WO2012072445A1 - Method and apparatus of communications - Google Patents
Method and apparatus of communications Download PDFInfo
- Publication number
- WO2012072445A1 WO2012072445A1 PCT/EP2011/070631 EP2011070631W WO2012072445A1 WO 2012072445 A1 WO2012072445 A1 WO 2012072445A1 EP 2011070631 W EP2011070631 W EP 2011070631W WO 2012072445 A1 WO2012072445 A1 WO 2012072445A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- learning
- network
- state
- parameters
- action
- Prior art date
Links
Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/08—Configuration management of networks or network elements
- H04L41/0803—Configuration setting
- H04L41/0823—Configuration setting characterised by the purposes of a change of settings, e.g. optimising configuration for enhancing reliability
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/16—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks using machine learning or artificial intelligence
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04W—WIRELESS COMMUNICATION NETWORKS
- H04W24/00—Supervisory, monitoring or testing arrangements
- H04W24/02—Arrangements for optimising operational condition
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/14—Network analysis or design
- H04L41/142—Network analysis or design using statistical or mathematical methods
Definitions
- the technical field of multi-user communications provides relevant art of technology for this specification of an invention. This may also be the case for a technical field of short-range radio communications or surface covering wireless communications; or operations, management or configuration of wireless communication networks. This may particularly be the case for a technical field of local awareness and local or distributed control of communication networks.
- Wireless communications provide a means of communicating across a distance by means of electromagnetic signals.
- a communications network being wireless to an ever increasing extent; some of the challenges of surface covering wireless communications; such as resource sensing and allocation, interference prediction, and decision making therefore has be approached in the art 15 in order to provide for increased automation of network maintenance and administration.
- 3GPP TR 36.902 V9.2.0 Technical report; 3rd Generation Partnership Project; 3rd Generation Partnership Project; Technical Specification Group Radio Access Network; Evolved Universal Terrestrial Radio Access Network (E-UTRAN), Self-configuring and self- optimizing network (SON) use cases and solutions(Release 9), France, June 2010, discusses e.g. automated configuration of Physical Cell Identity, Mobility Robustness and setting of HO (handover) parameters, Mobility Load Balancing, RACH (Random Access Channel) configuration, maintaining and building neighbor relationships, and inter-cell interference coordination. Particularly, it has been concluded that reduction of operational efforts and complexity improves system operability in a multi-vendor environment.
- United States Patent No. US6829491 provides a communication network subject to dynamic optimization using network operation metrics, such as may be acquired from a network controller such as a mobile switching center. Implementation of the parameter adjustments are modeled to determine if further or different operational parameter adjustments should be determined.
- network operation metrics such as may be acquired from a network controller such as a mobile switching center.
- Implementation of the parameter adjustments are modeled to determine if further or different operational parameter adjustments should be determined.
- the document mentions that a network may be load-unbalanced due to unusually dense subscriber populations (e.g. sports arenas during sports events). It concludes that it would be advantageous to have a method and system for dynamically monitoring of network communication metrics, inclusive of metrics associated with communications as provided through a plurality of network resources. Accordingly, operation parameters may thereby be redistributed dynamically as a result of modeling and estimation of network system parameters as a function of network performance information. Summary
- a method of controlling a telecommunications network comprising at least one device arranged for interaction as regards network configuration 20 parameters is disclosed. Examples of learning systems and network optimization during run-time are provided facilitating adaptation to a system state.
- FIG. 1 illustrates a typical Cognitive Engine, CE, in accordance with the invention.
- Figure 2 shows a system architecture illustrating functionality in two example independent CSONE entities.
- Figure 3 schematically illustrates a system as preferably described in terms of a
- Figure 4 schematically illustrates determining a best action
- Figure 5 illustrates some example key enabling technologies and solutions in three different dimensions of cooperative operation.
- Figure 6 illustrates schematically sensing monitoring interfaces.
- Figure 7 illustrates communication interfaces of a configuration/decision making and/or execution module
- FIG. 8 illustrates schematically and in accordance with the invention two example Communication/Cooperation/Execution Modules.
- Figure 9 illustrates schematically the interfaces of an optimization module (91) and various entities.
- Figure 10 illustrates a learning example
- Figure 11 illustrates another learning example.
- Figure 12 illustrates a cognitive SON centralized architecture.
- Figure 13 illustrates a cognitive SON distributed architecture with example autonomous cognitive engine.
- Figure 14 illustrates a cognitive SON hybrid network architecture.
- Figure 15 shows SON functionality of cognitive SON.
- Figure 16 illustrates schematically the interactions between two independent processes running in two separate autonomous nodes.
- Figure 17 illustrates a system relating to the invention.
- Figure 18 illustrates three levels of the operation relating to the invention.
- Figure 19 illustrates dimensions of cooperative decision and control relating to the invention.
- Figure 20 illustrates a system relating to the invention.
- Figure 21 illustrates cognitive SON optimisation process.
- Fig.22 illustrates the interactions between two independent processes running in two separate autonomous nodes.
- Figure 23 illustrates the procedure of optimization according to the invention.
- Figure 24 illustrates functionality in two independent CSONE entities according to the invention.
- Figure 25 illustrates a system according to the invention.
- Figure 26 illustrates a system according to the invention.
- Figure 27 illustrates a system according to the invention.
- Figure 28 illustrates optimization functional unit according to the invention.
- Figure 29 illustrates procedure of learning task.
- Figure 30 illustrates an example of learning according to the invention.
- Figure 31 illustrates a cognitive SON centralised architecture.
- Figure 32 illustrates a deployment of the architecture consisting only of CSONE entities.
- Figure 33 illustrates a cognitive SON distributed architecture.
- Figure 34 illustrates a deployment of the above architecture consisting only of CSONE entities.
- Figure 35 illustrates a CSONE hybrid Architecture of central coordination.
- Figure 36 illustrates a CSONE hybrid Architecture of distributed coordination.
- Figure 37 illustrates a deployment of the architecture consisting only of CSONE entities.
- cognitive nodes In order to make such a level of cognition possible, cognitive nodes efficiently represent and store environmental and operational information, since a distinctive characteristic of cognitive radios and cognitive networks is the capability of making decisions and adaptations based on past experience, on current operational conditions, and also possibly on future behavior predictions. A model of an underlying environment in each node provides only partial knowledge. Nodes may therefore cooperate in order to jointly acquire a global or wide-range knowledge of the environment, enabling distributed operations.
- FIG 1 illustrates a typical Cognitive Engine, CE, in accordance with the invention as will be further described in detail below.
- a cognitive node can maintain a model of the local environment that in turn allows for educated communications decision based on the impact of its actions.
- a cognitive node determines or selects decision variables in order to maximize a performance metric, e.g., determining or selecting a power setting value that will lead to (close to) maximum utilization of network resources.
- a cognitive node acts autonomously, as the CE provides the ability to learn and adapt to a changing environment.
- a cognitive engine preferably is adapted to: accurately model dynamics and one or more states of its environment by means of: performance metrics and environment dynamics (physical environment - radio resources)
- a system may change state at any point in time.
- a system's state typically may change many times during its life-time.
- some system states are useful for mapping into an action decision variable while others are not.
- some system states are targeted while others are not. Performing control over the processes aims at steering system transitions to targeted system states e.g., states where the system performs favorably.
- Figure 2 shows a system architecture illustrating functionality in two example independent CSONE entities. Operation in the cognitive SON engine CSONE is supported and realized by means of knowledge stored in a knowledge base. More specifically, each node of the various units or modules as described above preferably maintain a knowledge base (111) comprising facts and rules.
- the knowledge base may be distributed or centralized. Facts are represented by parameter value pairs that build up a model of the environment and itself, i.e. the owner of the facts and the knowledge base. Facts are used to represent information about e.g.
- radio environment inclusive of load and interference level
- configuration settings such as transmitted power settings.
- Rules are preferably represented by parameter-value implications of premise- implies-conclusion type (if ⁇ premise> then ⁇ conclusion).
- a premise is e.g. a rule or a (conjunction of) fact(s), typically of monitoring types.
- a conclusion correspondingly is, e.g., a rule or a (conjunction of) fact(s), typically of configuration type.
- rules apply for all values of parameters of a subset of values as defined by numerical operators.
- Rules may imply rules or facts.
- the set of facts and rules represents a model of the environment in which the knowledge possessing entity interacts.
- the set represents a model of the entity itself including its capabilities, objectives, roles, functions and actions.
- the set of facts and rules represents a model of the environment in which the knowledge possessing entity interacts in and a model of the entity itself including its capabilities, objectives, roles, functions and actions.
- knowledge K consists of facts and rules.
- Facts reflects on apriori knowledge of the environment and the entity itself. It includes among others the system state S set, the actions A set that the entity itself and functions F set.
- Facts and Rules are stored in a Knowledge Base, preferably accessible by all functional units partially or in its entirety.
- a model of the external environment and the rules the environment obeys can be described and stored in the knowledge base.
- An observation and transition model of the environment can be also described in terms of environment states and transitions between states due to events caused by external entities or due to actions taken by the CE itself.
- the environment model is based on a-priori and/or learned knowledge and presented by parameters or parameter functions.
- An cognitive SON engine CSONE is said to learn from experience E with respect to some class of tasks T and performance measure/metrics P, if its performance at tasks in T, as measured by P, improves with experience E.
- a radio node that learns configuration of mobility optimization might improve its mobility performance as measured by its ability to optimally configure mobility parameters through experience obtained by configuring mobility with its neighbors.
- a well-defined learning problem requires a well-defined task, performance metric and training experience.
- Design a learning approach involves a number of design choices, including choosing the type of training experience, the target (or objective) function to be learned, a representation for this function and an algorithm for learning the target function from training examples.
- learning involves searching through a space of possible hypotheses H to find the hypothesis h that best fit the available training examples D and other prior constraints or knowledge.
- h In terms of SON functionality at any one time t, h, would correspond to a state s, and D to the current set observations ⁇ .
- Much of the above optimisation and control functionality is performed by learning methods that search different hypothesis spaces (e.g., numerical functions, decision trees, neural networks, policies, rules) based on different conditions under which these search methods converge toward an optimal hypothesis.
- search different hypothesis spaces e.g., numerical functions, decision trees, neural networks, policies, rules
- Operation of optimization control is performed by learning new facts and rules or by modifying existing rules to improve performance.
- Figure 3 schematically illustrates a system as preferably described in terms of a model.
- a model should ideally represent all entities of the system, their states and procedures not hiding any information from being derived in order to correctly represent the system.
- a system state may typically be specified based on a multiplicity of quantifying parameters of the system model.
- a preferred set of parameters, S provides all the parameters necessary to differentiate between any two system states. Parameters can be monitored, calculated, estimated and/or derived from statistical observations.
- system parameters include
- N is a positive integer.
- a system responds as determined appropriate to a particular system state by means of actions as equipped.
- An action refers to execution of one or multiple instructions during operations of a system.
- an action corresponds to configuration of network nodes that controls operations of the network.
- the actions are arranged to maintain the system in a target state or bring it towards a target state.
- a system operating entity is equipped by a set of actions A which are performed as needed to drive the system towards the goal/target state.
- a goal/target state is, e.g., radio resource allocation for desired throughput performance where the actual allocation corresponds to the action.
- control 7t A (s) refers to the process of identifying an action for any state of the system that is a target state. More specifically, control 7t A (s),
- 7i A (s): S ⁇ A,, (eq. 2) maps a state ss S into action as A .
- An example process of determining a control in accordance with an embodiment of the invention is as follows: For each state of the system, find the best action, A,,, among a given of authorized actions, A,,. In accordance with an embodiment of the invention, determining the best action, A,, is schematically illustrated in figure 4. The determining involves configuring a controller (42) as depicted in the figure. Three levels of operation are preferably considered:
- execution level system function such as any RRM function (43) of a radio network.
- the optimization entity (41) determines a control process 7i(s), preferably optimized in relation to one or more objectives.
- optimizing a control process is understood as determining a policy, i.e. determining relevant control for a preferred set of state variables in order to maximize a utility objective, or minimize a cost/penalty objective, considering the various states.
- Objectives are preferably expressed by means of utility functions (objective functions).
- a utility function is a function that maps from system states preferably to real numbers. As indicated in figure 4, entities of the various operation levels cooperate. Implementing cooperation requires deployment of communication enabling functionality.
- cooperation enablers refer to those mechanisms, procedures and/or protocols which make the collaboration between network nodes and system entities possible. Collaboration spans between information exchange, action coordination and decision making; moreover, such aspects are expected to be exploited in different dimensions thus featuring different communication layers and capabilities.
- Three of the key aspects corresponding to dimensions for decision and control that are based on cooperation or potentially can benefit from it, are:
- two or more nodes may cooperate by simply exchanging information with each other and deciding independently.
- two or more nodes may cooperate by deciding on a coordinated plan of configurations shared between the nodes.
- cooperation may be performed by each layer separately or in a cross-layer fashion.
- a set of enablers for cooperative decision and control is preferably associated.
- the following associations are envisaged: in information/context exchange dimension (or collaboration dimension): - sensing data, configuration settings,
- the first aspect captures the balance between a node's individual objectives and the objectives of the network it belongs to.
- a network objective can be defined as the sum of all nodes' objectives (a "social welfare" objective).
- a node may defer from taking actions that maximize its individual objectives for the benefit of the maximization of network objectives. For instance, a cell may select a lower transmission power setting while this maximizes the overall network throughput (e.g. by causing less interference) at the expense of its local cell throughput performance.
- the opposite would be a node selecting a higher power setting to increase its local cell throughput, thereby possibly causing more interference to neighboring cells, reducing the overall network throughput.
- the second aspect refers to identification of optimal configurations for network operation (e.g. with the least energy consumption) that balance the benefits offered by a fully cooperative (coordinated decisions) and a simpler autonomic (independent decisions) approach. For example this should take into account on one hand that the complete picture can be made available to various parts of a cooperative system (e.g. utilizing information sharing) but this additional fine-grained information and flexibility comes with a cost in signaling to be justified by the expected gains. Also the processing associated with the second aspect (coordinated actions-independent actions) is preferably balanced.
- the invention identifies a number of events causing problems with state parameters or the associated mapping:
- the set of parameters comprises a great number of parameters making the system state description complex.
- the parameter values are noisy e.g., due to traffic and radio channel being
- the environment is stochastic i.e., the transition between system states is not deterministic.
- ⁇ Sensing/Monitoring Unit (102) deals with the observation and state transmission modeling.
- Configuration/Decision Making Unit (103) deals with the action-state modeling for action selection and valuation.
- Interaction Functional Unit (104) deals with interaction modeling for negotiation and communication of decisions and execution/effectuation of selected actions.
- Knowledge base consists of facts and rules describing the models required for the realization of the cognitive SON engine.
- Knowledge base can be a functional unit of its own or maintained and communicated between functional units as depicted above
- the various units communicate over interfaces (105), (106), (107), (108), (109), (110).
- operation in the cognitive engine (also referred to as policy engine) is supported and realized by means of knowledge in terms of fact and rules stored in a data base, a knowledge base (111).
- rules are the various controls of a policy, which is a mapping of S on A.
- FIG. 6 illustrates schematically sensing monitoring interfaces.
- the role of a sensing/monitoring module is, e.g., collection of KPIs, KPI statistical processing, and control of KPI monitoring.
- the sensing module has a monitoring to communication interface (106), (61), MCi. E.g. monitoring parameters and monitoring time-interval are communicated over the MCi.
- the sensing module also has a monitoring to decision interface, MDi, (109), (62).
- System state information is communicated over the MDi.
- monitoring interfaces that are device dependent, such as an interface to RRM (Radio Resource Management) at a base station, or a device interface between a gateway and the sensing module.
- RRM Radio Resource Management
- measurement monitoring interfaces 63), (64) e.g. for monitoring or communication of parameter values or time intervals, such as with a RAT/RAN RRM (Radio Access
- Figure 7 illustrates communication interfaces of a configuration/decision making and/or execution module.
- Configuration/decision making and/or execution module functions comprise e.g., making configuration decisions based on environment state information, radio resource configuration of control, and power and spectrum allocation.
- An example interface (107), (71) facilitates exchange of configuration parameters or information between the configuration/decision making and/or
- the monitoring to decision interface (109), (62), (72) has been explained in relation to figure 6.
- An example interface (between the configuration/decision making and/or execution module (73), (74) provides a device dependent interface for RRM at a base station or for a gateway.
- the interface may comprise two parts, a decision part for exchange of configuration control parameters (to be set) or configuration information (to be collected), and an execution part for exchange of messages configuring a device such as an RRM or a gateway.
- Figure 8 illustrates schematically and in accordance with the invention two example Communication/Cooperation/Execution Modules (81), (82), e.g., comprising functionality for providing ⁇ information exchange, such as.
- configuration information e.g. power, spectrum, interference cancellation, neighbor information
- the two modules communicate with each other over a Ci (Cooperation/Communication Interface) (83) and with other entities such as ⁇ RRM at a base station (84); or
- the execution part (87), (88) comprises e.g.
- the Communication /Execution /Cooperation modules interface an RRM entity/function and a sensor/actuator element/gateway across a Ci/Xi (87), (88) interface (communication/cooperation / execution interface).
- Figure 9 illustrates schematically the interfaces of an optimization module (91) and various entities (92), (93), (94) that the optimization module interfaces (95), (96), (97) in accordance with the invention.
- the optimization module (91) ⁇ classifies one or more states of the environment based on the parameters for single, or multiple objectives.
- the optimization module preferably have a plurality of interfaces (95), (96), (97). There are three different interfaces illustrated. One is intended for monitoring (92), and the other for decision making (97). A third interface between the optimization module and a user of a communication/cooperation module (96) is destined for execution.
- the optimization module is preferably adapted for learning a policy that maps any state of the system to an set of actions that operate favorably according to objectives of an adoption process of the optimization module, this regardless of whether
- policies are maintained and executed centrally or distributed, whether distributed in numerous or functionally.
- the optimization module is adapted to learn, identify and/or provide distinguishable states of the system and the differentiating parameters, an accurate model of environment and the rules governing it for future predictions,
- ⁇ a set of rules that provides efficient and stable operation and fast convergence as the system state changes.
- the set of state is recursively refined by learning, the actions onto which the states are mapped are correspondingly adaptively refined, as are the mapping rule and network parameter settings.
- a set of parameters are preferably identified for a given objective or set of objectives capable of differentiating between any two states of the system.
- Bayesian learning e.g., applied to identify the conditioning and the correlations between parameters indicative to a system state.
- Inductive learning learning rules out of observable facts, e.g., applied for learning a state.
- Neural network learning (learning a function from known examples), e.g. applied for learning a state.
- Instance-based learning learning state functions from similarities and differences between instances, e.g. applied for learning a state.
- An example output is a concise description of system states where organization patterns and operation patterns are uniquely identified, preferably with non or just a few non-explaining states remaining to be considered for the mapping, control or policy. At best there is a solution where each state is described by a minimum number of one or more parameter values or parameter-value pairs.
- Time is also an aspect as the output need provide an accurate result over time. To capture dynamics over time state -transitions are considered.
- Another aspect of the invention is action-state control.
- Methods applicable as such to action-state mapping, control or policy are known as such in the art.
- Non-exclusive examples of such methods are
- Reinforcement learning differs from standard supervised learning in that correct input/output pairs is not required.
- RL is a form of learning that conforms to
- ⁇ actions typically corresponding to value settings or one or more configuration parameters/variable s .
- Q-learning is a particular implementation of RL, where an expected payoff/reward associated with various actions is estimated.
- a controller makes such an estimate.
- Q-learning estimates Q-values recursively.
- a Q-value, Q(s,a) is a value function that provides a numerical estimate of the value of performing an individual action at a given state s of the environment.
- the controller updates its estimate Q(s,a) based on a sample (a, r): Q(s,a) ⁇ - Q(s,a) + (r-Q(a)) . (eq. 4)
- the sample (a, r) is the experience obtained by the base station: action a was performed resulting in payoff/reward r.
- ⁇ is the learning rate (0 ⁇ 1), governing to what extent the new sample replaces the current estimate. Assuming infinite number of iterations, the algorithm converges to Q(a).
- FIG. 10 A learning example is illustrated in figure 10: With reference to figure 10, the task is to find a policy 7i(s): S ⁇ A that maximizes the sum of future cumulative rewards, expressed as a utility function
- Non-deterministic environment m ⁇ a ⁇ x t+k+1 ; 0 ⁇ ⁇ ⁇ 1
- the Q-algorithm is as follows for a starting state and action (s t ,a t ):
- a learning rate coefficient r] is preferably added
- Exploration-Exploitation is a probabilistic approach to select actions
- k>0 is preferably a constant that determines how strongly the selection favors actions with high Q- values. Larger k-values will assign higher probabilities to actions with above average Q, causing an optimizer to exploit what it has been learned and seek actions as instructed to maximize its reward. Smaller values will assign higher probabilities for other actions with below average Q, causing the optimizer to explore actions that do not currently have high Q values. Parameter k may vary with the number of iterations so that the optimizer favors exploration in the early stages of learning, to gradually shift towards more exploitation.
- Figure 11 illustrates another learning example, where transmit power, p, and antenna tilt, a, are configured and determined according to the traffic of a cells area. Illustrated as a non-limiting single-cell example, transmit power is assumed constant and the Q-values for different antenna tilt angles are learned, until a favorable action a 4 is found with a resulting Q-value of
- utilities are applied to guide the determination of an action by providing a maximum utility.
- a utility function evaluates a state of an environment. It maps the state to a scalar value indicating how good the state is. By comparing the scalar to other one or more values, e.g. of other states, it is possible to compare how good different states are.
- Reward functions in reinforcement learning optimization should be expressed as utility functions on a multiplicity of KPIs.
- a negotiation strategy is preferably applied.
- a typical negotiation strategy comprises a sequence of actions taken in a negotiation process e.g. consisting of offers, counter-offers, accept or quit.
- Learning in negotiation in principle provides learning the negotiation strategy of other negotiating entities, their types, utilities and models.
- bayesian belief networks can be used as efficient updating mechanisms.
- recipient Given the domain knowledge in the form of conditional statements, recipient preferably uses a standard Bayesian updating rule to revise the desirable outcome of the offerer.
- Example classes of learning that can be applied in a multi-cell (multi -objective system are:
- a learning network provides great many benefits as compared to set preconfigured networks. It is not always known from the first deployment how traffic in an area will behave or develop, what will be the load, what it typical user mobility, or how the area should be classified according to kind. In brief the best configuration may not be known at the time of commission or deployment, while a learning network is capable of adapting thereto. According to preferred embodiments, the learning facilities provide dynamically discovering of optimal solutions at run -time. The learning process allows for base stations to reconfigure themselves if they are moved to a new area or if the traffic behavior changes, such as when establishing a new residential area. The learning process for a communications network should be arranged as a long-term process for convergence to a preferred solution over time.
- the cognitive engine and learning is preferably applied to a cellular network for various optimization objectives.
- the utility function f[Ki...,K n ] corresponds to a policy set by the operator and facilitates comparison between different sets of KPI providing different states. There is a mapping from the decision parameters (configuration parameters to KPI values. By learning, the system can understand this mapping and how to change configuration parameters to quickly get to the optimum system state.
- Figures 12-14 schematically illustrate deployment of cognitive SON functionality in wireless networks of various physical architectures.
- ⁇ ( ⁇ , ao, ⁇ , ai,. . . , 3 ⁇ 4 t ) (2.1) is called the policy of the node and maps the complete history of observation-action pairs up to time t— to an optimal action a t .
- the policy ignores all its observed history except for the last observation 0 t resulting in the form
- ⁇ ( ⁇ ,) a, (2.2) which is a mapping from the current observation of the entity to an action a t .
- the collective information that is contained in the world at any time step t, and that is relative to performance measure, is called a state of the world and is denoted by s t .
- the observation ⁇ of the entity provides only partial information about the actual state s,.
- the stochastic coupling between s, and ⁇ may alternatively be defined by an observation model in the form ⁇ ( ⁇ ,
- the Markov property is assumed for the world model where the current state of the world at time t summarizes all relevant information for the state at time t+1. More specifically, an entity can perceive a set S of distinct states and has a set A of actions it can perform. At each time step t the entity senses the current state s t , chooses an action a t and performs it with a
- function ⁇ corresponds to a transition model that specifies the mapping between a state-action pair (s t> a,) to a new state s, + i with probability one if the environment is deterministic and probability environment p(s, + i
- + i is a stochastic variable that can take all possible values in S, each with corresponding probability p(s, + i
- Each entity selects among the actions that achieve the objectives of the tasks/operations it has been aimed for.
- a way to formalize the notion of objective is to define them as goal states of the world that would correspond to the optimal states that the environment would be if the tasks were optimally performed.
- an autonomous entity searches through the state space for an optimal sequence of actions to a goal state.
- Clearly, not all states are of equal preference and not all goal states are equally optimal.
- a formulization of the notion of preference and optimality is by assigning to each state s a real number U(s) that is called the utility of state s for that particular task and entity; the larger the utility of the state U(s), the better the state s.
- U evaluating each state of the world can be used by an entity for its decision making. Assuming a stochastic environment utility-based decision making is based on the premise that the optimal action a,* of the entity at state s, should maximize expected utility, that is,
- a reward function r Sx A ⁇ R, i.e., the entity receives reward r(s, a) when it takes action a at state s, then the entity is to maximize a function of accumulated reward over its planning operation time.
- a standard such function is the discounted future reward r(s,,a,) + yr(s, + i,a, + i) + y 2 r(s, +2 , a, +2 )+" ⁇ where ⁇ e [0, 1) is a discount rate ensuring that the sum remains finite for infinite operation time.
- ⁇ e [0, 1) is a discount rate ensuring that the sum remains finite for infinite operation time.
- different policies will produce different discounted future rewards, since each policy will take the entity through different sequences of states.
- the optimal value of a state s following some policy is defined as the maximum discounted future reward the entity would receive by starting at state s by:
- a policy 7i*(s) that achieves the maximum in (2.8) or (2.9) is an optimal policy: n * (s) e arg max Q (2. 10) a Note that there can be many optimal policies in a given task, but they all share a unique U* and Q*.
- Q-learning is a method for estimating the optimal Q* (and from that an optimal policy) that does not require knowledge of the transition model.
- the entity repeatedly interacts with the environment and tries to estimate Q* by trial-and-error.
- the entity initializes a function Q(s,a) for each state-action pair, and then it begins exploring the environment.
- the entity can choose exploration action a in state s according to a Boltzmann distribution where ⁇ controls the smoothness of the distribution (and thus the randomness of the choice), and is decreasing with time.
- each entity i receives an observation ⁇ ⁇ e ⁇ that provides information about s.
- the profile of the individual observations of all entities ($ defines the joint observation ⁇ .
- each observation is a deterministic function of the state: the observation of each entity at each state is fully determined by the setup of the problem.
- a more general observation models can be defined in which the coupling between states and observations is stochastic.
- an observation model could define ajoint probability distribution p(s,$) over states and joint observations, from which various other quantities can be computed, like ⁇ ( ⁇ ) or p(6
- the profile of individual policies ( ⁇ ;) defines the joint policy ⁇ .
- Multi-entity decision making also requires defining an explicit payoff function Qi for each entity.
- This function can take several forms; for instance, it can be a function Qi (s, a) over states and joint actions; or a function Qi(9, a) over joint observations and joint actions; or a function Qi(9i, a) over individual observations and joint actions. Note that often one form can be derived from the other; for instance, when an inverse observation model p(s
- $) is available, we can write Qi($, a) ⁇ seS p(s
- ajoint policy 7i* ( 7ii* ) i s a Nash equilibrium if no entity has an incentive to unilaterally change its policy; that is, no entity i would like to take at state s an action ai ⁇ (s) assuming that all other entities stick with their equilibrium policies ⁇ - * (s).
- the policy can be negotiated among' the entities as necessary. Negotiations are performed by means of interaction rounds with offers and counter-offers ending with accept or quit.
- the offers and counter offers refers to suggestions for joint actions who's Q(s,a) of the joint action a is within the thresholds of offer acceptability of the involved entities.
- - Ai is the set of available actions of entity i.
- - ⁇ is the set of private information $i e ⁇ that define the types of entity and which is not revealed to the other entities
- Including payment functions ⁇ is essential because we need to motivate the entity to participate in the mechanism; participation for an entity is not a priori the case.
- a mechanism in which no entity is worse off by participating, that is, Qi(Si, a) > 0 for all i, ⁇ , and a , is called individually rational.
- Figure 12 illustrates a cognitive SON centralized architecture.
- a central node with cognitive engine configure node functions. This includes function referring to control and information functions, e.g. RRM functions. The functions are preferably dedicated and abstracted.
- Figure 13 illustrates a cognitive SON distributed architecture with example
- Figure 14 illustrates a cognitive SON hybrid network architecture with a plurality of options such as central coordination, distributed coordination, hierarchical structures, or a structure with central and distributed coordination at each level of the hierarchy.
- a communication node or simply node
- a communication node is generally assumed to observe its environment, deliberate, decide what actions to take, actuate its decisions and finally adapt to its environment. It's desirable that in due course the node learns the most optimal decision given a set of environment conditions and possibly some feedback.
- An autonomous node is any device where decisions can be made.
- communications nodes will be exemplifies by radio/wireless nodes which in cellular (mobile) networks refer to infrastructure nodes such eNBs (enhanced Node B) and BSs (Base Stations) and mobile nodes such as UE (User Equipment) and mobile terminals.
- eNBs enhanced Node B
- BSs Base Stations
- UE User Equipment
- Figure 15 shows SON functionality of cognitive SON as follows: ⁇ Observation: monitors the environment for observations ⁇ in order to derive the current state s (in its simplest form it monitors parameters and may/may not derive statistics from observed parameters).
- Figure 16 illustrates schematically the interactions between two independent processes running in two separate autonomous nodes.
- Cognition is a multi-disciplinary concept targeting systems with a wide range of capabilities such as resource sensing, interpretation, inference, prediction, decision making, learning, and cooperation.
- self-management encompasses self-capabilities, such as, self-awareness, self-configuration, self-optimization and self-healing.
- the need for cognitive adaptation spans various time-scales due to the different time-scales of the changes in the radio or networking environment. For example, short scale changes radio environment are caused by fading and shadowing, and adaptation requires fast reaction. Medium time-scale changes are caused by the changing set of communicating devices or traffic flows, finally, long term changes happen due to changing traffic load or due to network failures.
- the basis for cognitive, autonomous and self-managing networks is a high level of local node awareness about the local physical and network environment, as well as some notion of the corresponding global network status.
- cognitive nodes In order to make such a level of cognition possible, cognitive nodes must efficiently represent and store environmental and operational information, since a distinctive characteristic of cognitive radios and cognitive networks is the capability of making decisions and adaptations based on past experience, on current operational conditions, and also possibly on future behaviour predictions. It is therefore imperative to obtain a functional understanding of the underlying environments, such that operational models of each system layer can be constructed and subsequently combined to an integrated model where the relation between the parameters of the physical and network environment and its correlations are exposed.
- the models of the environment in each node provide only partial knowledge. Nodes may therefore cooperate in order to jointly acquire a more global knowledge of the environment, enabling distributed optimization.
- the cognitive capabilities of a network node are enabled by a Cognitive Engine (CE), as depicted in architecture later on.
- a cognitive node can maintain a model of the local environment that in turn allows for educated communications decision based on the impact of its actions.
- a cognitive node can further make rational decisions in order to maximize its performance metrics, e.g., a cognitive node selects a power setting value that will lead to optimal utilization of network resources.
- a cognitive node can act autonomously since the CE provides the ability to learn and adapt to a changing environment.
- a cognitive engine should be able to: Accurately model the dynamics and the state of its environment by means of : o Performance metrics and environment dynamics (physical environment - radio resources) o Model-deduced knowledge/information exchange between the cognitive nodes (network environment - neighboring nodes). Make rational decisions in terms of action selections. o The goal for a rational node is to maximize the expected utility of its actions given the state of its physical and network environment. o Learn from past actions, events, impact and (delayed) feedback.
- An architecture suited to dynamic future mobile network environments is herewith suggested to cope with emerging concept of cognitive autonomous, cooperative, self-Xed and self-organisednetworks.
- a system may be in different states at any one time.
- a system's state may change many times throughout its life-time.
- Such processes cause system state transitions.
- some system states are desirable while others are not.
- some system states are a system's target while others are not.
- Performing control over the processes aims at steering system transitions to targeted system states e.g., states where the system performs optimally.
- Describing a system is done by means of a model.
- a model of any system consists of all the entities in the system, their states and procedures not excluding any information derived to understand and evalutate the system.
- a system state is typically represented/described/characterised(?) based on a multiplicity of quantifying parameters of the system model.
- This set of parameters, S provide all the parameters necessary to differentiate between any two system states.
- System state S, S (KPIi,...,KPI N ) where KPI in a radio network may incl. cell load, number of users, radio resource utilisation, throughput, spectral efficiency, QoS, etc.
- the system may respond by means of actions it is equipped with.
- the goal is to act so as the system remains in or moves towards a target state.
- Acting refers to the execution of one or multiple instructions on the operation of the system.
- an action corresponds to the configuration of network nodes that controls its operation.
- a system operating entity is equiped by a set of actions A which are performed as needed to drive the system towards a goal/target state e.g., radio resource allocation for optimal throughput performance where the actual allocation corresponds to the action and optimal trhoughput performance to the target state. More specifically, we define
- Action A, A (ai,...,a M ) where a is an action which in a radio network corresponds to the setting of one or more configuration parameters incl. transmitted power, antenna tilt, antenna mode, beam-forming, mobility offset, admission threshold, etc
- Figure 17 illustrates a system according to the invention.
- control refers to the process of identifying an action to any state of the system that is a target state. More specifically,
- Control, 7i(s):S ⁇ A maps a state se S into action ae A and
- Policy - the control process function 7i(s) defined over all states in S.
- the objective of control optimisation is to find the most optimal (or an optimal) policy.
- Objectives are expressed by means of utility functions ( objective functions) that describes how close to the targeted optimum a system state is.
- a utility function is a function that maps from system states to real numbers.
- cooperation enablers refer to those mechanisms, procedures and/or protocols which make the collaboration between network nodes and system entities possible. Collaboration spans between information exchange, actions coordination and decision making; moreover, such aspects are expected to be exploited in different dimensions thus featuring different communication layers and capabilities.
- any cooperative and/or autonomous solution can be mapped to this space which can present numerous kinds of solution arrangements for cooperation.
- two nodes may cooperate by simply exchanging information with each other and deciding independently.
- two nodes may cooperate by deciding on a coordinated plan of configurations divided between them.
- cooperation may be performed by each layer separately or in a cross-layer fashion.
- Figure 19 illustrates dimensions of cooperative decision and control according to the invention.
- Information/Context exchanging axis or collaboration axis: sensing data, configuration settings, fused/processed information, knowledge presentation, etc.
- Decision coordination and control axis or coordination axis: routing/relaying control, negotiation protocol, coordination planning, synchronisation, distributed decision making, knowledge reasoning, conflict resolution, etc.
- Layer mechanisms axis Routing/ relaying at L3 layer, MAC protocols and/or relaying at L2 layer, cooperative multi-point transmission at LI (PHY) layer, network coding and cross-layer etc.
- a network objective can be defined as the sum of all nodes' objectives (as in social welfare).
- a node may defer from taking actions that maximise its individual objectives for the benefit of the maximisation of the network objectives. For instance, a cell may select a lower power setting that maximises the overall network throughput (e.g., cause less interference) to the expense of its cell throughput performance.
- a node may select a higher power setting to increase its own cell throughput causing more interference to all neighbouring cells and thus reducing the overall network throughput.
- the second direction focuses on the trade-offs and the benefits offered by a fully cooperative (coordinated decisions) and a simpler autonomic (independent decisions) approach. For example extensive information exchange would increase signalling while the absence of any information would lead to non-optimal decisions.
- the set of parameters is many and the system state description becomes complex.
- the parameteres are noisy e.g., due raffic and radio channel are stochastic snd/or
- the list of actions is incomplete to achieve the targeted objective.
- the utility function guiding the action selection diverges from target system state or converges unacceptably slowly. - ...
- Signalling/coordination/information exchange cost e.g., overhead and energy.
- a node In the observations of a node are embedded the (physical, really or artificial) environment it perceives and acts in and the world consisting of all nodes perceiving and acting in this environment.
- the observation 0 t of the entity provides only partial information about the actual state s t .
- the stochastic coupling between s t and 0 t may alternatively be defined by an observation model in the form p(0 t
- 6 t ) p(6 t
- the Markov property is assumed for the world model where the current state of the world at time t summarizes all relevant information for the state at time t+1. More specifically, an entity can perceive a set S of distinct states and has a set A of actions it can perform. At each time step t the entity senses the current state s t , chooses an action a, and performs it with a change of the environment and world state as a result. With other words upon action execution the environment responds by producing the succeeding state ⁇ ,).
- ⁇ corresponds to a transition model that specifies the mapping between a state-action pair (s t , ⁇ ,) to a new state s t +i with probability one if the environment is deterministic and probability environment p(s t +i
- Each entity selects among the actions that achieve the objectives of the tasks/operations it has been aimed for.
- a way to formalize the notion of objective is to define them as goal states of the world that would correspond to the optimal states that the environment would be if the tasks were optimally performed.
- an autonomous entity searches through the state space for an optimal sequence of actions to a goal state.
- states are of equal preference and not all goal states are equally optimal.
- a formulization of the notion of preference and optimality is by assigning to each state s a real number U(s ) that is called the utility of state s for that particular task and entity; the larger the utility of the state U(s ), the better the state s.
- Such a function U evaluating each state of the world can be used by an entity for its decision making. Assuming a stochastic environment utility-based decision making is based on the premise that the optimal action a, of the entity at state s, should maximize expected utility, that is,
- a standard such function is the discounted future reward r(s t ,a t ) + Yr(s t +i,a t +i) + y 2 r(s t +2, a t +i)+- ⁇ ⁇ , where ⁇ e [0, 1) is a discount rate ensuring that the sum remains finite for infinite operation time.
- ⁇ e [0, 1) is a discount rate ensuring that the sum remains finite for infinite operation time.
- the optimal Q-value of a state s and action a of the entity is the maximum discounted future reward the entity can receive after taking action a in state s:
- a policy Ji*(s) that achieves the maximum in (2.8) or (2.9) is an optimal policy:
- Q * (s, a) R(s, a) + ⁇ p(s' ⁇ s, a)max Q * (s ⁇ ') (2.11)
- This is a set of nonlinear equations, one for each state, the solution of which defines the optimal Q*.
- the transition model is unavailable .
- Q-learning is a method for estimating the optimal Q* (and from that an optimal policy) that does not require knowledge of the transition model.
- the entity repeatedly interacts with the environment and tries to estimate Q* by trial-and-error. The entity initializes a function Q(s,a) for each state-action pair, and then it begins exploring the environment.
- ⁇ (0, 1) is a learning rate that regulates convergence. If all state-action pairs are visited infinitely often and ⁇ decreases slowly with time, Q-learning converges to the optimal Q ⁇ [Watkins 1992] .
- the entity can choose exploration action a in state s according to a Boltzmann distribution
- a more general observation models can be defined in which the coupling between states and observations is stochastic.
- an observation model could define ajoint probability distribution p(s, ⁇ ) over states and joint observations, from which various other quantities can be computed, like ⁇ ( ⁇ ) or p(0
- the profile of individual policies (jii ) defines the joint policy ⁇ .
- Multi-entity decision making also requires defining an explicit payoff function Qi for each entity.
- This function can take several forms; for instance, it can be a function Qi (s , a) over states and joint actions; or a function Qi ( ⁇ , a) over joint observations and joint actions; or a function Qi (0i , a) over individual observations and joint actions. Note that often one form can be derived from the other; for instance, when an inverse observation model p(s
- ⁇ ) is available, we can write Qi ( ⁇ , a) ⁇ se S p(s
- ajoint policy ⁇ * ( ⁇ * ⁇ ) is a Nash equilibrium if no entity has an incentive to unilaterally change its policy; that is, no entity i would like to take at state s an action a ⁇ ⁇ * ⁇ (s ) assuming that all other entities stick with their equilibrium policies ⁇ *- ⁇ (s).
- the policy can be negotiated among the entities as necessary. Negotiations are performed by means of interaction rounds with offers and counter-offers ending with accept or quit.
- the offers and counter offers refers to suggestions for joint actions who's Q(s,a) of the joint action a is within the thresholds of offer acceptability of the involved entities.
- Ai is the set of available actions of entity i.
- Qi (0i , a) is the payoff function of entity i that is defined as
- Including payment functions ⁇ is essential because we need to motivate the entity to participate in the mechanism; participation for an entity is not a priori the case.
- a mechanism in which no entity is worse off by participating, that is, Qi (0i , a) > 0 for all i, 0i, and a, is called individually rational.
- Figure 21 illustrates cognitive SON optimisation process
- a communication node (or simply node) to observe its environment, deliberate, decide what actions to take, actuate its decisions and finally adapt to its environment. It's desirable that in due course the node learns the most optimal decision given a set of environment conditions and possibly some feedback.
- An autonomous node is any device where decisions can be made.
- the term communications nodes will be exemplifies by radio/wireless nodes which in cellular (mobile) networks refer to infrastructure nodes such eNBs and BSs and mobile nodes such as UE and mobile terminals.
- a node implementing the steps depicted in Figure 21 implements cognitive SON.
- Observation monitors the enviroment for observations ⁇ in order to derive the current state s (in its simplest form it monitors parameters and may/may not derive statistics from observed parameters)
- Actuator execute actions or cooperates with other entities to collaborate i.e., exchange observations or to coordinate i.e. synchronize actions
- Fig.22 visualises the interactions between two independent processes running in two separate autonomous nodes.
- Sensing/Monitoring Functional Unit deals with the observation and state transmission modelling.
- Configuration/Decision Making Functional Unit deals with the action-state modelling for action selection and valuation.
- Optimisation Functional Unit deals with the optimisation of all models, functional units and optimal control of policies
- Interaction Functional Unit deals with interaction modelling for negotiation and communication of decisions and execution/effectuation of selected actions.
- Knowledge base consists of facts and rules describing the models required for the realisation of the cognitive SON engine.
- Knowledge base can be a Functional Unit of its own or maintained and communicated between functional units as depicted above.
- each node of the above identified functional units maintain a knowledge -base consisting of facts and rules.
- the implementation of such a knowledge base can be part of the above modules or a separate functional entity updating and providing access to information.
- Facts are represented by parameter-value pairs that build up a model of the environment and the-self i.e., the owner of the facts and the knowledge -base. Facts are used to represent information about Monitoring Parameterse.g., o the radio environment incl. load, interference etc o KPIs i.e., performance metrics Discovery Parameters o neighbouring nodes and neighbouring nodes capabilities, state etc.
- Configuration parameters o Configuration settings e.g., transmitted power settings, etc
- Rules are represented by parameter-value implications of premise-implies-conclusion (If ⁇ premise> then ⁇ conclusion>) type.
- a premise may be a rule or a (conjunction of) fact(s), typically of monitoring types.
- a conclusion can be a rule or a (conjunction of) fact(s), typically of configuration type.
- the set of facts and rules represents a model of the environment in which the knowledge possesing entity interacts in and a model of the entity itself including its capabilities, objectives, roles, functions and actions.
- Knowledge K consists of facts and rules
- Facts reflects on apriori knowledge of the environment and the entity itself. It includes among others the system state S set, the actions A set that the entity itself and functions F set
- a model of the external environment and the rules the environment obays can be described and stored in the knowledge base.
- An observation and transition model of the environment can be also described in terms of environment states and transisitions between states due to events caused by external entities or due to actions taken by the CE itself.
- the environment model is based on apriori and/or learned knowledge and presented by parameters or parameter functions.
- Figure 25 illustrates a system according to the invention.
- sensing/monitoring Two of the main roles of the sensing/monitoring is to sense and monitor observable parameters and collect short-term and long-term statistics on parameter values and performance measurements (infromation observing operation). to better describe the environment states i.e., to uniquely identify the state of the environement and define it accurately and in a concise way (information processing operation).
- the task of the information observing operation is to update the state environment description p so as it reflects the actual environment at anyone time.
- the information processing operation targets to learn the different states of the environment. This can be done in numerous ways including classifying the parameter-value pair ⁇ p, x(p)> combinations observed in the system by means e.g., decision trees. Decision trees classify instances of p by sorting them down the tree from the root to some leaf node, which provides the classification of the instance. Each node in the tree specifies a test of some parameter of p, and each branch descending from the node corresponds to one of the possible values for this parameter.
- a instance of p is clasified by starting at the root node of the tree, testing the parameter specified by this node, then moving down the tree branch corresponding to the value of the parameter. This process is repeated for the subtree rooted at the new node.
- decision trees represent a disjunction of conjunctions on the parameter values of instances. Each path from a tree root to a leaf corresponds to a conjunction of parameter tests, and the tree itself to a disjunctions of these conjunctions. The goal of a decision tree is to select the parameter that is most useful in classifying states. Parameter tests based on the measure of entropy can be used to characterise the (im)purity of an arbitrary collection of parameter p instances. Decision tree is only an example of classifying states.
- Sensing/Monitoring FU contributes directly to ⁇ Observation model • Transition model
- MCi monitoring-to-communication interface
- MDi monitoring-to-decision interface
- Figure 26 illustrates a system according to the invention. Configuration/Decision Making functions incl.
- Device dependent o RRM at Base station o Sensor Element/Gateway Decision Part (Di) o Config control parameters (set) o Configuration info (get) - Execution part (Xi) o Configuration of device 3.5 Interaction Functional Unit
- Figure 27 illustrates a system according to the invention.
- Ci/Xi Cooperation-Communication / Execution interface
- Figure 28 illustrates optimization functional unit.
- Opimisation Functional Unit deals with an analysis part and a learning part.
- the analysis/reasoning unit elaborates on the identification of relevant statistics, correlations and conditional probablities between states, observations, actions and any combination thereof.
- the learnign unit is trying to learn from experince patterns in the world model that can assist in predicitions and optimal operation.
- a cognitive SON engine CSONE is said to learn from experience E with respect to some class of tasks T and performance measure/metrics P, if its performance at tasks in T, as measured by P, improves with experience E.
- a radio node that learns configuration of mobility optimisation might improve its mobility performance as measured by its ability to optimally configure mobility parameters through experience obtained by configuring mobility with its neighbours.
- a well-defined learning problem requires a well-defined task, performance metric and training experience.
- Design a learning approach involves a number of design choices, including choosing the type of training experience, the target (or objective) function to be learned, a representation for this function and an algorithm for learning the target function from training examples.
- learning involves searching through a space of possible hypotheses H to find the hypothesis h that best fit the available training examples D and other prior constraints or knowledge.
- h In terms of SON functionality at any one time t, h, would correspond to a state s, and D to the current set observations ⁇ .
- Much of the above optimisation and control functionality is performed by learning methods that search different hypothesis spaces (e.g., numerical functions, decision trees, neural networks, policies, rules) based on different conditions under which these search methods converge toward an optimal hypotheses.
- search different hypothesis spaces e.g., numerical functions, decision trees, neural networks, policies, rules
- Operation of optimisation control is performed by learning new facts and rules or by modifying existing rules to improve performance.
- optimisation methods aims at learning a policy that maps any state of the system to an optimal set of actions according to the objectives of the optimising entity/function(s).
- the optimising entity is able to efficiently learn - all distinguishable states of the system and the differentiating parameters an accurate model of environment and the rules governing it for future predictions all transitions between different system states an optimal course of sequential and/or joint parallell actions to achieve control and operation optimisation a set of rules that guarantees efficient and stable operation and fast convergence as the system state changes.
- the goal of the state optimisation is to identify the set of parameters that for a given objective (or set of objectives) concisely differentiates between any two states of the system.
- Bayesian Learning can be applied to identify the conditioning and the correlations between parameters indicative to a system state.
- the output of the state optimisation is concise descriptions of system states where organisation patterns and operation patterns are uniquelly identified.
- An optimised solution is a solution where each state is described by a minimum number of parameter-value pairs.
- Another objective of the state optimisation is that facts and rules i.e., the model renders accurately the environment at any one time. Updating the facts to reflect the state of the environment optimally requires
- the goal of the state optimisation is to identify the set of parameters that for a given objective (or set of objectives) concisely differentiates between any two states of the system.
- Radio Learning refers to the ability of radio nodes to learn from their environment and their interactions with other radio nodes.
- Learning aims at identifying an optimal set of actions for which the radio node and the overall network perform best.
- An action typically corresponds to value settings of configuration parameters/variables.
- the performance of the system is evaluated by means of an objective function which corresponds to the total reward or payoff or utility.
- the learning is performed by means of sophisticated trial and error searching among all possible parameter value combinations.
- Q- Learning Q- Learning
- RL can be used by a controller to estimate based on past experience, the expected payoff/reward associated with their actions.
- One particular implementation of RL is
- Q-value, Q(s,a) is a value function that provides a numerical estimate of the value of performing an individual action a at a given state s of the environment.
- the controller updates its estimate Q(s,a), based on sample (a, r) as follows:
- the sample (a, r) is the experience obtained by the base station: action a was performed resulting in payoff/reward r.
- ⁇ is the learning rate (0 ⁇ ⁇ ⁇ 1), governing to what extent the new sample replaces the current estimate. Assuming infinite number of iterations the algorithm converges to an Q(a).
- k may vary with the number of iterations so that the optimiser favors exploration in the early stages of learning, to gradually shift towards more exploitation.
- transmit power (p) and antenna tilt (a) will be configured and optimised according to the traffic of a cells area.
- transmit power is assumed constant and the Q-values for different antenna tilt angles are learned
- Figure 30 illustrates an example of learning according to the invention.
- Utilities are used to guide for the selection of the optimal action as described by the utility optimisation next.
- a utility function evaluates the state of the environment. It maps a state to a scalar value indicating how good the state is. By comparing the scalar, we can compare how good different states are.
- An non-aggregating function that is non-pareto based o E.g., user-defined ordering where the objectives are ranked according to the order of importance of the desinger
- negotiation strategy is a sequence of actions taken in a negotiation process consisting of offers, counter-offers, accept or quit.
- bayesian belief networks can be used as efficient updating mechanisms. Given the domain knowledge in the form of conditional statements and the signal e in the form of offers then offer recipient can use the standard bayesian updating rule to revise the desirable outcome of the offerer.
- N cells implementing control with full information sharing and simultaneous actions.
- KPI Key Performance Indicators
- the utility function enables the comparison of different sets of KPI (different states)
- All CSONE-equipped nodes are communicating via its interaction units. Interactions with non-CSONE nodes are performed in their entirety by means of the execution unit. Interactions between CSONE nodes can be perfromed either by means of communication/cooperation unit.
- ⁇ Functions refer only to control and information e.g., RRM functions, etc
- CSONE centralised architecture facilitates centralized control performed by a central entity, e.g., O&M etc., that may operate in the following way, it:
- the model maintained by a central entity as envisaged above induces full knowledge of the world and the nodes the central entity monitors, controls, interacts and optimises.
- FIG. 32 A deployment of the above architecture consisting only of CSONE entities is illustrated the figure 32.
- CSONE distributed architecture facilitates distributed control performed by CSONE nodes each one:
- the model maintained by each entity implies partial knowledge of the world pertinent to the local environment of the entity i.e., the entity itself and the neighbours within reach.
- Working towards full knowledge requires information exchange by means of observations, state descriptions and statistics, action selection and evaluation and interactions.
- Figure Hybrid 1 (Fig. 35): CSONE hybrid Architecture of central coordination
- Figure Hybrid 2 (Fig. 36): CSONE hybrid Architecture of distributed coordination Cognitive SON hybrid Architecture (as illustrated in the figures above) Many possible options ⁇ central coordination Fig. Hybrid 1
- Hierarchical structures or central and distributed coordination at each level of the hierarchy facilitates hierarchical structure of control that combines centralized control or distributed control at any level of hierarchy and any order.
- central control at the root of the hierarchy the architecture is said to perform central coordination control as in fig.
- Hybrid 1 In case of distributed control is said to perform distributed coordination control as in fig.
- Models at higher level of hierarchy are closer to the management operation and models maintained by lower levels of abstraction are closer to the functional operation of networks or node functions.
- a deployment of the above architecture consisting only of CSONE entities is illustrated in figure 37.
Abstract
A method of controlling a telecommunications network, the network comprising at least one device arranged for interaction as regards network configuration parameters is disclosed. Examples of learning systems and network optimization during run-time are provided facilitating adaptation to a system state.
Description
METHOD AND APPARATUS OF COMMUNICATIONS
Technical field
The technical field of multi-user communications provides relevant art of technology for this specification of an invention. This may also be the case for a technical field of short-range radio communications or surface covering wireless communications; or operations, management or configuration of wireless communication networks. This may particularly be the case for a technical field of local awareness and local or distributed control of communication networks. Background
Wireless communications provide a means of communicating across a distance by means of electromagnetic signals. With user access to a communications network being wireless to an ever increasing extent; some of the challenges of surface covering wireless communications; such as resource sensing and allocation, interference prediction, and decision making therefore has be approached in the art 15 in order to provide for increased automation of network maintenance and administration.
3GPP TR 36.902 V9.2.0, Technical report; 3rd Generation Partnership Project; 3rd Generation Partnership Project; Technical Specification Group Radio Access Network; Evolved Universal Terrestrial Radio Access Network (E-UTRAN), Self-configuring and self- optimizing network (SON) use cases and solutions(Release 9), France, June 2010, discusses e.g. automated configuration of Physical Cell Identity, Mobility Robustness and setting of HO (handover) parameters, Mobility Load Balancing, RACH (Random Access Channel) configuration, maintaining and building neighbor relationships, and inter-cell interference coordination. Particularly, it has been concluded that reduction of operational efforts and complexity improves system operability in a multi-vendor environment.
Andreas Lobinger et at, 'Load Balancing in Downlink LTE Self-Optimizing Networks/ VTC 2010-Spring Taipei 19 May, mentions self-optimizing, self-healing and self-organizing
networks as part of a project receiving EU-funding. The authors discuss in some detail load balancing and setting of HO parameters.
United States Patent No. US6829491, provides a communication network subject to dynamic optimization using network operation metrics, such as may be acquired from a network controller such as a mobile switching center. Implementation of the parameter adjustments are modeled to determine if further or different operational parameter adjustments should be determined. The document mentions that a network may be load-unbalanced due to unusually dense subscriber populations (e.g. sports arenas during sports events). It concludes that it would be advantageous to have a method and system for dynamically monitoring of network communication metrics, inclusive of metrics associated with communications as provided through a plurality of network resources. Accordingly, operation parameters may thereby be redistributed dynamically as a result of modeling and estimation of network system parameters as a function of network performance information. Summary
A method of controlling a telecommunications network, the network comprising at least one device arranged for interaction as regards network configuration 20 parameters is disclosed. Examples of learning systems and network optimization during run-time are provided facilitating adaptation to a system state.
Brief description of the drawings
Figure 1 illustrates a typical Cognitive Engine, CE, in accordance with the invention.
Figure 2 shows a system architecture illustrating functionality in two example independent CSONE entities. Figure 3 schematically illustrates a system as preferably described in terms of a
model.
Figure 4 schematically illustrates determining a best action,
Figure 5 illustrates some example key enabling technologies and solutions in three different dimensions of cooperative operation.
Figure 6 illustrates schematically sensing monitoring interfaces.
Figure 7 illustrates communication interfaces of a configuration/decision making and/or execution module
Figure 8 illustrates schematically and in accordance with the invention two example Communication/Cooperation/Execution Modules.
Figure 9 illustrates schematically the interfaces of an optimization module (91) and various entities.
Figure 10 illustrates a learning example.
Figure 11 illustrates another learning example. Figure 12 illustrates a cognitive SON centralized architecture.
Figure 13 illustrates a cognitive SON distributed architecture with example autonomous cognitive engine.
Figure 14 illustrates a cognitive SON hybrid network architecture. Figure 15 shows SON functionality of cognitive SON.
Figure 16 illustrates schematically the interactions between two independent processes running in two separate autonomous nodes.
Figure 17 illustrates a system relating to the invention.
Figure 18 illustrates three levels of the operation relating to the invention.
Figure 19 illustrates dimensions of cooperative decision and control relating to the invention. Figure 20 illustrates a system relating to the invention.
Figure 21 illustrates cognitive SON optimisation process.
Fig.22 illustrates the interactions between two independent processes running in two separate autonomous nodes.
Figure 23 illustrates the procedure of optimization according to the invention.
Figure 24 illustrates functionality in two independent CSONE entities according to the invention.
Figure 25 illustrates a system according to the invention.
Figure 26 illustrates a system according to the invention.
Figure 27 illustrates a system according to the invention.
Figure 28 illustrates optimization functional unit according to the invention. Figure 29 illustrates procedure of learning task.
Figure 30 illustrates an example of learning according to the invention. Figure 31 illustrates a cognitive SON centralised architecture.
Figure 32 illustrates a deployment of the architecture consisting only of CSONE entities. Figure 33 illustrates a cognitive SON distributed architecture.
Figure 34 illustrates a deployment of the above architecture consisting only of CSONE entities.
Figure 35 illustrates a CSONE hybrid Architecture of central coordination.
Figure 36 illustrates a CSONE hybrid Architecture of distributed coordination.
Figure 37 illustrates a deployment of the architecture consisting only of CSONE entities.
Detailed description
The role of wireless networks in a future Internet will, in a most dynamic form, enable multi-hop network topologies consisting of heterogeneous wireless networks and technologies ranging from short-range radio to cellular systems. User devices of different capabilities, traffic demands conforming to different QoS (Quality of Service) profiles and multiple control and management authorities may interfere and contend for a common set of radio resources.
This evolution towards more complex systems renders imperative the need for adaptable and/or scalable systems that operate well in complex, adverse or unpredictable environments, not excluding operation and interactions over wireless or wired backhauling connections. A basis for cognitive, autonomous and self-managing networks is a high level of local node awareness about the local physical and network environment, as well as some notion of the corresponding global network status. In order to make such a level of cognition possible, cognitive nodes efficiently represent and store environmental and operational information, since a distinctive characteristic of cognitive radios and cognitive networks is the capability of making decisions and adaptations based on past experience, on current operational conditions, and also possibly on future behavior predictions. A model of an underlying environment in each node provides only partial knowledge. Nodes may therefore cooperate in order to jointly acquire a global or wide-range knowledge of the environment, enabling distributed operations.
Figure 1 illustrates a typical Cognitive Engine, CE, in accordance with the invention as will be further described in detail below. Through the cognitive engine, a cognitive node can maintain a model of the local environment that in turn allows for educated communications decision based on the impact of its actions. A cognitive node determines or selects decision variables in order to maximize a performance metric, e.g., determining or selecting a power setting value that will lead to (close to) maximum utilization of network resources. A cognitive node acts autonomously, as the CE provides the ability to learn and adapt to a changing environment. To empower such cognitive nodes, a cognitive engine preferably is adapted to: accurately model dynamics and one or more states of its environment by means of: performance metrics and environment dynamics (physical environment - radio resources)
model-deduced knowledge/information exchange between the cognitive nodes (network environment - neighboring nodes); and
make action selections
maximizing expected utility of its actions given the state of its physical and network environment, and
learning from past actions, events, impact and (delayed) feedback.
A system may change state at any point in time. As a result of internal processes (within the system) or external processes (within the outside environment) a system's state typically may change many times during its life-time. In general, some system states are useful for mapping into an action decision variable while others are not. Also, some system states are targeted while others are not. Performing control over the processes aims at steering system transitions to targeted system states e.g., states where the system performs favorably.
Figure 2 shows a system architecture illustrating functionality in two example independent CSONE entities. Operation in the cognitive SON engine CSONE is supported and realized by means of knowledge stored in a knowledge base. More specifically, each node of the various units or modules as described above preferably maintain a knowledge base (111) comprising facts and rules. The knowledge base may be distributed or centralized. Facts are represented by parameter value pairs that build up a model of the environment and itself, i.e. the owner of the facts and the knowledge base. Facts are used to represent information about e.g.
Monitoring parameters, such as
radio environment, inclusive of load and interference level,
KPIs and their performance metrics,
• Discovery parameters, such as
- neighboring nodes and neighboring nodes capabilities; and
• Configuration parameters providing e.g.
configuration settings such as transmitted power settings.
Rules are preferably represented by parameter-value implications of premise- implies-conclusion type (if <premise> then <conclusion). A premise is e.g. a rule or a (conjunction of) fact(s), typically of monitoring types. A conclusion correspondingly is, e.g., a rule or a (conjunction of) fact(s), typically of configuration type. According to preferred embodiments, rules apply for all values of parameters of a subset of values as defined by numerical operators. Rules may imply rules or facts.
In terms of contents, the set of facts and rules represents a model of the environment in which the knowledge possessing entity interacts. In addition, the set represents a model of the entity itself including its capabilities, objectives, roles, functions and actions.
In terms of contents the set of facts and rules represents a model of the environment in which the knowledge possessing entity interacts in and a model of the entity itself including its capabilities, objectives, roles, functions and actions.
Formally, knowledge K consists of facts and rules.
• Facts reflects on apriori knowledge of the environment and the entity itself. It includes among others the system state S set, the actions A set that the entity itself and functions F set.
• Rules= control i.e., IF ss S THEN ae A.
• Utilities = functions for the evaluation of system states U.
Facts and Rules are stored in a Knowledge Base, preferably accessible by all functional units partially or in its entirety.
The state of the environment ss S is described as a state function /seF over the set of observed parameters, /s(p): P →S, where p = (θ(ρ , θ(ρ2), θ(ρρ |)) where piis a parameter of parameter function and |P | denoting the cardinality of the set of parameters.
By means of facts, rules and utilities as described, a model of the external environment and the rules the environment obeys can be described and stored in the knowledge base. An observation and transition model of the environment can be also described in terms of environment states and transitions between states due to events caused by external entities or due to actions taken by the CE itself. The environment model is based on a-priori and/or learned knowledge and presented by parameters or parameter functions.
An cognitive SON engine CSONE is said to learn from experience E with respect to some class of tasks T and performance measure/metrics P, if its performance at tasks in T, as measured by P, improves with experience E.
For example a radio node that learns configuration of mobility optimization might improve its mobility performance as measured by its ability to optimally configure mobility parameters through experience obtained by configuring mobility with its neighbors.
A well-defined learning problem requires a well-defined task, performance metric and training experience. Design a learning approach involves a number of design choices, including choosing the type of training experience, the target (or objective) function to be learned, a representation for this function and an algorithm for learning the target function from training examples.
In general, learning involves searching through a space of possible hypotheses H to find the hypothesis h that best fit the available training examples D and other prior constraints or knowledge. In terms of SON functionality at any one time t, h, would correspond to a state s, and D to the current set observations Θ.
Much of the above optimisation and control functionality is performed by learning methods that search different hypothesis spaces (e.g., numerical functions, decision trees, neural networks, policies, rules) based on different conditions under which these search methods converge toward an optimal hypothesis.
Operation of optimization control is performed by learning new facts and rules or by modifying existing rules to improve performance.
Figure 3 schematically illustrates a system as preferably described in terms of a model. Such a model should ideally represent all entities of the system, their states and procedures not hiding any information from being derived in order to correctly represent the system.
A system state may typically be specified based on a multiplicity of quantifying parameters of the system model. A preferred set of parameters, S, provides all the parameters necessary to differentiate between any two system states. Parameters can be monitored, calculated, estimated and/or derived from statistical observations. In technical systems, such as (cellular) radio networks, system parameters include
performance/evaluation metrics, key performance indicators, configuration settings etc. More specifically, a system state, S, can be defined as
S = (KPI1,...,KPIN), (eq. 1) where the various N KPIs (Key Performance Indicators), KPIi5 i = I , .. . , N, where N is a positive integer, in a radio network may non-exclusively include, e.g., cell load,
number of users, radio resource utilization, throughput, spectral efficiency and QoS, where N is a positive integer.
A system responds as determined appropriate to a particular system state by means of actions as equipped. An action refers to execution of one or multiple instructions during operations of a system. In a wireless communications network, e.g., an action corresponds to configuration of network nodes that controls operations of the network. The actions are arranged to maintain the system in a target state or bring it towards a target state. To this end, a system operating entity is equipped by a set of actions A which are performed as needed to drive the system towards the goal/target state. As a non-exclusive example, such a goal/target state is, e.g., radio resource allocation for desired throughput performance where the actual allocation corresponds to the action.
More specifically, an action, A, A= (ai,...,aM), where ai, i = 1,..., M, where M is a positive integer, is an action which in a radio network corresponds to the setting of one or more configuration parameters non-exclusively including, e.g., transmitted power, antenna tilt, antenna mode, beam-forming, mobility offset and admission threshold.
The concept of (action) control refers to the process of identifying an action for any state of the system that is a target state. More specifically, control 7tA(s),
7iA(s): S→A,, (eq. 2) maps a state ss S into action as A . The concept of (action) policy, nA(S), refers to the control process function 7iA(s) defined over all states in S nA(S)={ 7tA(s) V sG S } (eq. 3)
An example process of determining a control in accordance with an embodiment of the invention is as follows: For each state of the system, find the best action, A,,, among a given of authorized actions, A,,.
In accordance with an embodiment of the invention, determining the best action, A,,, is schematically illustrated in figure 4. The determining involves configuring a controller (42) as depicted in the figure. Three levels of operation are preferably considered:
(i) optimization level (optimizer (41)),
(ii) adaptation level (controller (42)) and
(iii) execution level (system function such as any RRM function (43) of a radio network).
The optimization entity (41) determines a control process 7i(s), preferably optimized in relation to one or more objectives. In this context, optimizing a control process is understood as determining a policy, i.e. determining relevant control for a preferred set of state variables in order to maximize a utility objective, or minimize a cost/penalty objective, considering the various states.
Objectives are preferably expressed by means of utility functions (objective functions). A utility function is a function that maps from system states preferably to real numbers. As indicated in figure 4, entities of the various operation levels cooperate. Implementing cooperation requires deployment of communication enabling functionality. In this framework, cooperation enablers refer to those mechanisms, procedures and/or protocols which make the collaboration between network nodes and system entities possible. Collaboration spans between information exchange, action coordination and decision making; moreover, such aspects are expected to be exploited in different dimensions thus featuring different communication layers and capabilities. Three of the key aspects corresponding to dimensions for decision and control that are based on cooperation or potentially can benefit from it, are:
• collaboration by means of information exchange, ranging from node independent sensing (i.e., no information exchange between nodes) to full context/knowledge presentation and sharing,
• coordination of decision and configuration control ranging from independent decisions up to fully coordinated decisions about reconfigurations, and
• utilization of layer mechanisms ranging from PHY/MAC layer mechanisms to L3 and above for cooperative transmissions.
In figure 5, the above three different dimensions of cooperative operation are illustrated along with some key enabling technologies and solutions that can be deployed for addressing energy-efficiency. These technology solutions are depicted as planes in a three-dimensional space. The planes illustrated here are only examples that demonstrate the scope of cooperation. It is also possible that the scope of some technology solutions can be a line, a vector or a point in this space. As an example it can be seen that the information exchange (collaboration) axis ranges between no information and full information. In case of no information exchange, it is assumed that nodes rely on their sensing/monitoring of the environment. Although this implies local (partial) knowledge of the environment, it is still possible to have nodes cooperating as for instance in pure conflict resolution protocols where nodes sense collisions and react by means of back-off (giving the opportunity to other nodes to transmit). Certainly, this is a very simple case of cooperation of nodes making independent decisions. Similarly in a cognitive radio scenario secondary users may base their (independent) decisions for acquiring white spaces on their own sensing data.
In principle, any cooperative and/or autonomous solution can be mapped to this
(three-dimensional) space which can present numerous kinds of solution arrangements for cooperation. In other words, two or more nodes may cooperate by simply exchanging information with each other and deciding independently.
Alternatively two or more nodes may cooperate by deciding on a coordinated plan of configurations shared between the nodes. Finally, cooperation may be performed by each layer separately or in a cross-layer fashion.
With each one of the above dimensions, a set of enablers for cooperative decision and control is preferably associated. In particular, the following associations are envisaged: in information/context exchange dimension (or collaboration dimension): - sensing data,
configuration settings,
fused/processed information,
knowledge presentation;
• in decision coordination and control dimension (or coordination dimension):
routing/relaying control,
negotiation protocol,
coordination planning,
synchronization,
- distributed decision making,
knowledge reasoning,
conflict resolution; and
• in layer mechanisms dimension (or communication layer dimension):
routing/ relaying at L3 layer,
MAC protocols and/or relaying at L2 layer,
cooperative multi-point transmission at LI (PHY) layer,
network coding and cross-layer.
There are two general aspects of cooperativeness. The first aspect captures the balance between a node's individual objectives and the objectives of the network it belongs to. In its simplest form a network objective can be defined as the sum of all nodes' objectives (a "social welfare" objective). A node may defer from taking actions that maximize its individual objectives for the benefit of the maximization of network objectives. For instance, a cell may select a lower transmission power setting while this maximizes the overall network throughput (e.g. by causing less interference) at the expense of its local cell throughput performance. The opposite would be a node selecting a higher power setting to increase its local cell throughput, thereby possibly causing more interference to neighboring cells, reducing the overall network throughput. The second aspect refers to identification of optimal
configurations for network operation (e.g. with the least energy consumption) that balance the benefits offered by a fully cooperative (coordinated decisions) and a simpler autonomic (independent decisions) approach. For example this should take into account on one hand that the complete picture can be made available to various parts of a cooperative system (e.g. utilizing information sharing) but this additional fine-grained information and flexibility comes with a cost in signaling to be justified by the expected gains. Also the processing associated with the second aspect (coordinated actions-independent actions) is preferably balanced.
The invention identifies a number of events causing problems with state parameters or the associated mapping:
• The set of parameters describing the system state is not complete, i.e., the
parameters fail to differentiate system states.
• The set of parameters comprises a great number of parameters making the system state description complex.
· There is only partial knowledge about parameter values.
• The parameter values are noisy e.g., due to traffic and radio channel being
stochastic and/or measurements having limited precision
• System parameters are continuous and consequently the state space consists of infinitely many states.
· The environment is stochastic i.e., the transition between system states is not deterministic.
• The list of actions is incomplete to achieve the targeted objective.
• The utility function guiding the action selection diverges from target system state or converges unacceptably slowly.
· The invention also identifies problems associated with cooperative optimization control:
• How to balance the trade-off between node objectives and network objectives.
• How to justify signaling/coordination/information exchange cost e.g., overhead and energy.
With reference to figure 1, the system architecture is designed to adaptive ly refine the control policy as follows: · Sensing/Monitoring Unit (102) deals with the observation and state transmission modeling.
• Configuration/Decision Making Unit (103) deals with the action-state modeling for action selection and valuation.
• Optimization Functional Unit (101) deals with the optimization of models,
functional units and optimal control of policies.
• Interaction Functional Unit (104) deals with interaction modeling for negotiation and communication of decisions and execution/effectuation of selected actions.
• Knowledge base (111) consists of facts and rules describing the models required for the realization of the cognitive SON engine. Knowledge base can be a functional unit of its own or maintained and communicated between functional units as depicted above
The various units communicate over interfaces (105), (106), (107), (108), (109), (110).
According to a preferred embodiment, operation in the cognitive engine (also referred to as policy engine) is supported and realized by means of knowledge in terms of fact and rules stored in a data base, a knowledge base (111).
• With reference to figures 3 and 4, facts are the elements of a system state, S, and the associated set of actions, A.
• Correspondingly, rules are the various controls of a policy, which is a mapping of S on A.
Operation of optimization control identifies new or modifies existing rules.
Figure 6 illustrates schematically sensing monitoring interfaces. The role of a sensing/monitoring module is, e.g., collection of KPIs, KPI statistical processing, and control of KPI monitoring. The sensing module has a monitoring to communication interface (106), (61), MCi. E.g. monitoring parameters and monitoring time-interval are communicated over the MCi. The sensing module also has a monitoring to decision interface, MDi, (109), (62).
System state information is communicated over the MDi. There may also be other, optional, monitoring interfaces that are device dependent, such as an interface to RRM (Radio Resource Management) at a base station, or a device interface between a gateway and the sensing module. Notwithstanding device dependent interfaces, there may also be other, optional, measurement monitoring interfaces (63), (64) e.g. for monitoring or communication of parameter values or time intervals, such as with a RAT/RAN RRM (Radio Access
Technology/Radio Access Network Radio Resource Management) entity or a wireless network gateway.
Figure 7 illustrates communication interfaces of a configuration/decision making and/or execution module. Configuration/decision making and/or execution module functions comprise e.g., making configuration decisions based on environment state information, radio resource configuration of control, and power and spectrum allocation. An example interface (107), (71) facilitates exchange of configuration parameters or information between the configuration/decision making and/or
execution module and the communication/execution/cooperation module. Among the various one or more interfaces of the configuration/decision making and/or execution module, the monitoring to decision interface (109), (62), (72) has been explained in relation to figure 6. An example interface (between the configuration/decision making and/or execution module (73), (74) provides a device dependent interface for RRM at a base station or for a gateway. The interface may comprise two parts, a decision part for exchange of configuration control parameters (to be set) or configuration information (to be collected), and an execution part for
exchange of messages configuring a device such as an RRM or a gateway.
Figure 8 illustrates schematically and in accordance with the invention two example Communication/Cooperation/Execution Modules (81), (82), e.g., comprising functionality for providing · information exchange, such as.
monitoring information,
configuration information, e.g. power, spectrum, interference cancellation, neighbor information;
• cooperation procedures and protocols, such as
- negotiation of configuration parameter settings,
auction for radio resources as in multi-operator spectrum sharing; and
• execution, e.g. according to configuration settings.
The two modules communicate with each other over a Ci (Cooperation/Communication Interface) (83) and with other entities such as · RRM at a base station (84); or
• Sensor Element/Gateway (85) over a Ci or Xi (Execution interface). The execution part (87), (88) comprises e.g.
• configuration of self-controlled devices (on behalf of one or more
sensing/monitoring, decision making or optimizing modules),
· configuration of remote devices (on behalf of one or more sensing/monitoring, decision making, or optimizing modules).
• configuration of function (on behalf of one or more sensing/monitoring, decision making and optimizing modules).
The Communication /Execution /Cooperation modules interface an RRM entity/function and a sensor/actuator element/gateway across a Ci/Xi (87), (88)
interface (communication/cooperation / execution interface).
Figure 9 illustrates schematically the interfaces of an optimization module (91) and various entities (92), (93), (94) that the optimization module interfaces (95), (96), (97) in accordance with the invention. The optimization module (91) · classifies one or more states of the environment based on the parameters for single, or multiple objectives.
• it learns and recognizes the most significant parameters for specific functions;
• it learns and recognizes the most significant parameters for an intended specific product;
· it learns favorable configuration settings for different environment states.
• it also learns optimal cooperation strategies.
The optimization module preferably have a plurality of interfaces (95), (96), (97). There are three different interfaces illustrated. One is intended for monitoring (92), and the other for decision making (97). A third interface between the optimization module and a user of a communication/cooperation module (96) is destined for execution.
The optimization module is preferably adapted for learning a policy that maps any state of the system to an set of actions that operate favorably according to objectives of an adoption process of the optimization module, this regardless of whether
policies are maintained and executed centrally or distributed, whether distributed in numerous or functionally.
According to an embodiment of the invention, the optimization module is adapted to learn, identify and/or provide distinguishable states of the system and the differentiating parameters, an accurate model of environment and the rules governing it for future
predictions,
• transitions between different system states,
• a course of sequential and/or parallel actions to achieve control and adapted
operation, and
· a set of rules that provides efficient and stable operation and fast convergence as the system state changes.
According to a preferred embodiment, the set of state is recursively refined by learning, the actions onto which the states are mapped are correspondingly adaptively refined, as are the mapping rule and network parameter settings. When refining the set of states, a set of parameters are preferably identified for a given objective or set of objectives capable of differentiating between any two states of the system. Some example learning methods applicable for this purpose are known as such in the art:
• Decision tree learning, e.g., applied to identify the parameter-value-pair that best classifies the states.
· Bayesian learning, e.g., applied to identify the conditioning and the correlations between parameters indicative to a system state.
• Inductive learning (learning rules out of observable facts), e.g., applied for learning a state.
• Neural network learning (learning a function from known examples), e.g. applied for learning a state.
• Instance-based learning (learning state functions from similarities and differences between instances, e.g. applied for learning a state.
An example output is a concise description of system states where organization patterns and operation patterns are uniquely identified, preferably with non or just a few non-explaining states remaining to be considered for the mapping, control or policy. At best there is a solution where each state is described by a minimum
number of one or more parameter values or parameter-value pairs.
Time is also an aspect as the output need provide an accurate result over time. To capture dynamics over time state -transitions are considered.
Another aspect of the invention is action-state control. Methods applicable as such to action-state mapping, control or policy are known as such in the art. Non-exclusive examples of such methods are
• reinforcement learning and
• genetic algorithms.
Reinforcement learning, RL, differs from standard supervised learning in that correct input/output pairs is not required. RL is a form of learning that conforms to
• learning comprising ability of wireless or radio nodes to learn from their
environment and their interactions with other radio nodes,
• learning targeting a set of actions for which the radio node and the overall network perform at its best,
· actions typically corresponding to value settings or one or more configuration parameters/variable s .
• an objective function corresponding to a total reward, payoff or utility or
corresponding measure providing a target for evaluation,
• the learning being performed by means of trial and error searching among possible parameter value combinations.
Q-learning is a particular implementation of RL, where an expected payoff/reward associated with various actions is estimated. According to an example embodiment, a controller makes such an estimate. Q-learning estimates Q-values recursively. A Q-value, Q(s,a), is a value function that provides a numerical estimate of the value of performing an individual action at a given state s of the environment. The controller updates its estimate Q(s,a) based on a sample (a, r):
Q(s,a)<- Q(s,a) + (r-Q(a)) . (eq. 4)
The sample (a, r) is the experience obtained by the base station: action a was performed resulting in payoff/reward r. λ is the learning rate (0<λ<1), governing to what extent the new sample replaces the current estimate. Assuming infinite number of iterations, the algorithm converges to Q(a).
A learning example is illustrated in figure 10: With reference to figure 10, the task is to find a policy 7i(s): S→A that maximizes the sum of future cumulative rewards, expressed as a utility function
Determi

Non-deterministic environment: m π<ΞaΠx t+k+1 ; 0 < γ < 1
k=0
π *≡ arg max U" (s), (Vs)
Optimal policy: π with value function denoted as Un (s) or 7Γ * (s)≡ arg max Q{s, a) V* is)≡ arg max Q(S, a')
a a'
In more detail, the Q-algorithm is as follows for a starting state and action (st,at):

Choose an action a^ and continue with the (until current iteration) best policy,
Qt+i ist at ) = + Y m aax Qt (st+1 , ') (eq. 6)
To guarantee convergence, a learning rate coefficient r] is preferably added,
Qt+i (s,, <*t) = (l - te, (s,, <*t) + (rt+1 + J max Qt (st+1 , a'))
rt+l + Y max Qt (st+l, a')- Qt (st, at)j (eq' ?)

Exploration-Exploitation is a probabilistic approach to select actions,

where k>0 is preferably a constant that determines how strongly the selection favors actions with high Q- values. Larger k-values will assign higher probabilities to actions with above average Q, causing an optimizer to exploit what it has been learned and seek actions as instructed to maximize its reward. Smaller values will assign higher probabilities for other actions with below average Q, causing the optimizer to explore actions that do not currently have high Q values. Parameter k may vary with the number of iterations so that the optimizer favors exploration in the early stages of learning, to gradually shift towards more exploitation.
Example advantages of reinforced learning are its
• robustness to noise,
• low complexity, and
• favorable implementation/realization
Figure 11 illustrates another learning example, where transmit power, p, and antenna tilt, a, are configured and determined according to the traffic of a cells area. Illustrated as a non-limiting single-cell example, transmit power is assumed constant and the Q-values for different antenna tilt angles are learned, until a favorable action a4 is found with a resulting Q-value of
Q4(p, a4).
The most important aspect guiding the selection of action for a communications system is its impact. According to an embodiment of the invention, utilities are applied to guide the determination of an action by providing a maximum utility.
A utility function evaluates a state of an environment. It maps the state to a scalar value indicating how good the state is. By comparing the scalar to other one or more values, e.g. of other states, it is possible to compare how good different states are. In essence, the utility of a solution vector x= (xi,... xn) of n decision variables can be
expressed in terms of its effects on various KPIs objectives fi(x), ... fn(x) where f(x), i = l ...n, corresponds to a KPI, e.g. HO success rate or coverage outage.
If regularities can be found, then a preference structure can be found expressing the utility function as u(x)= u(xi, ... xn) = f[fi(x),...,fn(x)], (eq. 9) where f corresponds to the policy/prioritization among the objectives.
The utility function u(x)= u(x 1,..., xn) = f[fi(x), ... fn(x)] can be expressed in many example ways:
1. As an aggregation function
• E.g., weighted sum, u(x)= Wift(x) + ..+wnfn(x), where Wi + ...+wn= 1
2. goal programming min∑ | f k(x)-Tt | where Tk is the target set by the designer
3. An non-aggregating function that is non-pareto based
• E.g., user-defined ordering where the objectives are ranked according to the order of importance by the designer.
4. MIN -MAX which compare relative deviations from the separately obtainable minima, (used in game theory to solve conflicting situations).
5. Pareto-based function
• E .g . , pareto optimal, pareto front
Reward functions in reinforcement learning optimization should be expressed as utility functions on a multiplicity of KPIs.
For adapting a network or provide its setting, a negotiation strategy is preferably applied. A typical negotiation strategy comprises a sequence of actions taken in a negotiation process e.g. consisting of offers, counter-offers, accept or quit. Learning
in negotiation in principle provides learning the negotiation strategy of other negotiating entities, their types, utilities and models. For the update of other entities' decision making model in the interaction/negotiation model, bayesian belief networks can be used as efficient updating mechanisms. Given the domain knowledge in the form of conditional statements, recipient preferably uses a standard Bayesian updating rule to revise the desirable outcome of the offerer.
Example classes of learning that can be applied in a multi-cell (multi -objective system are:
• N cells implementing control with full information sharing and simultaneous actions.
• Independent learners where each node independently learns the Q- values of its individual actions without taking into account the actions of its neighbors in the control.
• Coupled learners where each radio node models other radio nodes' actions in its Q-values.
• Joint Action learners where radio nodes learn Q-values of joint actions rather than their individual actions. This implies that each radio node can observe or exchange the actions of other radio nodes.
• Learning negotiation efficiency.
A learning network provides great many benefits as compared to set preconfigured networks. It is not always known from the first deployment how traffic in an area will behave or develop, what will be the load, what it typical user mobility, or how the area should be classified according to kind. In brief the best configuration may not be known at the time of commission or deployment, while a learning network is capable of adapting thereto. According to preferred embodiments, the learning facilities provide dynamically discovering of optimal solutions at run -time. The learning process allows for base stations to reconfigure themselves if they are moved to a new area or if the traffic behavior changes, such as when establishing a new
residential area. The learning process for a communications network should be arranged as a long-term process for convergence to a preferred solution over time.
The cognitive engine and learning is preferably applied to a cellular network for various optimization objectives. For a SON (Self Optimizing Network), a utility function preferably evaluates the state of the current environment u(x)=f[f1(x),..
Key performance indicators, KPIs Ki5 i=l,... n, reflect important aspects of the system and are preferably applied as input to the utility function u(K)=f[K1...,Kn] .
The utility function f[Ki...,Kn] corresponds to a policy set by the operator and facilitates comparison between different sets of KPI providing different states. There is a mapping from the decision parameters (configuration parameters to KPI values. By learning, the system can understand this mapping and how to change configuration parameters to quickly get to the optimum system state.
Figures 12-14 schematically illustrate deployment of cognitive SON functionality in wireless networks of various physical architectures.
Assume a discrete set of time steps t = 0, 1 ,2, .. . , in, each of which a specific node must choose an action at from a finite set of actions A (including the empty action) that it has available in order to optimize an appropriate performance measure. If we denote by θ( the observation of the node at time r, then the function
π( θο, ao, θι, ai,. . . , ¾t) (2.1) is called the policy of the node and maps the complete history of observation-action pairs up to time t— to an optimal action at . In its simplest form the policy ignores all its observed history except for the last observation 0t resulting in the form
π(θ,) = a, (2.2) which is a mapping from the current observation of the entity to an action at.
In the observations of a node are embedded the (physical, really or artificial) environment it perceives and acts in and the world consisting of all nodes perceiving and acting in this environment. The collective information that is contained in the world at any time step t, and that is relative to performance measure, is called a state of the world and is denoted by st. The set of all states of the world will be denoted by S. From the point of view of a node, the world is (fully) observable if the observation θ, of the entity completely reveals the actual state of the world, that is, s, = θ,. On the other hand, in a partially observable world the observation θ, of the entity provides only partial information about the actual state s,. The stochastic coupling between s, and θ, may alternatively be defined by an observation model in the form ρ(θ, | s,), and a posterior state distribution p(s,|$,) can be computed from a prior distribution p(s,) using the Bayes rule:
p(st|St) = p(St | st) p(st) /p(¾) (2.3)
In many cases it is practical to perceive st as a function of st =h$ (θ,) which determines the best hypothesis from S, given the observations Θ. A fully observable world implies st = θ(, where h$ (θ,) = θ, and therefore the policy reads
π(δ,) = a, (2.4)
In many cases and for the purpose of simplification the Markov property is assumed for the world model where the current state of the world at time t summarizes all relevant information for the state at time t+1. More specifically, an entity can perceive a set S of distinct states and has a set A of actions it can perform. At each time step t the entity senses the current state st, chooses an action at and performs it with a
change of the environment and world state as a result. With other words upon action execution the environment responds by producing the succeeding state s,+i = 5(s,, a,). Here function δ corresponds to a transition model that specifies the mapping between a state-action pair (st> a,) to a new state s,+i with probability one if the environment is deterministic and probability environment p(s,+i|s,, a,) if the environment is stochastic. In the latter s,+i is a stochastic variable that can take all possible values in S, each with corresponding probability p(s,+i|s,, a,).
Each entity selects among the actions that achieve the objectives of the tasks/operations it has been aimed for. A way to formalize the notion of objective is to define them as goal states of the world that would correspond to the optimal states that the environment would be if the tasks were optimally performed. In general, an autonomous entity searches through the state space for an optimal sequence of actions to a goal state. Clearly, not all states are of equal preference and not all goal states are equally optimal. A formulization of the notion of preference and optimality is by assigning to each state s a real number U(s) that is called the utility of state s for that particular task and entity; the larger the utility of the state U(s), the better the state s. Such a function U evaluating each state of the world can be used by an entity for its decision making. Assuming a stochastic environment utility-based decision making is based on the premise that the optimal action a,* of the entity at state s, should maximize expected utility, that is,

where we sum over all possible states st+i e S the world may transition to given the entity takes action at. Then the entity must choose the action at* that gives the highest sum. This provides the entity with a policy that maps states to action optimally given utilities U(s). In particular, given a set of optimal (that is, highest attainable) utilities U*(s) in a given task, the greedy policy

is an optimal policy for the entity.
There is an alternative and often useful way to characterize an optimal policy. For each state s and each possible action a we can define an optimal action value or Q- value Q*(s, a) that measures the 'appropriateness' of action a in state s for that entity. For the Q-values holds U*(s ) = maxa Q*(s, a), while an optimal policy can be computed as

which is a simpler formula than (2.6) that does not make use of a transition model.
In many practical situations neither π nor U are known a-priori rather they should be learned as the entity executes its actions. Assuming that each time an action a the entity may derive a value indication for this state-action transition or may receive a reward r, = r(st, at) indicating the appropriateness of it, then the entity that executes a sequence of actions may face the problem of temporal credit assignment:
determining which of the actions in its sequence are to be credited with producing the eventual rewards.
Assuming a reward function r: Sx A→ R, i.e., the entity receives reward r(s, a) when it takes action a at state s, then the entity is to maximize a function of accumulated reward over its planning operation time. A standard such function is the discounted future reward r(s,,a,) + yr(s,+i,a,+i) + y2r(s,+2, a,+2)+"\ where γ e [0, 1) is a discount rate ensuring that the sum remains finite for infinite operation time. Clearly, different policies will produce different discounted future rewards, since each policy will take the entity through different sequences of states. The optimal value of a state s following some policy is defined as the maximum discounted future reward the entity would receive by starting at state s by:
U*(s) = maxEl (2.8) where the expectation operator Ε[·] averages over the stochastic transitions. Similarly, the optimal Q-value of a state s and action a of the entity is the maximum discounted future reward the entity can receive after taking action a in state s:

A policy 7i*(s) that achieves the maximum in (2.8) or (2.9) is an optimal policy: n*(s) e arg max Q (2. 10) a
Note that there can be many optimal policies in a given task, but they all share a unique U* and Q*.
The definition of Q* in (2.9) can be rewritten recursively by making use of the transition model:
Q*(s, a) = R(s, a) + γΥ p 'ls, ajmax Q*{s α') (2.11) a'
s
This is a set of nonlinear equations, one for each state, the solution of which defines the optimal Q* .
In many applications the transition model is unavailable. Q-learning is a method for estimating the optimal Q* (and from that an optimal policy) that does not require knowledge of the transition model. In Q-learning the entity repeatedly interacts with the environment and tries to estimate Q* by trial-and-error. The entity initializes a function Q(s,a) for each state-action pair, and then it begins exploring the environment. The exploration generates tuples (s,,a,,rt,s,+i) where s, is a state, a, is an action taken at state s,, r, = r(s,, a,) is a received reward, and S†+ IS i resulting state after executing a,. From each such tuple the entity updates its Q-value estimates as
Q(st, at) = (l - ) Q(st, at) + r + y ax Q(st+1 , at+l ) (2.12) where λε (0, 1) is a learning rate that regulates convergence. If all state-action pairs are visited infinitely often and λ decreases slowly with time, Q-learning converges to the optimal Q* [Watkinsl992] . A common exploration policy is the so-called ε-greedy policy by which in state s the entity selects a random action with probability ε, and action a = argmaxa Q(s,a ) with probability 1 - ε, where ε< 1 is a small number. Alternatively, the entity can choose exploration action a in state s according to a Boltzmann distribution
 where τ controls the smoothness of the distribution (and thus the randomness of the choice), and is decreasing with time.
where τ controls the smoothness of the distribution (and thus the randomness of the choice), and is decreasing with time.
Fully observable world environments imply that an entity is aware of all other
entities in its environment, their decisions and actions and the impact of these in the environment state. As a result of partial knowledge of the environment it is likely that an entity's actions may be counteracted by other entities actions. To avoid such a consequence entities may interact to converge to ajoint observation that is closer to true state of the world as in full observability. The true state is s is partially observable to the entities: each entity i receives an observation θί e Θί that provides information about s. The profile of the individual observations of all entities ($ defines the joint observation Θ. In many problems each observation is a deterministic function of the state: the observation of each entity at each state is fully determined by the setup of the problem. A more general observation models can be defined in which the coupling between states and observations is stochastic. For instance, an observation model could define ajoint probability distribution p(s,$) over states and joint observations, from which various other quantities can be computed, like ρ(θ) or p(6|s), by using the laws of probability theory.
In general, in multi -entity decision making under partial observability, the policy of each entity i is a mapping π;: θί→Α ι from individual observations $i to individual actions a; = π; (θί). The profile of individual policies (π;) defines the joint policy π.
Multi-entity decision making also requires defining an explicit payoff function Qi for each entity. This function can take several forms; for instance, it can be a function Qi (s, a) over states and joint actions; or a function Qi(9, a) over joint observations and
joint actions; or a function Qi(9i, a) over individual observations and joint actions. Note that often one form can be derived from the other; for instance, when an inverse observation model p(s|$) is available, we can write Qi($, a) =∑seS p(s|$) Qi(s, a) .
Assuming that every entity fully observes the current state then Q-learning can be extended to cover the case of concurrently learning entities. Furthermore we assume (i) for each entity i, a discrete set of actions ai e Ai i; (ii) a stochastic transition model p(s'|s, a) that is conditioned on the joint action a = (a at state s and (iii) for each entity i, a reward function ri: Sx A→ R , that gives entity i reward r^ (s, a) when joint action a is taken at state s. As previously, a policy of an entity i is a mapping %i(s) from states to individual actions. As in strategic games, ajoint policy 7i* = ( 7ii* ) i s a Nash equilibrium if no entity has an incentive to unilaterally change its policy; that is, no entity i would like to take at state s an action ai≠ (s) assuming that all other entities stick with their equilibrium policies π- * (s). The policy can be negotiated among' the entities as necessary. Negotiations are performed by means of interaction rounds with offers and counter-offers ending with accept or quit. The offers and counter offers refers to suggestions for joint actions who's Q(s,a) of the joint action a is within the thresholds of offer acceptability of the involved entities.
Under the above assumptions learning can be done, among others. by each entity separately, ignoring the presence of the other entities in the system, by having entities attempt to model each other, in which case their learning
algorithms are coupled i.e, by having each entity i maintain an Q-function Qi (s , a) , where the latter is defined over joint actions a. by having entities maximizing a discounted future global reward collaboratively, by having entities learning other entities negotiation strategies
For the cooperation and the negotiations the challenge is to design non-manipulable mechanisms in which no entity can benefit from not abiding by the rules of the mechanism. The focus here is on simple mechanisms with the following primitives:
- Ai is the set of available actions of entity i. - Θί is the set of private information $i e Θί that define the types of entity and which is not revealed to the other entities
- g: A→ O is an outcome function that maps a joint action a = (a to an outcome o = g(a).
- Qi (θί, a) is the payoff function of entity i that is defined as Qi(Si , a) = νι(θι , g (a) ) + ξί(8(α)) (2.14) where §: O→ R are payment functions, so that agent i receives payment ξί(ο) when outcome o is selected.
Including payment functions ξί is essential because we need to motivate the entity to participate in the mechanism; participation for an entity is not a priori the case. A mechanism in which no entity is worse off by participating, that is, Qi(Si, a) > 0 for all i, θί, and a , is called individually rational.
Figure 12 illustrates a cognitive SON centralized architecture. A central node with cognitive engine configure node functions. This includes function referring to control and information functions, e.g. RRM functions. The functions are preferably dedicated and abstracted. Figure 13 illustrates a cognitive SON distributed architecture with example
autonomous cognitive engine and where network nodes preferably have cognitive engine and functions collocated.
Figure 14 illustrates a cognitive SON hybrid network architecture with a plurality of options such as central coordination, distributed coordination, hierarchical structures, or a structure with central and distributed coordination at each level of the hierarchy.
As regards SON, a communication node (or simply node) is generally assumed to observe its environment, deliberate, decide what actions to take, actuate its decisions and finally adapt to its environment. It's desirable that in due course the node learns the most optimal decision given a set of environment conditions and possibly some feedback. An autonomous node is any device where decisions can be made. The term communications nodes will be exemplifies by radio/wireless nodes which in cellular (mobile) networks refer to infrastructure nodes such eNBs (enhanced Node B) and BSs (Base Stations) and mobile nodes such as UE (User Equipment) and mobile terminals.
Figure 15 shows SON functionality of cognitive SON as follows: · Observation: monitors the environment for observations Θ in order to derive the current state s (in its simplest form it monitors parameters and may/may not derive statistics from observed parameters).
• Analysis: derives the true state s from observations Θ (in its simplest form it estimates performance metrics and correlations between parameters that would characterize a true state s).
• Decision: select action a by exploring and exploiting based on a policy π
Figure 16 illustrates schematically the interactions between two independent processes running in two separate autonomous nodes.
In this description, certain acronyms and concepts widely adopted within the technical field have been applied in order to facilitate understanding. The invention is not limited to units or devices due to being provided particular names or labels. It applies to all methods and devices operating correspondingly. This also holds in relation to the various systems that the acronyms might be associated with.
While the invention has been described in connection with specific embodiments thereof, it will be understood that it is capable of combining the various embodiments, or features thereof, as well as of further modifications. This specification is intended to cover any variations, uses, adaptations or implementations of the invention; not excluding software
enabled units and devices, processing in different sequential order where non-critical, or mutually non-exclusive combinations of fea- tures or embodiments; within the scope of subsequent claims following, in general, the principles of the invention as would be obvious to a person skilled in the art to which the invention pertains.
More embodiments of the invention Background
The role of Wireless Networks in the Future internet will, in its most dynamic form, enable multi-hop topologies consisting of heterogeneous wireless networks and technologies ranging from short-range radio to cellular systems. The final vision becomes rather complex when user devices of different capabilities, traffic demands conforming to different QoS profiles and multiple control and management authorities interfere and contend for a common set of radio resources. This evolution towards more complex systems renders imperative the need for adaptable and scalable systems that operate optimally in complex, adverse and unpredictable environments. To approach optimal network operation, the development of rational and autonomous network nodes is critical. Here we therefore focus on cognitive, autonomous, cooperative self- xed nodes, operating and interacting in a network over wireless and wired backhauling connections.
Cognition is a multi-disciplinary concept targeting systems with a wide range of capabilities such as resource sensing, interpretation, inference, prediction, decision making, learning, and cooperation. Generally, self-management encompasses self-capabilities, such as, self-awareness, self-configuration, self-optimization and self-healing. The need for cognitive adaptation spans various time-scales due to the different time-scales of the changes in the radio or networking environment. For example, short scale changes radio environment are caused by fading and shadowing, and adaptation requires fast reaction. Medium time-scale changes are caused by the changing set of communicating devices or traffic flows, finally, long term changes happen due to changing traffic load or due to network failures.
The basis for cognitive, autonomous and self-managing networks is a high level of local node awareness about the local physical and network environment, as well as some notion of the corresponding global network status. In order to make such a level of cognition possible, cognitive nodes must efficiently represent and store environmental and operational information, since a distinctive characteristic of cognitive radios and cognitive networks is the capability of making decisions and adaptations based on past experience, on current operational conditions, and also possibly on future behaviour predictions. It is therefore imperative to obtain a functional understanding of the underlying environments, such that operational models of each system layer can be constructed and subsequently combined to an integrated model where the relation between the parameters of the physical and network environment and its correlations are exposed. The models of the environment in each node provide only partial knowledge. Nodes may therefore cooperate in order to jointly acquire a more global knowledge of the environment, enabling distributed optimization.
The cognitive capabilities of a network node are enabled by a Cognitive Engine (CE), as depicted in architecture later on. Through the cognitive engine, a cognitive node can maintain a model of the local environment that in turn allows for educated communications decision based on the impact of its actions. A cognitive node can further make rational decisions in order to maximize its performance metrics, e.g., a cognitive node selects a power setting value that will lead to optimal utilization of network resources. A cognitive node can act autonomously since the CE provides the ability to learn and adapt to a changing environment.
To empower such cognitive nodes a cognitive engine should be able to: Accurately model the dynamics and the state of its environment by means of : o Performance metrics and environment dynamics (physical environment - radio resources)
o Model-deduced knowledge/information exchange between the cognitive nodes (network environment - neighboring nodes). Make rational decisions in terms of action selections. o The goal for a rational node is to maximize the expected utility of its actions given the state of its physical and network environment. o Learn from past actions, events, impact and (delayed) feedback.
An architecture suited to dynamic future mobile network environments is herewith suggested to cope with emerging concept of cognitive autonomous, cooperative, self-Xed and self-organisednetworks.
/. / Control Optimisation Concepts
A system may be in different states at any one time. As a result of internal processes (within the system) or external processes (within the outside environment) a system's state may change many times throughout its life-time. Typically, such processes cause system state transitions. In general, some system states are desirable while others are not. In technical systems, some system states are a system's target while others are not. Performing control over the processes aims at steering system transitions to targeted system states e.g., states where the system performs optimally. Describing a system is done by means of a model. A model of any system consists of all the entities in the system, their states and procedures not excluding any information derived to understand and evalutate the system.
In technical systems, a system state is typically represented/described/characterised(?) based on a multiplicity of quantifying parameters of the system model. This set of parameters, S, provide all the parameters necessary to differentiate between any two system states.
Parameters can be monitored, calculated, estimated and/or derived from statistical observations. In technical systems such as, (cellular) radio networks, system parameters include perfbrmance/evaluaiton metrics, key performance indicators, configuration settings
etc. More specifically, a system state can be defined as System state S, S = (KPIi,...,KPIN) where KPI in a radio network may incl. cell load, number of users, radio resource utilisation, throughput, spectral efficiency, QoS, etc.
To any system state the system may respond by means of actions it is equipped with. The goal is to act so as the system remains in or moves towards a target state. Acting refers to the execution of one or multiple instructions on the operation of the system. In a radio network an action corresponds to the configuration of network nodes that controls its operation. To this end, a system operating entity is equiped by a set of actions A which are performed as needed to drive the system towards a goal/target state e.g., radio resource allocation for optimal throughput performance where the actual allocation corresponds to the action and optimal trhoughput performance to the target state. More specifically, we define
Action A, A = (ai,...,aM) where a is an action which in a radio network corresponds to the setting of one or more configuration parameters incl. transmitted power, antenna tilt, antenna mode, beam-forming, mobility offset, admission threshold, etc Figure 17 illustrates a system according to the invention.
Given the above definitions, control refers to the process of identifying an action to any state of the system that is a target state. More specifically,
Control, 7i(s):S→A maps a state se S into action ae A and
Policy - the control process function 7i(s) defined over all states in S. Generally, the objective of control optimisation is to find the most optimal (or an optimal) policy.
With other words the problem can be defined as follows:
- At each state of the system, find the best action a among a given set of authorised actions A
This is performed by means of an optimiser that operates on top of and configures the controller. As depicted in Fig. 18 three levels of operation can be defined:
(i) optimisation level (optimiser),
(ii) adaptation level (controller) and
(iii) execution level (system function such as any RRM function of a radio
network).
Consequently, the best action can an be found if the full control process 7i(s) is optimised towards one single or multiple objectives.
Objectives are expressed by means of utility functions ( objective functions) that describes how close to the targeted optimum a system state is. A utility function is a function that maps from system states to real numbers.
1.2 Cooperative control Optimisation
Implementing cooperation requires the deployment of communication enabling functionality. In this framework, cooperation enablers refer to those mechanisms, procedures and/or protocols which make the collaboration between network nodes and system entities possible. Collaboration spans between information exchange, actions coordination and decision making; moreover, such aspects are expected to be exploited in different dimensions thus featuring different communication layers and capabilities. Three of the key aspects for decision and control that are based on cooperation or can potentially benefit from it, are:
Collaboration by means of information exchange, ranging from node independent sensing (i.e., no information exchange between nodes) to full context/knowledge presentation and sharing,
Coordination of decision and configuration control ranging from independent decisions up to fully coordinated decisions about reconfigurations,
• Utilisation of layer mechanisms ranging from PHY/MAC layer mechanisms to L3 and above for cooperative transmissions.
In Figure 1, the above three different dimensions of cooperative operation are illustrated along with some key enabling technologies and solutions that can be deployed for addressing energy-efficiency. These technology solutions are depicted as planes in the three-dimensional space described above. The planes illustrated here are only examples that demonstrate the scope of cooperation. It is also possible that the scope of some technology solutions can be a line, a vector or a point in this space. As an example it can be seen that the information exchange (collaboration) axis ranges between no information and full information. In case of no information exchange, it is assumed that nodes rely on their sensing/monitoring of the environment. Although this implies local (partial) knowledge of the environment it is still possible to have nodes cooperating as for instance in pure conflict resolution protocols where nodes sense collisions and react by means of back -off (giving the opportunity to other nodes to transmit). Certainly, this is a very simple case of cooperation of nodes making independent decisions. Similarly in a cognitive radio scenario secondary users may base their (independent) decisions for acquiring white spaces on their own sensing data.
In principle any cooperative and/or autonomous solution can be mapped to this space which can present numerous kinds of solution arrangements for cooperation. With other words, two nodes may cooperate by simply exchanging information with each other and deciding independently. Alternatively two nodes may cooperate by deciding on a coordinated plan of configurations divided between them. Finally, cooperation may be performed by each layer separately or in a cross-layer fashion.
For each one of the above dimensions a set of enablers for cooperative decision and control should be associated to it. In particular the following associations are envisaged:
Figure 19 illustrates dimensions of cooperative decision and control according to the invention.
• Information/Context exchanging axis (or collaboration axis): sensing data, configuration settings, fused/processed information, knowledge presentation, etc.,
• Decision coordination and control axis (or coordination axis): routing/relaying control, negotiation protocol, coordination planning, synchronisation, distributed decision making, knowledge reasoning, conflict resolution, etc.,
• Layer mechanisms axis (or communication layer axis): Routing/ relaying at L3 layer, MAC protocols and/or relaying at L2 layer, cooperative multi-point transmission at LI (PHY) layer, network coding and cross-layer etc.
The above resembles an optimisation system where information, control and configuration are specified as part of the enablers which are briefly described in section III.
In general, cooperativeness can be studied in two different directions. In the first direction it captures the balance between a node's individual objectives and the objectives of the network it belongs to. In its simplest form a network objective can be defined as the sum of all nodes' objectives (as in social welfare). A node may defer from taking actions that maximise its individual objectives for the benefit of the maximisation of the network objectives. For instance, a cell may select a lower power setting that maximises the overall network throughput (e.g., cause less interference) to the expense of its cell throughput performance. On the other hand a node may select a higher power setting to increase its own cell throughput causing more interference to all neighbouring cells and thus reducing the overall network throughput.
The second direction focuses on the trade-offs and the benefits offered by a fully cooperative (coordinated decisions) and a simpler autonomic (independent decisions) approach. For example extensive information exchange would increase signalling while the absence of any information would lead to non-optimal decisions.
1.3 Optimisation Problems
Problems to be solved in order to achieve an optimal control implemenation are listed below as associated to policy optimisations i.e., the optimisation of the action-state mapping .
Problems associated to state parameters
The set of parameters describing the system state is not complete i.e., the parameters fail to differentiate system states.
The set of parameters is many and the system state description becomes complex.
There is only partial knowledge about the values of the parameters - The parameteres are noisy e.g., due raffic and radio channel are stochastic snd/or
measurements have limited precision
System parameters are continuous and consequently the state space consists of infinitely many states. The latter is typically tackled by statistical methods ro fuzzy logic.
Problems associated to state-action pairs - The environment is stochastic i.e., the transition between system states is not deterministic.
Problems associated to actions
The list of actions is incomplete to achieve the targeted objective.
The utility function guiding the action selection diverges from target system state or converges unacceptably slowly. - ...
Problems associated to cooperative optimisation control Trade-off between node versus network objectives.
Signalling/coordination/information exchange cost e.g., overhead and energy.
2 SON Functionality
2.1 Background
Assume a discrete set of time steps t = 0, 1, 2, . . ., in each of which a specific node must choose an action a, from a finite set of actions A (including the empty action) that it has available in
order to optimize an appropriate performance measure. If we denote by θχ the observation of the node at time τ, then the function π( θο, α0, θι, (Xi, . . . , 0, ) = a, (2.1) is called the policy of the node and maps the complete history of observation-action pairs up to time t -to an optimal action a, . In its simplest form the policy ignores all its observed history except for the last observation Θ, resulting in the form π( Θ, ) = a, (2.2) which is a mapping from the current observation of the entity to an action α,.
In the observations of a node are embedded the (physical, really or artificial) environment it perceives and acts in and the world consisting of all nodes perceiving and acting in this environment. The collective information that is contained in the world at any time step t, and that is relative to performance measure, is called a state of the world and is denoted by st. The set of all states of the world will be denoted by S. From the point of view of a node, the world is (fully) observable if the observation 0t of the entity completely reveals the actual state of the world, that is, st = 9t. On the other hand, in a partially observable world the observation 0t of the entity provides only partial information about the actual state st. The stochastic coupling between st and 0t may alternatively be defined by an observation model in the form p(0t |st ), and a posterior state distribution p(st |9t) can be computed from a prior distribution p(st) using the Bayes rule: p(st |6t ) = p(6t |st )p(st)/p(6t) (2.3) In many cases it is practical to perceive st as a function of st =he(9t ) which determine the best hypothesis from S, given the observations Θ. A fully observable world implies st = 9t , where he(9t ) = 6t and therefore the policy reads π( ¾ ) = at (2.4) In many cases and for the purpose of simplification the Markov property is assumed for the world model where the current state of the world at time t summarizes all relevant information for the state at time t+1. More specifically, an entity can perceive a set S of distinct states and
has a set A of actions it can perform. At each time step t the entity senses the current state st, chooses an action a, and performs it with a change of the environment and world state as a result. With other words upon action execution the environment responds by producing the succeeding state
 α,). Here function δ corresponds to a transition model that specifies the mapping between a state-action pair (st, α,) to a new state st+i with probability one if the environment is deterministic and probability environment p(st+i|st , a, ) if the environment is stochastic. In the latter S†+ IS i stochastic variable that can take all possible values in S, each with corresponding probability p(s,+i|s, , a, ).
α,). Here function δ corresponds to a transition model that specifies the mapping between a state-action pair (st, α,) to a new state st+i with probability one if the environment is deterministic and probability environment p(st+i|st , a, ) if the environment is stochastic. In the latter S†+ IS i stochastic variable that can take all possible values in S, each with corresponding probability p(s,+i|s, , a, ).
Each entity selects among the actions that achieve the objectives of the tasks/operations it has been aimed for. A way to formalize the notion of objective is to define them as goal states of the world that would correspond to the optimal states that the environment would be if the tasks were optimally performed. In general, an autonomous entity searches through the state space for an optimal sequence of actions to a goal state. Clearly, not all states are of equal preference and not all goal states are equally optimal. A formulization of the notion of preference and optimality is by assigning to each state s a real number U(s ) that is called the utility of state s for that particular task and entity; the larger the utility of the state U(s ), the better the state s. Such a function U evaluating each state of the world can be used by an entity for its decision making. Assuming a stochastic environment utility-based decision making is based on the premise that the optimal action a, of the entity at state s, should maximize expected utility, that is,

where we sum over all possible states s,+i e S the world may transition to given the entity takes action a, . Then the entity must choose the action a, that gives the highest sum. This provides the entity with a policy that maps states to action optimally given utilities U(s ). In particular, given a set of optimal (that is, highest attainable) utilities U*(s ) in a given task, the greedy policy

is an optimal policy for the entity.
There is an alternative and often useful way to characterize an optimal policy. For each state s and each possible action a we can define an optimal action value or Q-value Q*(s , a) that measures the 'appropriateness' of action a in state s for that entity. For the Q-values holds U*(s ) = maxa Q*(s , a), while an optimal policy can be computed as * (s) = arg max Q* (s, ) (2.7) which is a simpler formula than (2.6) that does not make use of a transition model.
In many practical situations neither π nor U are known a-priori rather they should be learned as the entity executes its actions. Assuming that each time an action a the entity may derive a value indication for this state-action transition or may receive a reward r, = r(st,a, ) indicating the appropriateness of it, then the entity that executes a sequence of actions may face the problem of temporal credit assignment: determining which of the actions in its sequence are to be credited with producing the eventual rewards. Assuming a reward function r: S χ A→ R, i.e., the entity receives reward r(s , a) when it takes action a at state s, then the entity is to maximize a function of accumulated reward over its planning operation time. A standard such function is the discounted future reward r(st,at) + Yr(st+i,at+i) + y2r(st+2, at+i)+- · · , where γ e [0, 1) is a discount rate ensuring that the sum remains finite for infinite operation time. Clearly, different policies will produce different discounted future rewards, since each policy will take the entity through different sequences of states. The optimal value of a state s following some policy is defined as the maximum discounted future reward the entity would receive by starting at state s by:
U* (s) = max (2.8)

where the expectation operator Ε[·] averages over the stochastic transitions. Similarly, the optimal Q-value of a state s and action a of the entity is the maximum discounted future reward the entity can receive after taking action a in state s:
Q* (s, a) = = s, 0 = a, at>0 = (st ) (2.9)
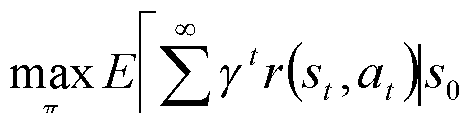
A policy Ji*(s) that achieves the maximum in (2.8) or (2.9) is an optimal policy:
π * (s) e arg max Q* (s, a) (2.10) Note that there can be many optimal policies in a given task, but they all share a unique U* Q*.
The definition of Q* in (2.9) can be rewritten recursively by making use of the transition model:
Q* (s, a) = R(s, a) + γ∑ p(s'\s, a)max Q* (s α') (2.11) This is a set of nonlinear equations, one for each state, the solution of which defines the optimal Q*. In many applications the transition model is unavailable . Q-learning is a method for estimating the optimal Q* (and from that an optimal policy) that does not require knowledge of the transition model. In Q-learning the entity repeatedly interacts with the environment and tries to estimate Q* by trial-and-error. The entity initializes a function Q(s,a) for each state-action pair, and then it begins exploring the environment. The exploration generates tuples (st,at,r,,St+i) where st is a state, at is an action taken at state st, r, = r(st , at) is a received reward, and st+i is a
resulting state after executing at. From each such tuple the entity updates its Q-value estimates as
Q{s at ) = {l - ) Q{st , at ) + r + Ymax Q(st+1 , at+1 )
where λ□ (0, 1) is a learning rate that regulates convergence. If all state-action pairs are visited infinitely often and λ decreases slowly with time, Q-learning converges to the optimal Q□ [Watkins 1992] . A common exploration policy is the so-called ε-greedy policy by which in state s the entity selects a random action with probability ε, and action a = argmaxa'Q(s,a ) with probability 1 - ε, where ε < 1 is a small number. Alternatively, the entity can choose exploration action a in state s according to a Boltzmann distribution

Fully observable world environments imply that an entity is aware of all other entities in its environment, their decisions and actions and the impact of these in the environment state. As a result of partial knowledge of the environment it is likely that an entity's actions may be counteracted by other entities actions. To avoid such a consequence entities may interact to converge to a joint observation that is closer to true state of the world as in full observability. The true state is s is partially observable to the entities: each entity i receives an observation θί εΘΙ that provides information about s. The profile of the individual observations of all entities (0i ) defines the joint observation θ. In many problems each observation is a deterministic function of the state: the observation of each entity at each state is fully determined by the setup of the problem. A more general observation models can be defined in which the coupling between states and observations is stochastic. For instance, an observation
model could define ajoint probability distribution p(s, Θ) over states and joint observations, from which various other quantities can be computed, like ρ(θ) or p(0|s ), by using the laws of probability theory.
In general, in multi -entity decision making under partial observability, the policy of each entity i is a mapping jii : Θί→ Ai from individual observations 0i to individual actions ai = Jii (0i ).
The profile of individual policies (jii ) defines the joint policy π.
Multi-entity decision making also requires defining an explicit payoff function Qi for each entity. This function can take several forms; for instance, it can be a function Qi (s , a) over states and joint actions; or a function Qi (θ, a) over joint observations and joint actions; or a function Qi (0i , a) over individual observations and joint actions. Note that often one form can be derived from the other; for instance, when an inverse observation model p(s |θ) is available, we can write Qi (Θ, a) =∑se S p(s |0)Qi (s , a).
Assuming that every entity fully observes the current state then Q-learning can be extended to cover the case of concurrently learning entities. Furthermore we assume (i) for each entity i, a discrete set of actions ¾ ε Ai 5 (ii) a stochastic transition model p(s'|s , a) that is conditioned on the joint action a = (a^ ) at state s and (iii) for each entity i, a reward function ri : S χ A→ R, that gives entity i reward ri(s , a) when joint action a is taken at state s. As previously, a policy of an entity i is a mapping jii (s ) from states to individual actions. As in strategic games, ajoint policy π* = (π*ί ) is a Nash equilibrium if no entity has an incentive to unilaterally change its policy; that is, no entity i would like to take at state s an action a^≠ π*ί (s ) assuming that all other entities stick with their equilibrium policies π*-ί (s). The policy can be negotiated among the entities as necessary. Negotiations are performed by means of interaction rounds with offers and counter-offers ending with accept or quit. The offers and counter offers refers to suggestions for joint actions who's Q(s,a) of the joint action a is within the thresholds of offer acceptability of the involved entities.
Under the above assumptions learning can be done, among others, by each entity separately, ignoring the presence of the other entities in the system.
by having entities attempt to model each other, in which case their learning algorithms are coupled i.e, by having each entity i maintain an Q-function Qi (s , a), where the latter is defined over joint actions a. by having entities maximizing a discounted future global reward collaboratively. - by having entities learning other entities negotiation strategies
For the cooperation and the negotiations the challenge is to design non-manipulable mechanisms in which no entity can benefit from not abiding by the rules of the mechanism. The focus here is on simple mechanisms with the following primitives:
Ai is the set of available actions of entity i.
- Θί is the set of private information 0i e Θί that define the types of entity and which is not revealed to the other entities
g: A→ O is an outcome function that maps a joint action a = (ai ) to an outcome o = g(a). Qi (0i , a) is the payoff function of entity i that is defined as
Qi (0i , a) = vi (0i , g(a)) + ^ (g(a)) (2.14) where ξί : O→ R are payment functions, so that agent i receives payment ξί (o ) when outcome o is selected.
Including payment functions ξί is essential because we need to motivate the entity to participate in the mechanism; participation for an entity is not a priori the case. A mechanism in which no entity is worse off by participating, that is, Qi (0i , a) > 0 for all i, 0i, and a, is called individually rational.
2.2 Cognitive SON Optimisation process
Figure 21 illustrates cognitive SON optimisation process
general we assume a communication node (or simply node) to observe its environment, deliberate, decide what actions to take, actuate its decisions and finally adapt to its environment. It's desirable that in due course the node learns the most optimal decision given
a set of environment conditions and possibly some feedback. An autonomous node is any device where decisions can be made. In this text the term communications nodes will be exemplifies by radio/wireless nodes which in cellular (mobile) networks refer to infrastructure nodes such eNBs and BSs and mobile nodes such as UE and mobile terminals. A node implementing the steps depicted in Figure 21 implements cognitive SON.
Given the background a description of the cognitive SON functionality is as follows:
Observation: monitors the enviroment for observations Θ in order to derive the current state s (in its simplest form it monitors parameters and may/may not derive statistics from observed parameters)
Analysis: derives the true state s from observations Θ (in its simplest form it estimates performance metrics and correlations between parameters that would characterize a true state s).
Decision: select action a by exploring and exploiting based on a policy π Learning: learns optimal policy π *, learns a concise description distinguishing states, learns efficient negotiation and cooperation
Actuator: execute actions or cooperates with other entities to collaborate i.e., exchange observations or to coordinate i.e. synchronize actions
Some indications for the implementation of the above functions will be described in the system architecture that implements the SON optimization functionality.
Fig.22 visualises the interactions between two independent processes running in two separate autonomous nodes.
3 Overall Architecture Solution
3.1 Cognitive SON Engine Architecture
The above architecture has been designed for the optimisation of the control policy by Functional Units (FU) or simplicity Units (shown in Fig.23) as follows:
Sensing/Monitoring Functional Unit deals with the observation and state transmission modelling.
Configuration/Decision Making Functional Unit deals with the action-state modelling for action selection and valuation.
Optimisation Functional Unit deals with the optimisation of all models, functional units and optimal control of policies
Interaction Functional Unit deals with interaction modelling for negotiation and communication of decisions and execution/effectuation of selected actions.
Knowledge base consists of facts and rules describing the models required for the realisation of the cognitive SON engine. Knowledge base can be a Functional Unit of its own or maintained and communicated between functional units as depicted above.
The architecture illustrating the functionality in two independent CSONE entities (Fig. 24)
3.2 Knowledge/Information Base
Operation in the cognitive SON engine CSONE is supported and realised by means of knowledge stored in a knowledge base. More specifically, each node of the above identified functional units maintain a knowledge -base consisting of facts and rules. The implementation of such a knowledge base can be part of the above modules or a separate functional entity updating and providing access to information.
Facts are represented by parameter-value pairs that build up a model of the environment and the-self i.e., the owner of the facts and the knowledge -base. Facts are used to represent information about
Monitoring Parameterse.g., o the radio environment incl. load, interference etc o KPIs i.e., performance metrics Discovery Parameters o neighbouring nodes and neighbouring nodes capabilities, state etc
Configuration parameters o Configuration settings e.g., transmitted power settings, etc
Rules are represented by parameter-value implications of premise-implies-conclusion (If <premise> then <conclusion>) type. A premise may be a rule or a (conjunction of) fact(s), typically of monitoring types. A conclusion can be a rule or a (conjunction of) fact(s), typically of configuration type. Rules may apply for all values of parameters of a subset of values as defined by numerical operators ==, =<, =>, <,>,!= etc. Rules may imply rules or facts.
In terms of contents the set of facts and rules represents a model of the environment in which the knowledge possesing entity interacts in and a model of the entity itself including its capabilities, objectives, roles, functions and actions.
Formally, Knowledge K consists of facts and rules
Facts reflects on apriori knowledge of the environment and the entity itself. It includes among others the system state S set, the actions A set that the entity itself and functions F set
Rules= control i.e., IF se S then aeA Utilities = functions for the evaluation of system states U
Facts and Rules are stored in a Knowledge Base accessible by all functional units partially or in its entirity.
The state of the environment se S is described as a state function fseF over the set of observed parameters, fs (p):P --> S, where p = (θ(ρ , θ(ρ2), ..., θ(ρΡ )) where pi is a parameter of parameter function and |P| denoting the cardinality of the set of parameters.
By means of facts, rules and utilities as described, a model of the external environment and the rules the environment obays can be described and stored in the knowledge base. An observation and transition model of the environment can be also described in terms of environment states and transisitions between states due to events caused by external entities or due to actions taken by the CE itself. The environment model is based on apriori and/or learned knowledge and presented by parameters or parameter functions.
3.3 Sensoring/Monitoring Functional Unit
Figure 25 illustrates a system according to the invention.
Two of the main roles of the sensing/monitoring is to sense and monitor observable parameters and collect short-term and long-term statistics on parameter values and performance measurements (infromation observing operation). to better describe the environment states i.e., to uniquely identify the state of the environement and define it accurately and in a concise way (information processing operation).
In the above description, uniquely refers to the set of parameters that differentiate between any two states of the system. Accurately refers to the correct representation of the parameter values and parameter relations at any one time. Concisely refers to the minimum number of parameters required to characterise the state.
The task of the information observing operation is to update the state environment description p so as it reflects the actual environment at anyone time. The information processing operation
targets to learn the different states of the environment. This can be done in numerous ways including classifying the parameter-value pair <p, x(p)> combinations observed in the system by means e.g., decision trees. Decision trees classify instances of p by sorting them down the tree from the root to some leaf node, which provides the classification of the instance. Each node in the tree specifies a test of some parameter of p, and each branch descending from the node corresponds to one of the possible values for this parameter. A instance of p is clasified by starting at the root node of the tree, testing the parameter specified by this node, then moving down the tree branch corresponding to the value of the parameter. This process is repeated for the subtree rooted at the new node. In general, decision trees represent a disjunction of conjunctions on the parameter values of instances. Each path from a tree root to a leaf corresponds to a conjunction of parameter tests, and the tree itself to a disjunctions of these conjunctions. The goal of a decision tree is to select the parameter that is most useful in classifying states. Parameter tests based on the measure of entropy can be used to characterise the (im)purity of an arbitrary collection of parameter p instances. Decision tree is only an example of classifying states.
Sensing/Monitoring functions incl.
Collection of measurements and KPIs - KPI Statistical processing
Control of KPI monitoring o Control of monitoring parameters
Input to environment model
Sensing/Monitoring FU contributes directly to · Observation model
• Transition model
• state-action model and supports Interaction and Negotiation model
MCi (monitoring-to-communication interface) - Communicates measurement monitoring (set) o Monitoring parameters o Monitoring time interval
Communicates measurement info (get) according to set
MDi (monitoring-to-decision interface) - Communicates system state information
Mi (monitoring interface) - optional - alternatively this set of commands can be perfromed trhough the communication/execution module.
Device dependent o RRM at Base station o Sensor Element/Gateway
Config measurement monitoring (set) o Monitoring parameters o Monitoring time interval
Measurement info (get) according to set
3.4 Configuration/Decision Functional Unit
Figure 26 illustrates a system according to the invention.
Configuration/Decision Making functions incl.
Decisions for the configuration of control and operation (based on environment state info) e.g., o Radio resource configuration and control configuration ■ Power
■ Spectrum
■ Mobility parameters etc Configuration/Decision FU contributes directly to
• State-action model · Transition model
• Interaction and Negotiation model And interacts/supports observation model Di (configuration interface)
Device dependent o RRM at Base station o Sensor Element/Gateway Decision Part (Di) o Config control parameters (set) o Configuration info (get) - Execution part (Xi) o Configuration of device
3.5 Interaction Functional Unit
Figure 27 illustrates a system according to the invention.
Interaction functions incl.
Communication/Cooperation Unit
o Information exchange
■ Monitoring information
■ Configuration information incl. Power, IC, spectrum etc
■ Neighbour information
o Cooperation procedures and protocols incl
■ Negotiation of configuration parameter settings
■ Auction for radio resources as in multi-operator spectrum sharing Execution Unit - configuration settings
Interaction FU contributes directly to
Observation model
Interaction and Negotiation model
And supports state-action and transition models
Ci/Xi (Cooperation-Communication / Execution interface)
Device dependent
o RRM at Base station
o Sensor Element/Gateway
Communication/Cooperation part (Ci) o Negotiation protocol o Auction protocol o Discovery of Neighbouring nodes Execution part (Xi) o Configuration of (own) controlled devices (on behalf of Sensing/Monitoring, Decision Making, and Optimisation modules) o Configuration of remote devices (on behalf of Sensing/Monitoring, Decision
Making, and Optimisation modules) o Configuration of function (on behalf of Sensing/Monitoring, Decision Making, and Optimisation modules)
3.6 Optimisation Functional Unit
Figure 28 illustrates optimization functional unit.
Opimisation Functional Unit deals with an analysis part and a learning part.
The analysis/reasoning unit elaborates on the identification of relevant statistics, correlations and conditional probablities between states, observations, actions and any combination thereof.
The learnign unit is trying to learn from experince patterns in the world model that can assist in predicitions and optimal operation. A cognitive SON engine CSONE is said to learn from experience E with respect to some class of tasks T and performance measure/metrics P, if its performance at tasks in T, as measured by P, improves with experience E.
For example a radio node that learns configuration of mobility optimisation might improve its mobility performance as measured by its ability to optimally configure mobility parameters through experience obtained by configuring mobility with its neighbours.
A well-defined learning problem requires a well-defined task, performance metric and training experience. Design a learning approach involves a number of design choices, including choosing the type of training experience, the target (or objective) function to be learned, a representation for this function and an algorithm for learning the target function from training examples.
In general, learning involves searching through a space of possible hypotheses H to find the hypothesis h that best fit the available training examples D and other prior constraints or knowledge. In terms of SON functionality at any one time t, h, would correspond to a state s, and D to the current set observations Θ.
Much of the above optimisation and control functionality is performed by learning methods that search different hypothesis spaces (e.g., numerical functions, decision trees, neural networks, policies, rules) based on different conditions under which these search methods converge toward an optimal hypotheses.
Operation of optimisation control is performed by learning new facts and rules or by modifying existing rules to improve performance.
Optimisation functions incl. - Classifies state of the enviroment based on the parameters for one signele or multiple
objectives
Learn and recognise the most significant parameters for specific functions/ Learn and recognize changes in the environment state Learn optimum configuration settings for different environment states - Learn optimal cooperation and negotiation strategies
Optimisation FU contributes directly to all models in the cognition cycle
• Observation model
• Interaction and Negotiation model
• state-action model · transition model
Oi (Optimisation of Control interface)
Three different interface specifications for the different models within Monitoring (Osi) Decision making (Odi) - Communicating/Executing (Oci))
3.7 Optimisation Objective and Methods
Generally, optimisation methods aims at learning a policy that maps any state of the system to an optimal set of actions according to the objectives of the optimising entity/function(s).
Regardless whether policies are maintained and executed centrally or distributed in numerous was of functional split and functional distribution
For a practical implementation of the optimisation it is required that the optimising entity is able to efficiently learn - all distinguishable states of the system and the differentiating parameters an accurate model of environment and the rules governing it for future predictions all transitions between different system states
an optimal course of sequential and/or joint parallell actions to achieve control and operation optimisation a set of rules that guarantees efficient and stable operation and fast convergence as the system state changes.
Here we suggest an optimisation architecture that facilitates
State optimisation
Action optimisation
State-Action Optimisation
Networking Optimisation
In the sequel we mention some and present some other possible example optimisation methods.
State optimisation
The goal of the state optimisation is to identify the set of parameters that for a given objective (or set of objectives) concisely differentiates between any two states of the system. E.g.,
Decision Tree Learning can be applied to identify the parameter-value pair that best classifies the states
Bayesian Learning can be applied to identify the conditioning and the correlations between parameters indicative to a system state.
Alternative learning methods for learning the state are o inductive learning (learning the rules out of observable facts) , o Neural Networks (learning of functions from known examples), o instance-based learning (learning state functions from similarities and differences between instances),
o etc
The output of the state optimisation is concise descriptions of system states where organisation patterns and operation patterns are uniquelly identified. An optimised solution is a solution where each state is described by a minimum number of parameter-value pairs. Another objective of the state optimisation is that facts and rules i.e., the model renders accurately the environment at any one time. Updating the facts to reflect the state of the environment optimally requires
State Transition optimisation
The goal of the state optimisation is to identify the set of parameters that for a given objective (or set of objectives) concisely differentiates between any two states of the system.
State-Action optimisation
Methods for action-state optimisation that do not necessarity require a transition model include
Reinforcement learning
Genetic algorithms etc
Reinforcement Learning (RL) based optimisation
Learning refers to the ability of radio nodes to learn from their environment and their interactions with other radio nodes.
Learning aims at identifying an optimal set of actions for which the radio node and the overall network perform best.
An action typically corresponds to value settings of configuration parameters/variables.
The performance of the system is evaluated by means of an objective function which corresponds to the total reward or payoff or utility.
The learning is performed by means of sophisticated trial and error searching among all possible parameter value combinations.
A specific form of learning that conforms to the above description is reinforcement learning. Q- Learning (QL)
RL can be used by a controller to estimate based on past experience, the expected payoff/reward associated with their actions. One particular implementation of RL is
Q -learning.
Q-value, Q(s,a), is a value function that provides a numerical estimate of the value of performing an individual action a at a given state s of the environment. The controller updates its estimate Q(s,a), based on sample (a, r) as follows:
Q(s,a) Q(s,a) + λ(Γ- Q(a))
The sample (a, r) is the experience obtained by the base station: action a was performed resulting in payoff/reward r. λ is the learning rate (0 < λ <1), governing to what extent the new sample replaces the current estimate. Assuming infinite number of iterations the algorithm converges to an Q(a).
Learning task
Fig. 29
Find a policy 7i(s):S→A that maximises the sum of future cumulative rewards in which r, = r(s,,a,) St+i = 5(st,at)

- Deterministic Environment maxU" (s. ∑ +i+i
- Nondeterministic Environment π*≡ arg max U'I
 (ys) with value function denoted as U*(s)
(ys) with value function denoted as U*(s)
π
- Optimal policy
π * (s)≡ arg max Q(s, a) V* (s)≡ arg max Q(s, a')
a a'
Q-algorithm
Q-Function - starting from
We choose an action a,, and continue with the (up to now) best policy Qt+1 (st , at) = rt+l + γ max Qt (st+1 , a')
a
To guarantee convergence a learning rate coefficient η can be added
Qt+i (st > at ) = (l - 1 )£?, (s,, <*t) + (rt+1 + J max Qt (st+1 , a'
rt+l + γ max Q, (st+l , a')- Qt (s, , a, )
Exploration-Exploitation
Probabilistic approach to select actions
 where k>0 is a constant that determines how strongly the selection favors actions with high Q values.
Larger k values will assign higher probabilities to actions with above average Q, causing the optimiser to exploit what it has been learned and seek actions it believes will maximise its reward.
where k>0 is a constant that determines how strongly the selection favors actions with high Q values.
Larger k values will assign higher probabilities to actions with above average Q, causing the optimiser to exploit what it has been learned and seek actions it believes will maximise its reward.
Smaller k values will assign higher probabilities for other actions with below average Q, causing the optimiser to explore actions that do not currently have high Q values. k may vary with the number of iterations so that the optimiser favors exploration in the early stages of learning, to gradually shift towards more exploitation.
Reinforcement Learning optimisation
Why Reinforcement Learning? · Robust to Noise
• Simple
• Implementation realisation Example: Learning
After many iterations the transmit power (p) and antenna tilt (a) will be configured and optimised according to the traffic of a cells area. In the following single-cell example transmit power is assumed constant and the Q-values for different antenna tilt angles are learned
Figure 30 illustrates an example of learning according to the invention. Utility-based Decision Optimisation
The most important aspect that guides the selection of an action is its impact to the system. Utilities are used to guide for the selection of the optimal action as described by the utility optimisation next.
A utility function evaluates the state of the environment. It maps a state to a scalar value indicating how good the state is. By comparing the scalar, we can compare how good different states are.
In essence the utility of a solution vector x= (x .., xn) of n decision variables can be expressed in terms of its effects on various KPIs objectives fi(x),.., fn(x) where ¾χ), corresponds to a KPI e.g. HO success rate, Coverage outage etc
If regularities can be found then a preference structure can be found expressing the utility function as
U(x)= u(Xi, .., Xn) = f[ fl(x),.., fn(x) ] and f corresponds to the policy/prioritization among the objectives.
The utility function u(x)= u(xi, .., xn) = f[ fi(x),.., fn(x) ] can be expressed in many ways:
An aggregation function o E.g., weighted sum, u(x)= Wifi(x) + ..+wnfn(x), where wi + ..+wn=l goal programming min∑ | fk(x)-Tk | where Tk is the target set by the designer - An non-aggregating function that is non-pareto based o E.g., user-defined ordering where the objectives are ranked according to the order of importance of the desinger
MIN-MAX which compare relative deviations from the separately obtainable minima, (used in game theory to solve conflicting situations) - Pareto-based function o E.g. , pareto optimal , pareto front
Reward functions in reinforcement learning optimisation should be expressed as utility functions on a multiplicity of KPIs.
Networking Optimisation
Negotiation Optimisation
Typically negotiation strategy is a sequence of actions taken in a negotiation process consisting of offers, counter-offers, accept or quit.
Learning in negotiation means in principle learning the negotiation strategy of other negotiating entities, their types, utilities, and models.
For the update of other entities decision making model in the interaction/negotiation model bayesian belief networks (or dynamic bayesian networks or a dynamic decision networks) can be used as efficient updating mechanisms. Given the domain knowledge in the form of conditional statements and the signal e in the form of offers then offer recipient can use the standard bayesian updating rule to revise the desirable outcome of the offerer.
Learning in networks
Many different classes of learning that can be applied to a multi-cell (multi -objective) system
N cells implementing control with full information sharing and simultaneous actions.
Independent learners where each node independently learns the Q-values of its individual actions without taking into account the actions of its neighbours in the control
Coupled learners where each radio node models other radio nodes actions in its Q-values.
Joint Action learners where radio nodes learn Q-values of joint actions rather than their individual actions. This implies that each radio node can observe or exchange the actions of other radio nodes.
Learning negotiation efficiency
Learning benefits
It is not always known from the beginning
o how traffic in an area behaves o What is the load o What is the typical user mobility o What kind of area
Learning facilitates for optimal solutions that are not known at design time.
Learning facilitates for dynamically discovering optimal solutions at run time.
Allows for base stations to reconfigure themselves if they are moved to a new area or if the traffic behaviour changes i.e., establishing a new residential area.
Learning is a long term process and convergence to optimal solutions takes time
Cognitive SON Functionality Deployment and Architecture
Applying all this to a cellular network for various optimisation objectives
The utility function evaluates the state of the environment u(x)= f [ fi(x),.., fn(x) ]
In cellular systems, we use Key Performance Indicators (KPI) that reflects important aspects of the system
We can use the KPI as input to the utility function f [ Ki ... Kn] then corresponds to a policy set by the operator
The utility function enables the comparison of different sets of KPI (different states)
There is a mapping from the decision parameters (configuration parameters) to KPI values
By learning, the system can understand this mapping and how to change configuration parameters to quickly get to the optimum system state.
Below follows possible deployments of the cognitive SON functionality in alternative architectures in radio networks. All CSONE-equipped nodes are communicating via its
interaction units. Interactions with non-CSONE nodes are performed in their entirety by means of the execution unit. Interactions between CSONE nodes can be perfromed either by means of communication/cooperation unit.
CSONE Architecture of Centralised Control Cognitive SON centralised architecture (as illustrated in figure 31)
■ A central node with cognitive engine configuring node functions
□ Functions refer only to control and information e.g., RRM functions, etc
□ Functions can be dedicated and/or abstracted
CSONE centralised architecture facilitates centralized control performed by a central entity, e.g., O&M etc., that may operate in the following way, it:
- collects measurements and statistics from controlled CSONE nodes
- builds the observation, transition, state-action, and interaction models of the world based on aggregation functions of statistics, information, knowledge, actions and policies.
- coordinates controlled nodes and decides on joint actions of the nodes based on a network utility function or the utility functions of the controlled nodes which are known to the control node.
The model maintained by a central entity as envisaged above induces full knowledge of the world and the nodes the central entity monitors, controls, interacts and optimises.
A deployment of the above architecture consisting only of CSONE entities is illustrated the figure 32.
CSONE architecture of distributed control
Cognitive SON distributed architecture (as illustrated in the figure 33) Autonomous CE
■ Network nodes have cognitive engine and functions collocated
CSONE distributed architecture facilitates distributed control performed by CSONE nodes each one:
- collecting measurements and statistics from environment - building the observation, transition, state-action, and interaction models of the world.
- deciding on actions based on its utility function
- interacts and negotiates with other nodes on joint actions that will result in an acceptable and optimal solution for all involved nodes.
The model maintained by each entity implies partial knowledge of the world pertinent to the local environment of the entity i.e., the entity itself and the neighbours within reach. Working towards full knowledge requires information exchange by means of observations, state descriptions and statistics, action selection and evaluation and interactions.
A deployment of the above architecture consisting only of CSONE entities is illustrated in figure 34. CSONE Hybrid Architecture
Figure Hybrid 1 (Fig. 35): CSONE hybrid Architecture of central coordination Figure Hybrid 2 (Fig. 36): CSONE hybrid Architecture of distributed coordination Cognitive SON hybrid Architecture (as illustrated in the figures above) Many possible options □ central coordination Fig. Hybrid 1
□ Distributed coordination Fig. Hybrid2
□ Hierarchical structures or central and distributed coordination at each level of the hierarchy
CSONE distributed architecture facilitates hierarchical structure of control that combines centralized control or distributed control at any level of hierarchy and any order. In case of central control at the root of the hierarchy the architecture is said to perform central coordination control as in fig. Hybrid 1. In case of distributed control is said to perform distributed coordination control as in fig. Hybrid 2.
The model maintained by an entity at higher level of the coordination hierarchy differs from that maintained by an entity at lower level in the level of abstraction. Models at higher level of hierarchy are closer to the management operation and models maintained by lower levels of abstraction are closer to the functional operation of networks or node functions. A deployment of the above architecture consisting only of CSONE entities is illustrated in figure 37.
Claims
1. A method of controlling a telecommunications network, the network comprising at least one device arranged for interaction as regards network configuration parameters, the method c h a r a c t e r i z e d i n that one or more key performance indicators of the telecommunications network, defining a (sub-) system state, are mapped onto revised operation parameters, provided a given set of operation parameters, wherein the revised operation parameters are determined in accordance with a dynamic action policy as determined in an optimization module classifying or differentiating (sub-)system states for specifying a mapping rule providing action control of the telecommunications network for one or more sets of states according to a recursive process learning from past mapping rules.
2. The method according to claim 1, wherein (sub-)system states or state- transitions are predicted or identified in accordance with the policy.
3. The method according to claim 1, wherein the dynamic action policy is determined by recursive learning.
4. The method according to claim 1, wherein the number of parameters required for specifying one or more states is determined dynamically by recursive learning.
5. The method according to claim 4, wherein parameter statics are collected on a recurrent basis in time and wherein the actual parameters required for specifying the one or more states are determined accordingly.
6. The method according to claim 4 or 5, wherein the learning is any of inductive learning or learning the rules out of observable facts, decision tree learning,
Bayesian learning, artificial neural network based learning or learning of control functions from known observations, instance-based learning or learning state function from similarities and differences between instances or learning by regression, and correlation or statistical learning; not excluding any combination thereof.
7. The method according to any of claims 1-3, wherein the learning is any of reinforcement learning, Q-learning or learning by exploration or exploitation; not excluding any combination thereof.
8. The method according to claim 1, the network comprising at least two devices, wherein the action comprised interaction between devices.
9. The method according to claim 1, wherein the interaction comprised configuration, instruction or setting of network operation parameters.
10. The method according to claim 1, the network comprising at least two devices, wherein the interaction comprises negotiation of network parameters between devices.
11. The method according to claim 10, wherein the negotiation comprised communication or coordination of actions to a joint action of entities of the telecommunications network.
12. The method according to claim 8, the network comprising at least two devices - a first device being arranged for control and a second device for being controlled, wherein the action comprises interaction between the first device controlling the operation of the second device.
13. The method according to claim 1, wherein for learning a negotiation strategy or one or more sets of states, the telecommunications network is any of a Bayesian belief network, a dynamic Bayesian network, and a dynamic decision network.
14. The method according to claim 13, wherein the learned negotiation strategy is applied for negotiation between entities.
15. The method according to claim 1, comprising learning a dynamic network topology by discovery identifying respective network entities and their capabilities.
16. The method according to claim 1, wherein the dynamic action policy is determined dynamically during operations of the telecommunications network..
17. The method according to claim 1, wherein the device is adapted to maximize expected utility of its current state.
18. The method according to claim 1, wherein the state represents a number of key performance indicators of the telecommunications network.
19. The method according to claim 1, wherein the action policy comprises Radio Resource
Management parameter configuration.
20. The method according to claim 1, wherein the recursive process involves intra- unit iterative processing and inter-unit iterative processing.
21. A network device of a telecommunications network, the network device comprising at least one entity arranged for interaction as regards network configuration parameters characterized by processing circuitry adapted for operations on one or more key performance indicators, the key performance indicators of the telecommunications network defining a (sub-)system state, the operations including mapping the (sub-)system state onto revised operations parameters, provided a given set of operations parameters, wherein the revised operations parameters are determined in accordance with a dynamic action policy as determined in an optimization module capable of classifying or differentiating (subsystem states for specifying a mapping rule providing action control of the telecommunications network for one or more sets of states and learning from past mapping rules.
22. A telecommunications system comprising at least one entity arranged for interaction as regards network configuration parameters characterized by processing circuitry adapted for operations on one or more key performance indicators, the key performance indicators of the telecommunications network defining a (sub-)system state, the operations including mapping the (sub-)system state onto revised operations parameters, provided a given set of operation parameters, wherein the revised operation parameters are determined in accordance with a dynamic action policy as determined in an optimization module capable of classifying or differentiating (sub-)system states for specifying a mapping rule providing action control of the telecommunications network for one or more sets of states and learning from past mapping rules and comprising a communications interface between the entity arranged for negotiation of network configuration parameters and the optimization module adapted for exchange of the revised operation parameter setting or a dynamically revised action policy; a communications interface adapted for exchange of key performance indicators of the telecommunications network defining a (sub-)system state; and a communications interface adapted for exchange of device dependent parameters.
23. The telecommunications system according to claim 22, wherein one or more nodes of the system equipped with a device in claim 21 are configured centrally or distributedly, while other nodes are configured centrally.
24. The telecommunications system according to claim 22, wherein one or more nodes of the system equipped with a device in claim 21 are configured distributedly.
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201180055954.7A CN103548375A (en) | 2010-12-03 | 2011-11-22 | Method and apparatus of communications |
| EP11794062.7A EP2647239A1 (en) | 2010-12-03 | 2011-11-22 | Method and apparatus of communications |
Applications Claiming Priority (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| SE2010000285 | 2010-12-03 | ||
| SEPCT/SE2010/000285 | 2010-12-03 | ||
| SEPCT/SE2010/000287 | 2010-12-06 | ||
| SE2010000287 | 2010-12-06 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2012072445A1 true WO2012072445A1 (en) | 2012-06-07 |
Family
ID=45315737
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2011/070631 WO2012072445A1 (en) | 2010-12-03 | 2011-11-22 | Method and apparatus of communications |
Country Status (3)
| Country | Link |
|---|---|
| EP (1) | EP2647239A1 (en) |
| CN (1) | CN103548375A (en) |
| WO (1) | WO2012072445A1 (en) |
Cited By (32)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103068058A (en) * | 2012-12-24 | 2013-04-24 | 中国人民解放军总参谋部第六十一研究所 | Wireless resource scheduling method based on double-layer loop model |
| WO2013123162A1 (en) * | 2012-02-17 | 2013-08-22 | ReVerb Networks, Inc. | Methods and apparatus for coordination in multi-mode networks |
| CN103442368A (en) * | 2013-09-09 | 2013-12-11 | 哈尔滨工业大学 | Latent gaming-based method for distributing frequency spectrums in cognition wireless system |
| US8665835B2 (en) | 2009-10-16 | 2014-03-04 | Reverb Networks | Self-optimizing wireless network |
| WO2014067700A1 (en) * | 2012-10-31 | 2014-05-08 | Nokia Solutions And Networks Oy | Method, apparatus, computer program product and system for communicating predictions |
| WO2014102318A1 (en) * | 2012-12-28 | 2014-07-03 | Telefonica, S.A | Method and system for predicting the channel usage |
| WO2014158131A1 (en) * | 2013-03-25 | 2014-10-02 | Adaptive Spectrum And Signal Alignment, Inc. | Method and apparatus for implementing wireless system discovery and control using a state-space |
| WO2014198321A1 (en) * | 2013-06-13 | 2014-12-18 | Nokia Solutions And Networks Oy | Coordination in self-organizing networks |
| US9113353B1 (en) | 2015-02-27 | 2015-08-18 | ReVerb Networks, Inc. | Methods and apparatus for improving coverage and capacity in a wireless network |
| GB2524583A (en) * | 2014-03-28 | 2015-09-30 | Corey Kaizen Reaux-Savonte | System, architecture and methods for an intelligent, self-aware and context-aware digital organism-based telecommunication system |
| US9258719B2 (en) | 2011-11-08 | 2016-02-09 | Viavi Solutions Inc. | Methods and apparatus for partitioning wireless network cells into time-based clusters |
| WO2016026509A1 (en) * | 2014-08-18 | 2016-02-25 | Telefonaktiebolaget L M Ericsson (Publ) | Technique for handling rules for operating a self-organizing network |
| CN105391490A (en) * | 2015-10-20 | 2016-03-09 | 中国人民解放军理工大学 | Satellite communication network selection algorithm based on cognition |
| EP2986048A4 (en) * | 2013-05-02 | 2016-06-01 | Huawei Tech Co Ltd | Network optimization method, device and apparatus |
| US9369886B2 (en) | 2011-09-09 | 2016-06-14 | Viavi Solutions Inc. | Methods and apparatus for implementing a self optimizing-organizing network manager |
| EP3046289A1 (en) * | 2015-01-19 | 2016-07-20 | Viavi Solutions UK Limited | Techniques for dynamic network optimization using geolocation and network modeling |
| EP3122100A1 (en) * | 2015-07-24 | 2017-01-25 | Viavi Solutions UK Limited | Self-optimizing network (son) system for mobile networks |
| US20170255863A1 (en) * | 2016-03-04 | 2017-09-07 | Supported Intelligence, LLC | System and method of network optimization |
| US10375585B2 (en) | 2017-07-06 | 2019-08-06 | Futurwei Technologies, Inc. | System and method for deep learning and wireless network optimization using deep learning |
| CN112188505A (en) * | 2019-07-02 | 2021-01-05 | 中兴通讯股份有限公司 | Network optimization method and device |
| WO2021190772A1 (en) | 2020-03-27 | 2021-09-30 | Telefonaktiebolaget Lm Ericsson (Publ) | Policy for optimising cell parameters |
| WO2021213644A1 (en) * | 2020-04-22 | 2021-10-28 | Nokia Technologies Oy | A coordination and control mechanism for conflict resolution for network automation functions |
| WO2021244765A1 (en) | 2020-06-03 | 2021-12-09 | Telefonaktiebolaget Lm Ericsson (Publ) | Improving operation of a communication network |
| EP3951661A1 (en) * | 2020-08-04 | 2022-02-09 | Nokia Technologies Oy | Machine learning based antenna panel switching |
| WO2022115009A1 (en) * | 2020-11-24 | 2022-06-02 | Telefonaktiebolaget Lm Ericsson (Publ) | Network parameter for cellular network based on safety |
| WO2022123292A1 (en) * | 2020-12-09 | 2022-06-16 | Telefonaktiebolaget Lm Ericsson (Publ) | Decentralized coordinated reinforcement learning for optimizing radio access networks |
| WO2022167091A1 (en) * | 2021-02-05 | 2022-08-11 | Telefonaktiebolaget Lm Ericsson (Publ) | Configuring a reinforcement learning agent based on relative feature contribution |
| EP3961986A4 (en) * | 2019-04-22 | 2023-01-11 | ZTE Corporation | Adaptive configuration method and device of network |
| WO2023022679A1 (en) * | 2021-08-14 | 2023-02-23 | Telefonaktiebolaget Lm Ericsson (Publ) | Industrial 5g service quality assurance via markov decision process mapping |
| WO2023031098A1 (en) * | 2021-09-02 | 2023-03-09 | Nokia Solutions And Networks Oy | Devices and methods for priors generation |
| WO2023138776A1 (en) * | 2022-01-21 | 2023-07-27 | Huawei Technologies Co., Ltd. | Apparatus and method for distributed learning for communication networks |
| FR3140729A1 (en) * | 2022-10-11 | 2024-04-12 | Commissariat A L'energie Atomique Et Aux Energies Alternatives | METHOD FOR MANAGING RADIO RESOURCES IN A CELLULAR NETWORK USING HYBRID MAPPING OF RADIO CHARACTERISTICS |
Families Citing this family (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105532031B (en) * | 2014-06-05 | 2019-12-17 | 华为技术有限公司 | Resource optimization method and device |
| WO2018068857A1 (en) * | 2016-10-13 | 2018-04-19 | Huawei Technologies Co., Ltd. | Method and unit for radio resource management using reinforcement learning |
| CN107425997B (en) * | 2017-03-27 | 2019-08-06 | 烽火通信科技股份有限公司 | The network architecture and implementation method of class people net |
| WO2019007388A1 (en) * | 2017-07-06 | 2019-01-10 | Huawei Technologies Co., Ltd. | System and method for deep learning and wireless network optimization using deep learning |
| CN109308246A (en) * | 2017-07-27 | 2019-02-05 | 阿里巴巴集团控股有限公司 | Optimization method, device and the equipment of system parameter, readable medium |
| CN107948984B (en) * | 2017-11-13 | 2021-07-09 | 中国电子科技集团公司第三十研究所 | Active and passive perception combination-based cognitive system suitable for self-organizing network |
| CN111050330B (en) * | 2018-10-12 | 2023-04-28 | 中兴通讯股份有限公司 | Mobile network self-optimization method, system, terminal and computer readable storage medium |
| US11271795B2 (en) * | 2019-02-08 | 2022-03-08 | Ciena Corporation | Systems and methods for proactive network operations |
| EP3944562A3 (en) * | 2020-07-24 | 2022-03-23 | Nokia Technologies Oy | Methods and apparatuses for determining optimal configuration in cognitive autonomous networks |
| CN112039767B (en) * | 2020-08-11 | 2021-08-31 | 山东大学 | Multi-data center energy-saving routing method and system based on reinforcement learning |
| US11800398B2 (en) | 2021-10-27 | 2023-10-24 | T-Mobile Usa, Inc. | Predicting an attribute of an immature wireless telecommunication network, such as a 5G network |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6829491B1 (en) | 2001-08-15 | 2004-12-07 | Kathrein-Werke Kg | Dynamic and self-optimizing smart network |
| WO2005017707A2 (en) * | 2003-08-14 | 2005-02-24 | Telcordia Technologies, Inc. | Auto-ip traffic optimization in mobile telecommunications systems |
| EP1947897A2 (en) * | 2007-01-18 | 2008-07-23 | NEC Corporation | Wireless base station apparatus capable of effectivley using wireless resources according to sorts of data |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101488880B (en) * | 2008-01-16 | 2012-03-14 | 北京航空航天大学 | Adaptive maintenance method for improving reliability of service combination |
-
2011
- 2011-11-22 WO PCT/EP2011/070631 patent/WO2012072445A1/en unknown
- 2011-11-22 EP EP11794062.7A patent/EP2647239A1/en not_active Withdrawn
- 2011-11-22 CN CN201180055954.7A patent/CN103548375A/en active Pending
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6829491B1 (en) | 2001-08-15 | 2004-12-07 | Kathrein-Werke Kg | Dynamic and self-optimizing smart network |
| WO2005017707A2 (en) * | 2003-08-14 | 2005-02-24 | Telcordia Technologies, Inc. | Auto-ip traffic optimization in mobile telecommunications systems |
| EP1947897A2 (en) * | 2007-01-18 | 2008-07-23 | NEC Corporation | Wireless base station apparatus capable of effectivley using wireless resources according to sorts of data |
Non-Patent Citations (7)
| Title |
|---|
| ANDREAS LOBINGER: "Load Balancing in Downlink LTE Self Optimizing Networks", VTC 2010-SPRING TAIPEI, 19 May 2010 (2010-05-19) |
| ECKARD BOGENFELD, INGO GASPARD: "Self-x in radio access networks", 22 December 2008 (2008-12-22), XP002670465, Retrieved from the Internet <URL:https://ict-e3.eu/project/white_papers/Self-x_WhitePaper_Final_v1.0.pdf> [retrieved on 20120228] * |
| HENNING VETTER, WOON HAU CHIN,ANDREAS MERENTITIS,EVANGELOS REKKAS,MAKIS STAMATELATOS, ELI DE POORTER,LIEVEN TYTGAT,OPHER YARON: "Enablers for Energy-Aware Cooperative Decision and Control", 31 October 2010 (2010-10-31), XP002670464, Retrieved from the Internet <URL:http://kandalf.di.uoa.gr/consern/attachments/article/136/CONSERN_D3.1-Enablers%20for%20Energy-Aware%20Cooperative%20Decision%20and%20Control.pdf> [retrieved on 20120228] * |
| MARIANA DIRANI ET AL: "A cooperative Reinforcement Learning approach for Inter-Cell Interference Coordination in OFDMA cellular networks", MODELING AND OPTIMIZATION IN MOBILE, AD HOC AND WIRELESS NETWORKS (WIOPT), 2010 PROCEEDINGS OF THE 8TH INTERNATIONAL SYMPOSIUM ON, IEEE, PISCATAWAY, NJ, USA, 31 May 2010 (2010-05-31), pages 170 - 176, XP031714634, ISBN: 978-1-4244-7523-0 * |
| See also references of EP2647239A1 * |
| ZHIYONG FENG ET AL: "Reinforcement learning based Dynamic Network Self-optimization for heterogeneous networks", 2009 IEEE PACIFIC RIM CONFERENCE ON COMMUNICATIONS, COMPUTERS AND SIGNAL PROCESSING, 1 August 2009 (2009-08-01), pages 319 - 324, XP055020302, ISBN: 978-1-42-444560-8, DOI: 10.1109/PACRIM.2009.5291353 * |
| ZWI ALTMAN: "Design and evaluation of self-optimisationalgorithms for radio access networks", 9 June 2009 (2009-06-09), XP002670463, Retrieved from the Internet <URL:http://www.fp7-socrates.org/files/Workshop1/SOCRATES%20workshop%20Santander_Zwi%20Altman.pdf> [retrieved on 20120228] * |
Cited By (53)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9826420B2 (en) | 2009-10-16 | 2017-11-21 | Viavi Solutions Inc. | Self-optimizing wireless network |
| US8665835B2 (en) | 2009-10-16 | 2014-03-04 | Reverb Networks | Self-optimizing wireless network |
| US9226178B2 (en) | 2009-10-16 | 2015-12-29 | Reverb Networks | Self-optimizing wireless network |
| US9369886B2 (en) | 2011-09-09 | 2016-06-14 | Viavi Solutions Inc. | Methods and apparatus for implementing a self optimizing-organizing network manager |
| US9258719B2 (en) | 2011-11-08 | 2016-02-09 | Viavi Solutions Inc. | Methods and apparatus for partitioning wireless network cells into time-based clusters |
| US10003981B2 (en) | 2011-11-08 | 2018-06-19 | Viavi Solutions Inc. | Methods and apparatus for partitioning wireless network cells into time-based clusters |
| US9008722B2 (en) | 2012-02-17 | 2015-04-14 | ReVerb Networks, Inc. | Methods and apparatus for coordination in multi-mode networks |
| WO2013123162A1 (en) * | 2012-02-17 | 2013-08-22 | ReVerb Networks, Inc. | Methods and apparatus for coordination in multi-mode networks |
| WO2014067700A1 (en) * | 2012-10-31 | 2014-05-08 | Nokia Solutions And Networks Oy | Method, apparatus, computer program product and system for communicating predictions |
| CN103068058B (en) * | 2012-12-24 | 2015-08-26 | 中国人民解放军总参谋部第六十一研究所 | A kind of scheduling method for wireless resource based on double-layer loop model |
| CN103068058A (en) * | 2012-12-24 | 2013-04-24 | 中国人民解放军总参谋部第六十一研究所 | Wireless resource scheduling method based on double-layer loop model |
| WO2014102318A1 (en) * | 2012-12-28 | 2014-07-03 | Telefonica, S.A | Method and system for predicting the channel usage |
| US10231138B2 (en) | 2013-03-25 | 2019-03-12 | Adaptive Spectrum And Signal Alignment, Inc. | Method and apparatus for implementing wireless system discovery and control using a state-space |
| WO2014158131A1 (en) * | 2013-03-25 | 2014-10-02 | Adaptive Spectrum And Signal Alignment, Inc. | Method and apparatus for implementing wireless system discovery and control using a state-space |
| KR101861908B1 (en) * | 2013-03-25 | 2018-05-28 | 어댑티브 스펙트럼 앤드 시그널 얼라인먼트, 인크. | Method and apparatus for implementing wireless system discovery and control using a state-space |
| US10708793B2 (en) | 2013-03-25 | 2020-07-07 | Assia Spe, Llc | Method and apparatus for implementing wireless system discovery and control using a state-space |
| US20160066201A1 (en) * | 2013-03-25 | 2016-03-03 | Adaptive Spectrum And Signal Alignment, Inc. | Method and apparatus for implementing wireless system discovery and control using a state-space |
| US9848341B2 (en) | 2013-05-02 | 2017-12-19 | Huawei Technologies Co., Ltd. | Network optimization method, and network optimization device |
| EP2986048A4 (en) * | 2013-05-02 | 2016-06-01 | Huawei Tech Co Ltd | Network optimization method, device and apparatus |
| US10412601B2 (en) | 2013-06-13 | 2019-09-10 | Nokia Solutions And Networks Oy | Coordination in self-organizing networks |
| WO2014198321A1 (en) * | 2013-06-13 | 2014-12-18 | Nokia Solutions And Networks Oy | Coordination in self-organizing networks |
| CN103442368A (en) * | 2013-09-09 | 2013-12-11 | 哈尔滨工业大学 | Latent gaming-based method for distributing frequency spectrums in cognition wireless system |
| CN103442368B (en) * | 2013-09-09 | 2016-03-30 | 哈尔滨工业大学 | Based on the frequency spectrum distributing method of potential game in cognitive radio system |
| GB2524583A (en) * | 2014-03-28 | 2015-09-30 | Corey Kaizen Reaux-Savonte | System, architecture and methods for an intelligent, self-aware and context-aware digital organism-based telecommunication system |
| GB2524583B (en) * | 2014-03-28 | 2017-08-09 | Kaizen Reaux-Savonte Corey | System, architecture and methods for an intelligent, self-aware and context-aware digital organism-based telecommunication system |
| WO2016026509A1 (en) * | 2014-08-18 | 2016-02-25 | Telefonaktiebolaget L M Ericsson (Publ) | Technique for handling rules for operating a self-organizing network |
| US9456362B2 (en) | 2015-01-19 | 2016-09-27 | Viavi Solutions Uk Limited | Techniques for dynamic network optimization using geolocation and network modeling |
| US10050844B2 (en) | 2015-01-19 | 2018-08-14 | Viavi Solutions Uk Limited | Techniques for dynamic network optimization using geolocation and network modeling |
| EP3046289A1 (en) * | 2015-01-19 | 2016-07-20 | Viavi Solutions UK Limited | Techniques for dynamic network optimization using geolocation and network modeling |
| US9113353B1 (en) | 2015-02-27 | 2015-08-18 | ReVerb Networks, Inc. | Methods and apparatus for improving coverage and capacity in a wireless network |
| CN106375951A (en) * | 2015-07-24 | 2017-02-01 | 维亚威解决方案英国有限公司 | Self-optimizing network (SON) system for mobile networks |
| EP3122100A1 (en) * | 2015-07-24 | 2017-01-25 | Viavi Solutions UK Limited | Self-optimizing network (son) system for mobile networks |
| US9918239B2 (en) | 2015-07-24 | 2018-03-13 | Viavi Solutions Uk Limited | Self-optimizing network (SON) system for mobile networks |
| CN106375951B (en) * | 2015-07-24 | 2018-03-23 | 维亚威解决方案英国有限公司 | self-optimizing network (SON) system for mobile network |
| CN105391490A (en) * | 2015-10-20 | 2016-03-09 | 中国人民解放军理工大学 | Satellite communication network selection algorithm based on cognition |
| CN105391490B (en) * | 2015-10-20 | 2019-02-05 | 中国人民解放军理工大学 | A kind of satellite communication network selection algorithm based on cognition |
| US20170255863A1 (en) * | 2016-03-04 | 2017-09-07 | Supported Intelligence, LLC | System and method of network optimization |
| US10375585B2 (en) | 2017-07-06 | 2019-08-06 | Futurwei Technologies, Inc. | System and method for deep learning and wireless network optimization using deep learning |
| EP3961986A4 (en) * | 2019-04-22 | 2023-01-11 | ZTE Corporation | Adaptive configuration method and device of network |
| CN112188505A (en) * | 2019-07-02 | 2021-01-05 | 中兴通讯股份有限公司 | Network optimization method and device |
| WO2021190772A1 (en) | 2020-03-27 | 2021-09-30 | Telefonaktiebolaget Lm Ericsson (Publ) | Policy for optimising cell parameters |
| WO2021213644A1 (en) * | 2020-04-22 | 2021-10-28 | Nokia Technologies Oy | A coordination and control mechanism for conflict resolution for network automation functions |
| WO2021244765A1 (en) | 2020-06-03 | 2021-12-09 | Telefonaktiebolaget Lm Ericsson (Publ) | Improving operation of a communication network |
| EP3951661A1 (en) * | 2020-08-04 | 2022-02-09 | Nokia Technologies Oy | Machine learning based antenna panel switching |
| US11902806B2 (en) | 2020-08-04 | 2024-02-13 | Nokia Technologies Oy | Machine learning based antenna panel switching |
| WO2022115009A1 (en) * | 2020-11-24 | 2022-06-02 | Telefonaktiebolaget Lm Ericsson (Publ) | Network parameter for cellular network based on safety |
| WO2022123292A1 (en) * | 2020-12-09 | 2022-06-16 | Telefonaktiebolaget Lm Ericsson (Publ) | Decentralized coordinated reinforcement learning for optimizing radio access networks |
| WO2022167091A1 (en) * | 2021-02-05 | 2022-08-11 | Telefonaktiebolaget Lm Ericsson (Publ) | Configuring a reinforcement learning agent based on relative feature contribution |
| WO2023022679A1 (en) * | 2021-08-14 | 2023-02-23 | Telefonaktiebolaget Lm Ericsson (Publ) | Industrial 5g service quality assurance via markov decision process mapping |
| WO2023031098A1 (en) * | 2021-09-02 | 2023-03-09 | Nokia Solutions And Networks Oy | Devices and methods for priors generation |
| WO2023138776A1 (en) * | 2022-01-21 | 2023-07-27 | Huawei Technologies Co., Ltd. | Apparatus and method for distributed learning for communication networks |
| FR3140729A1 (en) * | 2022-10-11 | 2024-04-12 | Commissariat A L'energie Atomique Et Aux Energies Alternatives | METHOD FOR MANAGING RADIO RESOURCES IN A CELLULAR NETWORK USING HYBRID MAPPING OF RADIO CHARACTERISTICS |
| EP4354949A1 (en) * | 2022-10-11 | 2024-04-17 | Commissariat à l'énergie atomique et aux énergies alternatives | Method for managing radio resources in a cellular network using hybrid mapping of radio characteristics |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2647239A1 (en) | 2013-10-09 |
| CN103548375A (en) | 2014-01-29 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2012072445A1 (en) | Method and apparatus of communications | |
| Morocho-Cayamcela et al. | Machine learning for 5G/B5G mobile and wireless communications: Potential, limitations, and future directions | |
| Szott et al. | Wi-Fi meets ML: A survey on improving IEEE 802.11 performance with machine learning | |
| Wang et al. | Artificial intelligence-based techniques for emerging heterogeneous network: State of the arts, opportunities, and challenges | |
| Pasandi et al. | Challenges and limitations in automating the design of mac protocols using machine-learning | |
| Fourati et al. | Comprehensive survey on self-organizing cellular network approaches applied to 5G networks | |
| Kaloxylos et al. | AI and ML–Enablers for beyond 5G Networks | |
| Matinmikko et al. | Fuzzy-logic based framework for spectrum availability assessment in cognitive radio systems | |
| Karunaratne et al. | An overview of machine learning approaches in wireless mesh networks | |
| Abbasi et al. | Deep Reinforcement Learning for QoS provisioning at the MAC layer: A Survey | |
| Ashtari et al. | Knowledge-defined networking: Applications, challenges and future work | |
| Cheng et al. | Deep learning for wireless networking: The next frontier | |
| Caso et al. | User-centric radio access technology selection: A survey of game theory models and multi-agent learning algorithms | |
| Rojas et al. | A scalable SON coordination framework for 5G | |
| Zheng et al. | An adaptive backoff selection scheme based on Q-learning for CSMA/CA | |
| Meshkova et al. | Designing a self-optimization system for cognitive wireless home networks | |
| Flushing et al. | Relay node placement for performance enhancement with uncertain demand: A robust optimization approach | |
| Arnous et al. | ILFCS: an intelligent learning fuzzy-based channel selection framework for cognitive radio networks | |
| Burgueño et al. | Distributed deep reinforcement learning resource allocation scheme for industry 4.0 device-to-device scenarios | |
| Pandey | Adaptive Learning For Mobile Network Management | |
| Höyhtyä et al. | Cognitive engine: design aspects for mobile clouds | |
| Galindo-Serrano et al. | Managing femto to macro interference without X2 interface support through POMDP | |
| Jia et al. | Digital Twin Enabled Intelligent Network Orchestration for 6G: A Dual-Layered Approach | |
| Wang et al. | Cognitive networks and its layered cognitive architecture | |
| Jurado-Lasso et al. | HRL-TSCH: A Hierarchical Reinforcement Learning-based TSCH Scheduler for IIoT |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 11794062 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |