NO: 97)
MGGKQRDEDD EAYGKPVKYD PSFRGPIKNR SCTDVICCVL FLLFILGYIV VGIVAWLYGD 60
PRQVLYPRNS TGAYCGMGEN KDKPYLLYFN IFSCILSSNI ISVAENGLQC PTPQVCVSSC 120
PEDPWTVGKN EFSQTVGEVF YTKNRNFCLP GVPWNMTVIT SLQQELCPSF LLPSAPALGR 180
CFPWTNVTPP ALPGITNDTT IQQGISGLID SLNARDISVK IFEDFAQSWY WILVAVGQMM 240
STMFYPLVTF VLLLICIAYW AMTALYLATS GQPQYVLWAS NISSPGCEKV PINTSCNPTA 300
HLVNSSCPGL MCVFQGYSSK GLIQRSVFNL QIYGVLGLFW TLNWVLALGQ CVLAGAFASF 360
YWAFHKPQDI PTFPLISAFI RTLRYHTGSL AFGALILTLV QIARVILEYI DHKLRGVQNP 420
VARCIMCCFK CCLWCLEKFI KFLNRNAYIM IAIYGKNFCV SAKNAFMLLM RNIVRVWLD 480
KVTDLLLFFG KLLWGGVGV LSFFFFSGRI PGLGKDFKSP HLNYYWLPIM TSILGAYVIA 540
SGFFSVFGMC VDTLFLCFLE DLERNNGSLD RPYYMSKSLL KILGKKNEAP PDNKKRKK 598
Table LV. Amino acid sequence alignment of 24E4C12v.l v.1 (SEQ ID NO: 98) and 24P4C12 v.7 (SEQ ID NO: 99).
Score = 1195 bits (3091), Expect = O.Oldentities = 598/710 (84%), Positives = 598/710 (84%), Gaps = 112/710 (15%)
24P4C12v.l: 1 MGGKQRDEDDEAYGKPVKYQPSFRGPIKNRSCTDVICCVLFLLFILGYIVVGIVF-MLYGD 60
MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 24P4C12V.7: 1 MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIVVGIVAWLYGD 60
24P4C12V.1: 61 PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 120
PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 24P4C12v.7: 61 PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 120
24P4C12V.1: 121 PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 180
PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 24P4C12V.7: 121 PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWMTVITSLQQELCPSFLLPSAPALGR 180
24P4C12v.l: 181 CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVALGVAL 240
CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYV.ILVA 24P4C12V.7: 181 CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVA 235
24P4C12v.l: 241 VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS 300
24 P4C12V.7 : 235 235
24 P4C12v . l : 301 AYQSVQETWLAALIVLAVLEAILLLMLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 360
VGQMMSTMFYPLV
24P4C12v .7 : 236 VGQMMSTMFYPLV 248
24P4C12v . l : 361 TFVLLLICIAYWAMTALYLATSGQPQYVLWASNISSPGCEKVFINTSCNPTAHLVNSSCP 420 TFVLLLICIAYWAMTALYLATSGQPQYVLWASNISSPGCEKVPINTSCNPTAHLVNSSCP
24 P4C12V.7 : 249 TFVLLLICIAYWAMTALYLATSGQPQYVLWASNISSPGCEKVPINTSCNPTAHLVNSSCP 308
24P4C12v. l t 421 GLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFHKPQ 480 GLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFHKPQ
24P4C12V.7 : 309 GLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFHKPQ 368
24P4C12v. l : 481 DIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCIMCC 540 DIP FPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCIMCC
24P4C12V. 7 : 369 DIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCIMCC 428
24P4C12v . l : 541 FKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDLLLF 600 FKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVVVLDKVTDLLLF
24P4C12V . 7 : 429 FKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDLLLF 488
24P4C12v . l : 601 FGKLLVVGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMTSILGAYVIASGFFSVFG 660 FGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMTSILGAYVIASGFFSVFG
24 P4C12V. 7 : 489 FGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMTSILGAYVIASGFFSVFG 548
24 P4C12v . l t 661 MCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKRKK 710 MCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKRKK
24P4C12v .7 t 549 MCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKRKK 598
Table LVI . Nucleotide sequence of transcript variant 24P4C12 v.8 (SEQ ZD NO: 100) gagccatggg gggaaagcag cgggacgagg atgacgaggc ctacgggaag ccagtcaaat 60 acgacccctc ctttcgaggc cccatcaaga acagaagctg cacagatgtc atctgctgcg 120 tcctcttcct gctcttcatt ctaggttaca tcgtggtggg gattgtggcc tggttgtatg 180 gagacccccg gcaagtcctc taccccagga actctactgg ggcctactgt ggcatggggg 240 agaacaaaga taagccgtat ctcctgtact tcaacatctt cagctgcatc ctgtccagca 300 acatcatctc agttgctgag aacggcctac agtgccccac accccaggtg tgtgtgtcct 360 cctgcccgga ggacccatgg actgtgggaa aaaacgagtt ctcacagact gttggggaag 420 tcttctatac aaaaaacagg aacttttgtc tgccaggggt accctggaat atgacggtga 480 tcacaagcct gcaacaggaa ctctgcccca gtttcctcct cccctctgct ccagctctgg 540 ggcgctgctt tccatggacc aacgttactc caccggcgct cccagggatc accaatgaca 600 ccaccataca gcaggggatc agcggtctta ttgacagcct caatgcccga gacatcagtg 660 ttaagatctt tgaagatttt gcccagtcct ggtattggat tcttgttgcc ctgggggtgg 720 ctctggtctt gagcctactg tttatcttgc ttctgcgcct ggtggctggg cccctggtgc 780 tggtgctgat cctgggagtg ctgggcgtgc tggcatacgg catctactac tgctgggagg 840 agtaccgagt gctgcgggac aagggcgcct ccatctccca gctgggtttc accaccaacc 900 tcagtgccta ccagagσgtg caggagacct ggctggccgc cctgatcgtg ttggcggtgc 960 ttgaagccat cctgctgctg atgctcatct tcctgcggca gcggattcgt attgccatcg 1020 ccctcctgaa ggaggcσagc aaggctgtgg gacagatgat gtctaccatg ttctacccac 1080 tggtcacctt tgtcctcctc ctcatctgca ttgcctactg ggccatgact gctctgtacc 1140 tggctacatc ggggcaaccc cagtatgtgc tctgggcatc caacatcagc tcccccggct 1200 gtgagaaagt gccaataaat acatcatgca accccacggc ccaccttgtg aactcctcgt 1260 gcccagggct gatgtgcgtc ttccagggct actcatccaa aggcctaatc caacgttctg 1320 tcttcaatct gcaaatctat ggggtcctgg ggctcttctg gacccttaac tgggtactgg 1380 ccctgggcca atgcgtcctc gctggagcct ttgcctcctt ctactgggcc ttccacaagc 1440 cccaggacat ccctaccttc cccttaatct ctgccttcat ccgcacactc cgttaccaca 1500 ctgggtcatt ggcatttgga gccctcatcc tgacccttgt gcagatagcc cgggtcatct 1560 tggagtatat tgaccacaag ctcagaggag tgcagaaccc tgtagcccgc tgcatcatgt 1620 gctgtttcaa gtgctgcctc tggtgtctgg aaaaatttat caagttccta aaccgcaatg 1680 catacatcat gatcgccatc tacgggaaga atttctgtgt ctcagccaaa aatgcgttca 1740 tgctactcat gcgaaacatt gtcagggtgg tcgtcctgga caaagtcaca gacctgctgc 1800 tgttctttgg gaagctgctg gtggtcggag gcgtgggggt cctgtccttc ttttttttct 1860 ccggtcgcat cccggggctg ggtaaagact ttaagagccc ccacctcaac tattactggc 1920 tgcccatcat gaggaaccca ataaccccaa cgggtcatgt cttccagacc tccatcctgg 1980 gggcctatgt catcgccagc ggcttcttca gcgttttcgg catgtgtgtg gacacgctct 2040 tcctctgctt cctggaagac ctggagcgga acaacggctc cctggaccgg ccctactaca 2100 tgtccaagag ccttctaaag attctgggca agaagaacga ggcgcccccg gacaacaaga 2160 agaggaagaa gtgacagctc cggccctgat ccaggactgc accccacccc caccgtccag 2220
ccatccaacc tcacttcgcc ttacaggtct ccattttgtg gtaaaaaaag gttttaggcc 2280 aggcgccgtg gctcacgcct gtaatccaac actttgagag gctgaggcgg gcggatcacc 2340 tgagtcagga gttcgagacc agcctggcca acatggtgaa acctccgtct ctattaaaaa 2400 tacaaaaatt agccgagagt ggtggcatgc acctgtcatc ccagctactc gggaggctga 2460 ggcaggagaa tcgcttgaac ccgggaggca gaggttgcag tgagccgaga tcgcgccact 2520 gcactccaac ctgggtgaca gactctgtct ccaaaacaaa acaaacaaac aaaaagattt 2580 tattaaagat attttgttaa ctcagtaaaa aaaaaaaaaa aaa 2623
Table LVII . Nucleotide sequence alignment of 24P4C12v.l v.1 (SEQ ID NO: 101) and 24P4C12 v.8 (SEQ ID NO: 102)
Score = 3715 bits (1932), Expect = 0.Oldentities = 1932/1932 (100%) Strand = Plus / Plus
24P4C12v.l: 1 gagccatggggggaaagcagcgggacgaggatgacgaggcctacgggaagccagtcaaat 60
I I I II II I II I I ill I I II I II I II I I I I I I I I I I I I II I I I II I I I I II II I I I I II I I 2 P4C12v.8: 1 gagccatggggggaaagcagcgggacgaggatgacgaggcctacgggaagccagtcaaat 60
24P4C12v.l: 61 acgacccctcctttcgaggccccatcaagaacagaagctgcacagatgtcatctgctgcg 120
I I II I II I M I MM I I I M II II I II I II II I II I II II I I I II II I I II I I I I II I II 24P4C12v.8: 61 acgacccctcctttcgaggccccatcaagaacagaagctgcacagatgtcatctgctgcg 120
24P4C12v.l: 121 tcctcttcctgctcttcattctaggttacatcgtggtggggattgtggcctggttgtatg 180
I I II II I I I I I I I I I I II I I I I I I II I I I II I I I I I II II I I II II I I I I I I II I II I I I 24P4C12v.8: 121 tcctcttcctgctcttcattctaggttacatcgtggtggggattgtggcctggttgtatg 180
24P4C12v.l: 181 gagacccccggcaagtcctctaccccaggaactctactggggcctactgtggcatggggg 240
I II I II II I I II I I I I I I I II II I I I I I I I I I II I I I I I I I I I I I I I I I I I II I II II I I 24P4C12v.8: 181 gagacccccggcaagtcctctaccccaggaactctactggggcctactgtggcatggggg 240
24P4C12v.l: 241 agaacaaagataagccgtatctcctgtacttcaacatcttcagctgcatcctgtccagca 300
II I II I I I I II I I MM I I II II II II I I I I II I I I I I I I I II I II I I I I II I I I I II I I 24P4C12v.8: 241 agaacaaagataagccgtatctcctgtacttcaacatcttcagctgcatcctgtccagca 300
24P4C12v.l: 301 acatcatctcagttgctgagaacggcctacagtgccccacaccccaggtgtgtgtgtcct 360
II II I I I I II II I II I I II I I II I I I I I I I I I II II II I I I II I III II I I II I II I I II 24P4C12v.8: 301 acatcatctcagttgctgagaacggcctacagtgccccacaccccaggtgtgtgtgtcct 360
24P4C12v.l: 361 cctgcccggaggacccatggactgtgggaaaaaacgagttctcacagactgttggggaag 420
I I II I II II II I II I I II I II I I II II I II I I II I II I II I I I I I I I II II I I I I I I I I I 24P4C12v.8t 361 cctgcccggaggacccatggactgtgggaaaaaacgagttctcacagactgttggggaag 420
24P4C12v.l: 421 tcttctatacaaaaaacaggaacttttgtctgccaggggtaccctggaatatgacggtga 480
II II I I I I I I I I I I III I I II I I I I I II II II II I II II II I I I II I I I I II I I I I I II I 24P4C12v.8: 421 tcttctatacaaaaaacaggaacttttgtctgccaggggtaccctggaatatgacggtga 480
24P4C12v.l: 481 tcacaagcctgcaacaggaactctgccccagtttcctcctcccctctgctccagctctgg 540
I III I II II II I I I III I I I I I I I I I II I I I I I I I I I I I I I I II I II I II II III I II II 24P4C12v.8: 481 tcacaagcctgcaacaggaactctgccccagtttcctcctcccctctgctccagctctgg 540
24P4C12v.l: 541 ggcgctgctttccatggaccaacgttactccaccggcgctcccagggatcaccaatgaca 600
II M II I I II M I Mill I II I I II I II I I I I I I I I I I I I I I I I I I I I I I II II I I I I I I 24P4C12v.8: 541 ggcgctgctttccatggaccaacgttactccaccggcgctcccagggatcaccaatgaca 600
24P4C12v.l: 601 ccaccatacagcaggggatcagcggtcttattgacagcctcaatgcccgagacatcagtg 660
I III I I II I I I I I I III I II III I I II II I III I I II I I I I I II I I I I I I II II I I I I I I 24P4C12v.8: 601 ccaccatacagcaggggatcagcggtcttattgacagcctcaatgcccgagacatcagtg 660
P4C12v.l: 661 ttaagatctttgaagattttgcccagtcctggtattggattcttgttgccctgggggtgg 720
I I II I I II I I I II I I I I II I I I I I II I II I I I I I I I I I I I I I I I I I I II I I I II I II I II P4C12v.8: 661 ttaagatctttgaagattttgcccagtcctggtattggattcttgttgccctgggggtgg 720
P4C12V.1: 721 ctctggtcttgagcctactgtttatcttgcttctgcgcctggtggctgggcccctggtgc 780 I I II I II I I I I I II II I I I I I I I I I I I I I I I I I I I I I II I I I I I I I II I I I I I I I I I I II P4C12v.8: 721 ctctggtcttgagcctactgtttatcttgcttctgcgcctggtggctgggcccctggtgc 780
P4C12v.l: 781 tggtgctgatcctgggagtgctgggcgtgctggcatacggcatctactactgctgggagg 840
II I II II I I I I I I I I I II II I I I II II I I II I I I I I I II I II I II I I I III I I I I II I I I P4C12v.8: 781 tggtgctgatcctgggagtgctgggcgtgctggcatacggcatctactactgctgggagg 840
P4C12v.l: 841 agtaccgagtgctgcgggacaagggcgcctccatctcccagctgggtttcaccaccaacc 900 I I I I I II I I I I I I I I I I II I II I II I MM I I I I II I II II I I I I I I II III I I I I II I I P4C12v.8t 841 agtaccgagtgctgcgggacaagggcgcctccatctcccagctgggtttcaccaccaacc 900
P4C12v.l: 901 tcagtgcctaccagagcgtgcaggagacctggctggccgccctgatcgtgttggcggtgc 960 II I I II II II I I I I I I I I I II II I I I I I I I II I I II II I I II II II I II III I I II II II P4C12V.8: 901 tcagtgcctaccagagcgtgcaggagacctggctggccgccctgatcgtgttggcggtgc 960
P4C12V.1: 961 ttgaagccatcctgctgctgatgctcatcttcctgcggcagcggattcgtattgcca cg 1020 II II II I I I I I I II I I I I II I I I II I I I II I I II I II I I I I I I I I I I I I II M I I I I I I I P4C12v.8: 961 ttgaagccatcctgctgctgatgctcatcttcctgcggcagcggattcgtattgccatcg 1020
P4C12v.l: 1021 ccctcctgaaggaggccagcaaggctgtgggacagatgatgtctaccatgttctacccac 1080
I II I I II II I II I II I II II II II I I I II I I I I I I I I II I I I I II I I I I I I I I I I I I I I I P4C12v.8: 1021 ccctcctgaaggaggccagcaaggctgtgggacagatgatgtctaccatgttctacccac 1080
P4C12v.l: 1081 tggtcacctttgtcctcctcctcatctgcattgcctactgggccatgactgctctgtacc 1140
II I II I I II I II I II I II I I II I II I I II II I I II II II I II I I II I I I I I I II I I II I I P4C12V.8: 1081 tggtcacctttgtcctcctcctcatctgcattgcctactgggccatgactgctctgtacc 1140
P4C12v.l: 1141 tggctacatcggggcaaccccagtatgtgctctgggcatccaacatcagctcccccggct 1200
I I I I II I I I I I I I I I I I I I I I I I I I I I II II I I II II I II I I I I II II I III I I I II I I I P4C12v.8: 1141 tggctacatcggggcaaccccagtatgtgctctgggcatccaacatcagctcccccggct 1200
P4C12v.l: 1201 gtgagaaagtgccaataaatacatcatgcaaccccacggcccaccttgtgaactcctcgt 1260
II II I II II II I I I I I I I II I II I I I I I I I I I I I II II I I I II II I I I I IIIl I II I I I I P4C12v.8: 1201 gtgagaaagtgccaataaatacatcatgcaaccccacggcccaccttgtgaactcctcgt 1260
P4C12v.l: 1261 gcccagggctgatgtgcgtcttccagggctactcatccaaaggcctaatccaacgttctg 1320
II I II II I II I I II I II II I II I I I II I I II I I I I II I I I I I I I II II I I III I I I I I I I P4C12v.8: 1261 gcccagggctgatgtgcgtcttccagggctactcatccaaaggcctaatccaacgttctg 1320
P4C12v.l: 1321 tcttcaatctgcaaatctatggggtcctggggctcttctggacccttaactgggtactgg 1380
I II II I I I II I I I II II I I I I I I II II I I I I I I I I I I I I II I I II I I I I IIIl II II I II P4C12v.8: 1321 tcttcaatctgcaaatctatggggtcctggggctcttctggacccttaactgggtactgg 1380
P4C12v.l: 1381 ccctgggccaatgcgtcctcgctggagcctttgcctccttctactgggccttccacaagc 1440
I I I I I II I I I I I I I I I I I II I I I II I I I I III II I I I I II I II II I I I I I IIIl I I I II I P4C12v.8: 1381 ccctgggccaatgcgtcctcgctggagcctttgcctccttctactgggccttccacaagc 1440
P4C12v.l: 1441 cccaggacatccctaccttccccttaatctctgccttcatccgcacactccgttaccaca 1500
I I I II I I II I I II II I I I I I I II II II I I I I II I I I I I I I I I I I I I I I I I I III II I I I I P4C12v.8: 1441 cccaggacatccctaccttccccttaatctctgccttcatccgcacactccgttaccaca 1500
24P4C12v.l: 1501 ctgggtcattggcatttggagccctcatcctgacccttgtgcagatagcccgggtcatct 1560
I II I II II II II I I I II II II I I I I I II II I I I I I I I I I II II I I II I II II I I I II I I I 24P4C12v.8: 1501 ctgggtcattggcatttggagccctcatcctgacccttgtgcagatagcccgggtcatct 1560
24P4C12v.l: 1561 tggagtatattgaccacaagctcagaggagtgcagaaccctgtagcccgctgcatcatgt 1620
I I I I I I I I II I II I I I II I II II I I II II II I I I I I II I I II I I I I I I II II I II I I I I I 24P4C12v.8: 1561 tggagtatattgaccacaagctcagaggagtgcagaaccctgtagcccgctgcatcatgt 1620
24P4C12v.l: 1621 gctgtttcaagtgctgcctctggtgtctggaaaaatttatcaagttcctaaaccgcaatg 1680
II I I I II I I I I I II I I I I I I I I II I I II II II I II I I II II II I I I I I I I I II II I I II I 24P4C12v.8: 1621 gctgtttcaagtgctgcctctggtgtctggaaaaatttatcaagttcctaaaccgcaatg 1680
24P4C12v.l: 1681 catacatcatgatcgccatctacgggaagaatttctgtgtctcagccaaaaatgcgttca 1740
I II II I I I II II I I I II II I II I II I I I I I I II II II II I I I II I II I I I IIIl II I I I I 24P4C12v.8: 1681 catacatcatgatcgccatctacgggaagaatttctgtgtctcagccaaaaatgcgttca 1740
24P4C12v.l: 1741 tgctactcatgcgaaacattgtcagggtggtcgtcctggacaaagtcacagacctgctgc 1800
I I I I I I I I II II I I II II I II II II I I I I I III I I I I I II II II I I I I I I II I I II I I I I 24P4C12v.8: 1741 tgctactcatgcgaaacattgtcagggtggtcgtcctggacaaagtcacagacctgctgc 1800
24P4C12v.l: 1801 tgttctttgggaagctgctggtggtcggaggcgtgggggtcctgtccttcttttttttct 1860
II II II I I I I II II I I I II I I II I I I I I I I I I I II I II I I I I I I I I II I I II II I I I II I 24P4C12v.8: 1801 tgttctttgggaagctgctggtggtcggaggcgtgggggtcctgtccttcttttttttct 1860
24P4C12v.l: 1861 ccggtcgcatcccggggctgggtaaagactttaagagcccccacctcaactattactggc 1920
II I I I II I I I I I II I I I I I I I I I I II I I II II I II I I I I I II I I I I II I II I I I I I II I I 24P4C12v.8: 1861 ccggtcgcatcccggggctgggtaaagactttaagagcccccacctcaactattactggc 1920
24P4C12v.l: 1921 tgcccatcatga 1932
I I I I I I I II II I 24P4C12v.8: 1921 tgcccatcatga 1932
Score = 1263 bits (657), Expect O.OIdentities = 657/657 (100%) Strand = Plus / Plus
24P4C12v.l: 1931 gacctccatcctgggggcctatgtcatcgccagcggcttcttcagcgttttcggcatgtg 1990
II I I II I I I I I II I I II I I I I I I I II I I I I I II I I I I I I I I I I I I II I I I I IIIl I I I I I 24P4C12v.8: 1967 gacctccatcctgggggcctatgtcatcgccagcggcttcttcagcgttttcggcatgtg 2026
24P4C12v.l: 1991 tgtggacacgctcttcctctgcttcctggaagacctggagcggaacaacggctccctgga 2050
I I I I I I I I I I I I I I I I I I I I I I I I I I I I II II I I II I I I I I I I I I I I II I I III I I II I I 24P4C12v.8: 2027 tgtggacacgctcttcctctgcttcctggaagacctggagcggaacaacggctccctgga 2086
24P4C12v.l: 2051 ccggccctactacatgtccaagagccttctaaagattctgggcaagaagaacgaggcgcc 2110
I I II I II I I I I I I I I I I I I I I II I I I I I I I II I I I I I II I I I I I I I I I I I I I II I I I I II 24P4C12v.8: 2087 ccggccctactacatgtccaagagccttctaaagattctgggcaagaagaacgaggcgcc 2146
24P4C12v.l: 2111 cccggacaacaagaagaggaagaagtgacagctccggccctgatccaggactgcacccca 2170
I I II II I II I II I I II I I II II I I I I I I I II II I I I II II I I I I I I I I I I I I I I I I I I I I 24P4C12v.8: 2147 cccggacaacaagaagaggaagaagtgacagctccggccctgatccaggactgcacccca 2206
24P4C12v.l: 2171 cccccaccgtccagccatccaacctcacttcgccttacaggtctccattttgtggtaaaa 2230
I II I I II II I II I II II I I I I II II I II II I I II I I II I I II I I II I I I II I I I I I I I II 24P4C12v.8: 2207 cccccaccgtccagccatccaacctcacttcgccttacaggtctccattttgtggtaaaa 2266
24P4C12v.l: 2231 aaaggttttaggccaggcgccgtggctcacgcctgtaatccaacactttgagaggctgag 2290
IIIIMIMM I I IMMIII II I I I I I I M II II I II I II I U II U II II II 111111 24P4C12v.8t 2267 aaaggttttaggccaggcgccgtggctcacgcctgtaatccaacactttgagaggctgag 2326
24P4C12V.1-. 2291 gcgggcggatcacctgagtcaggagttcgagaccagcctggccaacatggtgaaacctcc 2350
Mill I Mill I III II I II MM I II I I I II I III III II III III I II III I 24P4C12v.8: 2327 gcgggcggatcacctgagtcaggagttcgagaccagcctggccaacatggtgaaacctcc 2386
24P4C12v.l: 2351 gtctctattaaaaatacaaaaattagccgagagtggtggcatgcacctgtcatcccagct 2410
MM III MM I Mill II I II III I III I II I I I I I I I I MM I IMMIII I I II I II 24P4C12v.8: 2387 gtctctattaaaaatacaaaaattagccgagagtggtggcatgcacctgtcatcccagct 2446
24P4C12v.l: 2411 actcgggaggctgaggcaggagaatcgcttgaacccgggaggcagaggttgcagtgagcc 2470
MM II II I I II lllll II IIIl I II I I I II II II IIIl II I I II M M M II U I II II 24P4C12v.8: 2447 actcgggaggctgaggcaggagaatcgcttgaacccgggaggcagaggttgcagtgagcc 2506
24P4C12v.l: 2471 gagatcgcgccactgcactccaacctgggtgacagactctgtctccaaaacaaaacaaac 2530
II II I II I II I II I I II I I I II I II II II I II II II I I I II II I I I II II I I I I I II II I 24P4C12v.8: 2507 gagatcgcgccactgcactccaacctgggtgacagactctgtctccaaaacaaaacaaac 2566
24P4C12v.l: 2531 aaacaaaaagattttattaaagatattttgttaactcagtaaaaaaaaaaaaaaaaa 2587
I I II II II II I II MM II II II I I I I II I II I II I II I II II I II II II M I I I II 24P4C12v.8: 2567 aaacaaaaagattttattaaagatattttgttaactcagtaaaaaaaaaaaaaaaaa 2623
Table XiVXXI. Peptide sequences of protein coded by 24P4C12 v.8 (SEQ ID NO: 103)
MGGKQRDEDD EAYGKPVKYD PSFRGPIKNR SCTDVICCVL FLLFILGYIV VGIVAWLYGD 60
PRQVLYPRNS TGAYCGMGEN KDKPYLLYFN IFSCILSSNI ISVAENGLQC PTPQVCVSSC 120
PEDPWTVGKN EFSQTVGEVF YTKNRNFCLP GVPWNMTVIT SLQQELCPSF LLPSAPALGR 180
CFPWTNVTPP ALPGITNDTT IQQGISGLID SLNARDISVK IFEDFAQSWY WILVALGVAL 240
VLSLLFILLL RLVAGPLVLV LILGVLGVLA YGIYYCWEEY RVLRDKGASI SQLGFTTNLS 300
AYQSVQETWL AALIVLAVLE AILLLMLIFL RQRIRIAIAL LKEASKAVGQ MMSTMFYPLV 360
TFVLLLICIA YWAMTALYLA TSGQPQYVLW ASNISSPGCE KVPINTSCNP TAHLVNSSCP 420
GLMCVFQGYS SKGLIQRSVF NLQIYGVLGL FWTLNWVLAL GQCVLAGAFA SFYWAFHKPQ 480
DIPTFPLISA FIRTLRYHTG SLAFGALILT LVQIARVILE YIDHKLRGVQ NPVARCIMCC 540
FKCCLWCLEK FIKFLNRNAY IMIAIYGKNF CVSAKNAFML LMRNIVRVW LDKVTDLLLF 600
FGKLLWGGV GVLSFFFFSG RIPGLGKDFK SPHLNYYWLP IMRNPITPTG HVFQTSILGA 660
YVIASGFFSV FGMCVDTLFL CFLEDLERNN GSLDRPYYMS KSLLKILGKK NEAPPDNKKR 720
KK 722
Table LIX. Amino acid sequence alignment of 24P4C12v.l v.1 (SEQ ID NO: 104) and 24P4C12 v.8 (SEQ ID NO: 105)
Score = 1438 bits (3722), Expect = 0. Oldentities = 710/722 (98%), Positives = 710/722 (98%), Gaps = 12/722 (1%)
24P4C12V.1: 1 MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 60
MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 24P4C12V.8: 1 MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 60
24P4C12v.l: 61 PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 120
PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 24P4C12v.8: 61 PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 120
24P4C12V.1: 121 PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 180
PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 24P4C12V.8: 121 PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 180
24P4C12v.lt 181 CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVALGVAL 240
CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVALGVAL 24P4C12v.8: 181 CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNAR-.ISVKIFEDFAQSWYWILVALGVAL 240
24P4C12V.1: 241 VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS 300 VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS
24P4C12v.8 241 VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS 300 24P4C12V.1 301 AYQSVQETWLAALIVLAVLEAILLLMLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 360
AYQSVQETWLAALIVI-AVLEAILLLMLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 24P4C12V.8 301 AYQSVQETWLAALIVLAVLEAILLLMLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 360 24P4C12v.l 361 TFVLLLICIAYWAMTALYLATSGQPQYVLWASNISSPGCEKVPINTSCNPTAHLVNSSCP 420
TFVLLLICIAYWAMTALYLATSGQPQYVLWASNISSPGCEKVPINTSCNPTAHLVNSSCP 24P4C12v.8 361 TFVLLLICIAYWAMTALYLATSGQPQYVLWASNISSPGCEKVPINTSCNPTAHLVNSSCP 420 24P4C12V.1 421 GLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFHKPQ 480
GLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFHKPQ 24P4C12v.8 421 GLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFHKPQ 480 24P4C12v.l 481 DIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCIMCC 540
DIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCIMCC 24P4C12v.8 481 DIPTFPLISAFIRTLRYHTGΞLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCIMCC 540 24P4C12V.1 541 FKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDLLLF 600
FKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDLLLF 24P4C12V.8 541 FKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDLLLF 600 24P4C12V.1 601 FGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIM TSILGA 648
FGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIM TSILGA 24P4C12v.8 601 FGKLLVVGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMRNPITPTGHVFQTSILGA 660 24P4C12V.1 649 YVIASGFFSVFGMCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKR 708
YVIASGFFSVFGMCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKR 24P4C12V.8 661 YVIASGFFSVFGMCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKR 720 24P4C12V.1 709 KK 710
KK 24P4C12v.8 721 KK 722
Table I-X. Nucleotide sequence of transcript variant 24P4C12 v.9 (SEQ ID NO: 106) gagccatggg gggaaagcag cgggacgagg atgacgaggc ctacgggaag ccagtcaaat 60 acgacccctc ctttcgaggc cccatcaaga acagaagctg cacagatgtc atctgctgcg 120 tcctcttcct gctcttcatt ctaggttaca tcgtggtggg gattgtggcc tggttgtatg 180 gagacccccg gcaagtcctc taccccagga actctactgg ggcctactgt ggcatggggg 240 agaacaaaga taagccgtat ctcctgtact tcaacatctt cagctgcatc ctgtccagca 300 acatcatctc agttgctgag aacggcctac agtgccccac accccaggtg tgtgtgtcct 360 cctgcccgga ggacccatgg actgtgggaa aaaacgagtt ctcacagact gttggggaag 420 tcttctatac aaaaaacagg aacttttgtc tgccaggggt accctggaat atgacggtga 480 tcacaagcct gcaacaggaa ctctgcccca gtttcctcct cccctctgct ccagctctgg 540 ggcgctgctt tccatggacc aacgttactc caccggcgct cccagggatc accaatgaca 600 ccaccataca gcaggggatc agcggtctta ttgacagcct caatgcccga gacatcagtg 660 ttaagatctt tgaagatttt gcccagtcct ggtattggat tcttgttgcc ctgggggtgg 720 ctctggtctt gagcctactg tttatcttgc ttctgcgcct ggtggctggg cccctggtgc 780 tggtgctgat cctgggagtg ctgggcgtgc tggcatacgg catctactac tgctgggagg 840 agtaccgagt gctgcgggac aagggcgcct ccatctccca gctgggtttc accaccaacc 900 tcagtgccta ccagagcgtg caggagacct ggctggccgc cctgatcgtg ttggcggtgc 960 ttgaagccat cctgctgctg atgctcatct tcctgcggca gcggattcgt attgccatcg 1020 ccctcctgaa ggagg cagc aaggctgtgg gacagatgat gtctaccatg ttctacccac 1080 tggtcacctt tgtcctcctc ctcatctgca ttgcctactg ggccatgact gctctgtatc 1140 ctctgcccac gcagccagcc actcttggat atgtgctctg ggcatccaac atcagctccc 1200 ccggctgtga gaaagtgcca ataaatacat catgcaaccc cacggcccac cttgtgaact 1260 cctcgtgccc agggctgatg tgcgtcttcc agggctactc atccaaaggc ctaatccaac 1320 gttctgtctt caatctgcaa atctatgggg tcctggggct cttctggacc cttaactggg 1380 tactggccct gggccaatgc gtcctcgctg gagcctttgc ctccttctac tgggccttcc 1440 acaagcccca ggacatccct accttcccct taatctctgc cttcatccgc acactccgtt 1500 accacactgg gtcattggca tttggagccc tcatcctgac ccttgtgcag atagcccggg 1560 tcatcttgga gtatattgac cacaagctca gaggagtgca gaaccctgta gcccgctgca 1620 tcatgtgctg tttcaagtgc tgcctctggt gtctggaaaa atttatcaag ttcctaaacc 1680 gcaatgcata catcatgatc gccatctacg ggaagaattt ctgtgtctca gccaaaaatg 1740 cgttcatgct actcatgcga aacattgtca gggtggtcgt cctggacaaa gtcacagacc 1800 tgctgctgtt ctttgggaag ctgctggtgg tcggaggcgt gggggtcctg tccttctttt 1860 ttttctccgg tcgcatcccg gggctgggta aagactttaa gagcccccac ctcaactatt 1920 actggctgcc catcatgacc tccatcctgg gggcctatgt catcgccagc ggcttcttca 1980 gcgttttcgg catgtgtgtg gacacgctct tcctctgctt cctggaagac ctggagcgga 2040
acaacggctc cctggaccgg ccctactaca tgtccaagag ccttctaaag attctgggca 2100 agaagaacga ggcgcccccg gacaacaaga agaggaagaa gtgacagctc cggccctgat 2160 ccaggactgc accccacccc caccgtccag ccatccaacc tcacttcgcc ttacaggtct 2220 ccattttgtg gtaaaaaaag gttttaggcc aggcgccgtg gctcacgcct gtaatccaac 2280 actttgagag gctgaggcgg gcggatcacc tgagtcagga gttcgagacc agcctggcca 2340 acatggtgaa acctccgtct ctattaaaaa tacaaaaatt agccgagagt ggtggcatgc 2400 acctgtcatc ccagctactc gggaggctga ggcaggagaa tcgcttgaac ccgggaggca 2460 gaggttgcag tgagccgaga tcgcgccact gcactccaac ctgggtgaca gactctgtct 2520 ccaaaacaaa acaaacaaac aaaaagattt tattaaagat attttgttaa ctcagtaaaa 2580 aaaaaaaaaa aaa 2593
Table LXI. Nucleotide sequence alignment of 24P4C12v.l v.1 (SEQ ID NO: 107) and 24P4C12 V.9 (SEQ ID NO: 108)
Score = 2188 bits (1138), Expect = 0. Oldentities = 1138/1138 (100%) Strand = Plus / Plus
24P4C12v.l: 1 gagccatggggggaaagcagcgggacgaggatgacgaggcctacgggaagccagtcaaat 60
II II I II II I I II I I II I II II II II I II I I I I I I I I II I II I II II I I I II I I I II I I I 24P4C12v.9: 1 gagccatggggggaaagcagcgggacgaggatgacgaggcctacgggaagccagtcaaat 60
24P4C12v.l: 61 acgacccctcctttcgaggccccatcaagaacagaagctgcacagatgtcatctgctgcg 120
II II II I I II II II II II I II I I II II II I II II I I I I I I I I I II I I I I I III I I II I I I 24P4C12v.9: 61 acgacccctcctttcgaggccccatcaagaacagaagctgcacagatgtcatctgctgcg 120
24P4C12v.l: 121 tcctcttcctgctcttcattctaggttacatcgtggtggggattgtggcctggttgtatg 180
II II I II I II II II I I I I II II II I II I II II I II I I II I I II I II II II III I II II I I 24P4C12v.9: 121 tcctcttcctgctcttcattctaggttacatcgtggtggggattgtggcctggttgtatg 180
24P4C12v.l: 181 gagacccccggcaagtcctctaccccaggaactctactggggcctactgtggcatggggg 240
I II I II II I II I II I II I II I I II II I I II I II II I I II I II I II II I II I I I I I II II I 24P4C12v,9: 181 gagacccccggcaagtcctctaccccaggaactctactggggcctactgtggcatggggg 240
24P4C12v.l: 241 agaacaaagataagccgtatctcctgtacttcaacatcttcagctgcatcctgtccagca 300
I I I I I II I II III I I I II II I II II II I II II II I I I I III II IIIl I I IIIl I I II II I 24P4C12v.9: 241 agaacaaagataagccgtatctcctgtacttcaacatcttcagctgcatcctgtccagca 300
24P4C12v.l: 301 acatcatctcagttgctgagaacggcctacagtgccccacaccccaggtgtgtgtgtcct 360
II II II I II I I I I II II II I I II II II I II II II II II III II UK I I II III I III II 24P4C12v.9: 301 acatcatctcagttgctgagaacggcctacagtgccccacaccccaggtgtgtgtgtcct 360
24P4C12v.lt 361 cctgcccggaggacccatggactgtgggaaaaaacgagttctcacagactgttggggaag 420
II I I I I I I I I I II II II I I I I I II II I I I I I I I I I II I III I I I II II I I I II I I II I II 24P4C12v,9: 361 cctgcccggaggacccatggactgtgggaaaaaacgagttctcacagactgttggggaag 420
24P4C12v.l: 421 tcttctatacaaaaaacaggaacttttgtctgccaggggtaccctggaatatgacggtga 480
II II II II II I II I I I III I II I I I II II I I II II I II I I I I I I II I I I I III I II I I I I 24P4C12v.9: 421 tcttctatacaaaaaacaggaacttttgtctgccaggggtaccctggaatatgacggtga 480
24P4C12v.l: 481 tcacaagcctgcaacaggaactctgccccagtttcctcctcccctctgctccagctctgg 540
II I I I I I II II II I I I I MM II II II I I I II I I I I I I I II I I I II II I Mill I I I II I 24P4C12v,9: 481 tcacaagcctgcaacaggaactctgccccagtttcctcctcccctctgctccagctctgg 540
24P4C12v.l: 541 ggcgctgctttccatggaccaacgttactccaccggcgctcccagggatcaccaatgaca 600
I I I I I I II I I I II I I II I II II I I II I I I I I II I I I I I I II I I I I I I I I II III I I II I I 24P4C12v.9: 541 ggcgctgctttccatggaccaacgttactccaccggcgctcccagggatcaccaatgaca 600
24P4C12v.l: 601 ccaccatacagcaggggatcagcggtcttattgacagcctcaatgcccgagacatcagtg 660 II II I II II II I I I I I II III II I I I II II I I I M I I I I III I I III I II I Ml II II I I
24P4C12v.9t 601 ccaccatacagcaggggatcagcggtcttattgacagcctcaatgcccgagacatcagtg 660
24P4C12v.lt 661 ttaagatctttgaagattttgcccagtcctggtattggattcttgttgccctgggggtgg 720 II I II I I II II I II II I II I I I I I I I I I I I I I I I I I I I I I I I I I II I II MM I II II II
24P4C12v.9t 661 ttaagatctttgaagattttgcccagtcctggtattggattcttgttgccctgggggtgg 720
24P4C12v.lt 721 ctctggtcttgagcctactgtttatcttgcttctgcgcctggtggctgggcccctggtgc 780 II I I I I I I I I I I I I II II II I I II I I I I I II II II II II I I I I I I I I I I II I II II I II I
24P4C12v.9t 721 ctctggtcttgagcctactgtttatcttgcttctgcgcctggtggctgggcccctggtgc 780
24P4C12v.lt 781 tggtgctgatcctgggagtgctgggcgtgctggcatacggcatctactactgctgggagg 840 I I I I I I I I I II I I I I I I II I II I I I I I II II II II I I I I I Ml II I II I I I II I II I I I I
24P4C12v.9t 781 tggtgctgatcctgggagtgctgggcgtgctggcatacggcatctactactgctgggagg 840
24P4C12v.lt 841 agtaccgagtgctgcgggacaagggcgcctccatctcccagctgggtttcaccaccaacc 900 II II I I II I I I I I I II I II I I II II II I II I I II I II II I I II II I I I I II I I I II I I I I
24P4C12v.9t 841 agtaccgagtgctgcgggacaagggcgcctccatctcccagctgggtttcaccaccaacc 900
24P4C12v.l: 901 tcagtgcctaccagagcgtgcaggagacctggctggccgccctgatcgtgttggcggtgc 960 II I I I I I II I I I I II I I II I I II II II II I I I II I I II II I I II I I I II II I I I I I II I I
24P4C12V.9: 901 tcagtgcctaccagagcgtgcaggagacctggctggccgccctgatcgtgttggcggtgc 960
24P4C12v.lt 961 ttgaagccatcctgctgctgatgctcatcttcctgcggcagcggattcgtattgccatcg 1020 I II I II I I I I I I I I II I I II I II I I I I I I I I I II I I II I I I I II I I II II I I I I I I I I I I
24P4C12v.9t 961 ttgaagccatcctgctgctgatgctcatcttcctgcggcagcggattcgtattgccatcg 1020
24P4C12v.lt 1021 ccctcctgaaggaggccagcaaggctgtgggacagatgatgtctaccatgttctacccac 1080
II II II II I II I I I II I II II I I I II II II I I I I I I II II II I II I I II II I I I I II II I 24P4C12v.9t 1021 ccctcctgaaggaggccagcaaggctgtgggacagatgatgtctaccatgttctacccac 1080
24P4C12v.l: 1081 tggtcacctttgtcctcctcctcatctgcattgcctactgggccatgactgctctgta 1138
II II I II II II II I I I I I I II I II I II I II I II I I I I I I II I II II I I I II II I I II I 24P4C12v.9t 1081 tggtcacctttgtcctcctcctcatctgcattgcctactgggccatgactgctctgta 1138
Score = 2738 bits (1424), Expect = 0. Oldentities = 1424/1424 (100%) Strand = Plus / Plus
24P4C12v.lt 1164 tatgtgctctgggcatccaaσatcagctcccccggctgtgagaaagtgccaataaataca 1223
II I I I I I I I I I I I I I I I I I I I II I I II I I II I I I I I I I II I I I I I I I II I I II I I I I I II 24P4C12v.9: 1170 tatgtgctctgggcatccaacatcagctcccccggctgtgagaaagtgccaataaataca 1229
24P4C12v. It 1224 tcatgcaaccccacggcccaccttgtgaactcctcgtgcccagggctgatgtgcgtcttc 1283
II I I II II II I II I I I I I I II II I I II I II I I I II II II I I I I I I I I II II I II II II II 24P4C12v.9 1230 tcatgcaaccccacggcccaccttgtgaactcctcgtgcccagggctgatgtgcgtcttc 1289
24P4C12v.lt 1284 cagggctactcatccaaaggcctaatccaacgttctgtcttcaatctgcaaatctatggg 1343
I I I I I II I II II I I I I II II II I II I I I I I I I I II I I I II I II I I I I I I I I I II II II I I
24P4C12v.9t 1290 cagggctactcatccaaaggcctaatccaacgttctgtcttcaatctgcaaatctatggg 1349
24P4C12v.lt 1344 gtcctggggctcttctggacccttaactgggtactggccctgggccaatgcgtcctcgct 1403
I I I I I II II I II I I I II I I I I I I I I I II I I I I I I I I I I I I II I I I II I I I I I I I I I I I I I
24P4C12v.9: 1350 gtcctggggctcttctggacccttaactgggtactggccctgggccaatgcgtcctcgct 1409
24P4C12v.1: 1404 ggagcctttgcctccttctactgggccttccacaagccccaggacatccctaccttcccc 1463
II II II II I II I I I I I I I I I II I I I I I I I I I I II I III II II I II I I I I I I I II I II I I I
24P4C12v.9: 1410 ggagcctttgcctccttctactgggccttccacaagccccaggacatccctaccttcccc 1469
P4C12v.l: 1464 ttaatctctgccttcatccgcacactccgttaccacactgggtcattggcatttggagcc 1523
I I II II I I I II II I II I I I I I I I I I I II I II II I I II II II II II I I II I II II II I I I I P4C12v.9: 1470 ttaatctctgccttcatccgcacactccgttaccacactgggtcattggcatttggagcc 1529
P4C12v.l: 1524 ctcatcctgacccttgtgcagatagcccgggtcatcttggagtatattgaccacaagctc 1583
I II I I I II I II II I I II II I II I II I I I II II II II I I I I I I II II I I II II I I I II I I I P4C12v.9: 1530 ctcatcctgacccttgtgcagatagcccgggtcatcttggagtatattgaccacaagctc 1589
P4C12v.l: 1584 agaggagtgcagaaccctgtagcccgctgcatcatgtgctgtttcaagtgctgcctctgg 1643
II II II I I I III II I I I I II I I I II II I I I I II I I II I II I II I II II II I I I I II I I I I P4C12v.9: 1590 agaggagtgcagaaccctgtagcccgctgcatcatgtgctgtttcaagtgctgcctctgg 1649
P4C12v.l: 1644 tgtctggaaaaatttatcaagttcctaaaccgcaatgcatacatcatgatcgccatctac 1703
II I I I I II I II II I II II I II I I II I I I II I I II I II I I II I I II I I I II II I I I I II II P4C12v.9: 1650 tgtctggaaaaatttatcaagttcctaaaccgcaatgcatacatcatgatcgccatctac 1709
P4C12v.lt 1704 gggaagaatttctgtgtctcagccaaaaatgcgttcatgctactcatgcgaaacattgtc 1763 II I I II II I I I I I I I I I I I I I I II II I I II II II I I II II II I I II II II II II II II I I P4C12v.9t 1710 gggaagaatttctgtgtctcagccaaaaatgcgttcatgctactcatgcgaaacattgtc 1769
P4C12v.lt 1764 agggtggtcgtcctggacaaagtcacagacctgctgctgttctttgggaagctgctggtg 1823
II I I II I II I I I I I II I I II I II I I II I I I II I I I I I II I I I I I I I II I I I I I I I II I I I P4C12v.9t 1770 agggtggtcgtcctggacaaagtcacagacctgctgctgttctttgggaagctgctggtg 1829
P4C12v.lt 1824 gtcggaggcgtgggggtcctgtccttcttttttttctccggtcgcatcccggggctgggt 1883
I II I I I I I I I I I II I II I I I I I I I I I I I II II II I II I II I I I I II II I II I II II II I I P4C12v.9: 1830 gtcggaggcgtgggggtcctgtccttcttttttttctccggtcgcatcccggggctgggt 1889
P4C12v.l: 1884 aaagactttaagagcccccacctcaactattactggctgcccatcatgacctccatcctg 1943
I I I I II II I II II II I I I I I I II II I II II II II II I II I I I I I II II I II II II II I II P4C12v.9: 1890 aaagactttaagagcccccacctcaactattactggctgcccatcatgacctccatcctg 1949
P4C12v.l: 1944 ggggcctatgtcatcgccagcggcttcttcagcgttttcggcatgtgtgtggacacgctc 2003
I I I I I II I I I I II I I I I I I I I I II I I I I I I I I I I I I I I I I I I I I I I II I II II I II I II I P4C12v.9: 1950 ggggcctatgtcatcgccagcggcttcttcagcgttttcggcatgtgtgtggacacgctc 2009
P4C12v.l: 2004 ttcctctgcttcctggaagacctggagcggaacaacggctccctggaccggccctactac 2063
I I I I I I I I I I I II I I I I I I I I I I II I I II I I I I I I I I II I I I I I I I II II II I I II II II P4C12v.9: 2010 ttcctctgcttcctggaagacctggagcggaacaacggctccctggaccggccctactac 2069
P4C12v.l: 2064 atgtccaagagccttctaaagattctgggcaagaagaacgaggcgcccccggacaacaag 2123
I II II I II I II III II II II I I I I I I I I I I II I I II II I I I I I I I II I I I II I I I I I I II P4C12v.9: 2070 atgtccaagagccttctaaagattctgggcaagaagaacgaggcgcccccggacaacaag 2129
P4C12v.l: 2124 aagaggaagaagtgacagctccggccctgatccaggactgcaccccacccccaccgtcca 2183
I II I I I II I I I I I II II I I I I I I I I I I I I I I II I I I I I I II I I I II II I I I II I I I I I I I P4C12v.9: 2130 aagaggaagaagtgacagctccggccctgatccaggactgcaccccacccccaccgtcca 2189
P4C12v.l: 2184 gccatccaacctcacttcgccttacaggtctccattttgtggtaaaaaaaggttttaggc 2243
I I I I I I I II I I I I II I II I I I I I I II I I I I I I I I I I I I I I I I II I I I I I I I I II I I II II P4C12v,9: 2190 gccatccaacctcacttcgccttacaggtctccattttgtggtaaaaaaaggttttaggc 2249
P4C12v.l: 2244 caggcgccgtggctcacgcctgtaatccaacactttgagaggctgaggcgggcggatcac 2303
II I I II I II II I I II II I I I I I II I I I I I I I I I I I I I I I I I I I I I II I II I I I I I I II I I P4C12v.9: 2250 caggcgccgtggctcacgcctgtaatccaacactttgagaggctgaggcgggcggatcac 2309
24P4C12v.l: 2304 ctgagtcaggagttcgagaccagcctggccaacatggtgaaacctccgtctctattaaaa 2363 I I I III II I II I II II II II I I I II II II I II II I I I I I I I I I I I I I I I II I I I I I I I I I
24P4C12V.9: 2310 ctgagtcaggagttcgagaccagcctggccaacatggtgaaacctccgtctctattaaaa 2369
24P4C12v.l: 2364 atacaaaaattagccgagagtggtggcatgcacctgtcatcccagctactcgggaggctg 2423 I I I I I I I I II II I II I III II I II I I II I I II II I I I I I I I I I I II I II II II I II I II I
24P4C12v.9: 2370 atacaaaaattagccgagagtggtggcatgcacctgtcatcccagctactcgggaggctg 2429
24P4C12v.l: 2424 aggcaggagaatcgcttgaacccgggaggcagaggttgcagtgagccgagatcgcgccac 2483
II I MM II II II I I I I II I II I I I I II I I I I I I I I II I I I II I I I I I II II I I I I I I I I 24P4C12v.9: 2430 aggcaggagaatcgcttgaacccgggaggcagaggttgcagtgagccgagatcgcgccac 2489
24P4C12v.l: 2484 tgcactccaacctgggtgacagactctgtctccaaaacaaaacaaacaaacaaaaagatt 2543
II II I I II II I I II II I II I I I II I I II I I I I I I I I I I I I I I I II I I I I I II I I II I I II 24P4C12v.9: 2490 tgcactccaacctgggtgacagactctgtctccaaaacaaaacaaacaaacaaaaagatt 2549
24P4C12v.l: 2544 ttattaaagatattttgttaactcagtaaaaaaaaaaaaaaaaa 2587
I I I I II I I II II II I I I II I II I I II II I I II I I I I II II I II I 24P4C12v.9: 2550 ttattaaagatattttgttaactcagtaaaaaaaaaaaaaaaaa 2593
Table LXII. Peptide sequences of protein coded by 24P4C12 v.9 (SEQ ID NO: 109)
MGGKQRDEDD EAYGKPVKYD PSFRGPIKNR SCTDVICCVL FLLFILGYIV VGIVAWLYGD 60 PRQVLYPRNS TGAYCGMGEN KDKPYLLYF IFSCILSSNI ISVAENGLQC PTPQVCVSSC 120 PEDPWTVGKN EFSQTVGEVF YTKNRNFCLP GVPWNMTVIT SLQQELCPSF LLPSAPALGR 180 CFPWTNVTPP ALPGITNDTT IQQGISGLID SLNARDISVK IFEDFAQSWY WILVALGVAL 240 VLSLLFILLL RLVAGPLVLV LILGVLGVLA YGIYYCWEEY RVLRDKGASI SQLGFTTNLS 300 AYQSVQETWL AALIVLAVLE AILLLMLIFL RQRIRIAIAL LKEASKAVGQ MMSTMFYPLV 360 TFVLLLICIA YWAMTALYPL PTQPATLGYV LWASNISSPG CEKVPINTSC NPTAHLVNSS 420 CPGLMCVFQG YSSKGLIQRS VFNLQIYGVL GLFWTLNWVL ALGQCVLAGA FASFYWAFHK 480 PQDIPTFPLI SAFIRTLRYH TGSLAFGALI LTLVQIARVI LEYIDHKLRG VQNPVARCIM 540 CCFKCCLWCL EKFIKFLNRN AYIMIAIYGK NFCVSAKNAF MLLMRNIVRV WLDKVTDLL 600 LFFGKLLWG GVGVLSFFFF SGRIPGLGKD FKSPHLNYYW LPIMTSILGA YVIASGFFSV 660 FGMCVDTLFL CFLEDLERNN GSLDRPYYMS KSLLKILGKK NEAPPDNKKR KK 712
Table LXIII. Amino acid sequence alignment of 24P4C12v.l v.1 (SEQ ID NO: 110) and 24P4C12 v.9 (SEQ ID NO: 111)
Score = 1424 bits (3686), Expect = 0. Oldentities = 704/713 (98%), Positives = 705/713 (98%), Gaps = 4/713 (0%)
24P4C12V.1: 1 MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 60
MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 24P4C12V.9: 1 MGGKQRDEDDEAYGKPVKYDPSFRGPIKNRSCTDVICCVLFLLFILGYIWGIVAWLYGD 60
24P4C12v.lt 61 PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 120
PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 24P4C12V.9: 61 PRQVLYPRNSTGAYCGMGENKDKPYLLYFNIFSCILSSNIISVAENGLQCPTPQVCVSSC 120
24P4C12V.1: 121 PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 180
PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 24P4C12V.9: 121 PEDPWTVGKNEFSQTVGEVFYTKNRNFCLPGVPWNMTVITSLQQELCPSFLLPSAPALGR 180
24P4C12v.lt 181 CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVALGVAL 240
CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVALGVAL 24P4C12V.9: 181 CFPWTNVTPPALPGITNDTTIQQGISGLIDSLNARDISVKIFEDFAQSWYWILVALGVAL 240
24P4C12V.1: 241 VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS 300
VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS 24P4C12V.9: 241 VLSLLFILLLRLVAGPLVLVLILGVLGVLAYGIYYCWEEYRVLRDKGASISQLGFTTNLS 300
24P4C12v.lt 301 AYQSVQETWLAALIVLAVLEAILLLMLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 360
AYQSVQETWLAALIVLAVLEAILLLMLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 24P4C12v.9t 301 AYQSVQETWLAALIVI-AVLEAILLI-MLIFLRQRIRIAIALLKEASKAVGQMMSTMFYPLV 360
P4C12v.lt 361 TFVLLLICIAYWAMTALYLATSGQPQ YVLWASNISSPGCEKVPINTSCNPTAHLVNS 417
TFVLLLICIAYWAMTALY + QP YVLWASNISSPGCEKVPINTSCNPTAHLVNS P4C12V.9: 361 TFVLLLICIAYWAMTALYPLPT-QPATLGYVLWASNISSPGCEKVPINTSCNPTAHLVNS 419 P4C12v.lt 418 SCPGLMCVFQGYSSKGLIQRΞVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFH 477
SCPGLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFH P4C12v.9t 420 SCPGLMCVFQGYSSKGLIQRSVFNLQIYGVLGLFWTLNWVLALGQCVLAGAFASFYWAFH 479 P4C12v.l: 478 KPQDIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCI 537
KPQDIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCI P4C12V.9: 480 KPQDIPTFPLISAFIRTLRYHTGSLAFGALILTLVQIARVILEYIDHKLRGVQNPVARCI 539 P4C12v.lt 538 MCCFKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLD-VTDL 597
MCCFKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDL P4C12v.9: 540 MCCFKCCLWCLEKFIKFLNRNAYIMIAIYGKNFCVSAKNAFMLLMRNIVRVWLDKVTDL 599 P4C12v.l: 598 LLFFGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMTSILGAYVIASGFFS 657
LLFFGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMTSILGAYVIASGFFS P4C12V.9: 600 LLFFGKLLWGGVGVLSFFFFSGRIPGLGKDFKSPHLNYYWLPIMTSILGAYVIASGFFS 659 P4C12v.lt 658 VFGMCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKRKK 710
VFGMCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKRKK P4C12v.9t 660 VFGMCVDTLFLCFLEDLERNNGSLDRPYYMSKSLLKILGKKNEAPPDNKKRKK 712